
はじめに
GLB事業部Lakehouse部の鄭(ジョン)です。
Databricks Lakehouse Platformが提供するデモであるdbdemosの中で、患者の再入院を減らすための医療予測モデルの構築するデモを紹介したいと思います。
デモ名: Lakehouse for HLS: Patient readmission
今回の投稿はdbdemosを活用して医療データを探求し、予測モデルを作成することを目標にしています。
投稿は2編に分かれています。
1編はデモの概要とデータの探索的分析について紹介しています。
モデルに使われるテーブルと変数についての説明があります。
詳細は下記をご参照ください。
techblog.ap-com.co.jp
今回は2編で患者の再入院を減らすための医療予測モデルを作る過程を紹介してみます。
目次
全体の流れ
本記事では患者の再入院を予測することが目的です。 再入院とは退院後30日以内に計画になかった入院をする場合のことです。
そのために先ず必要なFeature(特徴量)を作成していきます。
Featureとしてはコロナ患者テーブルで患者の特性(性別、年齢、人種、結婚有無など)と入院情報(病院費、入院期間、入院状態など)、訪問当時の年齢を使用します。
そしてターゲットは、30日以内に再入院したことがあるかどうかです。
Featureは再入院患者を確認する変数の作成、One-Hotエンコーディングを通じてダミー変数の作成、入院期間を確認する変数を作成する手順でに作成していきます。
Feature作成後、Featureテーブルを結合してトレーニングデータセットを作成します。
そして、最後にAuto MLで「Pythonコーディングを利用した方法」と「DatabricksのExperimentを利用した方法」で複数のMLモデルを作成し、その中で最も性能の良いモデルを確認します。
Featureテーブルの作成
30日以内に再入院する患者確認する変数を定義
30日以内に再入院患者のターゲットカラムを作成します。
- encounters_mlテーブルは入院に関する情報が入っているテーブルです。
- Idカラムには診療のID、PATIENTカラムには患者のID、STARTカラムには診療開始時間、STOPカラムには診療終了時間があります。他のカラムの説明は1編のencounters_mlテーブルで確認できます。
- encounters_mlテーブルをWindow関数を通じてデータを患者別にパーティショニングします。患者別に分類するという意味です。
- 30日以内の再入院を判断するために、前診療日のSTOPカラムから現在診療日のSTARTカラムを引きます。Timestampの結果値は秒単位です。この計算を30_DAY_READMISSIONカラムを作成するときに使用します。
- 30日は秒単位で計算したら30x24x60x60(秒)です。(30日、24時間、60分、60秒)
- when関数を活用して30_DAY_READMISSIONカラムに30日以内に再入院したら1、しなかったら0が入れます。
%python from pyspark.sql import Window # 30日以内に再入院患者のターゲットカラムを作成 windowSpec = Window.partitionBy("PATIENT").orderBy("START") # Window関数で患者別にパーティショニング labels = spark.table('encounters_ml').select("PATIENT", "Id", "START", "STOP") \ .withColumn('30_DAY_READMISSION', F.when(col('START').cast('long') - F.lag(col('STOP')).over(windowSpec).cast('long') < 30*24*60*60, 1).otherwise(0)) # encounters_mlテーブルの作業 # 前診療日のSTOP - 現在診療日のSTART(結果値:秒単位) # .over(windowSpec)によって上のWindow関数規則の適用 # 30*24*60*60: 30日を秒単位で計算した値 display(labels)
 すべての診療記録中に再入院していない診療件数は4,941件、再入院している診療件数は5,059件です。
すべての診療記録中に再入院していない診療件数は4,941件、再入院している診療件数は5,059件です。
- Window関数を使用しているため、患者数を意味するのではなく、ecounters_mlの全行数で計算されたものです。
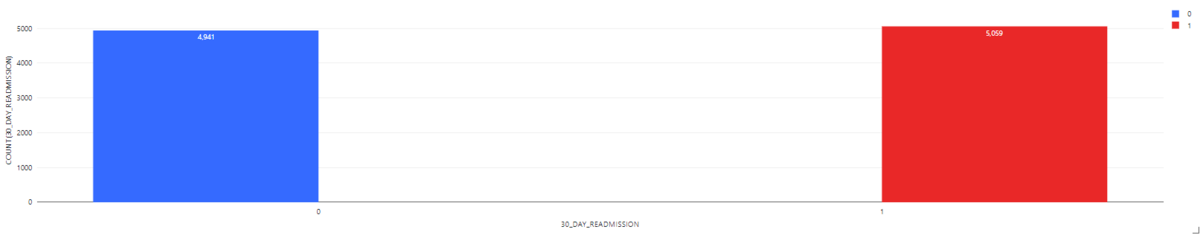
One-Hotエンコーディングを通じてダミー変数を作成
ダミー変数を作成する関数を作成します。
- カテゴリー型変数を1または0で表現するone-hot表現に変換します。
%python import pyspark.pandas as ps def compute_pat_features(data): data = data.pandas_api() data = ps.get_dummies(data, columns=['MARITAL', 'RACE', 'ETHNICITY', 'GENDER'],dtype = 'int64').to_spark() return data
コホートテーブルとpatients_mlテーブルを結合した後、ダミー変数を作成します。
- コホートテーブルには特定の病気に関するデータが含まれています。コホートとは、同じ特性を持つ集団を意味します。コホートテーブルの作成方法は1編のconditions_mlテーブルのcohortテーブルパートで確認できます。
- patients_mlテーブルは患者に関する情報が入っているテーブルです。patients_mlテーブルのカラムの説明は1編のpatients_mlテーブルで確認できます。
- コホートテーブルの中でコロナ患者のコホートテーブルを使用します。
cohort_name = 'COVID-19-cohort' cohort = spark.sql(f"SELECT p.* FROM cohort c INNER JOIN patients_ml p on c.patient=p.id WHERE c.name='{cohort_name}'") \ .dropDuplicates(["id"]) # コロナ患者コホートテーブルにpatients_mlインナージョイン # コホート名を変更し、別のテーブルを作成できる cohort_features_df = compute_pat_features(cohort) cohort_features_df.display()

入院期間を示すEncounter Featureテーブルの作成
Encounter Feature テーブルを作成します。
- enc_lengthカラムを追加して入院期間を計算します。単位は秒です。
- カテゴリ型変数ENCOUNTERCLASSをダミー変数に変換します。
- Encounter Feature テーブルに使用するカラムを選択します。
- Idカラムは重複するカラム名を防止するためにENCOUNTER_IDにカラム名を変更します。
def compute_enc_features(data): data = data.dropDuplicates(["Id"]) data = data.withColumn('enc_length', F.unix_timestamp(col('stop'))- F.unix_timestamp(col('start'))) # 入院期間カラムの作成 data = data.pandas_api() data = ps.get_dummies(data, columns=['ENCOUNTERCLASS'],dtype = 'int64').to_spark() # カテゴリ型変数ENCOUNTERCLASSをダミー変数に変換 return ( data .select( col('Id').alias('ENCOUNTER_ID'), 'BASE_ENCOUNTER_COST', 'TOTAL_CLAIM_COST', 'PAYER_COVERAGE', 'enc_length', 'ENCOUNTERCLASS_ambulatory', 'ENCOUNTERCLASS_emergency', 'ENCOUNTERCLASS_hospice', 'ENCOUNTERCLASS_inpatient', 'ENCOUNTERCLASS_outpatient', 'ENCOUNTERCLASS_wellness', ) # 使用するカラムを選択する ) enc_features_df = compute_enc_features(spark.table('encounters_ml')) display(enc_features_df)

トレーニングデータセットの作成
上で作ったFeaturesを組み合わせてトレーニング データセットを作成します。
- cohort_features_df: コロナ患者のコホートテーブルでpatient_mlと結合した後、「MARITAL」、「RACE」、「ETHNICITY」、「GENDER」カラムのダミー変数を作ったテーブルです。
- labels: 30日以内に再入院するかどうかを作成したテーブルです。
- enc_features_df: ENCOUNTERCLASSのダミー変数があるEncounter Featureテーブルです。
- 使用しないカラムはdrop関数で削除します。
training_dataset = cohort_features_df.join(labels, [labels.PATIENT==cohort_features_df.Id], "inner") \ .join(enc_features_df, [labels.Id==enc_features_df.ENCOUNTER_ID], "inner") \ .drop("Id", "_rescued_data", "SSN", "DRIVERS", "PASSPORT", "FIRST", "LAST", "ADDRESS", "BIRTHPLACE")
- PATIENTカラムのカラム名をpatient_idに変えます。
- 入院当時の年齢を計算したage_at_encounterカラムを作成します。
training_dataset = training_dataset.withColumnRenamed("PATIENT", "patient_id") \ .withColumn("age_at_encounter", ((F.datediff(col('START'), col('BIRTHDATE'))) / 365.25)) training_dataset.write.mode('overwrite').saveAsTable("training_dataset") display(spark.table("training_dataset"))

AutoML Experiment の作成
上で作ったトレーニングデータセットを利用してAutoMLを作ってみます。
AutoMLの作成方法には、PythonコーディングとDatabricksのExperimentを利用した方法があります。
二つの方法について紹介します。
Pythonコーディングを利用したAutoML作成
DatabricksのAutoMLライブラリを利用すると、簡単にPythonでAutoMLを作成できます。
- AutoMLにはclassify、regress、forecast機械学習があります。
- 各機械学習ごとにサポートされるアルゴリズムは、以下のマニュアルからご確認いただけます。
- オプションを通じてFeature選択、ターゲット選定、モデル性能評価方法、実行時間制御などが可能です。
- オプションの詳細については、以下のブログでご確認いただけます。
feature_names = ['MARITAL_M', 'MARITAL_S', 'RACE_asian', 'RACE_black', 'RACE_hawaiian', 'RACE_other', 'RACE_white', 'ETHNICITY_hispanic', 'ETHNICITY_nonhispanic', 'GENDER_F', 'GENDER_M', 'INCOME'] \ + ['BASE_ENCOUNTER_COST', 'TOTAL_CLAIM_COST', 'PAYER_COVERAGE', 'enc_length', 'ENCOUNTERCLASS_ambulatory', 'ENCOUNTERCLASS_emergency', 'ENCOUNTERCLASS_hospice', 'ENCOUNTERCLASS_inpatient', 'ENCOUNTERCLASS_outpatient', 'ENCOUNTERCLASS_wellness'] \ + ['age_at_encounter'] \ + ['30_DAY_READMISSION'] from databricks import automl summary = automl.classify(training_dataset.select(feature_names), target_col="30_DAY_READMISSION", primary_metric="roc_auc", timeout_minutes=6)
自動的にDatabricksのAutoMLが実行され、MLflow Experimentが作成されます。
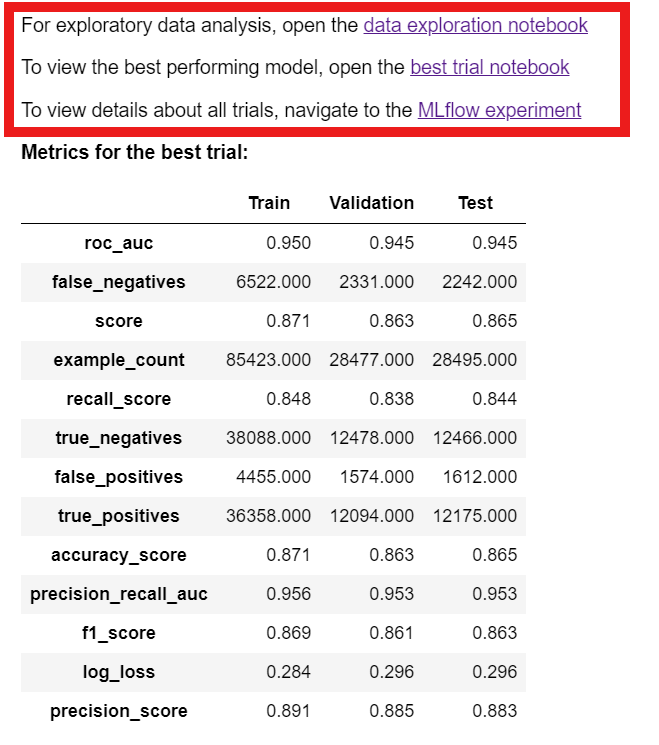
最も高い性能の実験結果を確認できます。
Train、Validation、Testの各スコアを示します。
実験用に提供されるリンクから実験に使用された変数の分析、実験過程が含まれたnotebook、DatabricksのExperimentsを確認することができます。
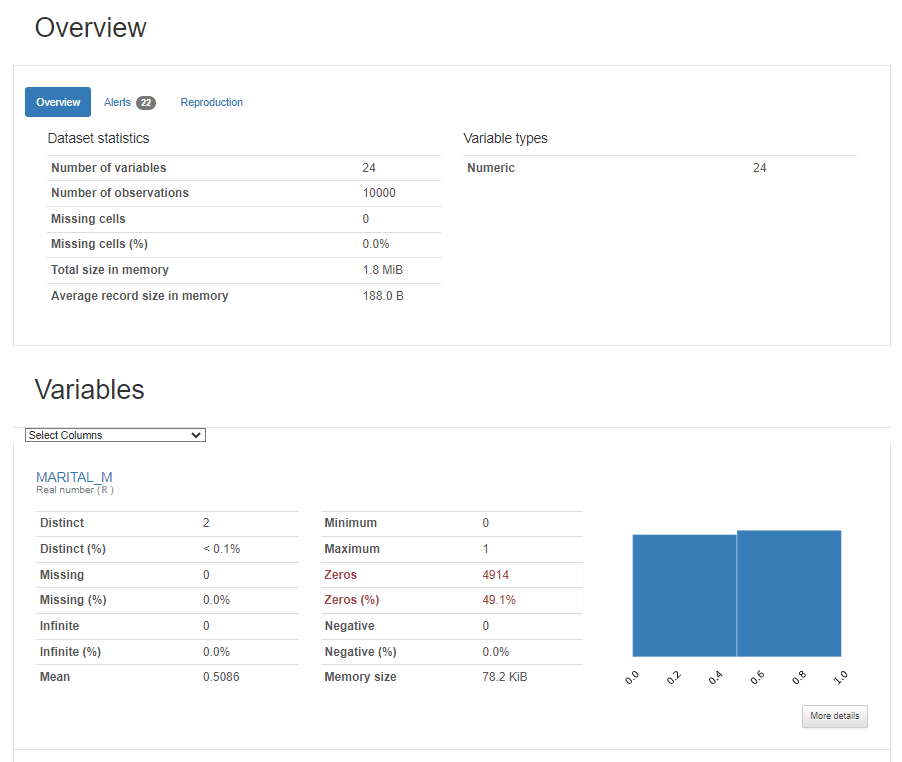
実験に使用された変数の分析 : Summary Statistics(平均、最大/最小値など)と簡単なグラフなど変数の分析を確認できます。
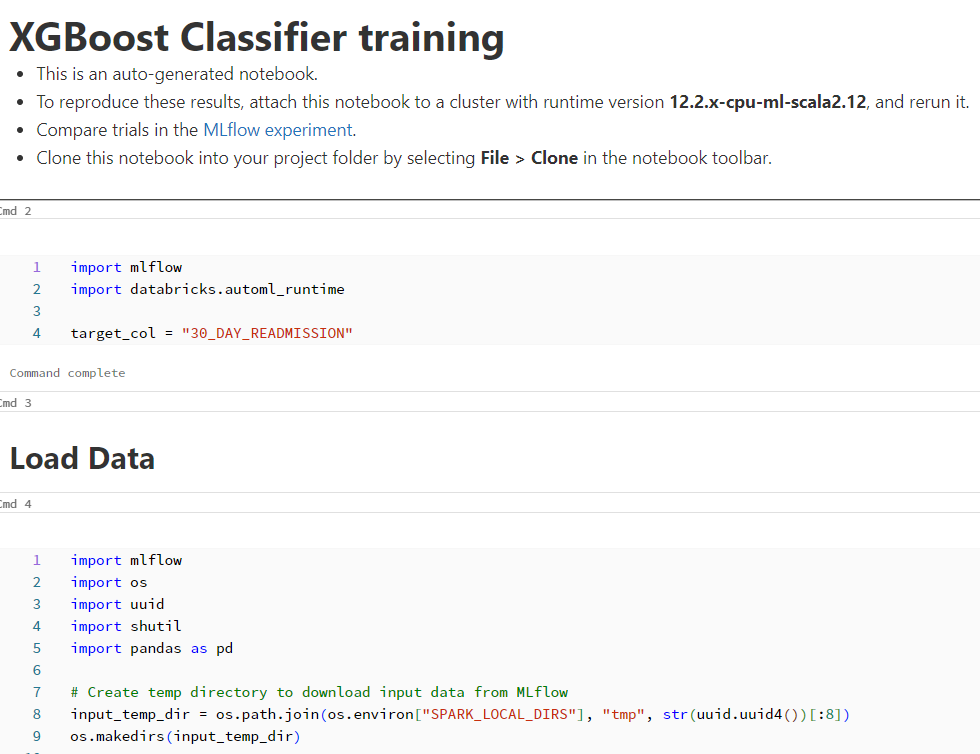
実験過程が含まれたnotebook : 使用されたアルゴリズム、データ前処理、データsplitプロセスなどを確認できます。
- AutoMLはデータを3セットに分割します。
① Train(学習): モデルのトレーニングに使用されるデータで60%比率
➁ Validation(検証): モデルのハイパーパラメータを調整するために使用されるデータで20%比率
③ Test(テスト): 実際のパフォーマンスを確認するために使用されるデータで20%比率 - "_automl_split_col_54d5"に上記の分割情報を含んでいます。
#_automl_split_col_54d5を利用してデータを分割する split_train_df = df_loaded.loc[df_loaded._automl_split_col_54d5 == "train"] split_val_df = df_loaded.loc[df_loaded._automl_split_col_54d5 == "val"] split_test_df = df_loaded.loc[df_loaded._automl_split_col_54d5 == "test"] #フィーチャーとターゲットを分離する X_train = split_train_df.drop([target_col, "_automl_split_col_54d5"], axis=1) y_train = split_train_df[target_col] X_val = split_val_df.drop([target_col, "_automl_split_col_54d5"], axis=1) y_val = split_val_df[target_col] X_test = split_test_df.drop([target_col, "_automl_split_col_54d5"], axis=1) y_test = split_test_df[target_col]
- DatabricksのExperiments : DatabricksのExperimentsで実験されたMLを確認できます。 実行時間、スコア、使用されたアルゴリズムなどを見ることができます。
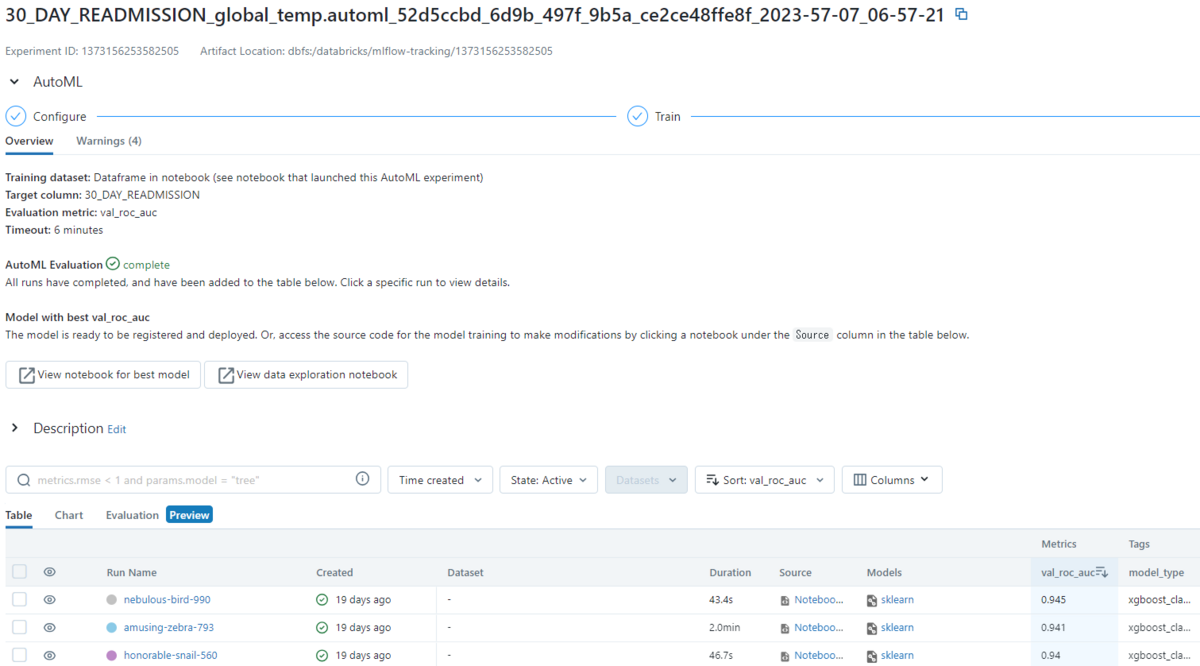
モデル評価が一番高かった実験結果です。
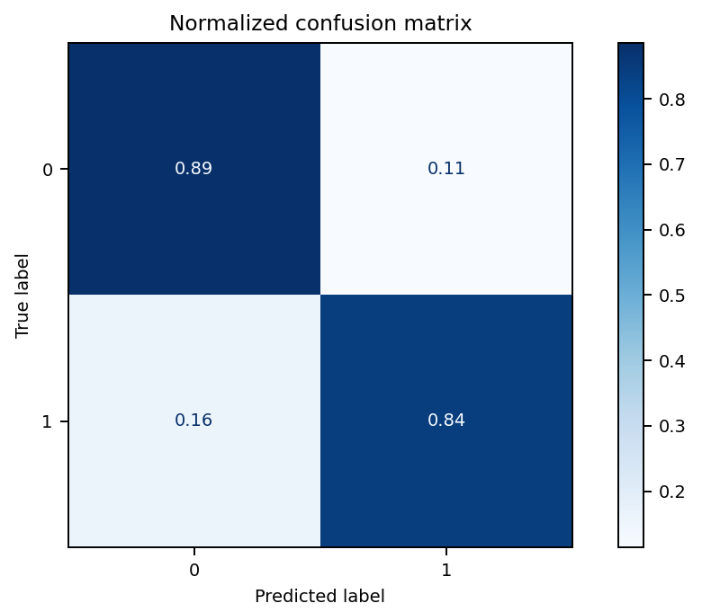
- 混同行列(Confusion Matrix)結果は、1を0と判断した割合は0.16、1を1と判断した割合は0.84、0を1と判断した割合は0.11、0を0と判断した割合は0.89です。
① TP : True Positiveは0.84
➁ FP : False Positiveは0.11
③ TN : True Negativeは0.89
④ FN : False Negativeは0.16
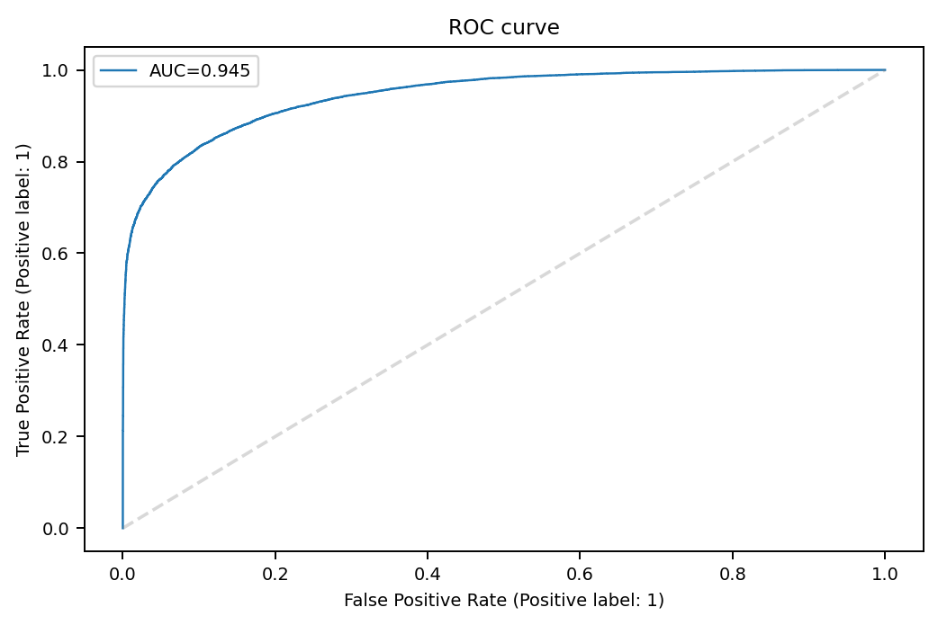
- Evaluation metric(モデル評価方法)は"ROC/AUC"を使用しました。
① ROCはTrue Positive RateとFalse Positive Rateを利用して表現した2 値分類のパフォーマンスを表現するカーブです。
➁ AUCはROCのカーブの下部分の面積で、AUCの面積が大きいほど性能が一般的に良い事を意味します。 - True Positive RateはTP/(TP+FN)、False Positive RateはFP/(FP+TN)です。
DatabricksのExperimentを利用したAutoML作成
DatabricksのExperimentを利用すると、コードを作成しなくても簡単にAutoMLを作成できます。
- Machine LearningセクションにあるExperimentsに入り、Create AutoML Experimentボタンを押します。
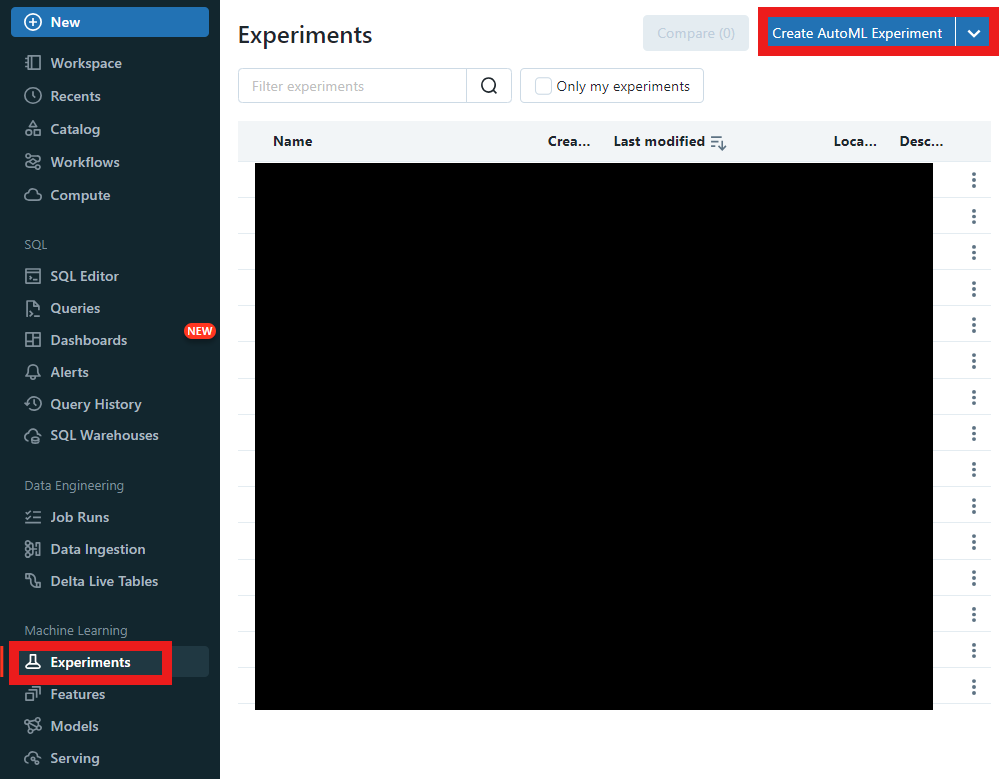
- 生成されたExperimentからオプションをAutoMLドロップダウン形式で選択できます。
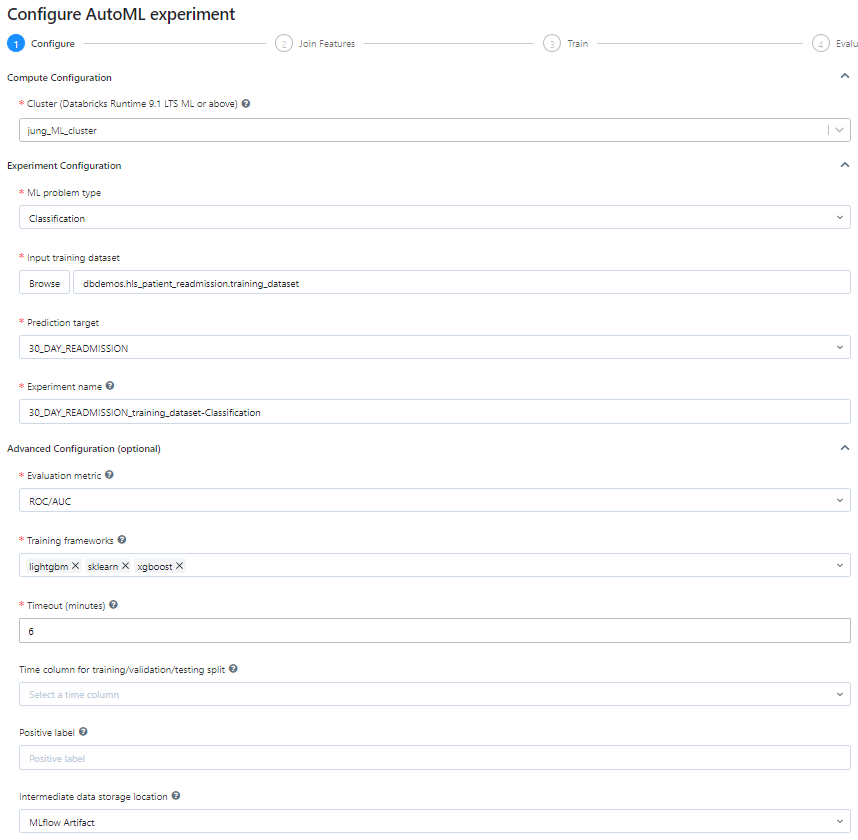
- Cluster接続、ML problem type(機械学習タイプ)、Training dataset、Prediction target、Experiment name、Evaluation metric(モデル評価方法)、Training frameworks(使用するアルゴリズム)、Timeout(実行時間制御)などを入力します。
- Training frameworksはDatabricksが提供しているすべての分類モデルを使用しました。
① lightgbm、➁ sklearn(決定木、ランダムフォレスト、ロジスティック回帰)、③ xgboost
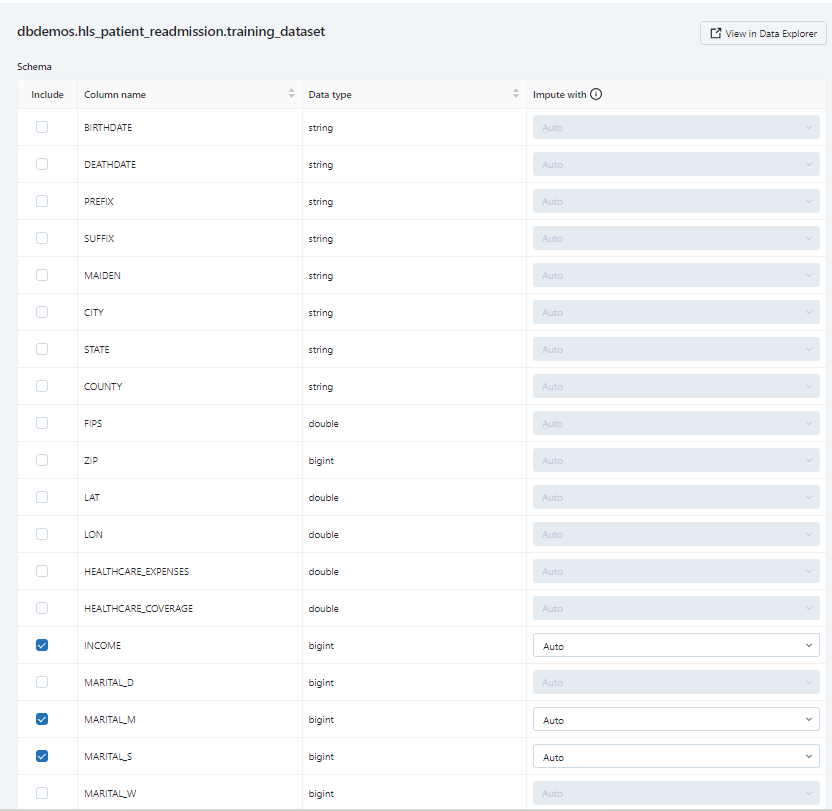
簡単なチェックで使用するFeatureを選択できます。
Featureはdbdemosと同じように進行しました。
オプション作成が完了したら、下段のStart AutoMLボタンを押します。
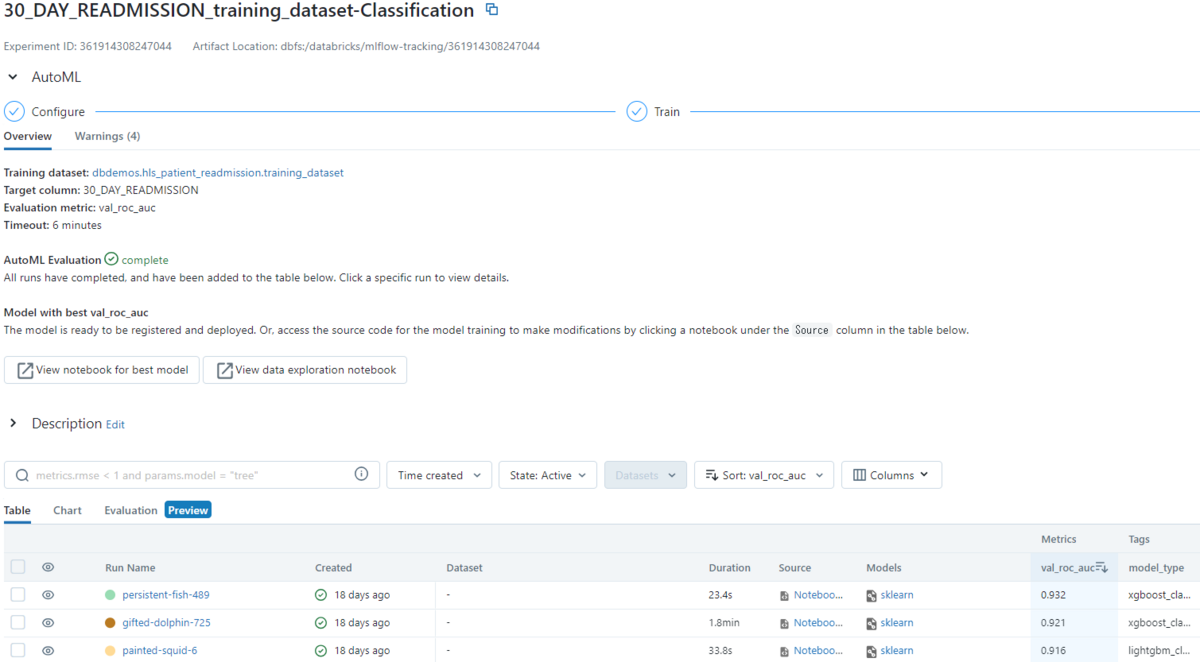
実験が完了すると、次のように実験結果が出ます。 Pythonを使った時と同じように 実行時間、スコア、使用されたアルゴリズムなどを見ることができます。
まとめ
今回はdbdemosを利用してヘルスケアデータを利用したMachine Learningモデルを作ってみました。
Window関数を利用してデータの行数は維持し、患者別ターゲットデータを作成しました。
カテゴリ型変数にOne-Hotエンコーディングを通じてダミー変数を作成しました。
Databricksの機能とPythonの関数を利用してAutoMLの作成方法について調べてみました。
既存変数を変形して新しい変数を作成し、AutoMLを作成できるようになったと思います。
最後までご覧いただきありがとうございます。
引き続きどうぞよろしくお願い致します!

私たちはDatabricksを用いたデータ分析基盤の導入から内製化支援まで幅広く支援をしております。
もしご興味がある方は、お問い合わせ頂ければ幸いです。
また、一緒に働いていただける仲間も募集中です!
APCにご興味がある方の連絡をお待ちしております。