
Introduction
This is Jung from the Lakehouse Department of the GLB Division.
In this article, I would like to introduce the sample code practice of KDB.AI that I introduced in the previous article.
KDB.AI is a Vector database powered by kdb+, the world's fastest time series database and analysis engine, and can be connected via Endpoint and API Key.
The Early Access Program was recently launched and you can try it out with a free account.
Instructions on how to create an account and Endpoints & API Keys can be found in the previous article. techblog.ap-com.co.jp
Please create an account, Endpoints, and API Keys to practice the sample code.
This time, we will introduce LangChain and RAG among the samples.
The order of the articles is the introduction of LangChain and RAG, how to create an OpenAI API Key and Hugging Face API Token, and the flow of sample code practice.
Contents
- Introduction
- Contents
- Introduction of sample code (LangChain and RAG)
- Advance preparation matters and preparation method
- Sample code practice
- Summary
Introduction of sample code (LangChain and RAG)
LangChain and RAG is a practice sample of similarity search using LangChain's text splitter and KDB.AI, and a practice sample of RAG that can answer user questions using external knowledge.
Load the TXT file used for LLM and use LangChain's text splitter to fit the loaded document into 500-sentence chunks. After making a list of each 500 sentence chunks and embedding them, we perform a distance-based similarity search using KDB.AI's similarity_search. Then, after creating a RAG using load_qa_chain and RetrievalQA, we ask the same questions as similarity_search and compare each result.
In the practical training, you will go through the following process.
➀ Load the TXT document using TextLoader and use LangChain's text splitter to fit the loaded document into 500-sentence chunks.
➁ Create a list of the 500 sentences created in ➀ and embedding it with an OpenAI model.
③ Create a table in KDB.AI and save the Embedding.
④ Search for the content you are interested in using KDB.AI's similarity_search.
➝ The most similar clusters of sentences will appear.
⑤ Create an LLM model using RAG's OpenAI and HuggingFaceHub.
⑥ Insert the group of chapters with the highest degree of similarity created in ④ into the LLM model created in ⑤ along with the questions in ④.
➝ Produce results based on external knowledge from OpenAI and HuggingFaceHub LLM models.
⑦Create a QA bot using RetrievalQA using GPT-3.5.
Enter KDB.AI's Vector Store in the method called as_retriever, which converts Vector Store into a search machine.
⑧ Input the question from ④ into the QA bot created in ⑦.
➝ Results based on KDB.AI's Vector Store and external knowledge.
Advance preparation matters and preparation method
For this exercise, you will need an OpenAI API Key and Hugging Face API Token.
Please create an OpenAI API Key and Hugging Face API Token in order to practice the sample code.
We will introduce how to create it below.
How to create an OpenAI API Key
- Create an account
➀ Create an account at the site below. platform.openai.com
Press the Sign up button on the homepage.
(If you already have an account, please log in and check "Create API Key".)

➁ Enter the email address and password you want to use.
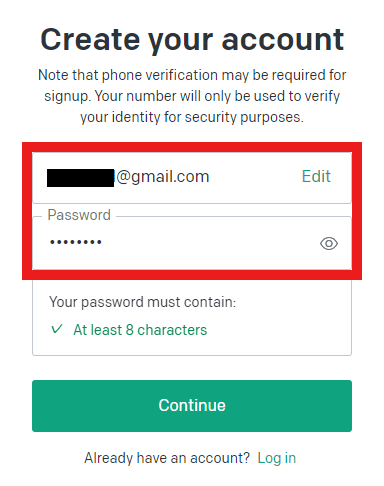
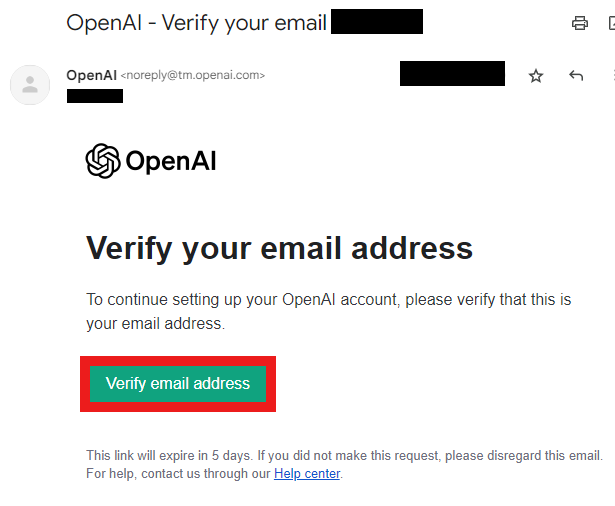
③ Verify your email.
(Open the email with the subject "OpenAI - Verify your email" and press the Verify email address button.)
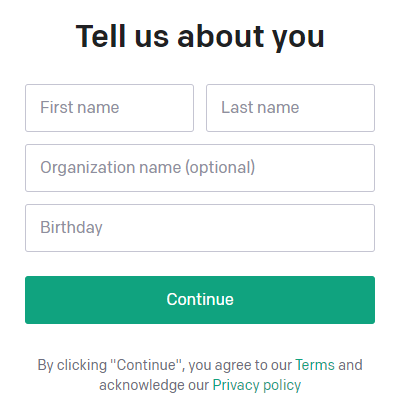
④ Return to the OpenAI homepage, log in again, and enter your personal information.
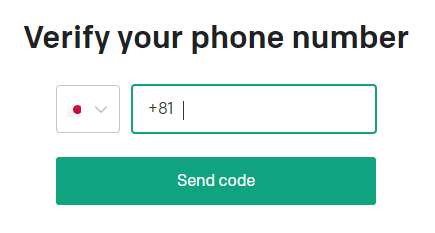
⑤ Once your phone number has been verified, your account will be created.
- Creating an API key
➀ Press your profile and then View API keys.
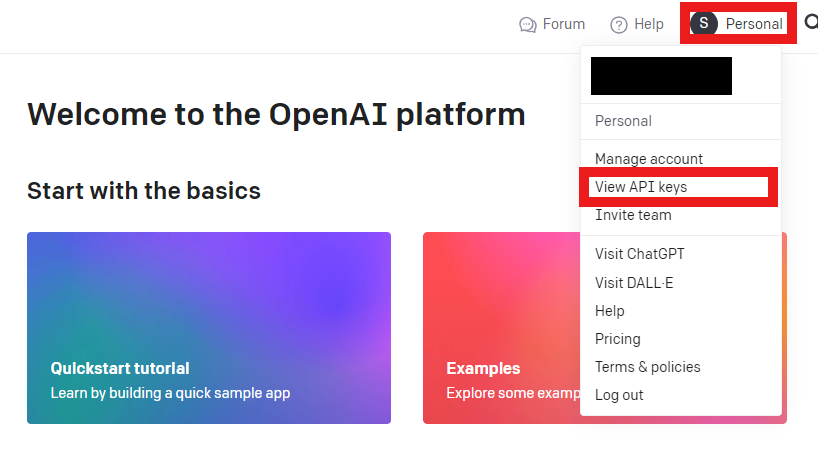
➁ Create an API key.
Press the Create new secret key button.
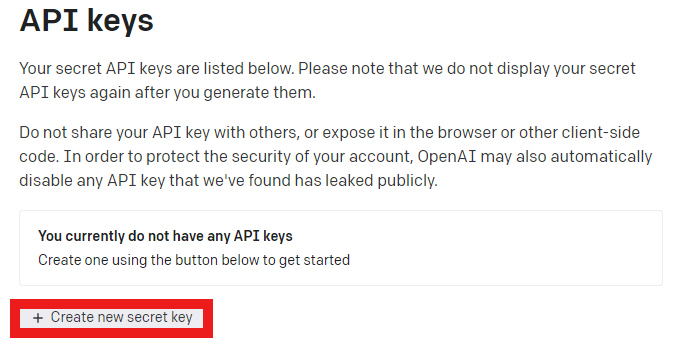
Create a name for your API key and press the Create new secret key button.
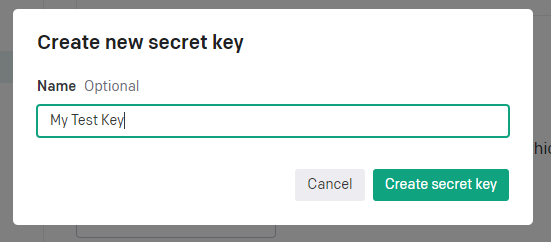
An API key will be created. (You will not be able to view it again, so please save it separately.)
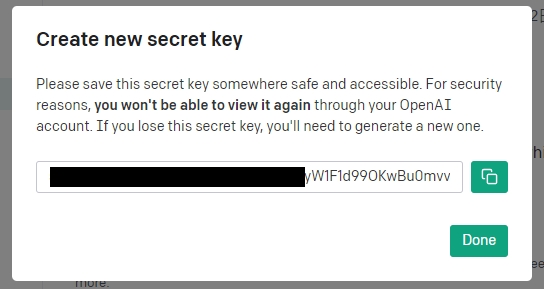
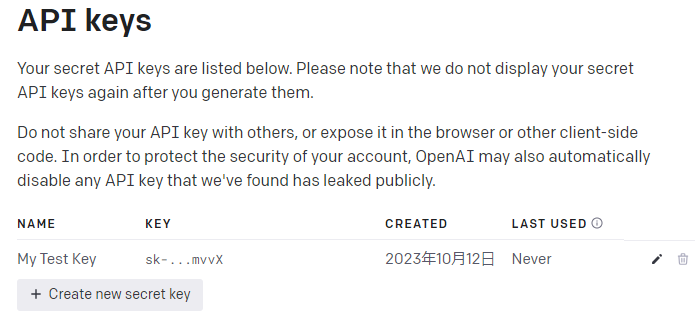
③ You can manage your API keys on the API Keys page.
You can rename or delete existing keys and create new keys.
How to create a Hugging Face API Token
- Create an account
➀ Create an account at the site below. huggingface.co
Press the Sign up button on the homepage.
(If you already have an account, please log in and check "Create API Key".)
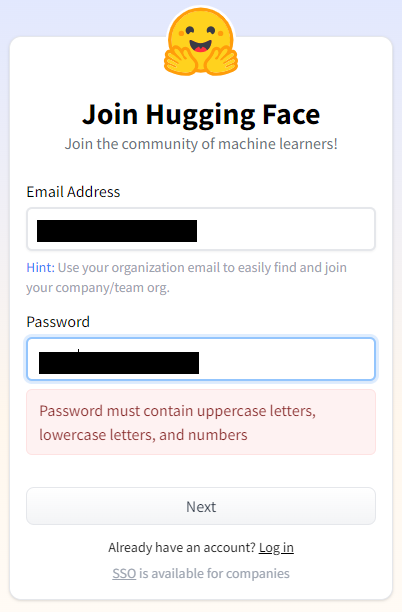
➁ Enter the email address and password you want to use.
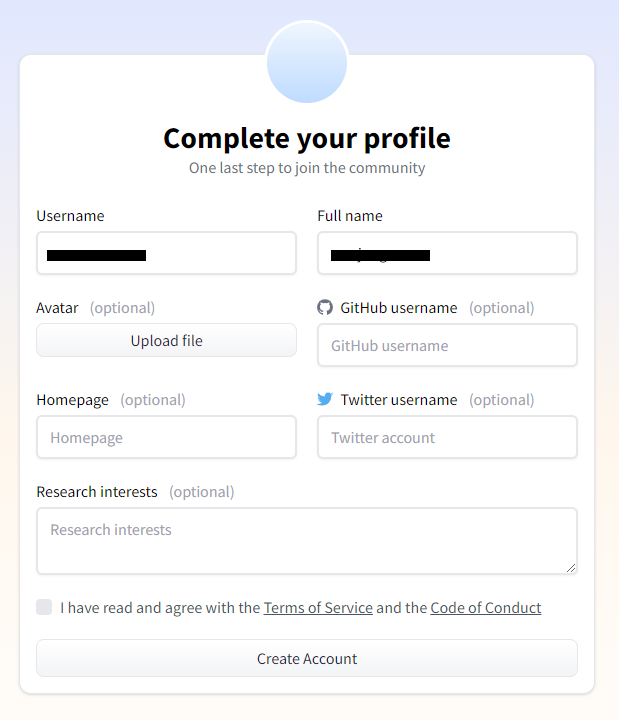
③ Create your own profile.
④ Verify your email.
Open the email with the subject line "[Hugging Face] Click this link to confirm your email address" and press the link to create an account.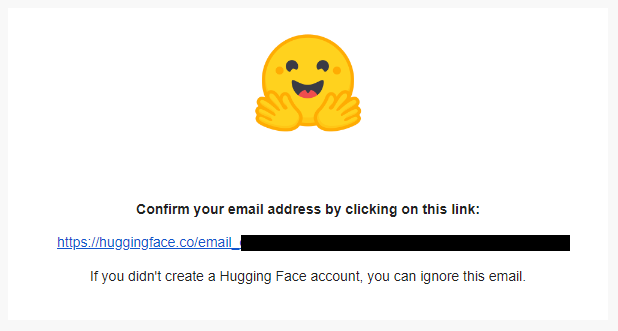
- Creating an API key
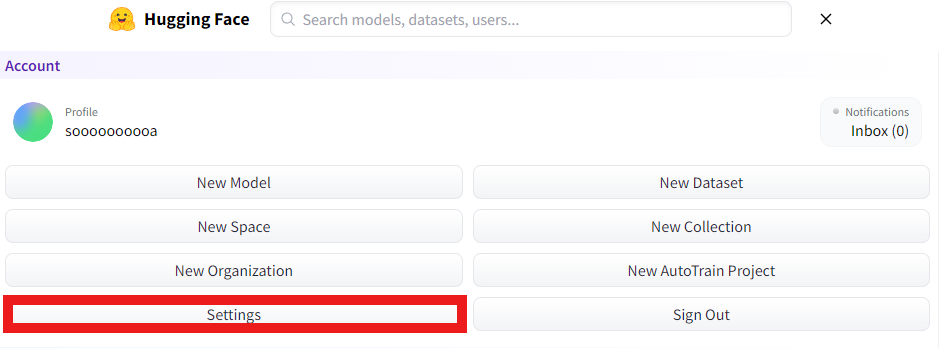
➀ After logging into Hugging Face, press the menu button.

➁ Press Settings.
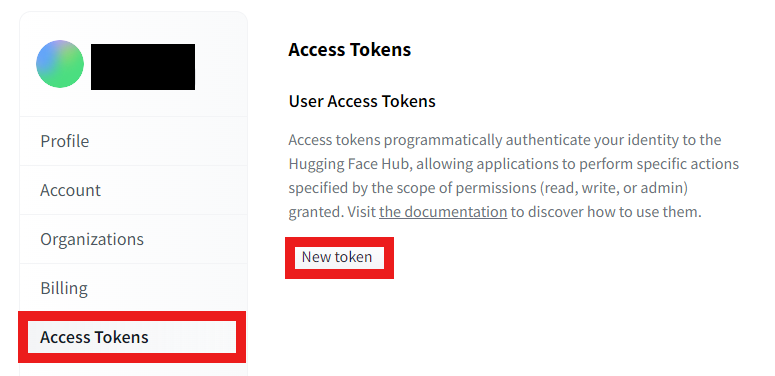
③ Press Access Tokens and then New token.
④ Create a token.
Create a Token name and select write for Role.
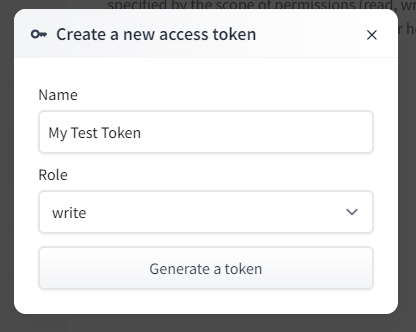
If you press Generate a token, a token will be created.
Sample code practice
The training was conducted using KDB.AI. kdb.ai
Let's try out the sample code on Databricks Workspace.
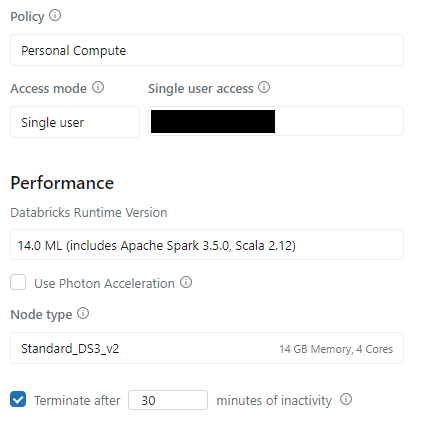
0. Databricks Cluster
Cluster uses 14.0 ML (includes Apache Spark 3.5.0, Scala 2.12). The above Cluster is Python3.10.12 version.
1. Installing Dependencies
Install some libraries.
%pip install pandas pyarrow openai pypdf tiktoken kdbai-client git+https://github.com/KxSystems/langchain.git@KDB.AI#subdirectory=libs/langchain -q
- Import the libraries you want to use.
# vector DB from getpass import getpass import os import pandas as pd import kdbai_client as kdbai
# langchain packages from langchain.chains import RetrievalQA from langchain.chat_models import ChatOpenAI from langchain.document_loaders import TextLoader from langchain.text_splitter import RecursiveCharacterTextSplitter from langchain.embeddings import OpenAIEmbeddings from langchain.vectorstores import KDBAI from langchain import HuggingFaceHub from langchain.llms import OpenAI from langchain.chains.question_answering import load_qa_chain
2. Setting API keys
Set the OpenAI API Key and Hugging Face API Token created above.
# OPENAI_API & HUGGINGFACEHUB KEYの接続 os.environ['OPENAI_API_KEY'] = getpass('OpenAI API Key: ') os.environ['HUGGINGFACEHUB_API_TOKEN'] = getpass('Hugging Face API Token: ')
Click the red box and enter your OpenAI API Key.

Once the OpenAI API Key is working properly, you can also create a Hugging Face API Token input window as shown below.
Click on the Hugging Face API Token input window and enter your Hugging Face API Token.

OpenAI API Key and Hugging Face API Token have been set.

3. Preparation of data
This time, we will use data from national policy messages sent by the US President to the US Congress. Load a TXT document.
- Load a TXT document using TextLoader.
- Documentation is to be requested from the LLM.
- Use LangChain's text splitter "RucursiveCharacterTextSplitter" to fit the read document into chunks of 500 sentences.
- List each group of 500 sentences.
- "Enter the TXT path in "My path where you uploaded the TXT".
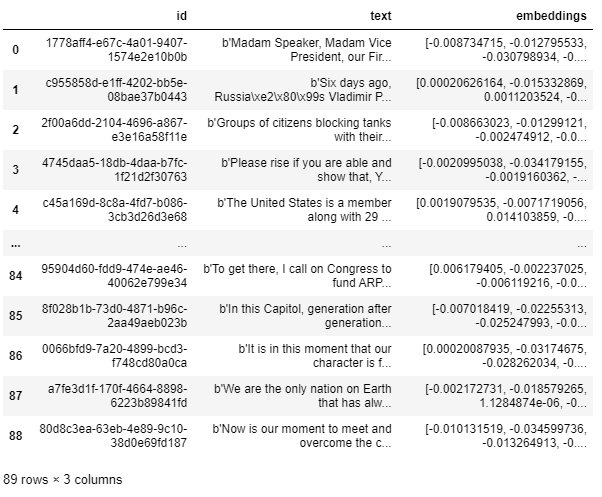
# Load TXT documents using TextLoader # Request documentation from LLM loader = TextLoader("My path where I uploaded the TXT") doc = loader.load() # Use langchain's text splitter "RucursiveCharacterTextSplitter" # Fit the entered documents into 500 sentence blocks text_splitter = RecursiveCharacterTextSplitter( chunk_size = 500, chunk_overlap = 0 ) # Fit loaded documents into chunks of 500 sentences chunks = text_splitter.split_documents(doc) # Make a list of 500 sentences texts = [p.page_content for p in chunks] # Check the data texts[0]

Make embeddings.
- Embedding represents text-like data as a single coordinate, and these values can be used for similar text searches, clustering, recommendation services, etc.
- Create an embedding using OpenAIEmbeddings.
- Select the "text-embedding-ada-002" model, which is recommended by OpenAI and has the characteristics of being easy and inexpensive.
embeddings = OpenAIEmbeddings(model='text-embedding-ada-002')
- Please check the link below for detailed explanation about Embedding and "text-embedding-ada-002". platform.openai.com
4. Save embedding to KDB.AI
Connect to KDB.AI Session using Endpoints and API Keys.
- How to create Endpoints and API Keys can be found in the previous blog.
"Enter your KDB.AI ENDPOINT in "My KDB.AI ENDPOINT".
"Enter your KDB.AI API KEY in "My KDB.AI API KEY".
import kdbai_client as kdbai KDBAI_ENDPOINT = "My KDB.AI ENDPOINT" KDBAI_API_KEY = "My KDB.AI API KEY" session = kdbai.Session(api_key=KDBAI_API_KEY, endpoint=KDBAI_ENDPOINT)
Define the schema of the KDB.AI table that stores the embedding.
Select the index and metric to use for search.
In this sample, we will use FLAT as index.
FLAT is a method that calculates the distance between all Vectors, so it may be less efficient, but it will find accurate values.
The similarity metric uses L2 of Euclidean distance.
Euclidean distance L2 calculates the distance of coordinates in high-dimensional space.
Please check the following page for details on the index handled by KDB.AI.
Please check the following page for details on the metrics handled by KDB.AI.
schema_rag = {
"columns": [
{"name": "id", "pytype": "str"},
{"name": "text", "pytype": "bytes"},
{
"name": "embeddings",
"pytype": "float32",
"vectorIndex": {"dims": 1536, "metric": "L2", "type": "flat"},
},
]
}
Create a table.
- Create the rag_langchain table with the session.create_table() function.
table = session.create_table('rag_langchain', schema_rag)
Enter Embedding into the table using KDBAI.from_texts.
vecdb_kdbai = KDBAI.from_texts(session, 'rag_langchain', texts=texts, embedding=embeddings)
table.query()
Embedding is now saved in KDB.AI, so you can perform semantic search.
5.Similarity search
Let's search for the points of interest in KDB.AI's Vector Store.
- The search uses Euclideandistance to calculate similarity.
- The most similar clusters of sentences will appear.
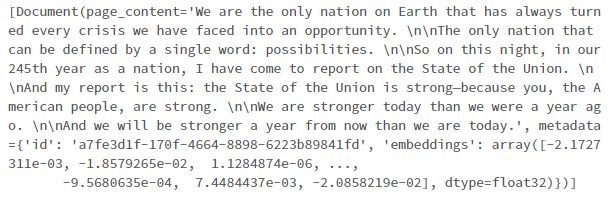
query = "what are the nations strengths?" query_sim = vecdb_kdbai.similarity_search(query) print(query_sim)
6. Retrieval-augmented Generation (RAG)
RAG is a technology that provides the latest information based on external knowledge when searching. In this sample, we will use load_qa_chain and RetrievalQA in RAG.
We asked the QA chatbot on the LangChain official website about the characteristics of the two methods.
load_qa_chain: load_qa_chain is a feature in the LangChain library that loads a preconfigured question answer chain using an LLM like OpenAI, which handles the prompts, LLM, etc. settings required for the QA chain.
RetrievalQA: A class in a rung chain that embodies a search-augmented QA architecture, combining a searcher and a reader LLM to answer questions.

➀ load_qa_chain with OpenAI and HuggingFaceHub Create an LLM model using OpenAI and HuggingFaceHub.
llm_openai = OpenAI(model="text-davinci-003", max_tokens=512) llm_flan = HuggingFaceHub(repo_id="google/flan-t5-xxl", model_kwargs={"temperature":0.5, "max_length":512})
Create a chain by applying load_qa_chain to the two models.
chain_openAI = load_qa_chain(llm_openai, chain_type="stuff") chain_HuggingFaceHub = load_qa_chain(llm_flan, chain_type="stuff") query = "what are the nations strengths?" #Find the most similar chapters query_sim = vecdb_kdbai.similarity_search(query) #Chain by model print("OpenAI Response: ") print(chain_openAI.run(input_documents=query_sim, question=query),'\n') print("HuggingFaceHub Response: ") print(chain_HuggingFaceHub.run(input_documents=query_sim, question=query))

➁ RetrievalQA using GPT-3.5 Create a QA bot using RetrievalQA.
- The query similarly uses "what are the nations strengths?".
- Enter KDB.AI's Vector Store in the method called as_retriever, which converts Vector Store into a search machine.
K = 10 qabot = RetrievalQA.from_chain_type(chain_type='stuff', llm=ChatOpenAI(model='gpt-3.5-turbo-16k', temperature=0.0), retriever=vecdb_kdbai.as_retriever(search_kwargs=dict(k=K)), return_source_documents=True) print(query) print("-----") print(qabot(dict(query=query))["result"])
The US President received an answer to the power of the nation based on the contents of the national policy message sent by the US Congress and external knowledge obtained through RetrievalQA.

7. Delete table
Delete the table.
table.drop()
![]()
Summary
In this post, I introduced the sample code of KDB.AI, LangChain and RAG, and the Databricks sample code exercise done on Databricks.
Through the practical training, I learned the following:
- How to use LangChain's text splitter "RucursiveCharacterTextSplitter" to fit the read document into a chunk of text
- How to create an LLM model for OpenAI and HuggingFaceHub through load_qa_chain
- How to create a QA bot using RetrievalQA
In the next post, I would like to test other KDB.AI sample codes on Databricks and introduce them as in this post.
Thank you for reading until the end. Thank you for your continued support!

We provide a wide range of support, from the introduction of data analysis platforms using Databricks to support for in-house production. If you are interested, please feel free to contact us.
We are also looking for people to work with us! We look forward to hearing from anyone interested in APC.
Translated by Johann