
Introduction
Hello, this is Chen from the Lakehouse Department of the GLB Division. The Lakehouse department is conducting verification using KDB.AI on the Databricks platform. An article by our company's Jung introduces KDB.AI and how to register to start using it. If you are interested, please see Jung's article.
In this article, we will introduce how to build and use a music recommendation system by coating it on Databricks. We will introduce the data acquisition from Kaggle (preliminary work) and coating on Databricks (main work) in order. For more details, please refer to KDB.AI's learning hub.
Contents
Preliminary work
This is an introduction to acquiring song data from Kaggle.
Get Music Data
We will use the music dataset provided by Sportify, which can be obtained from a data platform called Kaggle. The source is「Spotify dataset | Kaggle」
To obtain it, you will need to register as a Kaggle user. I will omit the details. Several files are included in the dataset, and only 「data.csv」will be used in this demo. In advance, upload 「data.csv」to Databricks' DBFS.
data.csv contains various information, and I will introduce the columns used in this demo. It is saved as a string, and columns related to song information use artists (artist name) and name (song name). During parsing, the strings contained in these columns will be vectorized. The columns related to melody are valence, acousticness, danceability, energy, instrumentalness, liveness, loudness mode, popularity, speechiness, and tempo. This information is saved as a numerical value, and each column is normalized in the analysis.
Main Work
We will coat it on the Databricks platform. We will introduce loading the necessary modules, preparing User Defined Functions (UDF), loading and formatting data, creating Vector Embedding, registering Vector DB on KDB.AI, and actual usage. We recommend using a cluster on Databricks that is 14.0ML or larger.
Preparing the Module
In Fig_1, we install the necessary libraries (gemsin and kdbai_client) and import modules (pandas, numpy, nltk, etc.).

Creating a UDF
Prepare a UDF in advance to check the contents of the data frame and embedding that will be created. "show_df" is a UDF that displays the data frame shape and data frame header. "show_embeddings" is a UDF that displays the total number, number of columns, and column names included in embeddings.

Loading and Formatting Data
As shown in Fig_3, after loading data.csv as a DataFrame, add the prefix "song_" in front of all column names. At the same time, delete unnecessary columns "song_id" and "song_release_date".

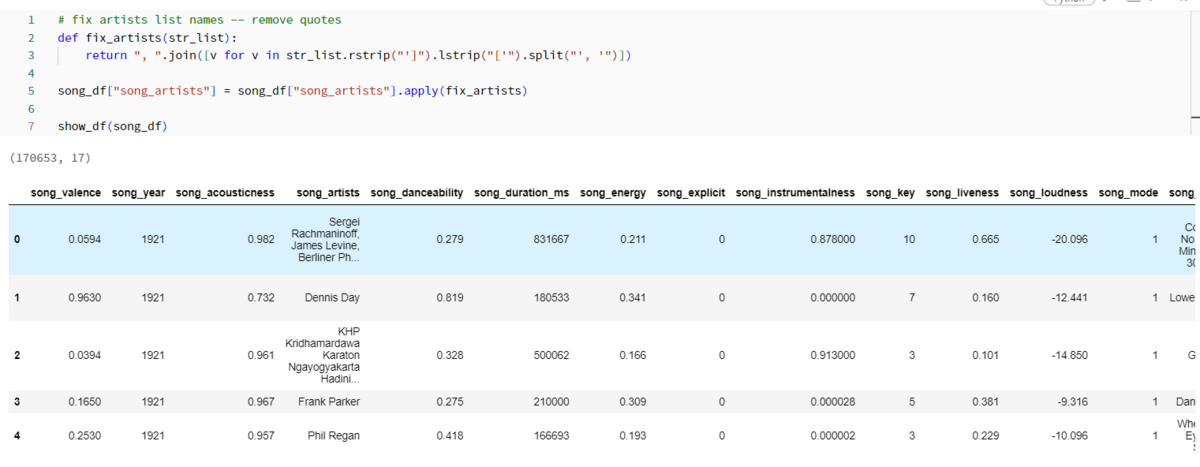
In Fig_4, delete the unnecessary characters " and " included in the column "song_artists". At the same time, join columns "song_name" and "song_artist" and create column "song_description". Finally, we removed duplicates and formatted the data.
Creating Vector Embeddings
Divide the sentence into meaningful units (Cmd19). In the case of English, most documents are divided into words using spaces as delimiters. As an example, a document like Cmd20 was broken down into words as shown in Cmd21.

Next, use Word2Vec to create an embedding model. This process is a natural language processing method that converts the words contained in a sentence into ``numeric vectors'' and understands their meaning. The results will change depending on the parameter settings, so if you are interested, please change the parameters and experience the changes in the results.

In Fig_7, tokenised_song_descs is added to the embedding model created in Fig_6, and the tokenised word group is vectorized. Put this vectorized word group into an array called categorical_embeddings.

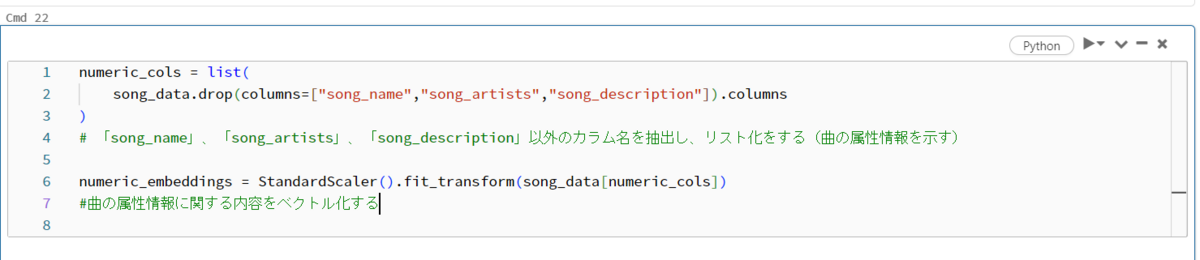
Fig_8 performs the work of standardizing and normalizing numerical data. First, remove the string columns ("song_name", "song_artists", "song_description") from the original table and create a new table (numerical_col). Normalize and standardize the numerical values in the table numerical_col and put them in numeric_embeddings as embeddings.
Combine the two embeddings created so far, "numeric_embeddings" and "categorical_embeddings" into one (Fig_9).

Finally, we left the "song_name", "song_artists", and "song_description" information as is and combined it with Embeddings, completing the preparation of the Embeddings database (Fig_10).

Create Vector Database on KDB.AI
Connect to KDB.AI Session
As shown in Fig_11, use Endpoint and API KEY to connect to KDB.AI. By entering and executing commands 1 to 3 in the cell, you will be asked to enter the Endpoint and API KEY. Please enter the appropriate information. If no errors occur, you will connect to KDB's Embedded Database on Databrics after the execution is complete.

Register Database on KDB.AI
Check the data type of each column of embedded_song_df created earlier. It contains four columns (song_name, song_artists, song_year, song_embeddings), and the types are clearly specified (Fig_12).

In Fig_13, a schema is defined based on columns and types. Please note that the column "song_embeddings" has a hierarchical structure and is defined differently than other columns.

Create a table (song) frame for the Database using the predefined schema. If the registration is successful, you can also check it on KDB.AI.

Next, write (insert) the data into the database. Before that, calculate the memory required for the table. We also adjust the chunk size. Finally, write the table created in Fig_14 to the database (Fig_15).

Try Using the Registered Database
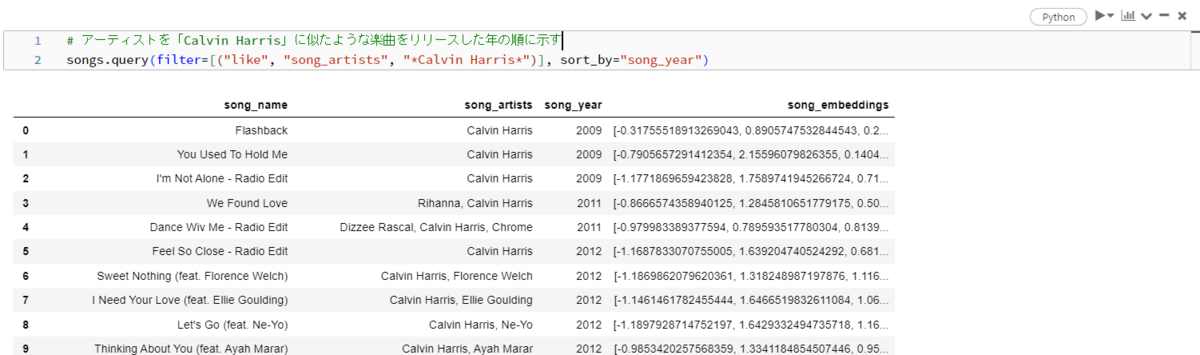
Ask for information by specifying the artist's name from the database. In this case, specify "Calvin Harris." Information about songs that include "Calvin Harris" is displayed in the artist column.
Additionally, ask for information by specifying the name of the artist and the name of the song. In Fig_17, the artist is added to "Calvin Harris" and the song is specified as "We Found Love." Information that matches the artist name and song name will be displayed as desired.

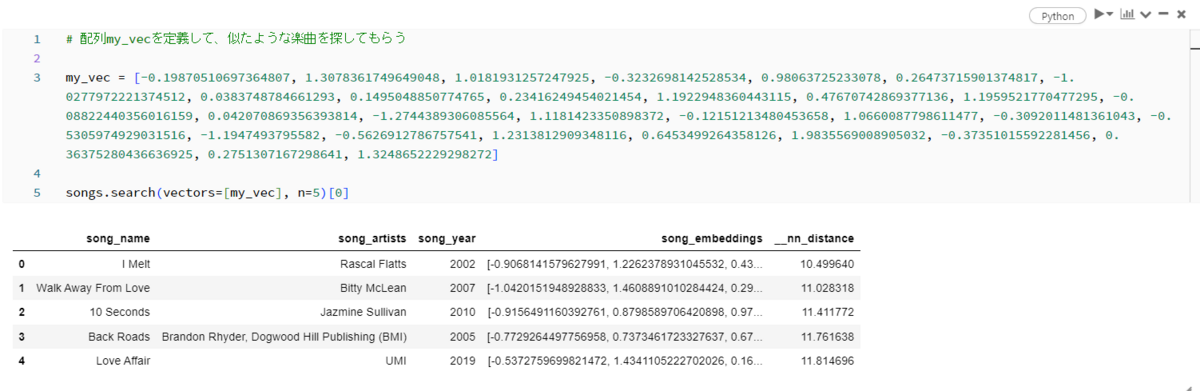
Finally, specify numerical values in an array as shown in Fig_18, specify that array as a vector, and ask them to show you songs similar to that array. You can see that information about various songs is displayed.
Song Recommendations
From here, we will create a function for recommending songs, and send a request to the function to have it recommend songs.
A recommendation function can be created as follows. If you specify the Embedded database to use and enter the artist name and song name, it will recommend songs with a similar atmosphere.

Use Function to make requests and have them recommend songs!
- How to use 1: Specify the song name and artist name and have the app recommend songs with a similar atmosphere (Fig_20)

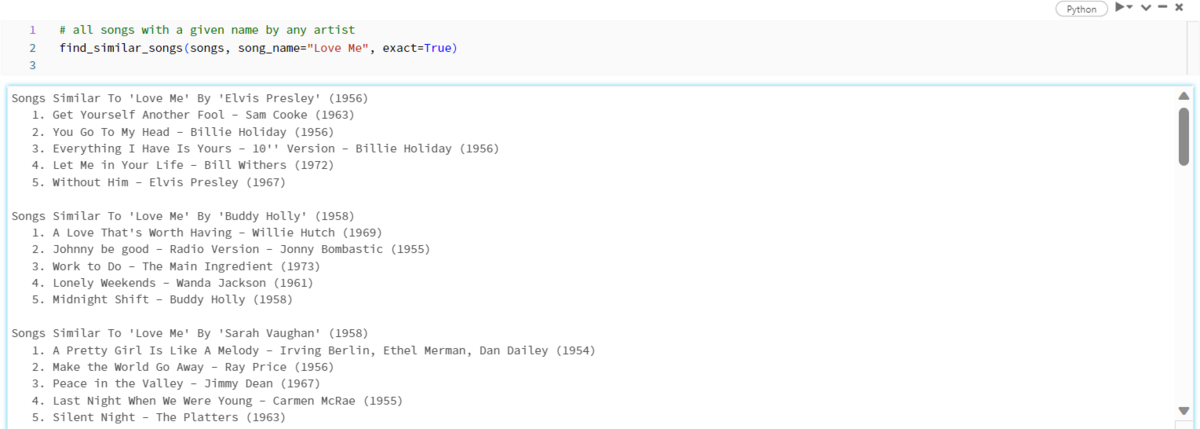
- Usage 2: Specify the song name and have the app recommend songs with a similar atmosphere (Fig_21)
Conclusion
That's all for this article. How was it? This article introduces the steps from acquiring data to registering a vector database on KDB.AI and creating a UDF that recommends songs. I think there are many other ways to use this as a reference. I would like anyone who is interested to try it out.

We provide a wide range of support using Databricks, from the introduction of data analysis platforms to in-house production support (https://www.ap-com.co.jp/service/data_ai/). If you are interested, please feel free to contact us.
We are also looking for people to work with us (https://www.ap-com.co.jp/recruit/info/requirements.html?utm_source=blog&utm_medium=article_bottom&utm_campaign=recruit)! We look forward to hearing from anyone interested in APC.
Translated by Johann