
はじめに
GLB事業部 Lakehouse 部のメイです。
KX Systems は時系列データベース kdb+ を活用して、KDB.AI を2023年9月に公開しました。 KDB.AI は、強力な知識ベースのベクトル データベースおよび検索エンジンであり、リアルタイム データを使用して AI アプリケーションの高度な検索、推奨、パーソナライゼーションを提供しています。
この記事では前の記事で紹介した KDB.AI のサンプルコードの中で感情分析についてご紹介致します。
目次
感情分析の紹介
感情分析はテキストを分析して、メッセージの感情的なトーンが肯定的 (positive) 、否定的 (negative) 、中立的 (neutral) のどれに属するかを判断するプロセスです。今回のサンプルの目的としては、ディズニーランド リゾートのレビューから貴重な感情を抽出し、顧客体験を深く理解するようにします。自然言語処理 (NLP) と感情分析を活用して、レビューで表現された感情を評価します。KDB.AI を使用すると、レビュー自体だけでなく感情ラベルもメタデータとして保存できます。
処理の流れとしては以下の通りです。
- レビューデータを読み込む
- レビューに対する感情分析を実行する
- レビューをベクトル化し埋め込む
- KDB.AI に埋め込みを保存する
- 対象のレビューに類似したレビューを検索する
- KDB.AIテーブルを削除する
サンプルデータは Kaggle から利用されます。データセットでは旅行者が TripAdvisor に投稿したディズニーランドの 3 つの支店 (パリ、カリフォルニア、香港) に関する 42,000 件のレビューが含まれています。 www.kaggle.com
サンプルコード実習
サンプルコードとデータをを Databricks の Workspace 上でアップして実習してみます。
kdb.ai
1. レビューデータを読み込む
Zipファイルからデータを抽出した後、csvファイルを読み込んで内容を見ます。
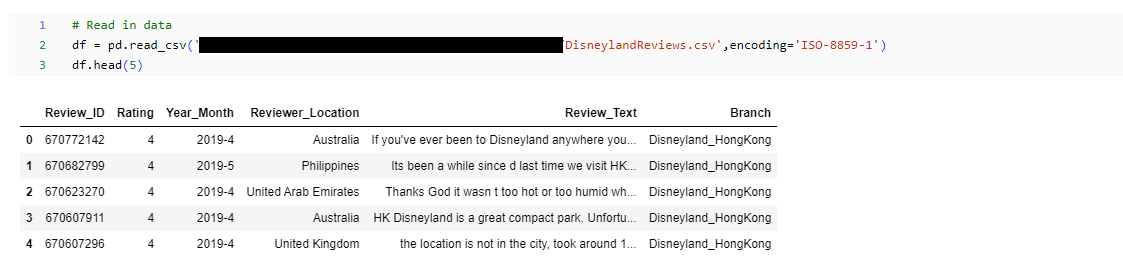
CPU とメモリの速度は、感情分析を実行するときの処理時間に影響します。 この例を CPU で実行する場合は、パフォーマンスを向上させるために行数を制限します。 GPU で実行する場合は、完全なデータセットを使用しても構いません。


2. レビューに対する感情分析を実行する
感情分析する為、重要なコンポーネントをインポートします。
- AutoModelForSequenceClassification: 感情分析などのシーケンス分類タスク用に微調整されたトランスフォーマー モデルです。 さまざまな NLP タスクを処理する為利用できます。
- AutoTokenizer: モデルにフィードするテキスト データを前処理(エンコード)します。
- MODEL: 感情分類タスク用に微調整されたモデルです。この例では、RoBERTa モデルをHugging Face からインポートします。


テキスト データの感情分析を簡単に実行できるようにパイプラインを構成します。
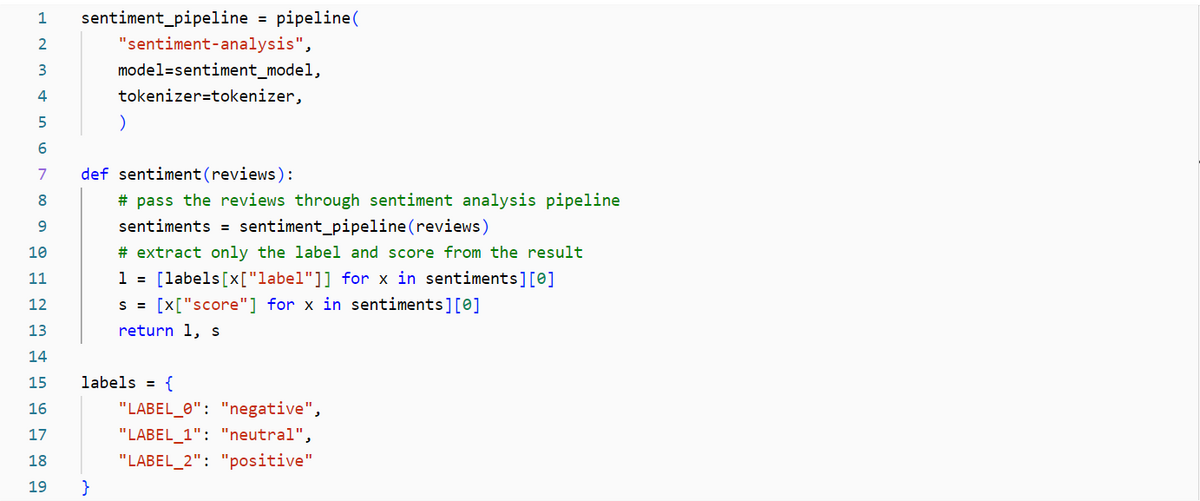
データ全体に対して感情分析を実行します。

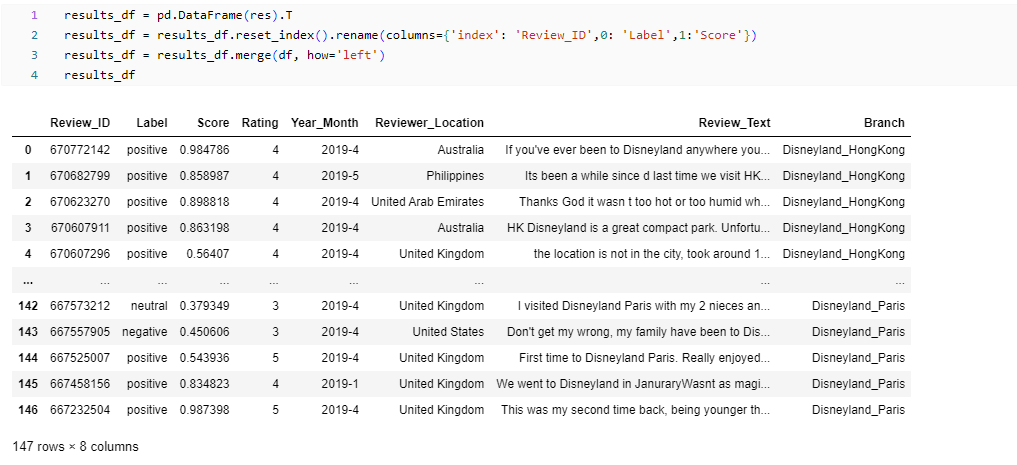
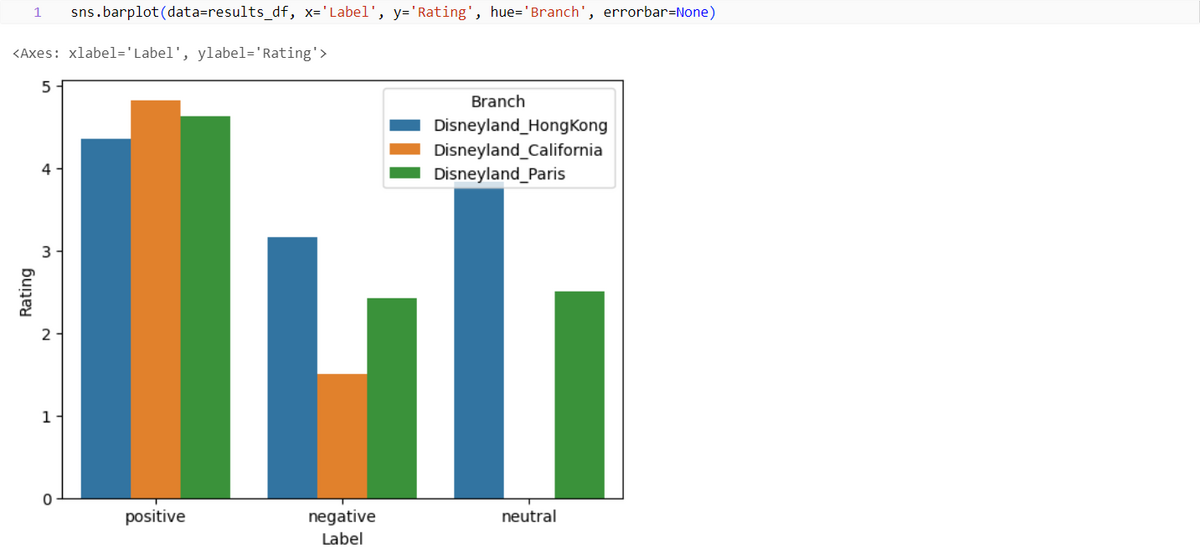
結果を視覚化すると、3 つの支店間の感情の多様性がわかり、評価を比較できます。 肯定的なレビューについてはすべて評価値 4, 5 で表示されます。 否定的なレビューの評価値は低くなり、カリフォルニア支店はすべて支店の中で最も低い評価を受けています。
3. レビューをベクトル化し埋め込む
KDB.AI に保存する前に、Sentence Transformer を利用してテキストの埋め込みを実行します。


4. KDB.AI に埋め込みを保存する
KDB.AI のセッションをAPIキーとEndpointで接続します。 APIキーの作り方は以下の記事をご参照ください。 techblog.ap-com.co.jp
KDB.AI との接続ができたら、スキーマを作成します。 時系列データをベクトルとして保存する為、「Branch, Label, Score, Rating, Review_Text, embeddings」カラムを設定します。 インデックスを作成する為、パラメータとして
- 前に設定したウィンドウ サイズ
- 距離メトリック
- インデックス種類 が必要です。
距離メトリックはベクトル間の類似性を測定するために使用されます。KDB.AI ではユークリッド距離 (Euclidean distance) L2、ドット積 (Dot product) IP, コサイン類似度 (Cosine similarity) CS が利用できます。このサンプルコードでは CS が選択されてます。
KDB.AI ではインデックスとしてFlat、IVF、IVFPQ、HNSW が利用できます。このサンプルコードでは HNSW が選択されてます。
設定したスキーマでテーブルを作成して埋め込みデータをテーブルに保存します。

5. 対象のレビューに類似したレビューを検索する
検索を実行して結果を取得するための関数を作成します。 取得したデータをさらに分析できるようにします。
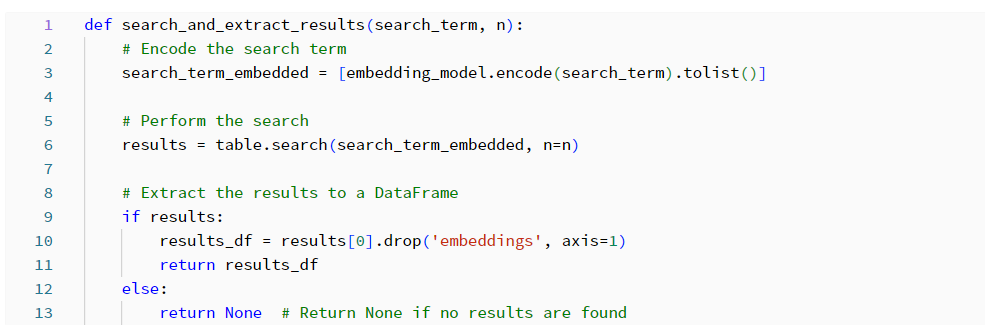
「顧客はパークの食事に満足していますか?」という検索語句を使用し、結果を10件に絞ってクエリを実行してみます。
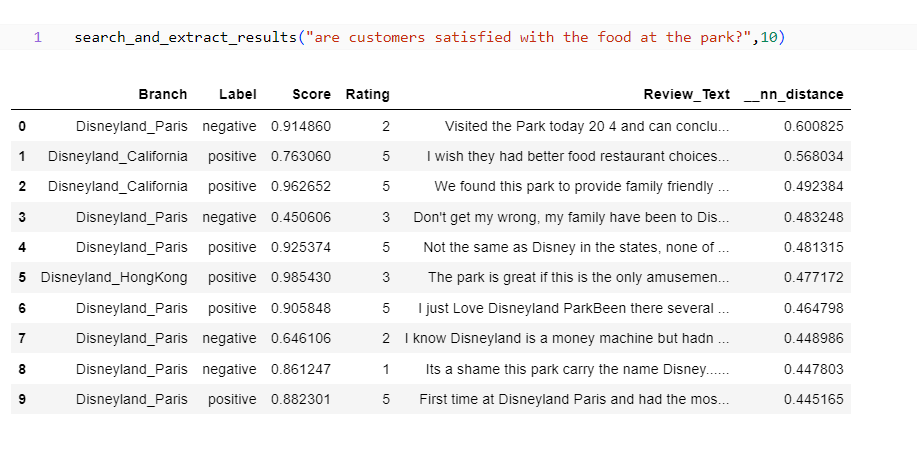
また支店 の感情数を集計し、結果を25件に絞ってクエリを実行してみます。
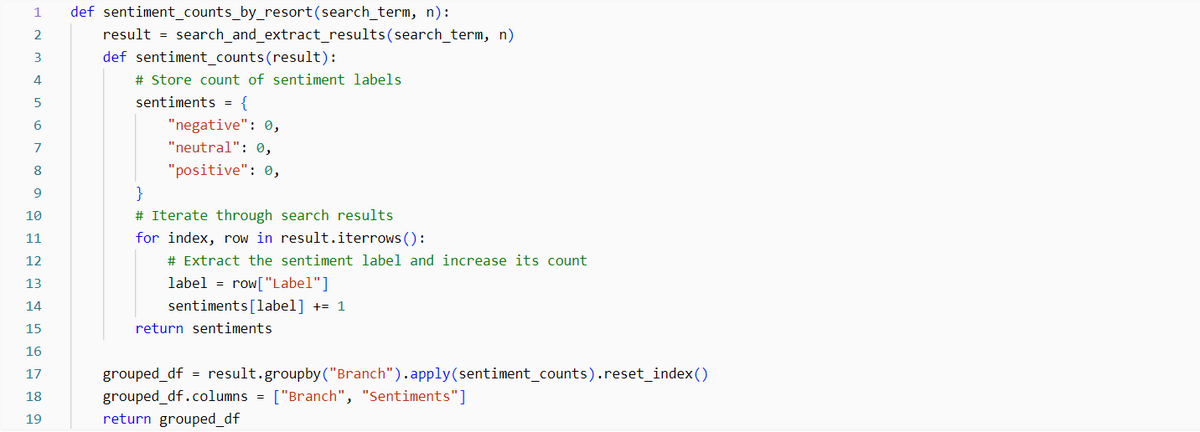

視覚化するための関数を作成します。
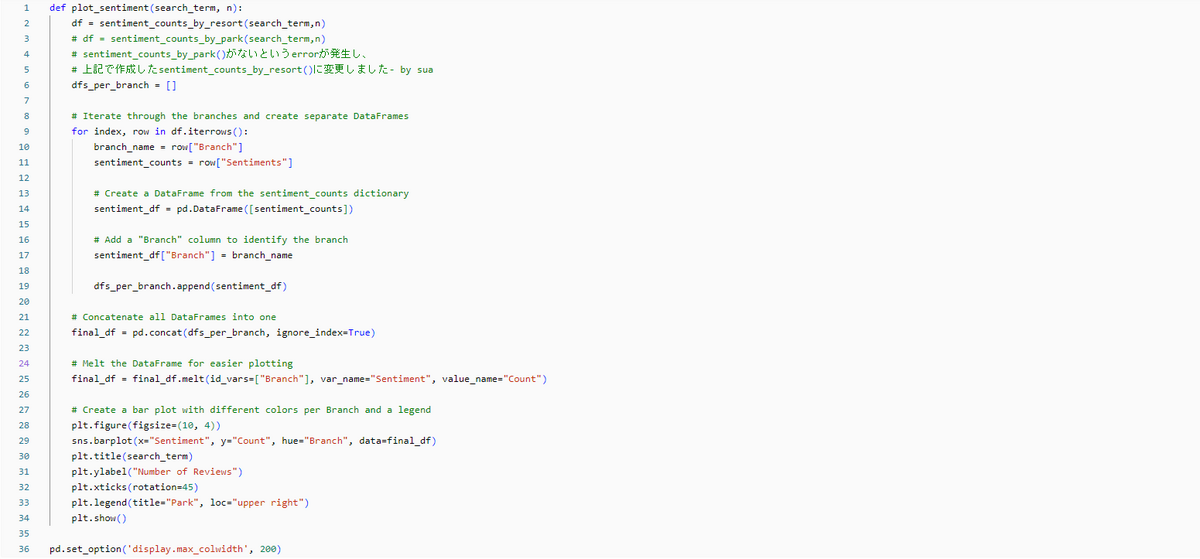
「顧客はパークの食事に満足していますか?」という検索語句を使用し、結果を50件に絞ってグラフで結果を見ます。
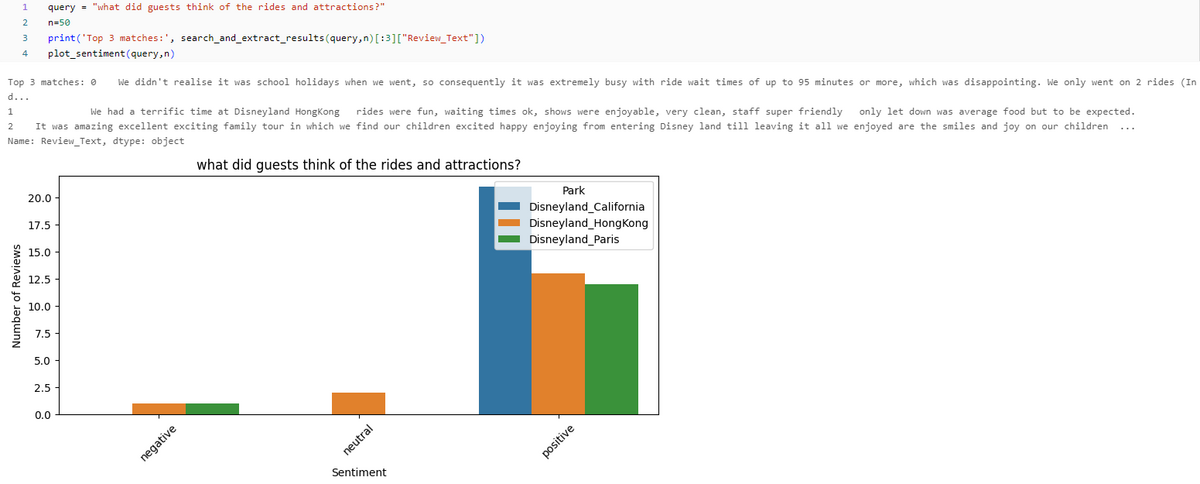
6. KDB.AIテーブルを削除する
テーブルの使用が終了したら、KDB.AIテーブルを削除することはベストプラクティスです。
まとめ
今回の投稿では Databricks 上で行った KDB.AI のサンプルコードである感情分析を Databricks 上で動かしました。 チャットボット履歴、カスタマー サービスの通話記録、顧客からの苦情メール、返品と返金のコメント、アンケートなどはすべてKDB.AI で早いスピードで分析できて顧客満足度を向上させるために活用できると思います。
最後までご覧いただきありがとうございます。
引き続きどうぞよろしくお願い致します!

私たちはDatabricksを用いたデータ分析基盤の導入から内製化支援まで幅広く支援をしております。 もしご興味がある方は、お問い合わせ頂ければ幸いです。
また、一緒に働いていただける仲間も募集中です!
APCにご興味がある方の連絡をお待ちしております。