
はじめに
エーピーコミュニケーションズGLB事業部Lakehouse部の鄭(ジョン)です。
この記事ではFivetranのAWS Lambdaコネクターを利用して、データをDatabricksに送信する方法を紹介いたします。
今回使ったデータ送信方法は、S3経由方法です。
検証は、以下のFivetran公式ドキュメントを見ながら進めました。
fivetran.com
Fivetranでは、コネクタを使って多様なデータソースに対応できます。
概要は、以下の記事をご参考ください。
techblog.ap-com.co.jp
Fivetranを利用すれば簡単かつ迅速に多様なソースのマイグレーションが可能です。
興味がある方は、ご連絡いただければ幸いです。
目次
検証
検証の流れ
Lambdaコネクターを利用してLambdaからS3経由でDatabricksにテストデータを送信します。
検証の流れは以下の通りです。
➀ (AWS) S3を作成します。
② (Fivetran) Lambda Connectorを作成します。
③ (AWS) IAMのポリシーを作成します。
➃ (AWS/Fivetran) IAMのロールを作成します。
⑤ (AWS) Lambda関数を作成します。
⑥ (Fivetran) Lambda Connectorを完成させます。
⑦ (Databricks) データを送信します。
参考) 作成した名前(S3名など)をあとで入力することが多いので、メモしておいて進めると便利です。

検証の内容
➀ (AWS) S3の作成
AWSでS3バケットを作成します。
- 設定値はすべてデフォルト値です。

- バケット名をメモに残したら便利です。

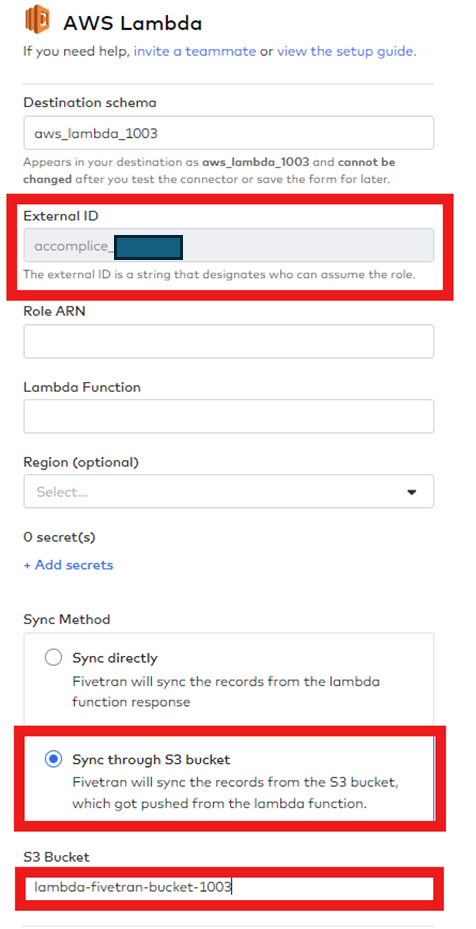
② (Fivetran) Lambda Connectorの作成
FivetranでLambda Connectorを作成します。
- Destination SchemaはDatabricksで使用するSchemaの名前です。(初期設定後の変更はできません。)
- External IDはAWSでFivetranと接続する際に使用するIDです。(External IDをメモに残したら便利です。)
- Sync MethodはS3の場合に設定します。
- S3 Bucketに生成したS3名を作成します。
③ (AWS) IAMのポリシーの作成
AWSでIAMのポリシーを作成します。
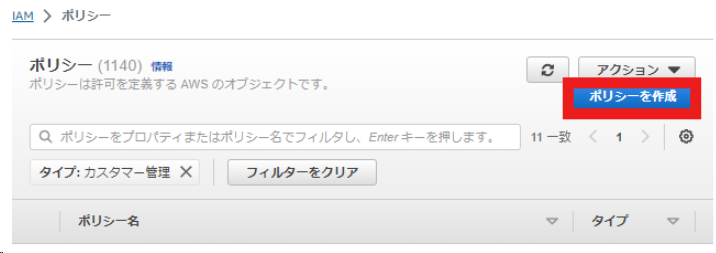
JSONにポリシーコードを作成します。(コードはイメージの下にあります。)

JSONコードはAWS Lambda Setup Guideにあります。
<bucket-name>に自分のS3名を入力します。
{ "Version": "2012-10-17", "Statement": [ { "Sid": "InvokePermission", "Effect": "Allow", "Action": "lambda:InvokeFunction", "Resource": "*" }, { "Sid": "AccessS3bucket", "Effect": "Allow", "Action": [ "s3:Put*", "s3:Get*", "s3:Delete*" ], "Resource": [ "arn:aws:s3:::<bucket-name>", "arn:aws:s3:::<bucket-name>/*" ] } ] }
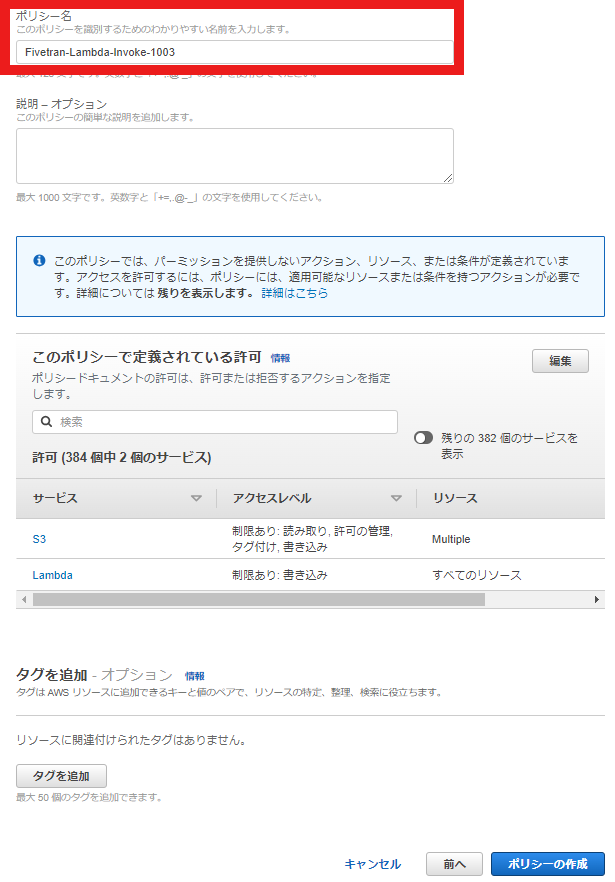
ポリシー名を作成した後、ポリシーを作成します。
ポリシー名をメモに残したら便利です。
➃ (AWS/Fivetran) IAMのロールの作成
AWSでIAMのロールを作成します。

- 信頼されたエンティティタイプにあるAWS アカウントを選択します。
- 別の AWS アカウントにFivetranアカウントのIDの834469178297を作成します。

許可に作成したポリシーを追加します。

ロール名を作成し、ポリシーが正しく設定されていることを確認します。
- ロール名をメモに残したら便利です。

- 作成したロールの管理ページに入り、信頼ポリシーを編集します。

JSONにポリシーコードを作成します。(コードはイメージの下にあります。)

JSONコードはAWS Lambda Setup Guideにあります。
- your_fivetran_externalIDに自分のFivetran External IDを入力します。
- 作成したFivetranのLambda Connectorにあります。
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Principal": { "AWS": "arn:aws:iam::834469178297:user/gcp_donkey" }, "Action": "sts:AssumeRole", "Condition": { "StringEquals": { "sts:ExternalId": "your_fivetran_externalID" } } }, { "Effect": "Allow", "Principal": { "Service": "lambda.amazonaws.com" }, "Action": "sts:AssumeRole" } ] }
- ロールのARNをFivetran ConnectorのRole ARNに入力します。


⑤ (AWS) Lambda関数の作成
AWSでLambda関数を作成します。
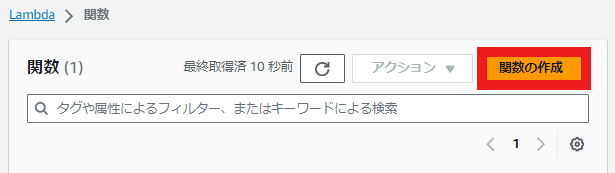
- 関数名を作成し、ランタイムはPython 3.10を選択します。
- 関数名をメモに残したら便利です。

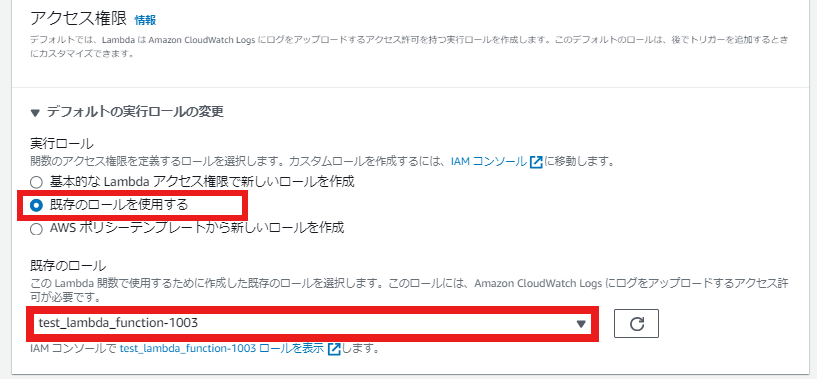
- デフォルトの実行ロールの変更の実行ロールを既存のロールを使用するで選択します。
- 既存のロールは作成したロールを選びます。
- lambda_functionにPythonコードを作成します。(コードはイメージの下にあります。)
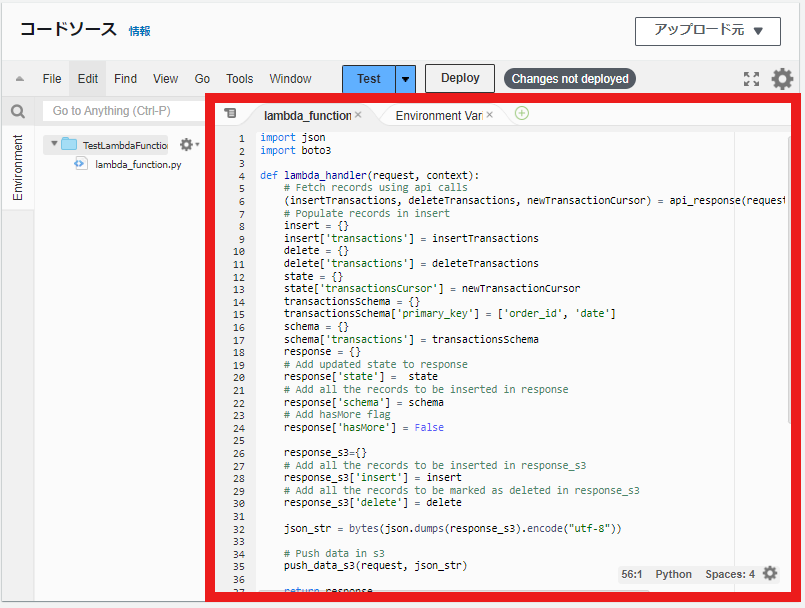
PythonコードはAWS Lambda Functions Data Connector By Fivetran | Example Lambda Functionsにあります。
Sync through S3 bucketのPythonコードを入力します。
関数からサンプル データを作成しています。
import json import boto3 def lambda_handler(request, context): # Fetch records using api calls (insertTransactions, deleteTransactions, newTransactionCursor) = api_response(request['state'], request['secrets']) # Populate records in insert insert = {} insert['transactions'] = insertTransactions delete = {} delete['transactions'] = deleteTransactions state = {} state['transactionsCursor'] = newTransactionCursor transactionsSchema = {} transactionsSchema['primary_key'] = ['order_id', 'date'] schema = {} schema['transactions'] = transactionsSchema response = {} # Add updated state to response response['state'] = state # Add all the records to be inserted in response response['schema'] = schema # Add hasMore flag response['hasMore'] = False response_s3={} # Add all the records to be inserted in response_s3 response_s3['insert'] = insert # Add all the records to be marked as deleted in response_s3 response_s3['delete'] = delete json_str = bytes(json.dumps(response_s3).encode("utf-8")) # Push data in s3 push_data_s3(request, json_str) return response def api_response(state, secrets): # your api call goes here insertTransactions = [ {"date":'2017-12-31T05:12:05Z', "order_id":1001, "amount":'$1200', "discount":'$12'}, {"date":'2017-12-31T06:12:04Z', "order_id":1001, "amount":'$1200', "discount":'$12'}, ] deleteTransactions = [ {"date":'2017-12-31T05:12:05Z', "order_id":1000, "amount":'$1200', "discount":'$12'}, {"date":'2017-12-31T06:12:04Z', "order_id":1000, "amount":'$1200', "discount":'$12'}, ] newTransactionCursor='2018-01-01T00:00:00Z' return (insertTransactions, deleteTransactions, newTransactionCursor) #Function to store data in s3 def push_data_s3(request, json_str): client = boto3.client('s3') client.put_object(Body=json_str, Bucket=request["bucket"], Key=request["file"])
- Deployを押してTestを押します。

- イベント名とJSONコードを作成します。(コードはイメージの下にあります。)
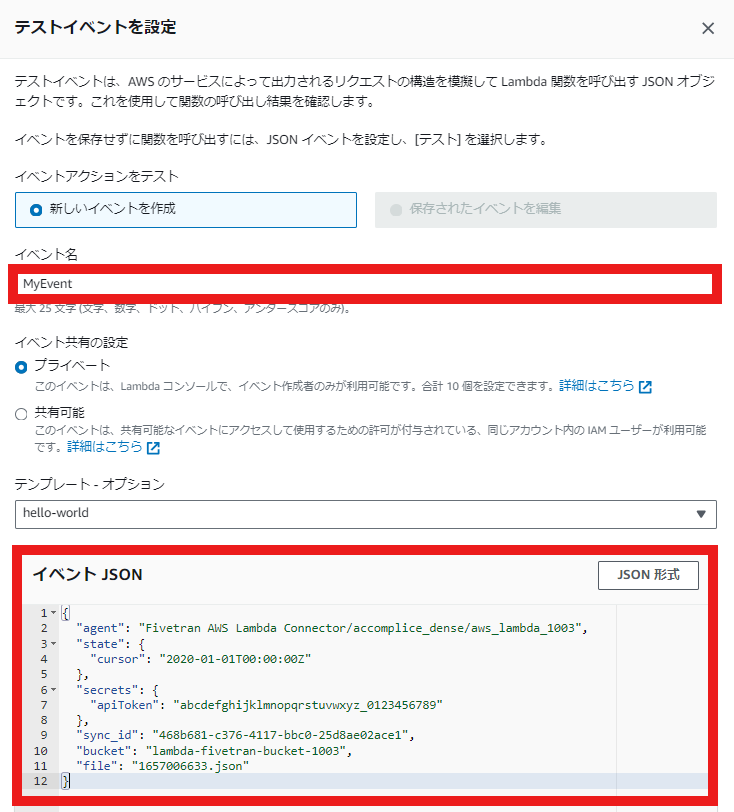
- JSONコードはAWS Lambda function for analytics infrastructure | Fivetranにあります。
- s3-test-bucketに作成したS3名を作成します。
- <external_id>に自分のFivetran External IDを入力します。
- <schema_name>に自分のFivetran Destination schemaを入力します。
{ "agent" : "Fivetran AWS Lambda Connector/<external_id>/<schema_name>", "state": { "cursor": "2020-01-01T00:00:00Z" }, "secrets": { "apiToken": "abcdefghijklmnopqrstuvwxyz_0123456789" }, "customPayload": { "samplePayload": "payload_value" }, "sync_id": "468b681-c376-4117-bbc0-25d8ae02ace1", "bucket": "s3-test-bucket", "file": "1657006633.json" }
- 作成完了後、再びTestを押した時、Errorが発生しなかったら、Lambda関数がうまく作成されたはずです。

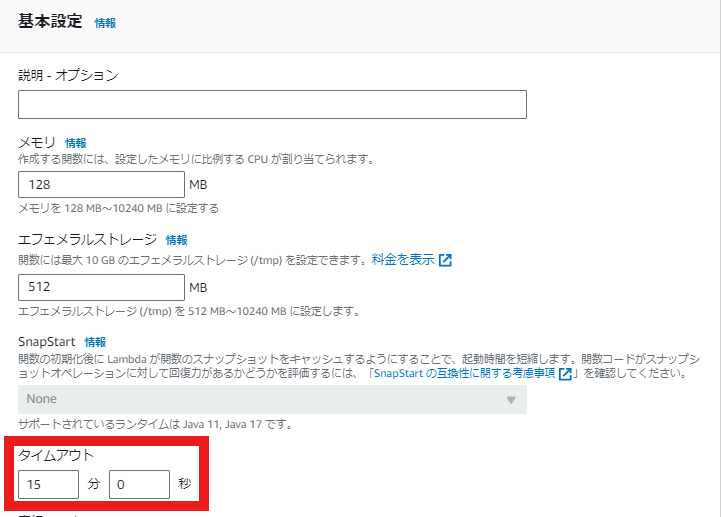
- Lambda関数の設定でタイムアウト時間を変更します。(時間を増やさないとダッシュボードでErrorが発生する可能性があります。)
⑥ (Fivetran) Lambda Connectorの完成
FivetranでLambda Connectorを完成させます。
- Lambda関数名を入力し、AWSのRegionを選びます。
- Sync MethodはS3の場合に設定します。
- S3 Bucket上で生成したS3人を作成します。
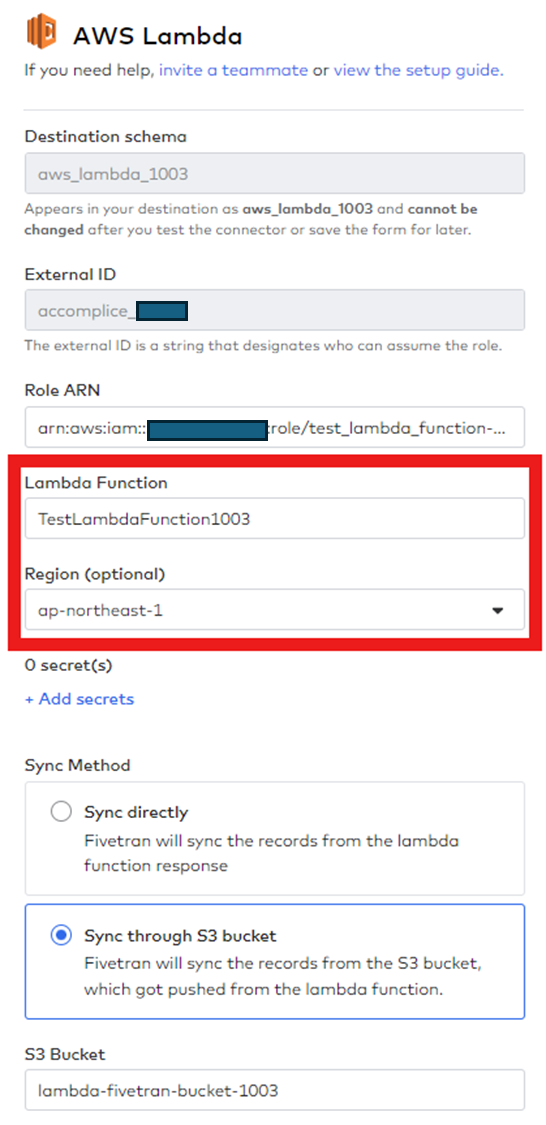
- Syncをします。

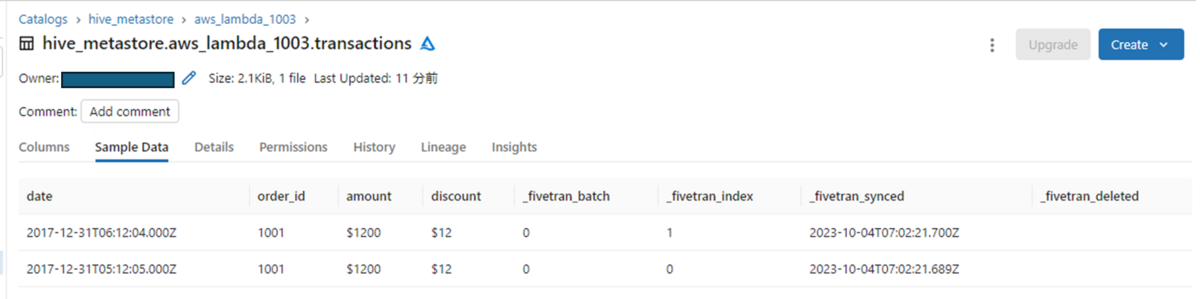
⑦ (Databricks) データの送信
Databricksにデータが作成されます。
- Fivetranを通じて自動的にLambdaからS3経由でDatabricksにテストデータを送信しました。
まとめ
今回の記事では、FivetranのAWS Lambda Connectorを利用してDatabricksにデータを送信する方法について調べてみました。
この機能を利用すれば、Lambdaで作成したデータをDatabricksに送信することができます。
ご興味のある方にお役に立てれば幸いです。
最後までご覧いただきありがとうございます。
引き続きどうぞよろしくお願い致します!

私たちはDatabricksを用いたデータ分析基盤の導入から内製化支援まで幅広く支援をしております。
もしご興味がある方は、お問い合わせ頂ければ幸いです。
また、一緒に働いていただける仲間も募集中です!
APCにご興味がある方の連絡をお待ちしております。