
はじめに
エーピーコミュニケーションズGLB事業部Lakehouse部の鄭(ジョン)です。
この記事ではFivetranのHashed機能を利用して、データを簡単にマスキングする方法を紹介いたします。
検証は、Fivetranを通じてDatabricksにアップロードされたデータにある特定のカラムをマスキングします。
Fivetranでは、コネクタを使って多様なデータソースに対応できます。
Fivetranを通じてDatabricksにデータをアップロードする方法は、以下の記事をご参考ください。
以下の方法以外に、多様なソースのマイグレーションが可能です。
興味がある方は、ご連絡いただければ幸いです。
目次
検証
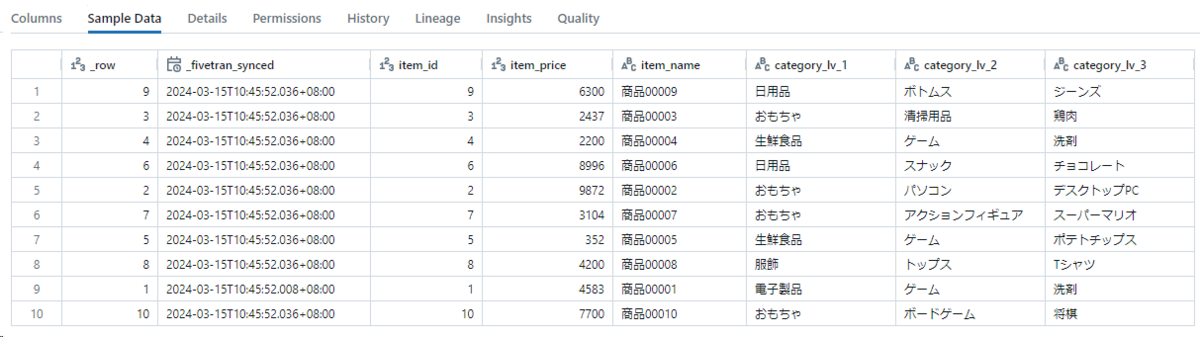
Fivetranを利用してDatabricksにアップロードしたデータです。まだHashed前です。
コネクタのSchemaでHashedの設定が可能です。
カラムの「category_lv_1」にHashedを設定した後、保存します。
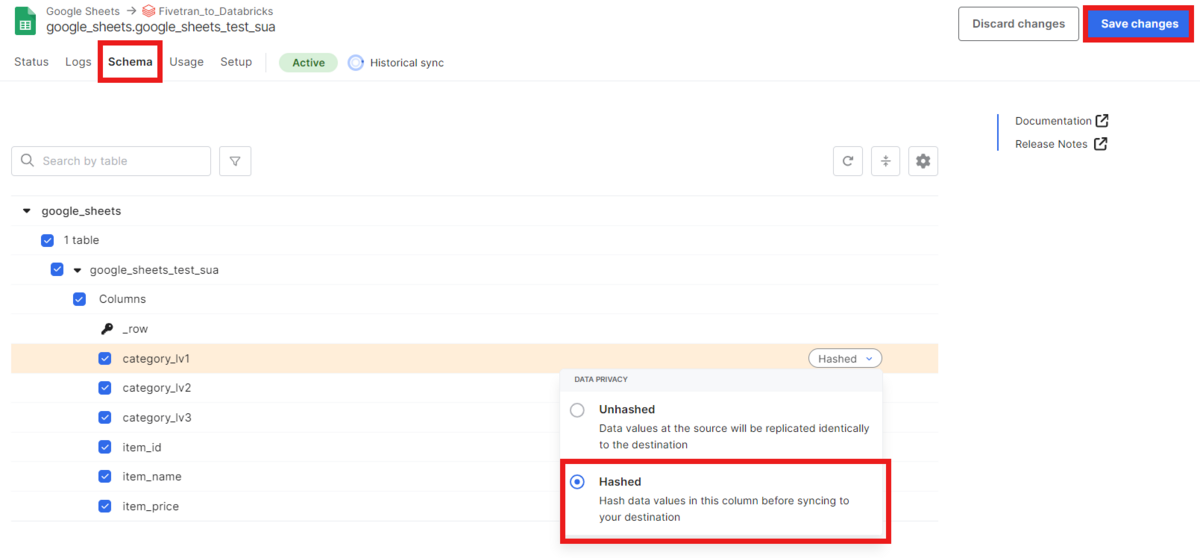
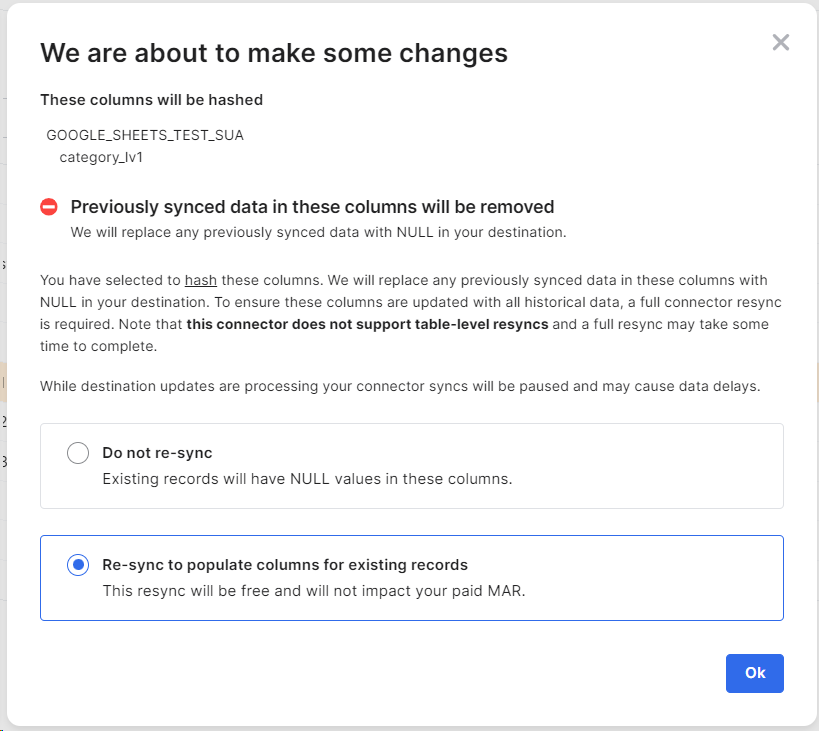
Re-syncを利用すると、Hashedをすぐに適用することができます。
後で適用を希望する方は、Do not re-syncを選択し、希望する時にsyncを起動するとHashedが適用されます。
Hashed設定の表記は、Schemaで引き続き確認することができます。
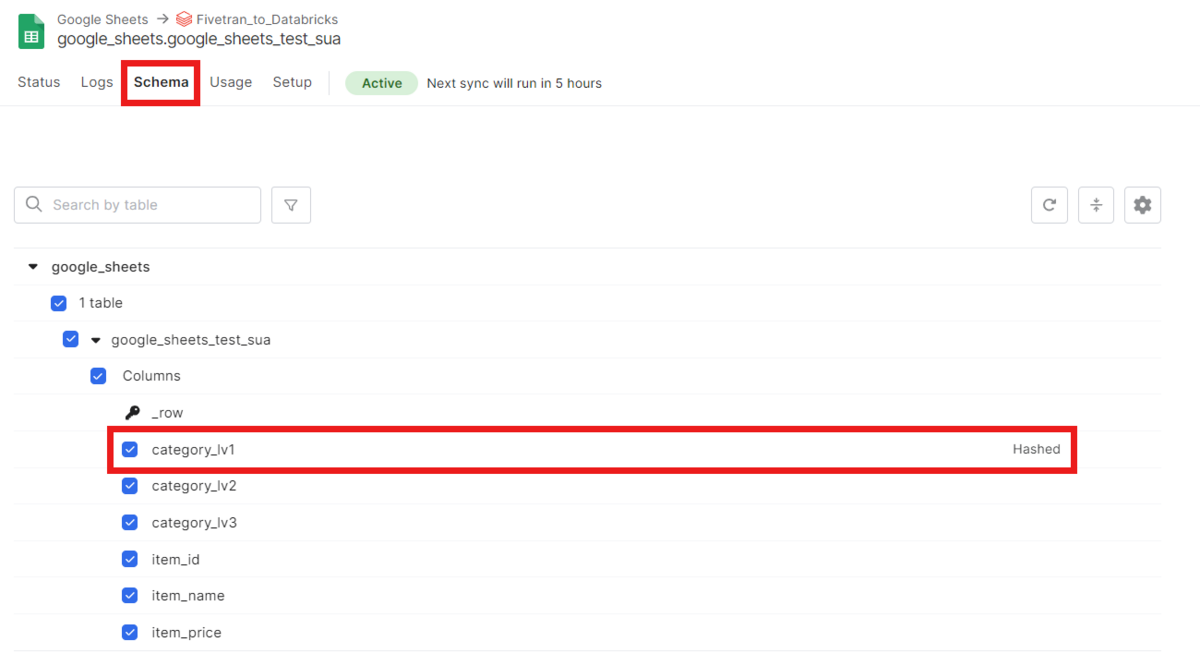
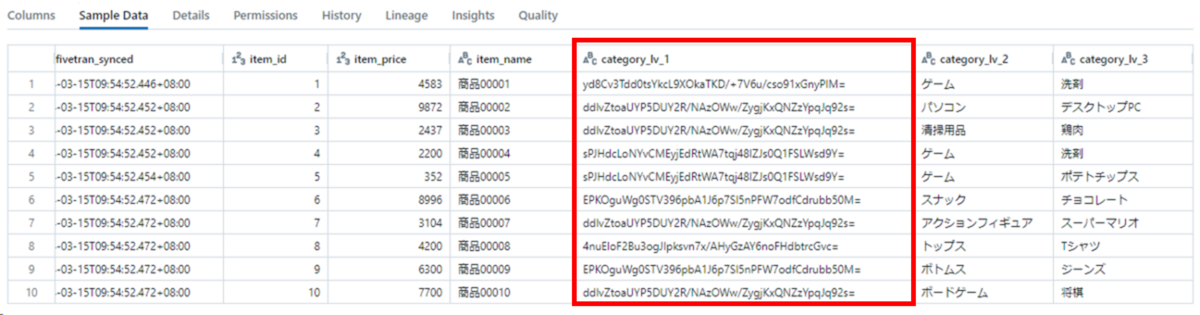
syncが終わったら、Databricks上のサンプルデータの「category_lv_1」がmasking処理されます。
まとめ
今回の記事では、FivetranのHashed機能を利用したデータマスキングについて調べてみました。
この機能を利用すれば、ノーコーディングでも簡単にデータをマスキングできます。
ご興味のある方にお役に立てれば幸いです。
最後までご覧いただきありがとうございます。
引き続きどうぞよろしくお願い致します!

私たちはDatabricksを用いたデータ分析基盤の導入から内製化支援まで幅広く支援をしております。
もしご興味がある方は、お問い合わせ頂ければ幸いです。
また、一緒に働いていただける仲間も募集中です!
APCにご興味がある方の連絡をお待ちしております。