
はじめに
エーピーコミュニケーションズGLB事業部Lakehouse部の鄭(ジョン)です。
この記事ではCDC(チェンジデータキャプチャ)について紹介致します。
そして、DatabricksとFivetranのCDC検証を行います。
効率的なパイプライン設計について興味がある方にお勧めします。
目次
CDC(チェンジデータキャプチャ)
概念および長所
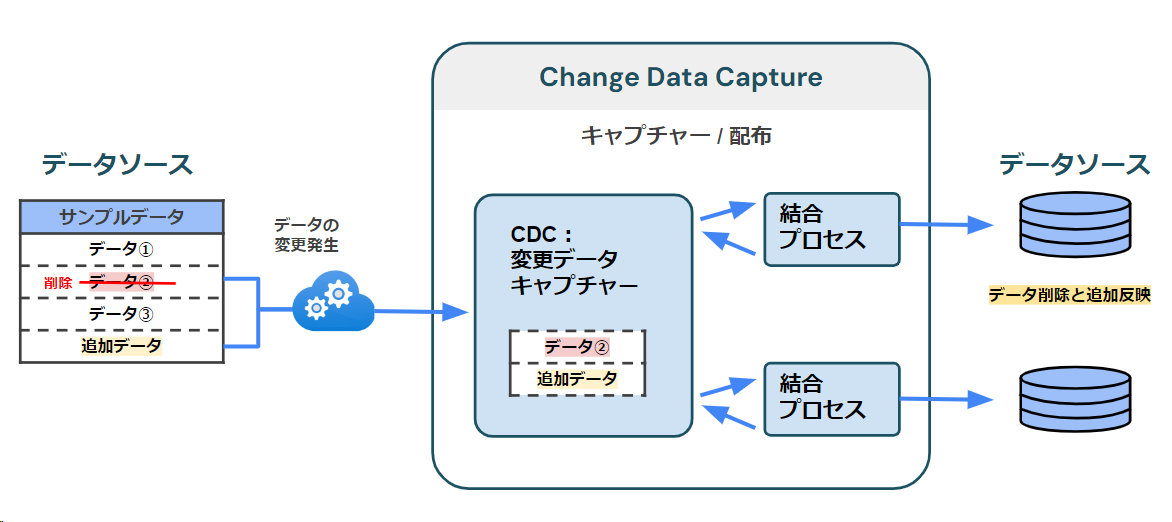
CDCは変更データをキャプチャする技術で、データエンジニアリングの核心技術の 1 つです。
データベースの変更(挿入、更新、削除)をリアルタイムで識別し、それを他のシステム(データ ウェアハウス、データ レイクなど)に転送します。
全体を再送信するのではなく、変更された部分だけを変更することができるため、効率的なパイプラインを構築できます。
また、データの変化をリアルタイムで同期できるため、すべてのシステムの一貫性を維持するのに役立ちます。
これにより、データの正確性が保証され、データの問題(重複など)を解決することができます。
方法
チェンジ データ キャプチャには多様な方法があります。 そのうち、Fivetranのブログを引用して4つの方法を紹介します。 (ログベースCDC、トリガーベースCDC、タイムスタンプベースCDC、差異ベースCDC)
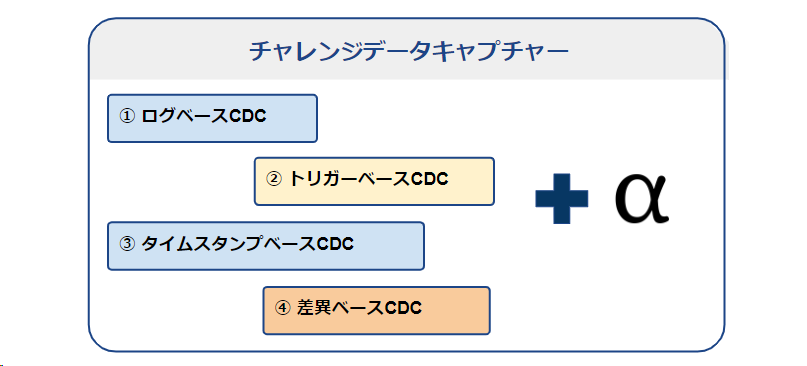
➀ ログベースCDC
トランザクションのログを利用して変更を記録します。
OLTP(オンライントランザクション処理用)で構築されたほとんどのデータベースが利用可能です。
システムまたはデータベースのクラッシュが発生した場合、トランザクション ログを使用すると、損失なく回復できます。
② トリガーベースCDC
変更が発生するとすぐに、該当事項を別のテーブルに記録します。
変更事項をすべて記録する方式と行の識別キーと変更タイプ(挿入、更新、削除)だけを記録する方式があります。
ログベースの方法が開発される前によく使用した方法で、大容量のデータベースが発生します。
③ タイムスタンプベースCDC
変更が発生した時間をLAST_MODIFIEDみたいな列に記録する方式です。
タイムスタンプに基づいて直近に変更されたデータを抽出できます。 行が削除される場合は、追跡できません。
➃ 差異ベースCDC
データのスナップショットに基づいて、すべてのデータに対する代入比較を通じて変更を識別します。 全体の違いを分析するために、すべてのデータが必要です。
詳細は以下のURLをご参考ください。
ユースケース
CDCのリアルタイム変更データキャプチャ機能がどのような状況で使用されているかを紹介致します。
➀ リアルタイムデータ統合
複数のデータ ソースからデータを収集し、単一のデータストアに保存する時に使用します。
リアルタイムで変更を検出するため、データの一貫性を維持するのに役立ちます。
② データマイグレーションおよび複製
データを新しいプラットフォームに移動する際、リアルタイムで新しいシステムを複製しながら、既存のシステムも運用できます。
データ損失を最小限に抑えながら、データの整合性を維持できます。
➂ リアルタイムイベント処理
注文、決済処理などの重要イベントをリアルタイムで感知し、在庫管理などの作業にリアルタイムで反映します。
➃ 監査および規制準拠
すべてのデータ変更を記録し、監査ログを生成します。
これは、金融サービスやヘルスケアのような厳しいデータ管理が必要な産業に役立ちます。
監査ログにより、いつ、なぜ、誰によって変更されたかがわかります。
検証
DatabricksとFivetranが上記のようなCDC機能を提供します。
Databricksの検証
Databricksは、デルタライブテーブルにAPPLY CHANGES APIを利用して、チェンジデータ キャプチャ (CDC) が簡単になります。
APPLY CHANGES APIは、SCD Type 1とSCD Type 2を使用します。
- SCD Type 1: 変更履歴を保持せずにレコードを直接変更
- SCD Type 2: 変更履歴を保持して全てまたは特定なカラムに対してレコードを変更
SCD Typeの詳細は以下のURLをご参考ください。
検証は、以下の公式ドキュメントに従っています。 learn.microsoft.com
テストデータの作成
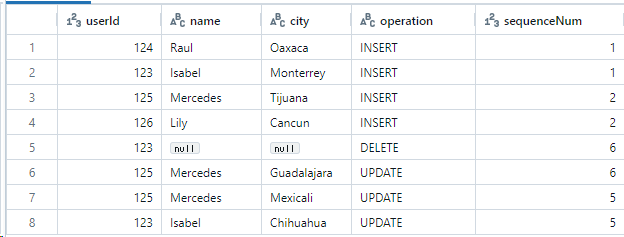
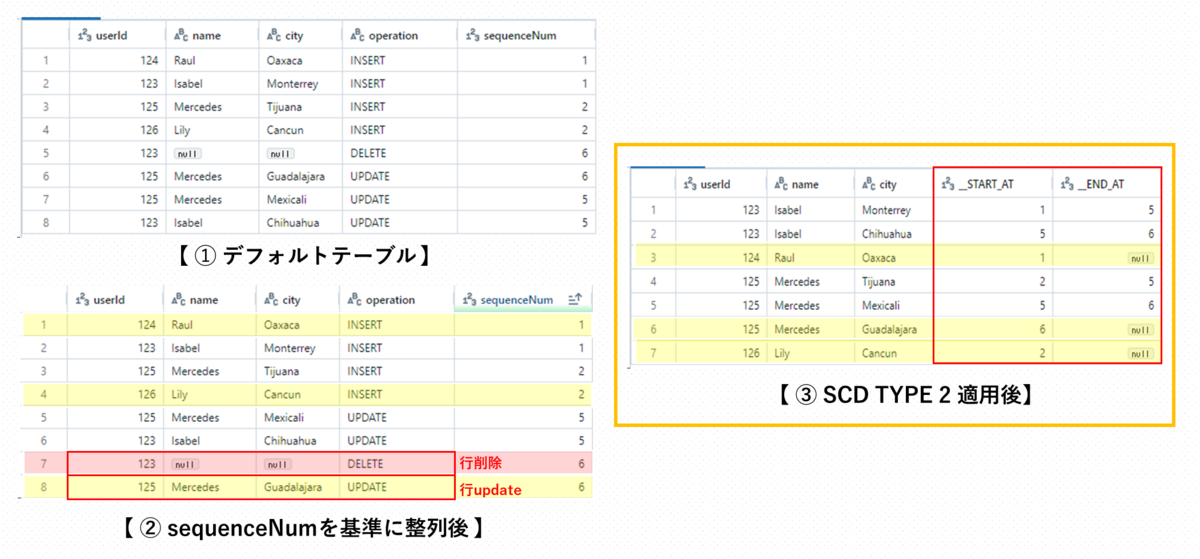
CREATE SCHEMA IF NOT EXISTS cdc_data; CREATE TABLE cdc_data.users AS SELECT col1 AS userId, col2 AS name, col3 AS city, col4 AS operation, col5 AS sequenceNum FROM ( VALUES -- Initial load. (124, "Raul", "Oaxaca", "INSERT", 1), (123, "Isabel", "Monterrey", "INSERT", 1), -- New users. (125, "Mercedes", "Tijuana", "INSERT", 2), (126, "Lily", "Cancun", "INSERT", 2), -- Isabel is removed from the system and Mercedes moved to Guadalajara. (123, null, null, "DELETE", 6), (125, "Mercedes", "Guadalajara", "UPDATE", 6), -- This batch of updates arrived out of order. The above batch at sequenceNum 5 will be the final state. (125, "Mercedes", "Mexicali", "UPDATE", 5), (123, "Isabel", "Chihuahua", "UPDATE", 5) -- Uncomment to test TRUNCATE. -- ,(null, null, null, "TRUNCATE", 3) );
- 8つのサンプルデータを作成
- 初期データ2件、ユーザー追加2件、データ変更2件、以前より小さいsequenceNum追加2件
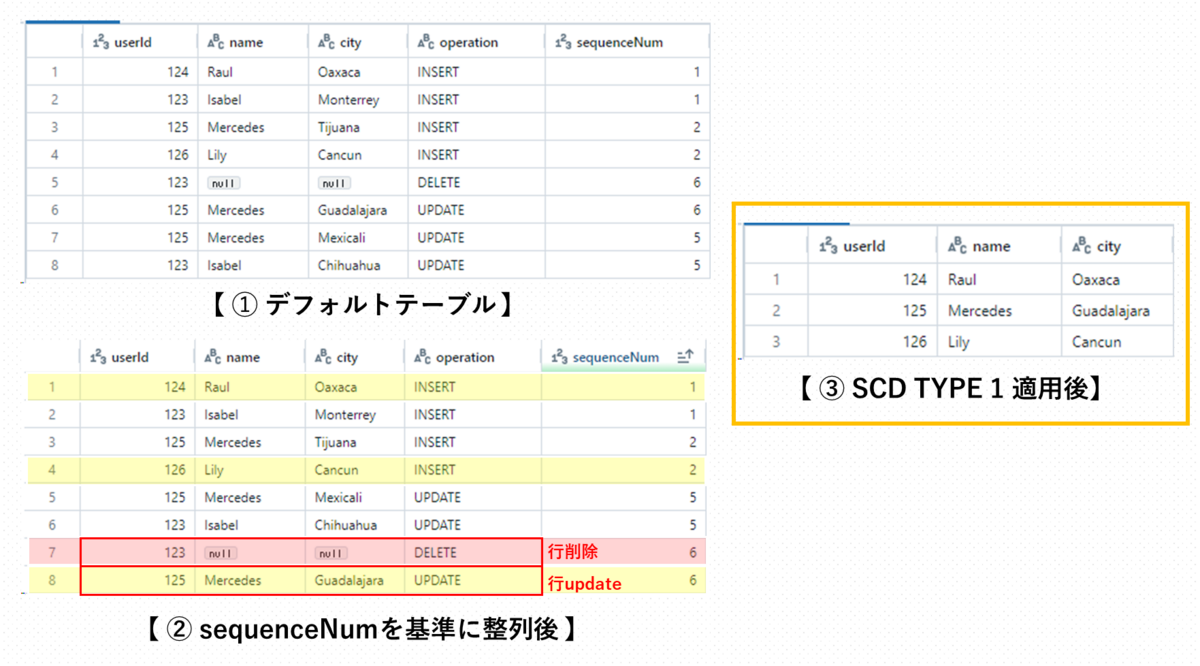
SCD Type 1
- APPLY CHANGES INTOはデルタライブテーブルを利用します。
- SCD Type 1: 変更履歴を保持せずにレコードを直接変更
-- Create and populate the target table. CREATE OR REFRESH STREAMING TABLE target; APPLY CHANGES INTO live.target FROM stream(cdc_data.users) KEYS (userId) APPLY AS DELETE WHEN operation = "DELETE" APPLY AS TRUNCATE WHEN operation = "TRUNCATE" SEQUENCE BY sequenceNum COLUMNS * EXCEPT (operation, sequenceNum) STORED AS SCD TYPE 1;
- userIdをキーとしてチェンジキャプチャ
- operationカラムが「DELETE」なら行削除、「TRUNCATE」ならテーブル削除
- sequenceNumを基準に論理的順序を指定
- operation、sequenceNumを除くすべてのカラムを使用して、SCD TYPE 1でテーブル作成
- userIdが124、125、126のデータを保存
SCD Type 2
- APPLY CHANGES INTOはデルタライブテーブルを利用します。
- SCD Type 2: 変更履歴を保持して全てまたは特定なカラムに対してレコードを変更
-- Create and populate the target table. CREATE OR REFRESH STREAMING LIVE TABLE target2; APPLY CHANGES INTO live.target2 FROM stream(cdc_data.users) KEYS (userId) APPLY AS DELETE WHEN operation = "DELETE" SEQUENCE BY sequenceNum COLUMNS * EXCEPT (operation, sequenceNum) STORED AS SCD TYPE 2;
- userIdをキーとしてチェンジキャプチャ
- operationカラムが「DELETE」なら行削除
- sequenceNumを基準に論理的順序を指定
- operation、sequenceNumを除くすべてのカラムを使用して、SCD TYPE 2でテーブル作成
- START_AT、END_ATカラムが追加される
- START_AT、END_ATカラムを利用してデータのバージョンを管理できる(始まりと終わりがわかる)
- 有効なデータはEND_ATがnull
Fivetranの検証
Fivetranは、Soft Delete ModeとHistory Modeを利用して、チェンジデータ キャプチャ (CDC) が簡単になります。
テーブルのprimary keyに基づいてCDCを実行を実行します。
primary keyがない場合はエラーが発生します。
- Soft Delete Mode: 変更履歴を保持して削除をキャプチャーする
- History Mode: SCD Type 2を基づいて変更履歴を保持して全てまたは特定なカラムに対してレコードを変更
Soft Delete Mode
検証は、以下の公式ドキュメントに従っています。
- 前提条件:AWS RDSを使用しており、FivetranのMySQL RDSコネクタを利用してDatabricksにデータを移行している
- Soft Delete Mode: 変更履歴を保持して削除をキャプチャーする
MySQLでテストデータを作成します。
- COUNTSカラムに3がある
-- choose schema USE fivetran_cdc; -- create table CREATE TABLE fivetran_cdc.soft_delete ( COUNTS INT, PRIMARY KEY (COUNTS) ); -- insert data INSERT INTO soft_delete (COUNTS) VALUES (3);
コネクターのスキーマページで対象テーブルのTABLE SYNC MODEをSoft delete modeにして同期化します。
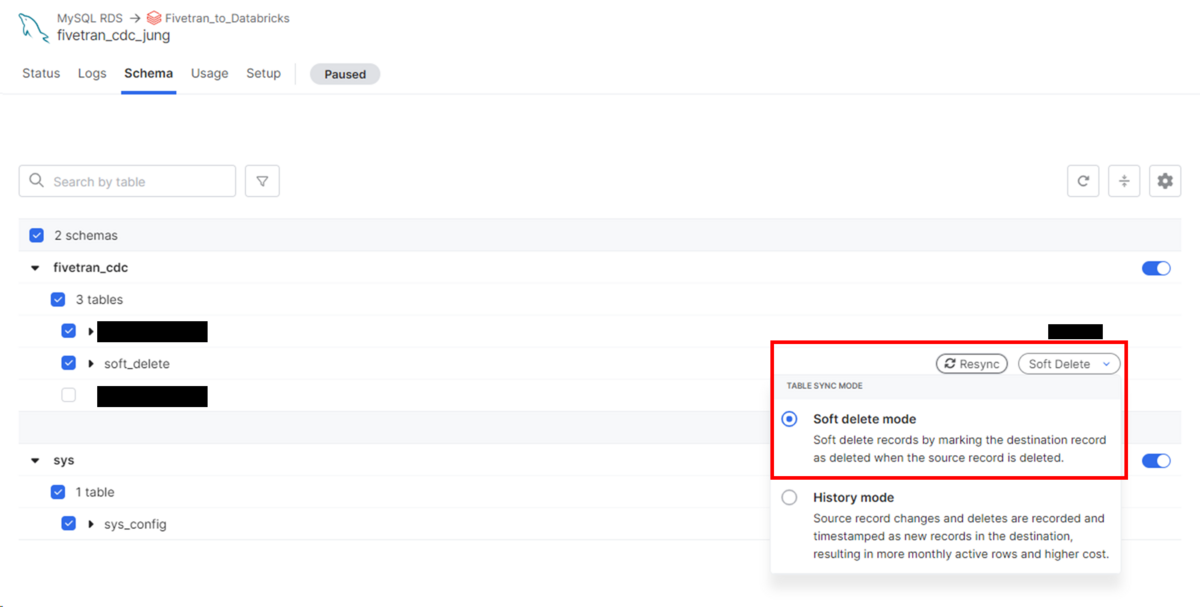
データがDatabricksに移動されます。
- fivetran_deleted、fivetran_syncedが追加され、削除記録と同期化について表示する
- 3は有効なデータなので_fivetran_deletedがfalse

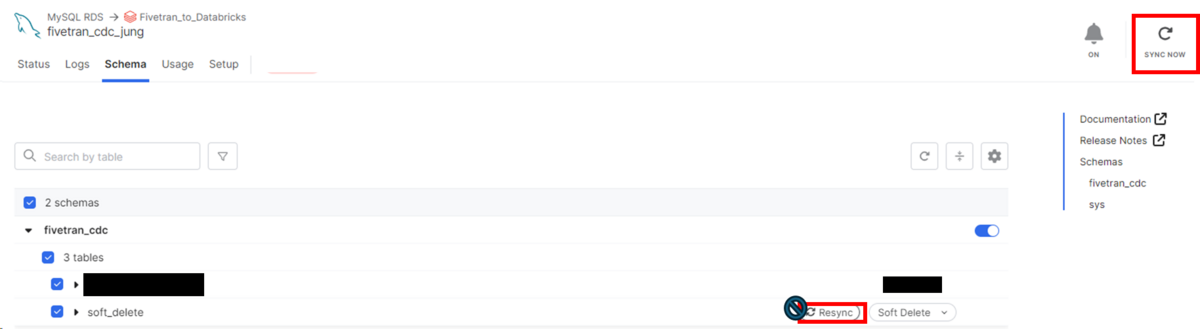
データを変更します。
- COUNTSカラムに3を削除した後、2を追加する
-- delete data and insert data DELETE FROM soft_delete WHERE COUNTS = 3; INSERT INTO soft_delete (COUNTS) VALUES (2);
- 右上にあるSYNC NOWを押す(差分同期)
- Resyncを押すと初期同期化が実行される(全てのデータがsyncされる)
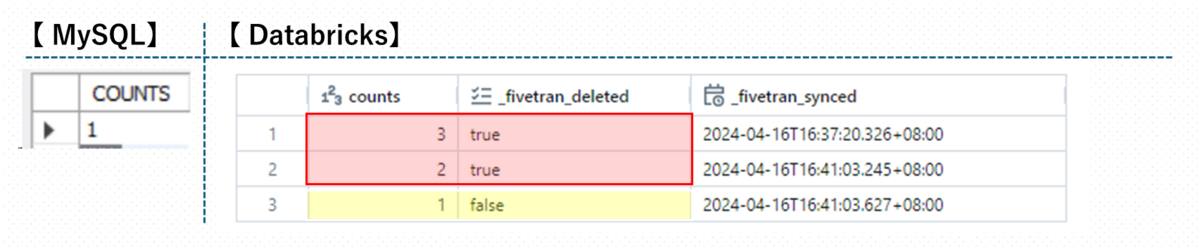
変更がキャプチャーされます。
- 3は削除されたデータなので_fivetran_deletedがtrue
- 2は有効なデータなので_fivetran_deletedがfalse

データをもう一度変更します。
- COUNTSカラムに2を削除した後、1を追加する
-- delete data and insert data DELETE FROM soft_delete WHERE COUNTS = 2; INSERT INTO soft_delete (COUNTS) VALUES (1);
- 右上にあるSYNC NOWを押す(差分同期)
- Resyncを押すと初期同期化が実行される(全てのデータがsyncされる)
変更がキャプチャーされます。
- 2は削除されたデータなので_fivetran_deletedがtrue
- 1は有効なデータなので_fivetran_deletedがfalse
- 先に処理した3の記録は残っている
History Mode
検証は、以下の公式ドキュメントに従っています。
- 前提条件:AWS RDSを使用しており、FivetranのMySQL RDSコネクタを利用してDatabricksにデータを移行している
- History Mode: SCD Type 2を基づいて変更履歴を保持して全てまたは特定なカラムに対してレコードを変更
MySQLでテストデータを作成します。
- IDとCOUNTERカラムがある
- データは('a', 10),('b', 20)が入っている
-- choose schema USE fivetran_cdc; -- create table CREATE TABLE fivetran_cdc.history_mode ( ID CHAR(1), COUNTER INT, PRIMARY KEY (ID) ); -- insert data INSERT INTO history_mode (ID, COUNTER) VALUES ('a', 10), ('b', 20);
コネクターのスキーマページで対象テーブルのTABLE SYNC MODEをHistory modeにします。
そして、Save changesボタンを押して同期化します。
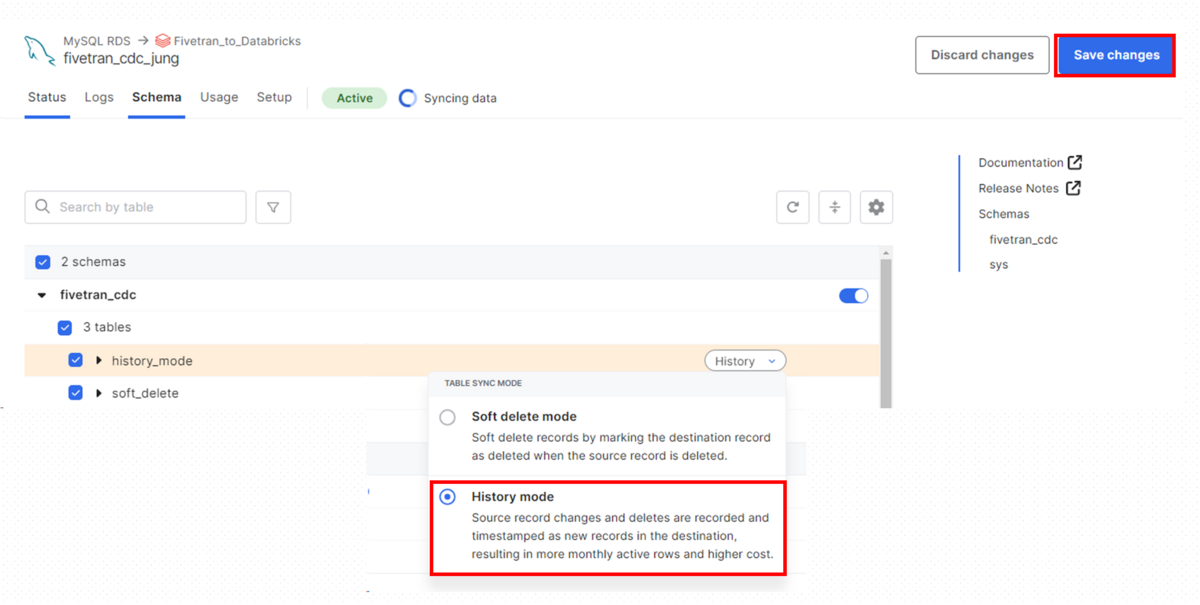
データがDatabricksに移動されます。
- fivetran_synced、fivetran_start、fivetran_end、fivetran_activeが追加され、同期化とデータの変更時期について表示する
- 有効なデータは、fivetran_endに特殊なタイムスタンプが追加され、fivetran_activeにtrueが表示される

データを変更します。
- aのCOUNTERを30に変更し、('c', 40)を追加する
-- data update UPDATE history_mode SET COUNTER = 30 WHERE ID = 'a'; INSERT INTO history_mode (ID, COUNTER) VALUES ('c', 40);
- 右上にあるSYNC NOWを押す(差分同期)
- Resyncを押すと初期同期化が実行される(全てのデータがsyncされる)
変更がキャプチャーされます。
- ('a', 30)と('c', 40)が追加される
- ('a', 10)のfivetran_endに変更が行ったタイムスタンプが記録され、fivetran_activeがfalseになる

データをもう一度変更します。
- IDがbのデータを削除する
-- delete data DELETE FROM history_mode WHERE ID = 'b';
- 右上にあるSYNC NOWを押す(差分同期)
- Resyncを押すと初期同期化が実行される(全てのデータがsyncされる)
変更がキャプチャーされます。
- IDがbのデータのfivetran_endに変更が行ったタイムスタンプが記録され、fivetran_activeがfalseになる
- 先に処理した('a', 10)の記録は残っている

まとめ
今回の記事では、変化感知によりパイプラインを効率的に管理できるCDCについて調べてみました。
そしてDatabricksとFivetranを利用したCDC検証を行いました。
ご興味のある方にお役に立てれば幸いです。
Lakehouse部では、様々な方法による効率的なデータパイプラインの構築が可能です!
データエンジニアリング、パイプライン管理など、データ管理に困った方がいらっしゃいましたら、お気軽にご連絡ください。
最後までご覧いただきありがとうございます。
引き続きどうぞよろしくお願い致します!

私たちはDatabricksを用いたデータ分析基盤の導入から内製化支援まで幅広く支援をしております。
もしご興味がある方は、お問い合わせ頂ければ幸いです。
また、一緒に働いていただける仲間も募集中です!
APCにご興味がある方の連絡をお待ちしております。