はじめに
GLB事業部Lakehouse部の佐藤です。
これから始まる本ブログシリーズでは、Databricks上でのdbt活用に役立つ実践的なTipsをお届けします。初めてdbtに触れる方から、既に使い慣れている方まで、幅広い層に向けた内容となっています。また、11月には本シリーズに関連したウェビナーも予定していますので、ぜひご期待ください。 ウェビナーへのお申し込みはこちらからお願い致します。
このブログでは「Databricksでdbtセマンティックレイヤーを可視化する」をテーマに検証した結果をご報告させていただきます。
セマンティックレイヤーとは?
セマンティックレイヤーの概要
セマンティックレイヤーは、データウェアハウスの上に位置する抽象化層で、dbtでメトリックロジックを一元的に定義できます。これにより、ビジネスチームが異なるツールや基準でメトリクスを定義することで生じる混乱を回避し、すべてのユーザーが同じメトリクス定義を使用できるようになります。
セマンティックレイヤーのメリット
セマンティックレイヤーを使用することで、ビジネスデータの信頼性が向上し、データチームはメトリクスの再定義やトラブルシューティングにかける時間が減り、効率が向上します。

dbtセマンティックレイヤー Tutorialのご紹介
dbtからは以下のTutorialが提供されています。 このブログでは、こちらのTutorialを使って作成できるセマンティックレイヤーに対して検証を行っています。 learn.getdbt.com このTutorialでは、セマンティックレイヤーとは何か、dbtCloudでセマンティックレイヤーを設定する方法(セマンティックモデルの設定とメトリクスの作成方法)、そして、Googleスプレッドシートからセマンティックレイヤーをクエリする方法までが動画付きで紹介されています。
セマンティックレイヤーの概念については冒頭でご説明しましたので、ここからは、セマンティックレイヤーの構成要素であるセマンティックモデルとメトリクスについて簡単にご紹介します。
セマンティックモデルとは
セマンティックモデルは、メトリクスを定義するためのデータロジックとメタデータを定義する場所です。 このモデルは、エンティティ、ディメンション、メジャーの3つの主要な構成要素で構築されます。
エンティティは、顧客や取引といったビジネスの現実世界の概念を表します。 エンティティは、セマンティックモデル間の結合キーとして機能します。
ディメンションは、カテゴリ情報(商品タイプ、地理情報など)や時間に関連した情報を含む列です。 これにより、データをグループ化したりフィルタリングすることができます。
メジャーは、SQLの集計演算を実行するカラムです。収益や顧客数など、メジャー自体がメトリクスとして機能します。
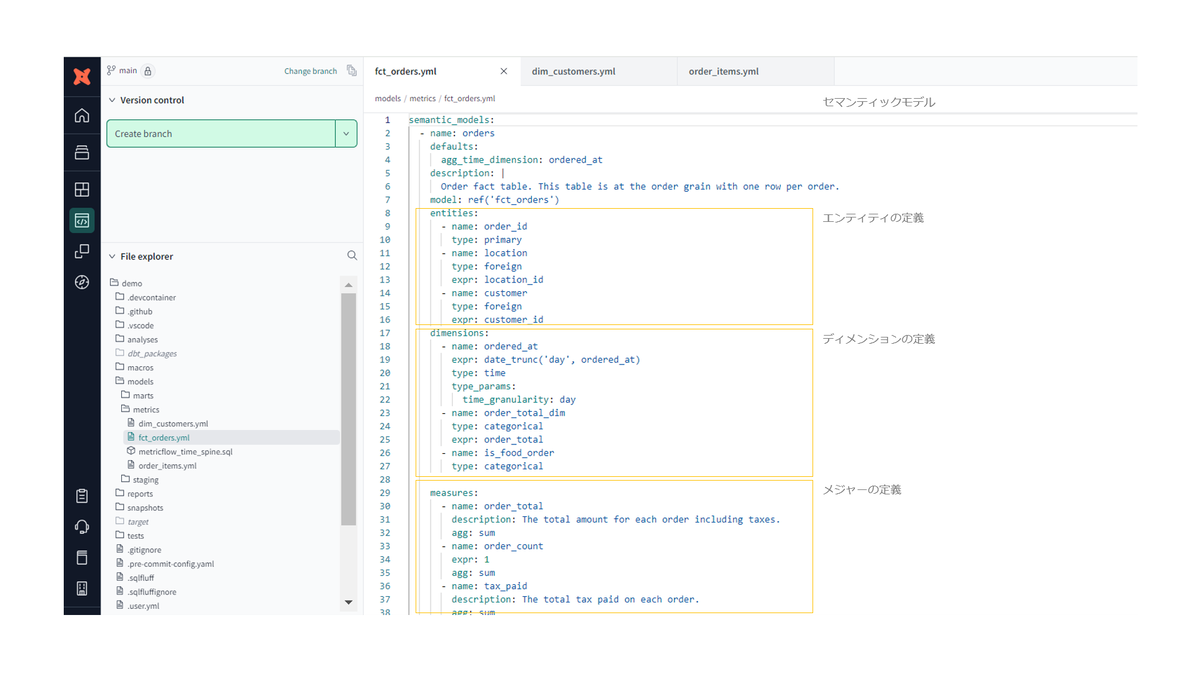
メトリクスとは
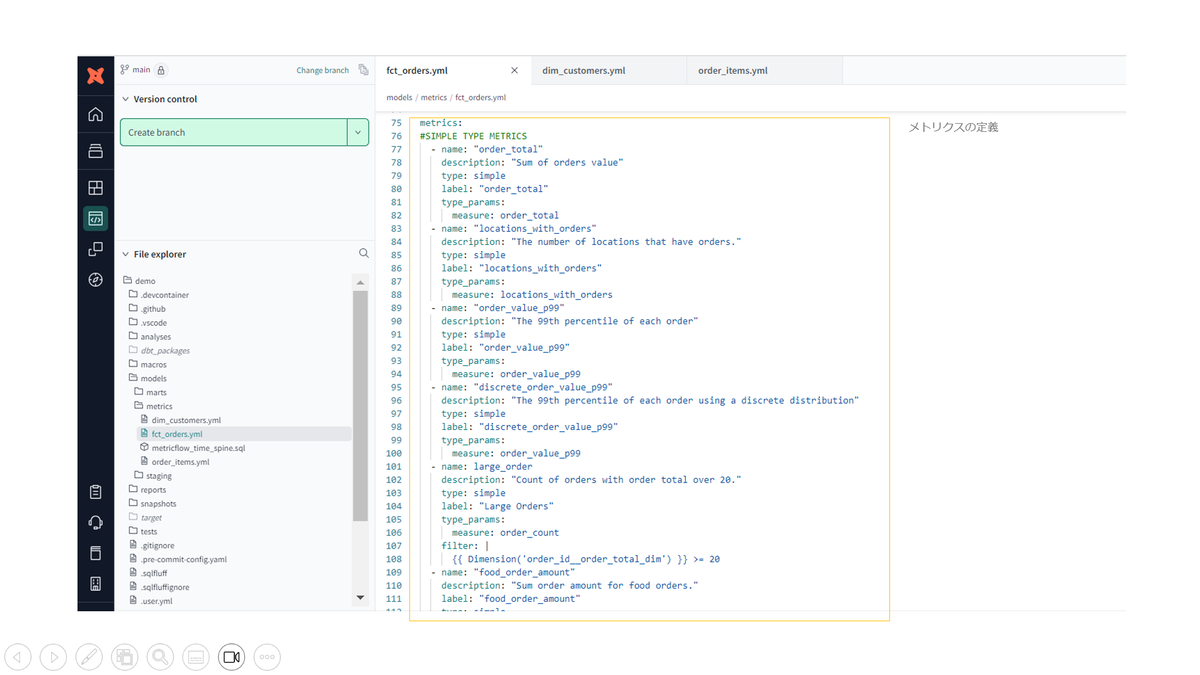
メトリクスは、ビジネスパフォーマンスを測定するための指標です。売上や収益、新規ユーザー数などを追跡するために使用されます。メトリクスは、データウェアハウスのカラムの集計をディメンションと組み合わせることで構築されます。メトリクスは名前、説明、タイプを指定し、YAMLファイルで設定します。 メトリクスには以下の4種類があります。
シンプルメトリクス: 単一のメジャーを直接参照し、追加のメジャーを使わずに簡単に設定できるメトリクスです。例として、注文合計額のような集計があります。
比率メトリクス: 2つのメトリクスの比率を計算するものです。分子と分母を指定して設定され、例えば、平均注文額と最大注文額の比率を計算することができます。
累積メトリクス: 指定された期間にわたって値を累積するメトリクスです。期間を指定しない場合は、全期間にわたって累積されます。
派生メトリクス:
他のメトリクスを組み合わせて新しい式を作成するメトリクスです。例えば、収益からコストを引いて利益を計算することができます。
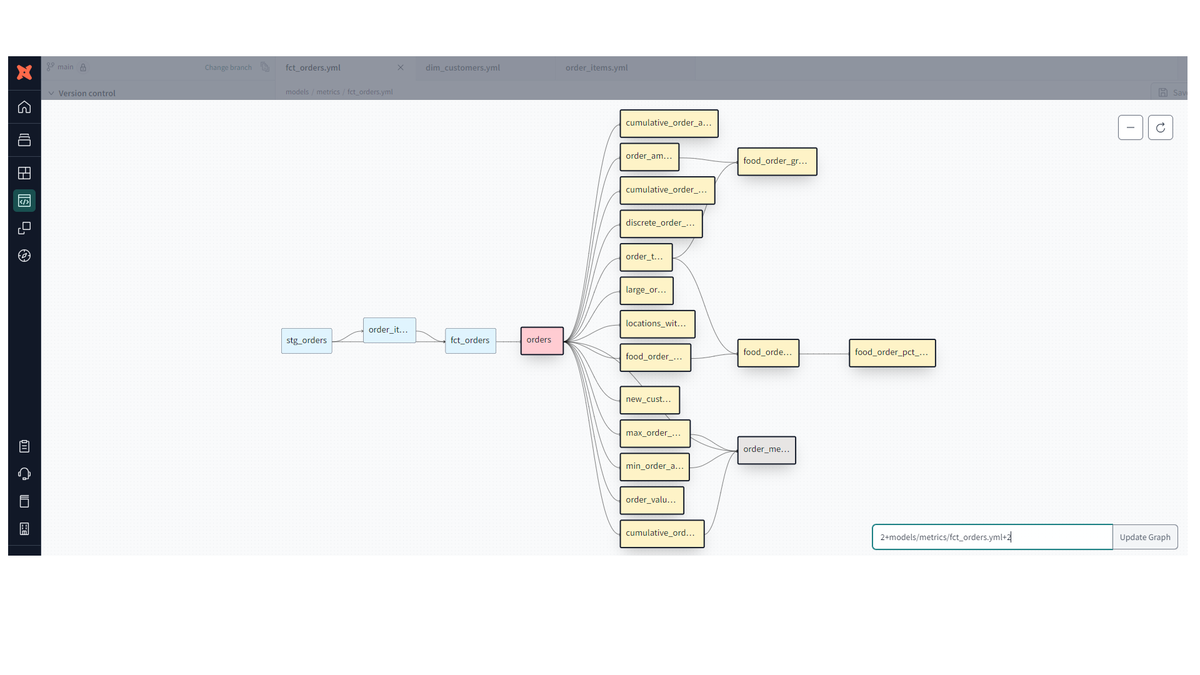
YAMLファイルでセマンティックモデルとメトリクスが設定されると、以下の様なモデルのデータリネージ図が作成されます。
この図は、データモデルがどのように関連し合っているかを視覚化したもので、データフローや依存関係を表しています。
青がdbtモデル(変換モデル)、ピンク色がセマンティックモデル、薄い黄色がメトリクスを表しています。
Databricksからセマンティックレイヤーにクエリする
さて、ここからはTutorialで作成したセマンティックレイヤーに対して、Databricksからクエリする方法をご紹介いたします。 Databricksからセマンティックレイヤーにクエリするには以下3つの方法があります。
PythonSDKを使う docs.getdbt.com
Java データベース接続 (JDBC) APIを使う docs.getdbt.com
Unity Catalog Metricsを使う (今年のDAISで発表された新機能で、まだ一般には公開されていません。) mobile.x.com
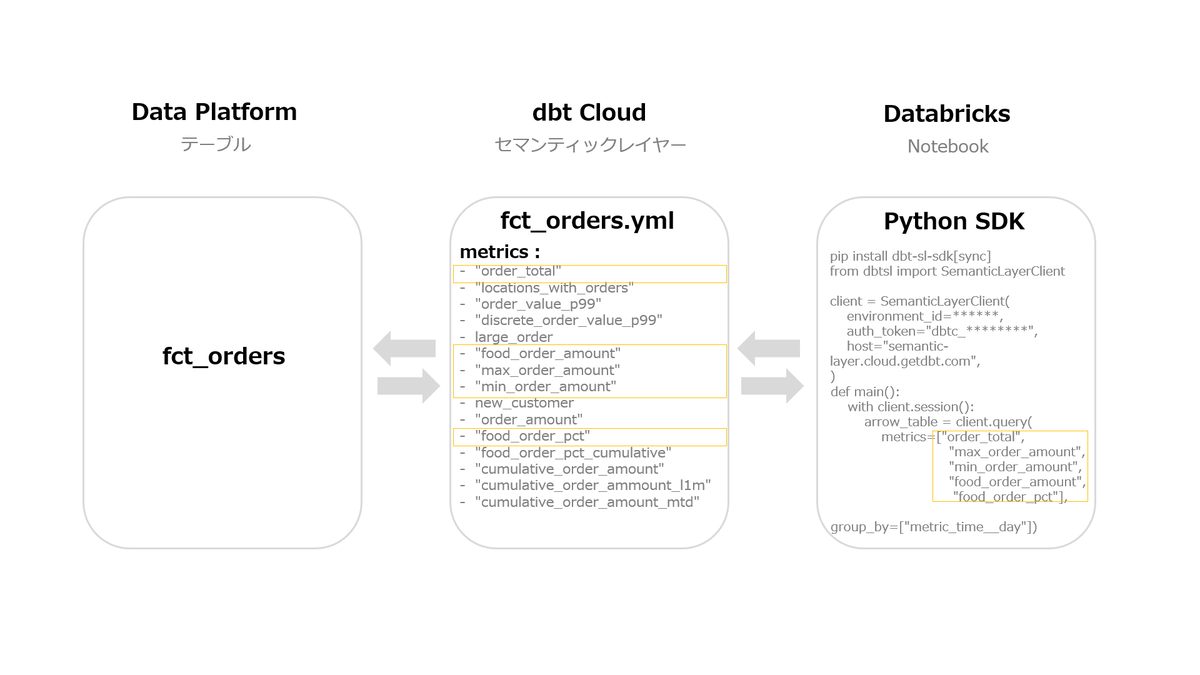
今回はPython SDKを使って検証しました。 今回の検証でのざっくりとした情報の流れとイメージは、以下の様になります。
- Python SDKを使用してdbtセマンティックレイヤーに接続し、YAMLファイルで定義されたメトリクスを抽出するコードを実行します。
- dbtセマンティックレイヤーでは、モデルやYAMLファイルの定義に基づきSQLを生成し、データプラットフォームに対してクエリを実行します。
- データプラットフォームは、dbt Cloudから送信されたSQLに従い集計を行い、その結果をdbt Cloudに返送します。
- dbt Cloudは、データプラットフォームから返された結果をDatabricksのNotebookに返します。
*今回の検証では、データプラットフォームとしてもDatabricksを使用しており、fct_ordersテーブルもDatabricks上に作成されています。
Databricksにテーブル・ダッシュボードを作る
まずは、Python ライブラリ:dbt-sl-sdkをインストールし、SemanticLayerClientをインポートします。
そして、セマンティックレイヤーの environment_idとauth_tokenを入力し、セマンティック レイヤー API に接続します。
pip install dbt-sl-sdk[sync] from dbtsl import SemanticLayerClient client = SemanticLayerClient( environment_id=******, auth_token="dbtc_*******************************_********_*********", host="semantic-layer.cloud.getdbt.com", )
client.session()メソッドを使い、セマンティックレイヤーにクエリします。 今回は、"order_total","max_order_amount","min_order_amount","food_order_amount","food_order_pct"の2016年9月1日から9月22日の期間のDaily実績を抽出しました。
そして、抽出した実績をPandas DataFrameに格納し、Pandas DataFrameをSpark DataFrameに変換後、checking_tableというテーブルを作成します。
from pyspark.sql import SparkSession def main(): spark = SparkSession.builder.appName("CreateView").getOrCreate() with client.session(): arrow_table = client.query( metrics=["order_total","max_order_amount","min_order_amount","food_order_amount","food_order_pct"], group_by=["metric_time__day"], filters=[{"field": "metric_time__day", "operator": ">=", "value": "2016-09-01"},{"field": "metric_time__day", "operator": "<=", "value": "2016-09-22"}] ) pandas_df = arrow_table.to_pandas() print(pandas_df) spark_df = spark.createDataFrame(pandas_df) spark_df.write.format("delta").saveAsTable("raw.default.checking_table") main()
テーブルが出来ました。
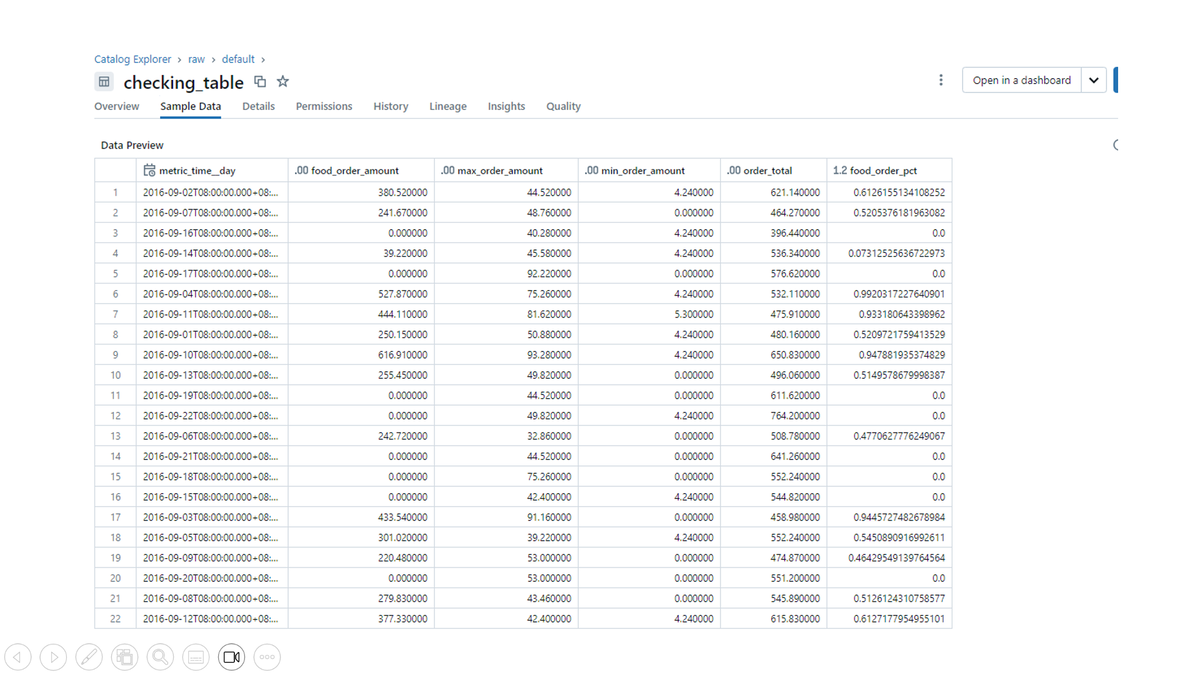
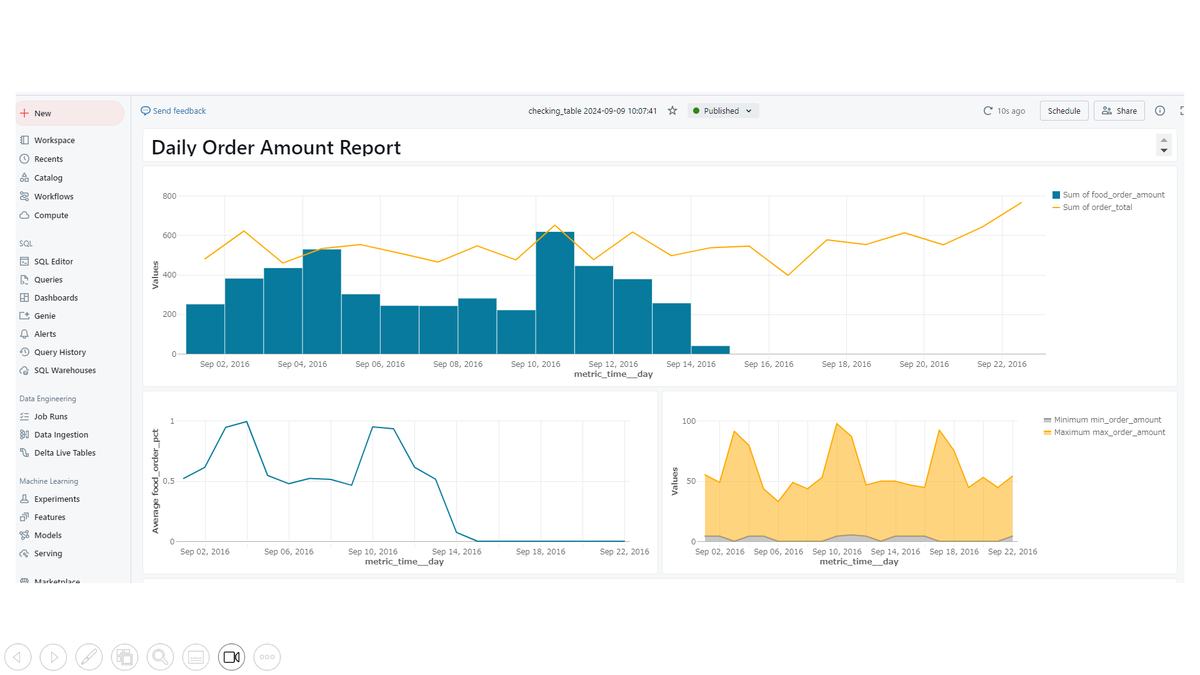
出来上がったテーブル:checking_tableを使って、オーダー総額と食べ物へのオーダー金額の推移、オーダー総額に占める食べ物へのオーダー金額の比率の推移、日毎のオーダーの最大値、最小値の推移を確認できるダッシュボードを作成しました。
おわりに
このブログでは「Databricksでdbtセマンティックレイヤーを可視化する」をテーマに検証を行いました。 Python SDKを使う方法も比較的簡単でしたが、Unity Catalog Metricsが使えるようになると、もっと簡単にクエリやダッシュボード構築が出来る様になるので、公開されるのが楽しみです。
2024年11月6日(水)に本シリーズに関連したウェビナーも開催します。詳細は以下URLから。
私たちはDatabricksを用いたデータ分析基盤の導入から内製化支援まで幅広く支援をしております。
もしご興味がある方は、お問い合わせ頂ければ幸いです。
また、一緒に働いていただける仲間も募集中です!
APCにご興味がある方の連絡をお待ちしております。
