はじめに
GLB事業部Lakehouse部の長尾です。
これから始まる本ブログシリーズでは、Databricks上でのdbt活用に役立つ実践的なTipsをお届けします。
初めてdbtに触れる方から、既に使い慣れている方まで、幅広い層に向けた内容となっています。
また、11月には本シリーズに関連したウェビナーも予定していますので、ぜひご期待ください。
これからの投稿をお見逃しなく!
ウェビナーへのお申し込みはこちらからお願い致します。
本ブログは、dbt × Databricksによるデータ処理と品質管理の最適化①の続編です。
前回同様に本ブログもDatabricks社の「Best Practices for Super Powering Your dbt Project on Databricks」を参照して(2024年9月9日時点)、dbtとDatabricksを効果的に連携して活用するためのベストプラクティスについて紹介しています。
 参考: dbt on Databricks: Training Series - Databricks
参考: dbt on Databricks: Training Series - Databricks
以下では今回の2本のブログで扱っているツールについて説明しています。

前回のブログの繰り返しになりますが、dbtとDatabricksを連携させることで、主に下記3つの観点からメリットを得られると考えています。
データトランスフォーメーションのスケーラビリティの課題と効果
課題: 大量のデータを効率的に処理できないこと。従来のデータ処理ツールでは、パフォーマンスが不足している。
効果: Databricksのスケーラブルな処理能力とdbtのデータトランスフォーメーション機能を組み合わせることで、大規模なデータを高速かつ効率的に処理できる。データエンジニアリングのワークフロー自動化の課題と効果
課題: 手動操作が多く、エラーが発生しやすい。再利用性の低いスクリプトが散在し、管理が煩雑。
効果: dbtを使用することで、データトランスフォーメーションをコード化し、バージョン管理も可能となる。これにより、エラーが少なく、再利用可能なワークフローを実現できる。データ品質の保証とモニタリングの課題と効果
課題: データ品質のチェックやモニタリングを手動で行うのは非効率であり、スケールしにくい。
効果: dbtのテスト機能とDatabricksの処理基盤を活用することで、データパイプライン全体の品質を自動で検証・モニタリングできる。
本ブログでは、1本目のブログでカバーしなかった下記2つについて説明します。
- dbt-project-evaluatorを使用してdbt best practiceと合致しているか確認する
- SQLFluffとGitHub Actionsを使用して自動で標準化するための仕組みをつくる
dbt-project-evaluatorを使用してdbt best practiceと合致しているか確認する
dbt Labsはdbtプロジェクトを実施するうえでのbest practiceを下記6つの観点から定めています。
- モデリング
- テスティング
- ドキュメンテーション
- 構成
- パフォーマンス
- ガバナンス
しかしながら、このbest practiceに常に則ってプロジェクトを実行し続けることは容易ではありません。
そのような状況に対して、dbt-project-evaluatorを利用することでbest practiceに則っていない部分についてErrorではなくWarnとして表示してくれます。
dbt_project_evaluatorパッケージをインストールするために、packages.ymlファイルに下記のパッケージ情報も追加します。
packages: - package: dbt-labs/spark_utils version: 0.3.0 - package: dbt-labs/dbt_project_evaluator version: 0.13.2
次に、Databricksと連携して、すべてのマクロとdbt_utilsが適切に機能するように下記のコードをdbt_project.ymlファイルに追加します。
dispatch: - macro_namespace: dbt_utils search_order: ['dbt_project_evaluator', 'spark_utils', 'dbt_utils']
dbt_project_evaluatorを使ってプロジェクトを評価するために必要な上記のパッケージをdbt CLIにdbt depsと入力しインストールし、dbt build --select package:dbt_project_evaluatorを実行します。
下記のようにErrorは出ていませんWarn(下記の赤枠部部分)が6つあることを確認できます。
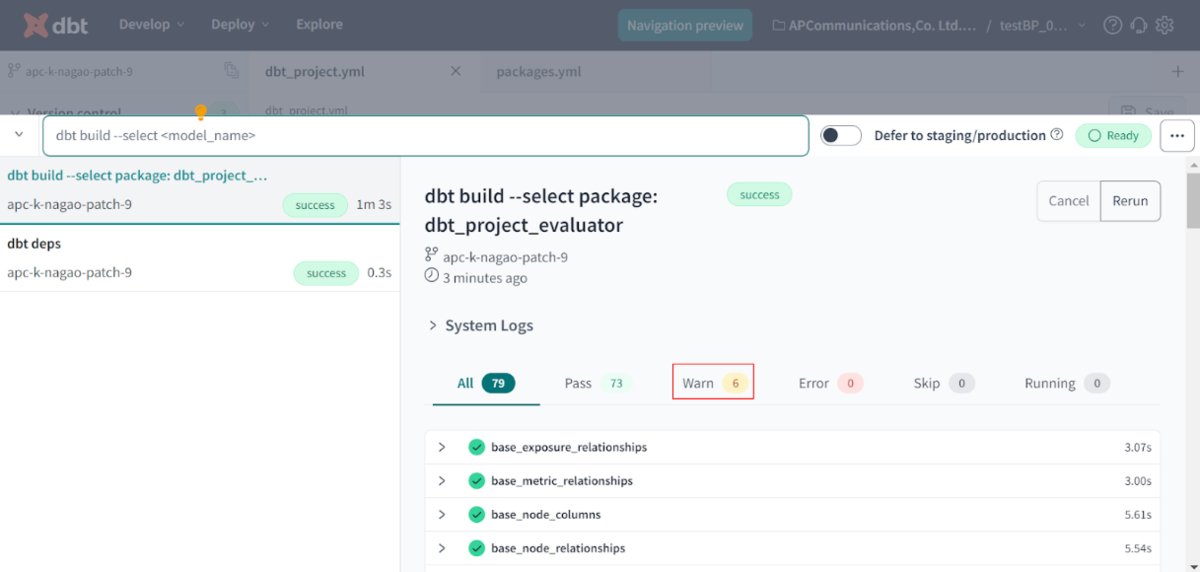
Warnをクリックすると以下のようにWarnの発生元を確認できます。
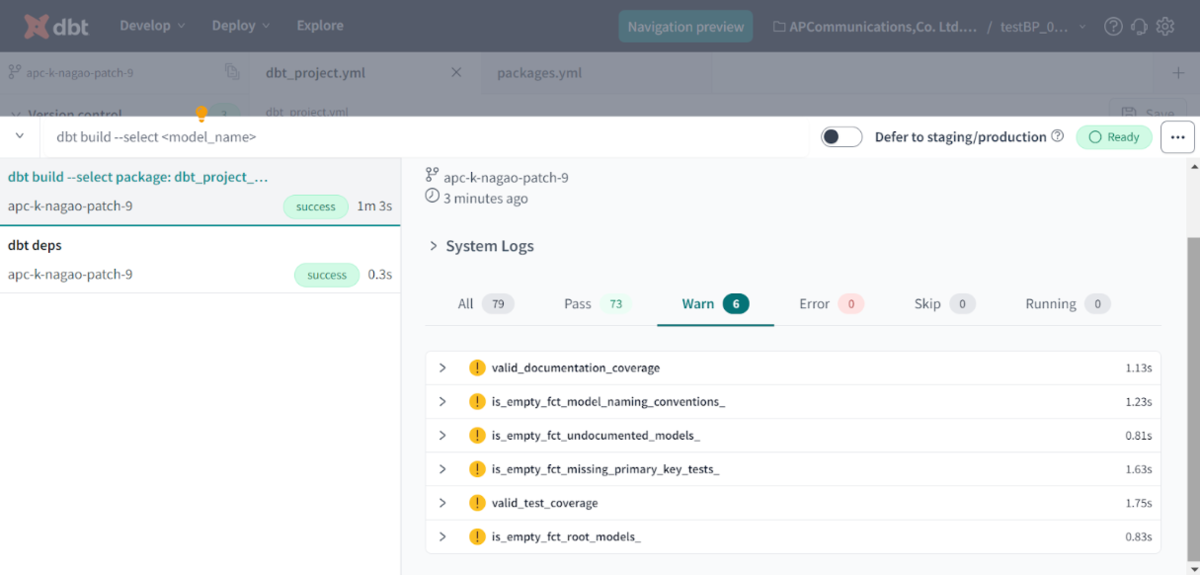
各項目の左側にある「>」をクリックすると以下のように表示されるので、それをひとつずつ修正することで、dbtのBest Practiceに則ったプロジェクトとして実装することができ、予期せねエラーや担当者によってdbtプロジェクトの作成方法が異なることによる不具合を解消することができます。
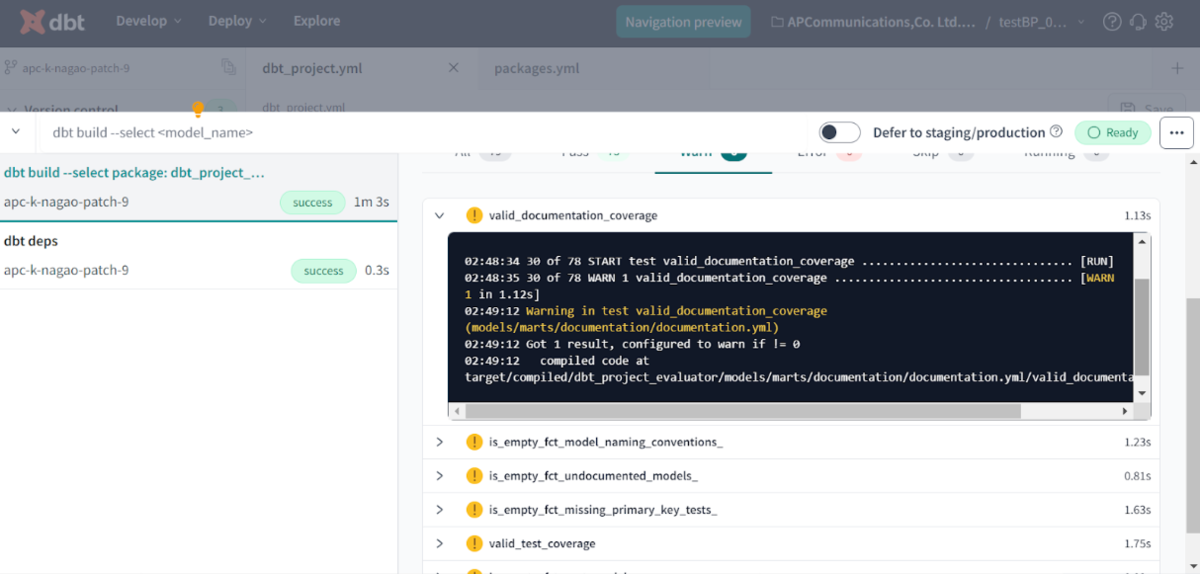
ちなみに、上記のエラーのフル内容は以下のとおりです。 要するに、valid_documentation_coverageで設定されているドキュメント化条件に従ってないという警告です。
02:42:15 30 of 78 START test valid_documentation_coverage ............................... [RUN] 02:42:18 30 of 78 WARN 1 valid_documentation_coverage ................................... [[33mWARN 1[0m in 2.86s] 02:43:06 [33mWarning in test valid_documentation_coverage (models/marts/documentation/documentation.yml)[0m 02:43:06 Got 1 result, configured to warn if != 0 02:43:06 compiled code at target/compiled/dbt_project_evaluator/models/marts/documentation/documentation.yml/valid_documentation_coverage.sql
上記だけだと、具体的にどのモデルがドキュメント化できていないのか特定しづらいので、Databricks上で以下のようにクエリしてみます。
SELECT * FROM dbtdbx.test_dbtdbx.fct_undocumented_models;
以下のように結果を返してくれ、ドキュメント化できていないモデルを特定することができます。

全部詳細に説明したいところですが、文字数の制限上、修正例としてstg_customers、stg_orders、stg_paymentsに絞って説明します。 以下がschema.ymlファイル(models/staging /schema.yml)に記載されているstg_customers、stg_orders、stg_paymentsの内容に、たしかにdescriptionの記載漏れがあることが分かります。
version: 2 models: - name: stg_customers columns: - name: customer_id tests: - unique - not_null - name: stg_orders columns: - name: order_id tests: - unique - not_null - name: status tests: - accepted_values: values: ['placed', 'shipped', 'completed', 'return_pending', 'returned'] - name: stg_payments columns: - name: payment_id tests: - unique - not_null - name: payment_method tests: - accepted_values: values: ['credit_card', 'coupon', 'bank_transfer', 'gift_card']
以下が修正例で、各モデルに対してdescriptionを追加します。
models: - name: stg_customers description: "This staging table contains cleaned and transformed data related to customers from the source systems, ready for downstream analysis and modeling." columns: - name: customer_id description: "A unique identifier for each customer in the staging layer." tests: - unique - not_null
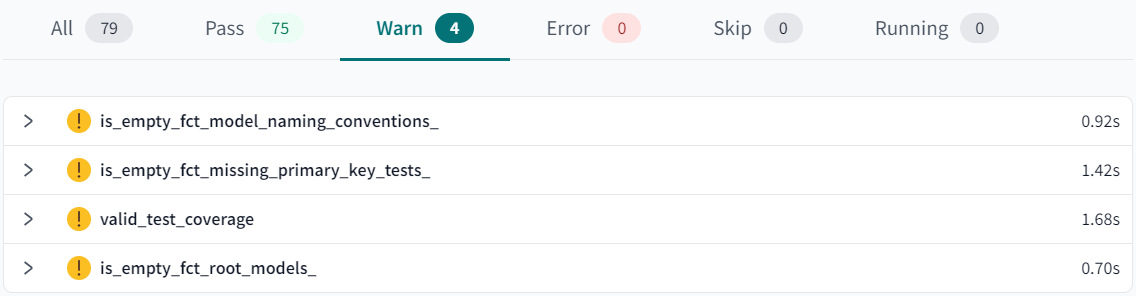
Warnの対象となった今回の14個のモデルついてドキュメント化した後、dbt build --select package:dbt_project_evaluatorを再度実行します。
すると、valid_documention_coverageとis_empty_fct_undocumented_models_の2つのWarnが消えました! (本ブログ内では、文字数の制限上、すべてのWarnの解消方法について紹介できませんが評判が良そうでしたら別ブログで紹介いたします。)
SQLFluffとGitHub Actionsを使用して自動で標準化するための仕組みをつくる
dbtは、SQLをベースとしたデータトランスフォーメーションをより効率的に実行する手助けをしてくれます。
加えて、SQLFluffを活用することでdbt projectの中で必要となるSQLをプロジェクトチームでのSQLフォーマットを統一することができます。
SQLFluffは、文法の間違いやフォーマットの不整合を検出してくれるのでモデルの数が多くなるほど運用・管理の際に品質管理のために重宝するLintツールです。
SQLFluffを利用するために、dbtとDatabricksと連携させる以下のようなconfigurationが必要です。
今回、GitHub Actionsを使用したSQLFluffの実装方法について以下で説明します。
sqlfluff.iniファイル(.github/workflows/sqlfluff.ini)に下記のコードを記述します。
[sqlfluff] templater = dbt dialect = sparksql
sqlfluff.ymlファイル(.github/workflows/sqlfluff.yml)に以下のとおり記述します。
name: sqlfluff project on: push: branches-ignore: - 'main' jobs: sqlfluff_project: name: test SQLFluff runs-on: ubuntu-latest env: DBT_PROFILES_DIR: ${{ github.workspace }}/.dbt DB_HOST: xxx-xxxxxxxxxxxxxxxx.xx.azuredatabricks.net DBX_TOKEN_0907: ${{ secrets.DBX_TOKEN_0907 }} steps: - uses: actions/checkout@v3 - uses: actions/setup-python@v2 with: python-version: 3.9 - name: Install SQLFluff, dbt templater, and dbt-core run: | pip install sqlfluff pip install sqlfluff-templater-dbt pip install dbt-databricks - name: dbt_dbx_sqlfluff run: sqlfluff lint models/*.sql --config .github/workflows/sqlfluff.ini
SQLFluffがどのような間違いを検知してくれるか確認するために、試しにmodels/customers.sqlの最後の行のselectを大文字にして(SELECT * from final)実行しましょう。
Run sqlfluff lint models/*.sql --config .github/workflows/sqlfluff.ini
=== [dbt templater] Sorting Nodes...
=== [dbt templater] Compiling dbt project...
=== [dbt templater] Project Compiled.
== [models/customers.sql] FAIL
L: 21 | P: 1 | LT02 | Expected indent of 4 spaces. [layout.indent]
L: 37 | P: 13 | RF02 | Unqualified reference 'amount' found in select with more
| than one referenced table/view.
| [references.qualification]
L: 41 | P: 21 | LT02 | Expected line break and indent of 4 spaces before 'on'.
| [layout.indent]
L: 42 | P: 1 | LT02 | Expected indent of 12 spaces. [layout.indent]
L: 65 | P: 11 | LT01 | Expected only single space before naked identifier.
| Found ' '. [layout.spacing]
L: 69 | P: 1 | CP01 | Keywords must be consistently lower case.
| [capitalisation.keywords]
上記の「Keywords must be consistently lower case.」で想定通りに間違いが検知されていることを確認できます。
最後に
本ブログでは、dbt-project-evaluator、SQLFluff、GitHub Actionsを使用したdbtプロジェクトの継続的な運用方法について紹介しました。
2024年11月6日(水)に本シリーズに関連したウェビナーも開催します。詳細は以下URLから。
私たちはDatabricksを用いたデータ分析基盤の導入から内製化支援まで幅広く支援をしております。
もしご興味がある方は、お問い合わせ頂ければ幸いです。
また、一緒に働いていただける仲間も募集中です!
APCにご興味がある方の連絡をお待ちしております。
※ APCは、Databricks Inc.の公式パートナーであり共同での内製化支援を実施しております。
また、dbt Labs, Inc. との販売パートナー契約を締結しており、dbtの販売と導入支援の提供が可能です。
