
はじめに
GLB事業部 Lakehouse 部のメイです。
KX Systems は時系列データベース kdb+ を活用して、KDB.AI を2023年9月に公開しました。 KDB.AI は、強力な知識ベースのベクトル データベースおよび検索エンジンであり、リアルタイム データを使用して AI アプリケーションの高度な検索、推奨、パーソナライゼーションを提供しています。
この記事では前の記事で紹介した KDB.AI のサンプルコードの中でセンサーデータのパターンマッチングについてご紹介致します。
目次
センサーデータのパターンマッチングの紹介
KDB.AI の類似性検索を使用して、時系列データに対してパターン マッチングを実行するプロセスをサンプルコードで紹介します。目標としては、特定のパターンにマッチする過去の時系列データを取得することです。 パターンマッチングは、品質管理、プロセスの最適化、予知保全などの幅広い製造シナリオに役立ちます。 たとえば、パフォーマンスを表す時系列データがあり、機械の異常な動き(上昇、低下、繰り返し発生する傾向など)を検知する為利用します。KDB.AI のベクトル データベースを使用して、入力クエリ パターンに一致する履歴パターンを見つけます。プロセスの流れとしては以下の通りです。
- センサーデータ読込、前処理をする
- ベクトル化し埋め込む
- KDB.AI に埋め込みを保存する
- ターゲットセンサーシーケンスに類似したシーケンスの検索する
- KDB.AIテーブルを削除する
サンプルデータは Kaggle から利用しています。給水ポンプから センサー52 個からのデータ (220,320行) は sensor.csv ファイルで格納されてます。 www.kaggle.com
サンプルコード実習
サンプルコードとデータをを Databricks の Workspace 上でアップして実習してみます。
kdb.ai
1. センサーデータ読込、前処理をする
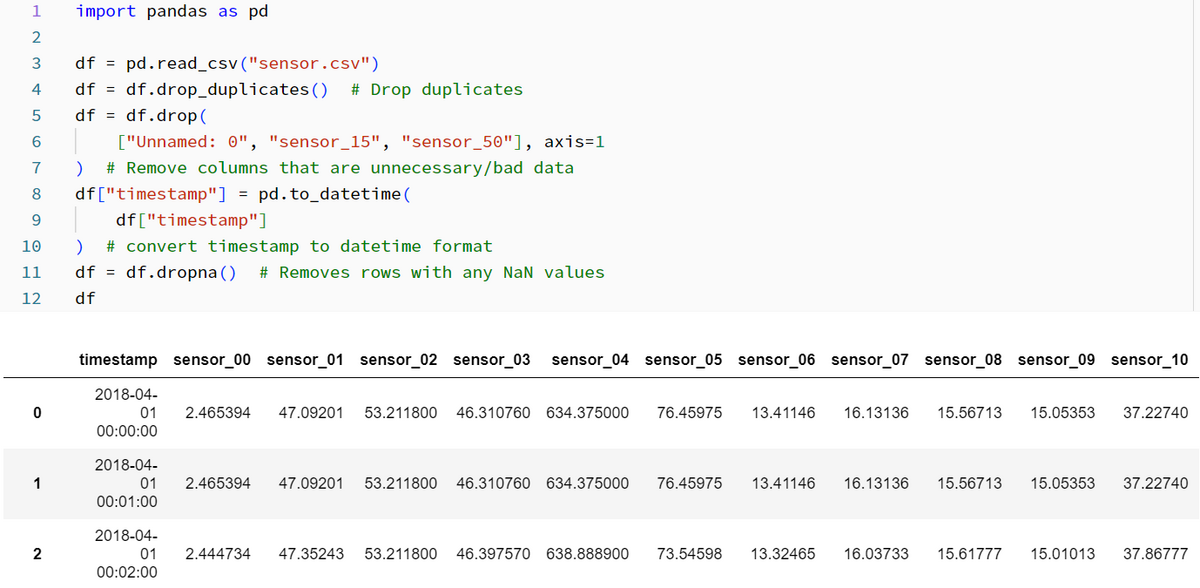
Zipファイルからデータを抽出した後、csvファイルを読み込みます。 全処理として、以下のプロセスを行います。
- 重複を削除する
- 不要なデータの列を削除する
- 全部の列がNull値になる行を削除する
- タイムスタンプを日時形式に変換する
2. ベクトル化し埋め込む
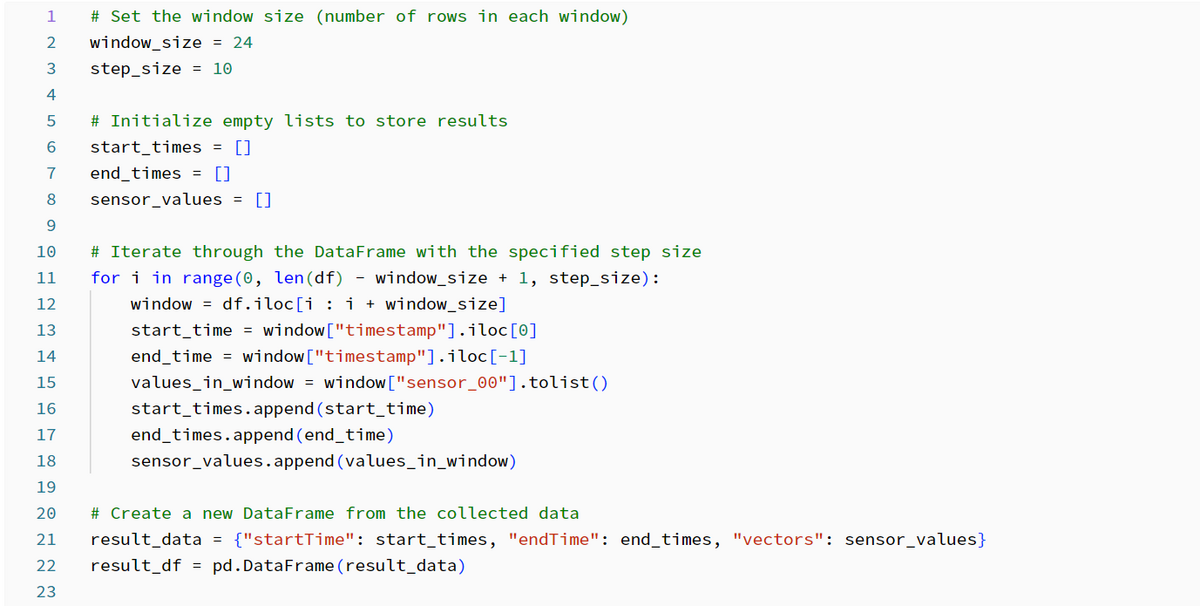
ウィンドウ処理とデータの正規化を組み合わせて埋め込みを作成します。1 つのセンサー値を取得してウィンドウにグループ化します。
各ウィンドウには、指定された行数とタイムラインに沿って行をシフトする方法を決定するステップ サイズが含まれます。
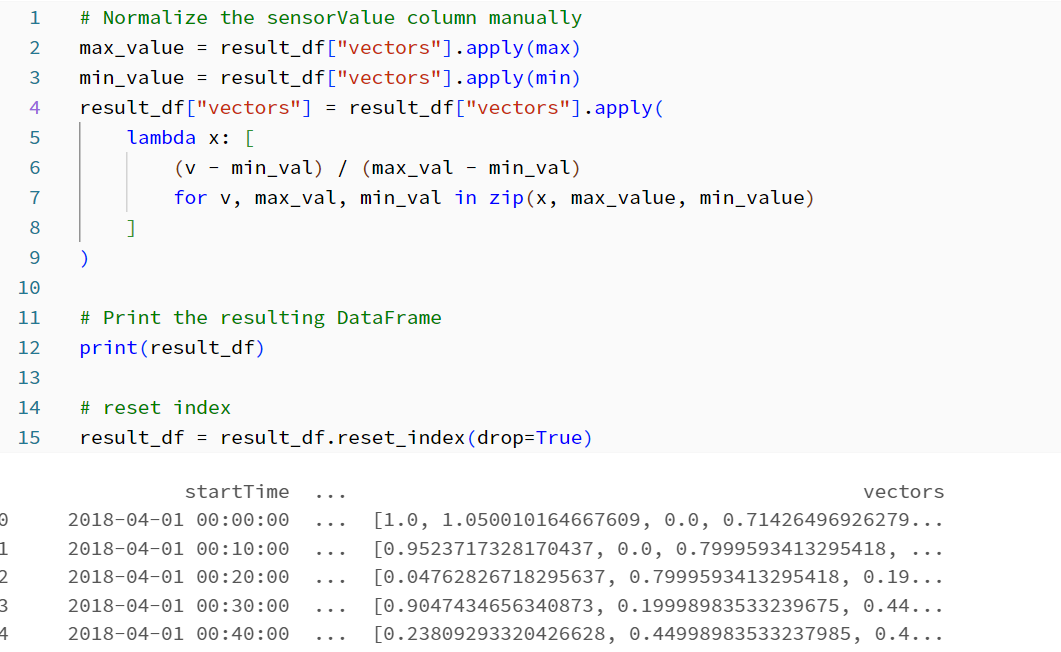
次に、各ウィンドウ内でセンサー値の手動正規化を実行します。
3. KDB.AI に埋め込みを保存する
KDB.AI のセッションをAPIキーとEndpointで接続します。 APIキーの作り方は以下の記事をご参照ください。 techblog.ap-com.co.jp
KDB.AI との接続ができたら、スキーマを作成します。 時系列データをベクトルとして保存する為、「startTime, endTime, vectors」カラムを設定します。 インデックスを作成する為、パラメータとして
- 前に設定したウィンドウ サイズ
- 距離メトリック
- インデックス種類 が必要です。
距離メトリックはベクトル間の類似性を測定するために使用されます。KDB.AI ではユークリッド距離 (Euclidean distance) L2、ドット積 (Dot product) IP, コサイン類似度 (Cosine similarity) CS が利用できます。このサンプルコードでは L2 が選択されてます。
KDB.AI ではインデックスとしてFlat、IVF、IVFPQ、HNSW が利用できます。このサンプルコードでは HNSW が選択されてます。
設定したスキーマでテーブルを作成して埋め込みデータをテーブルに保存します。
保存されたデータを検索してみます。

4. ターゲットセンサーシーケンスに類似したシーケンスの検索する
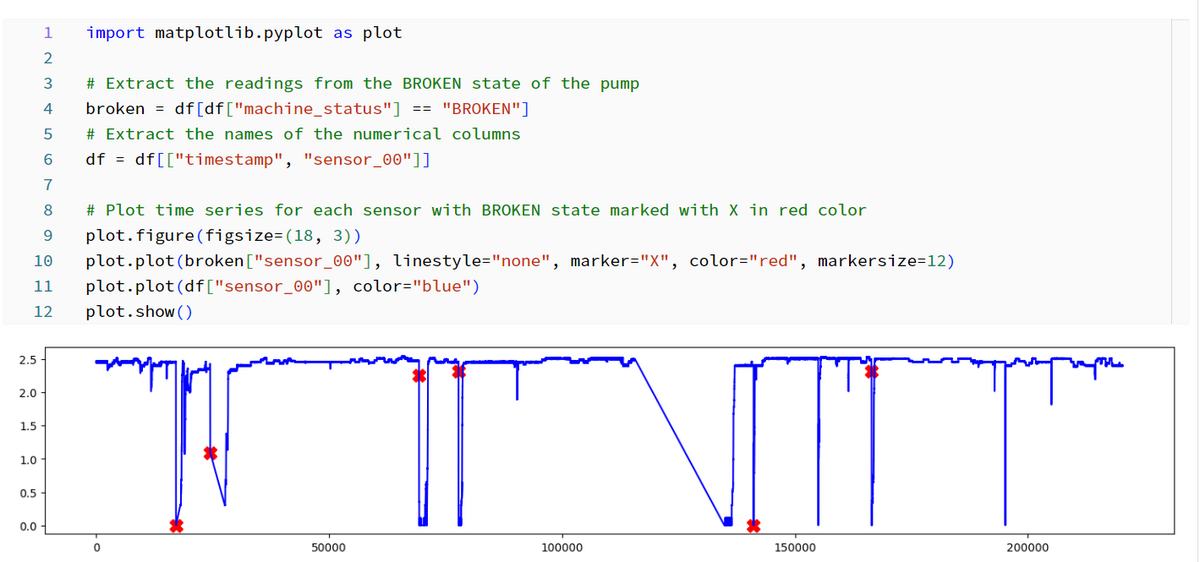
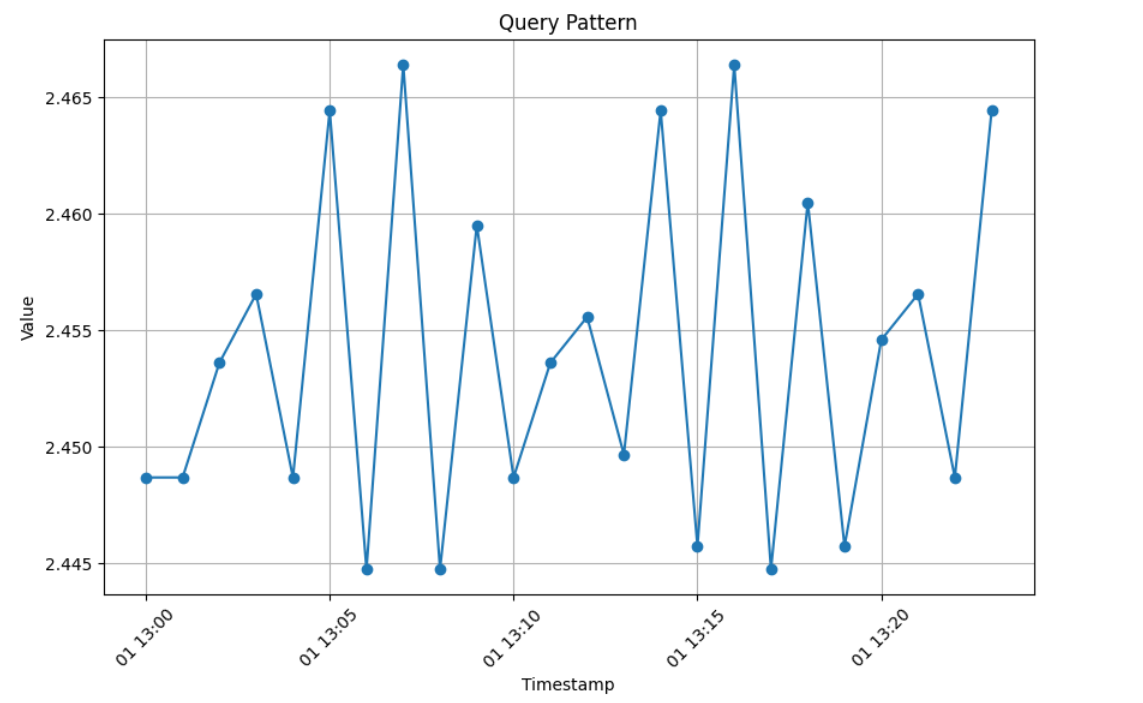
sensor_00の開始時間「2018-04-01 13:00:00」からベクトル値を選択して視覚化します。
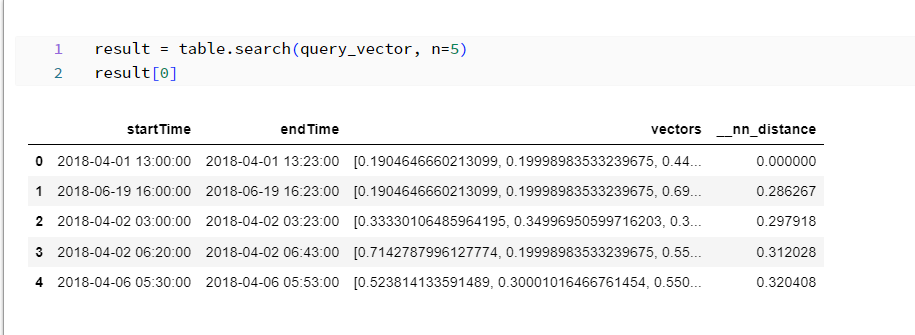
選択したパターンを ベクトル データベースに検索して、最も近い5 つの値を取得して視覚化します。
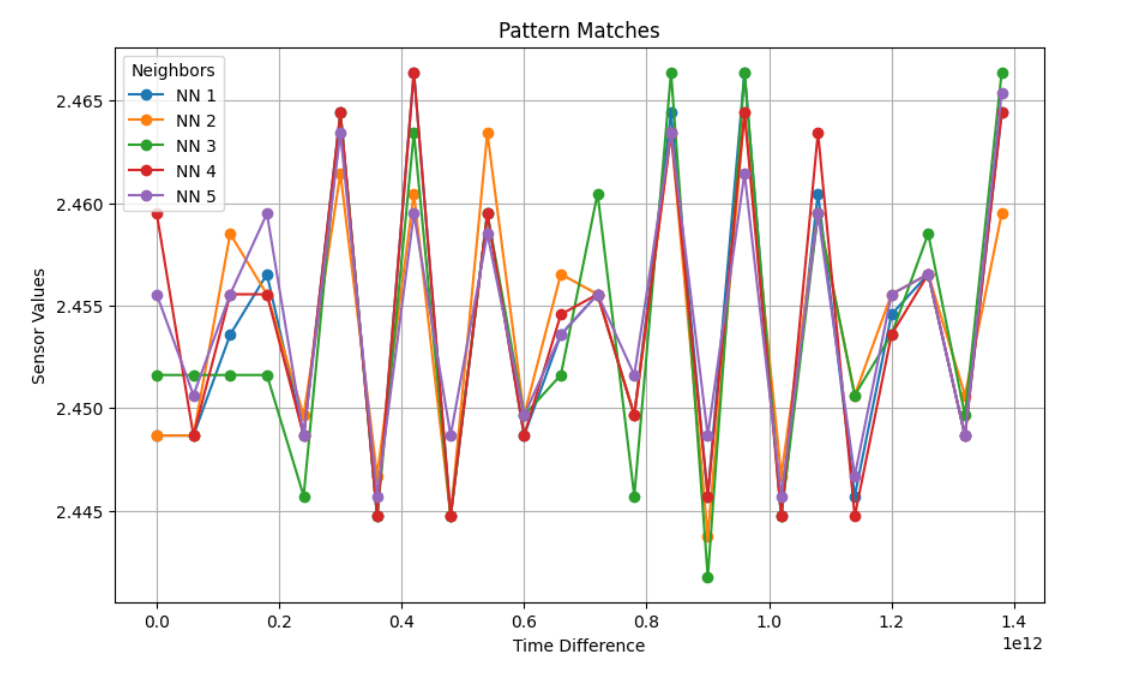
5. KDB.AIテーブルを削除する
テーブルの使用が終了したら、KDB.AIテーブルを削除することはベストプラクティスです。
まとめ
今回の投稿では Databricks 上で行った KDB.AI のサンプルコードであるパターンマッチングを Databricks 上で動かしました。早いスピードでインデックスを作成し、データを検索して結果を出せるのは素晴らしいだと思います。
次回の投稿では、今回の投稿のようにKDB.AIの他のサンプルコードをDatabricks上で検証してみて、これについてご紹介したいと思います。
最後までご覧いただきありがとうございます。
引き続きどうぞよろしくお願い致します!

私たちはDatabricksを用いたデータ分析基盤の導入から内製化支援まで幅広く支援をしております。
もしご興味がある方は、お問い合わせ頂ければ幸いです。
また、一緒に働いていただける仲間も募集中です!
APCにご興味がある方の連絡をお待ちしております。