
はじめに
GLB事業部Lakehouse部の鄭(ジョン)です。
Databricks Lakehouse Platformが提供するデモであるdbdemosの中で、患者の再入院を減らすための医療予測モデルの構築するデモを紹介したいと思います。
デモ名: Lakehouse for HLS: Patient readmission
今回の投稿はdbdemosを活用して医療データを探求し、予測モデルを作成することを目標にしています。
目次
医療分野での予測
予測分析は店舗在庫管理、会員離脱率、顧客推薦サービスなど過去または現在のデータを使用して未来に発生する状況を予測し、これに備えるために使用します。
技術の発達に伴い、定型化されたデータだけでなく映像、イメージ、音声など多様な形態に対する分析も可能になりました。
これにより、今日の医療分野にも多くの変化が生じました。 個人の健康データ、期間別診療データおよびSNSのキーワードなどのデータを通じて病気を発見、治療する方式、伝染病に対する予防および危険度など多様な予測を試みています。伝染病ではなく糖尿病、心臓病、がんのような病気の場合、適切な事前措置を通じて発病の原因となる問題を解決して予防することができます。 このような疾病予防に関するモデルをDatabricks Lakehouseのデモを利用して構築することができます。
デモの紹介
今回のデモは患者の再入院を予測することをしています。
再入院とは退院後30日以内に同一または他機関に計画していない入院をやり直す場合のことです。
患者の再入院を予測するために、本デモでは外部および内部システムのデータをつかいます。患者人口統計、ログ健康記録(過去訪問、状態、アレルギーなど)およびリアルタイム患者入院、退院などの情報を活用してLakehouseとともにエンドツーエンドソリューションを構築します。
再入院の予測の価値
患者の再入院の予測は、多くの価値が得られると思います。
以下はDatabricksのデモ紹介を見て、私の考えを追加して作成しました。
患者:病気に対する発病リスクを低くすることができ、これによる治療費を節約できます。そして、再入院数値を通じて病院が提供する治療の質を調べることができます。
病院:入院、退院に対する切実な計画を立てて医療施設運営に対する負担を減らすことができ、患者のモニタリングと治療施術に対して正確度を高めて病院に対する信頼度を上昇させることができます。
保険会社:詐欺性保険請求を防止でき、疾病を事前に予防して補償金に対する負担を減らすことができます。
EDA
EDAはExploratory Data Analysisの略で探索的データ分析です。
データを多様な角度で観察しながらデータについて理解する過程です。
EDAは大きく視覚化と非視覚化に分かれます。
グラフィックス(Graphic): グラフ、画像を利用してデータを確認する方法でデータを一目で把握しやすいですが、大まかな形で把握します。
非グラフィック(Non-Graphic): 視覚化資料を使わずにSummary Statistics(平均、中央値、最大/最小値など)を通じて確認する方法で正確な値が必要なら適しています。
上記の2つの方法を利用して、dbdemosのデータを探索してみましょう。 Databricksには、独自に簡単なEDAが可能なツールがあります。 出力したTableの横に+ボタンを押すと、VisualizationとData Profileボタンが表示されます。
Visualizationを通じてグラフィック分析ができ、Data Profileを通じて非グラフィック分析ができます。
dbdemosデータの探索的データ分析
今回のdbdemosでは、patients_mlテーブルとencounters_mlテーブル、conditions_mlを重点的に扱っています。 Databricksの機能を使って、3つのテーブルに対する探索的データ分析をします。
patients_mlテーブル: 患者に関する情報が入っているテーブルです。
SQLを利用してデータを読み込みます。
select * from patients_ml

次のような意味でコラムで構成されています。(データを見ながら直接把握した意味です。参考用としてご覧ください。)
- Id: 患者ID
- BIRTHDATE: 生年月日
- DEATHDATE: 死亡日
- SSN: 社会保障番号
- DRIVERS: 運転免許
- PASSPORT: パスポート
- PREFIX: Mr, Mrs, Msまたはnull
- FIRST: 名前
- LAST: 苗字
- SUFFIX: PhD, MD, JDまたはnull
- MAIDEN: 結婚前の名前
- MARITAL: 結婚するかどうか(結婚、シングル、死別、離婚)
- RACE: 人種
- ETHNICITY: 民族性(nonhispanic, hispanic)
- GENDER: 性別
- BIRTHPLACE: 出身地
- ADDRESS: 住所
- CITY: 都市
- STATE: 州
- COUNTY: 自治州
- FIPS: Federal Information Processing Standard, COUNTYを識別する番号
- ZIP: 郵便番号
- LAT: 緯度
- LON: 経度
- HEALTHCARE_EXPENSES: 医療費
- HEALTHCARE_COVERAGE: 健康保険
- INCOME: 収入
- _rescued_data: AutoLoaderがスキーマ醜時に発生するエラーに備えたコラム
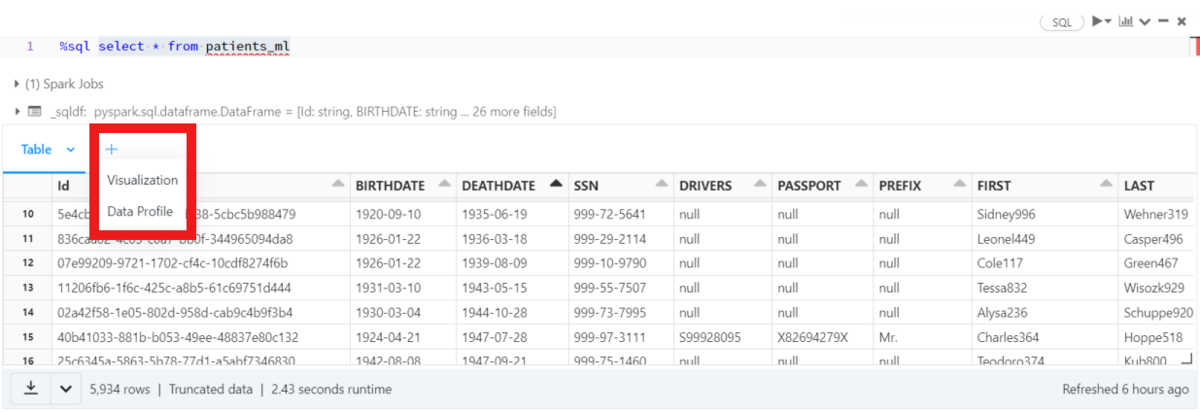
Databricksには、独自に簡単なEDAが可能なツールがあります。 出力したTableの横に「+」ボタンを押すと、VisualizationとData Profileボタンが表示されます。
Visualizationを通じてグラフィック分析ができ、Data Profileを通じて非グラフィック分析ができます。

まず、Data Profileです。
数値型変数とカテゴリ型変数を分類して表示します。
この機能により、数値型変数は欠損値と基本統計量、簡単なグラフを見ることができます。
カテゴリ型変数では、ユニークな値の個数、最も多くの変数とその頻度数を簡単に見ることができます。
数値型変数が7つ、カテゴリ型変数が21つあります。 Data Profileで知ることができるpatients_mlテーブルの情報は次のとおりです。
- HEALTHCARE_EXPENSESは平均181kドル、最低100ドル、最大6.74Mドルが発生した。

- HEALTHCARE_COVERAGEは平均396kドル、最低0ドル、最大7.54Mドルが発生した。

- INCOMEは平均120kドル、最低45ドル、最大998kドルだ。

- IDは23.5k(23,461)です。IDから患者数を知ることができます。正確な数はカーソルを上に載せて確認できます。

- DEATHDATEの欠損値が85.25%で、全体データに14.75%の死者データが含まれている。

- PREFIXは3種類のユニークな変数を持っており、18.9%の欠損値を持っている。 Mr.が9,533個で最も多い。

- MARITALは4種類のユニークな変数を持っており、31.77%の欠損値を持っている。 既婚者(M)は9,695人で最も多い。

- RACEは6種類のユニークな変数を持っており、欠損値がない。 白人が19.4k人で最も多い。

- ETHNICITYは2種類のユニークな変数を持っており、欠損値がない。 nonhispanicが20.9k人で最も多い。

- GENDERは2種類のユニークな変数を持っており、欠損値がない。 男(M)が11.8k
人で最も多い。 グラフを見た時、女性患者数と大差がない。

- 住所はCITY、STATE、COUNTYに分かれている。 STATEは一つのユニークな値で、すべての患者が同じ州に住んでいる。

この他にもSQLとPythonの様々な関数による探索的データ分析が可能です。
- SQLのDESCRIBE関数を通じてテーブルが持っているコラム、コラムのデータタイプを確認することができます。
%sql DESCRIBE patients_ml

- PythonのtoPandas()関数を通じてsparkテーブルをPandasに変形した後、以下のようなコードで各カテゴリ型データが持っている変数の種類を確認することができます。
%python patients_ml_pd = spark.table("patients_ml").toPandas() # Pandasに変形 for col in patients_ml_pd.columns: if patients_ml_pd[col].dtype == 'object' and patients_ml_pd[col].notna().all(): categories = patients_ml_pd[col].unique() print(f'[{col}] ({len(categories)})') print('\n'.join(categories)) print()

次に、patients_mlを利用して新しい変数を作ってみましょう。
現在、患者別のBIRTHDATEはありますが、年齢に関する変数はありません。
SQLのmonths_between()とcurrent_date()関数を利用して現在の年齢を計算することができます。
新しいageコラムとpatients_mlテーブルにある一部のコラムを抽出して、vw_patients_mlというVIEWを作成します。
%sql CREATE OR REPLACE VIEW vw_patients_ml AS SELECT Id,ceil(months_between(current_date(),BIRTHDATE)/12/5)*5 as age, GENDER, MARITAL, RACE, ETHNICITY,CITY, STATE, COUNTY, HEALTHCARE_EXPENSES, HEALTHCARE_COVERAGE, INCOME, DEATHDATE, LAT,LON, FIPS, ZIP FROM patients_ml
現在の日付とBIRTHDATEの違いを利用して年齢を計算しました。

性別でグループ化し、年齢順に並べ替えてからカウントします。
%sql select GENDER, age, count(*) as count from vw_patients_ml group by GENDER, age order by age

もう少し分かりやすくグラフで確認してみます。 今回はDatabricksのVisualizationを使用します。Visualization typeに様々なグラフがあります。

詳細については下記URLをご参照ください
learn.microsoft.com
左側でX column、Y column、Group byを設定することができます。
右側には設定に応じたグラフのプレビューが表示されます。

今回はAreaグラフで確認してみます。
どちらの性別も60代の患者が最も多いです。
年齢別患者数の動向は似ています。
死者も含まれているデータなので、100歳以上の患者がいます。

年齢グラフです。

encounters_mlテーブル: 入院に関する情報が入っているテーブルです。
SQLを利用してデータを読み込みます。
select * from encounters_ml

次のような意味でコラムで構成されています。(データを見ながら直接把握した意味です。参考用としてご覧ください。)
- Id: 診療ID
- PATIENT: 患者ID
- ORGANIZATION: データマスキングで確認不可
- PROVIDER: データマスキングで確認不可
- PAYER: データマスキングで確認不可
- ENCOUNTERCLASS: 診療クラス(入院患者、外来患者など)
- CODE: ENCOUNTERCLASSのCODE
- DESCRIPTION: 診療についての説明
- BASE_ENCOUNTER_COST: 基本費用
- TOTAL_CLAIM_COST: 総請求費用
- PAYER_COVERAGE: 保障金額
- REASONCODE: 疾病コード
- REASONDESCRIPTION: 病気名
- _rescued_data: AutoLoaderがスキーマ醜時に発生するエラーに備えたコラム
- START: 診療開始時間
- STOP: 診療終了時間
encounters_mlテーブルのData Profileです。
数値型変数が7つ、カテゴリ型変数が9つあります。

Data Profileで知ることができるencounters_mlテーブルの情報は次のとおりです。
- BASE_ENCOUNTER_COSTは平均113.76ドル、最低75ドル、最大146.18ドルが発生した。

- TOTAL_CLAIM_COSTは平均2,442.09ドル、最低75ドル、最大1.71Mドルが発生した。

- PAYER_COVERAGEは平均1,745.92ドル、最低0ドル、最大1.21Mドルが発生した。全体の31.7%の患者が0ドルを受け取る。

- ENCOUNTERCLASSは10種類のユニークな変数を持っており、欠損値がない。
ambulatoryが937kで最も多い。

- DESCRIPTIONは68種類のユニークな変数を持っており、欠損値がない。 Encounter for problem (procedure)が593kで最も多い。

- REASONDESCRIPTIONは169種類のユニークな変数を持っており、50.18%の欠損値を持っている。Chronic kidney disease stage 4 (disorder)が343kで最も多い。

診療記録に患者の情報を追加します。
- encounters_mlテーブルをpatients_mlテーブルとjoinを通じて結合してencounters_patientsテーブルを作ります。
- joinをする時、コラム名が同じなら[COLUMN_ALREADY_EXISTS] というエラーになることがあります。
- すべてのテーブルにIdコラムがあるので、encounters_mlテーブルのコラム名を変えてからjoinします(encounters_Id)。
- patients_mlテーブルのIdはencounters_mlテーブルのPATIENTです。
%sql CREATE OR REPLACE TABLE encounters2 AS SELECT * FROM encounters_ml; -- encounters_mlのようなencounters2テーブルを生成 ALTER TABLE encounters2 RENAME COLUMN Id TO encounters_Id; -- コラム名変更 CREATE OR REPLACE TABLE encounters_patients AS SELECT * FROM encounters2 as en JOIN vw_patients_ml as pa ON en.PATIENT = pa.Id; select * from encounters_patients

性別による診療数の割合グラフです。約5%の差があります。
男性が女性よりもっと診療を受けました。

Areaグラフで診療記録数を確認しました。
約55歳未満は女性患者の診療数が多く、55歳以上は男性患者の診療数が増加しました。

County別診療数分布です。
Middlesex County居住者が最も多く診療を受け、Nantucket County居住者が最も少ない診療を受けました。
その差は約162倍です。

conditions_mlテーブル: 患者さんの体調に関する情報が入っているテーブルです。
SQLを利用してデータを読み込みます。
select * from conditions_ml

次のような意味でコラムで構成されています。(データを見ながら直接把握した意味です。参考用としてご覧ください。)
- START: 症状の発症日
- STOP: 症状の完治日
- PATIENT: 患者ID
- ENCOUNTER: 診療ID
- CODE: CONDITIONSのCODE
- DESCRIPTION: CONDITIONSについての説明
- _rescued_data: AutoLoaderがスキーマ醜時に発生するエラーに備えたコラム
conditions_mlテーブルのData Profileです。
数値型変数が1つ、カテゴリ型変数が6つあります。

Data Profileで知ることができるconditions_mlテーブルの情報は次のとおりです。
- STOPは18.7%の欠損値を持っている。

- DESCRIPTIONは288種類のユニークな変数を持っており、欠損値がない。Medication review due (situation)が445k
で最も多い。

診療記録に患者が追加されたテーブルにコンディション テーブルを追加します。
- 今回はPythonでspark関数を利用してテーブルをjoinしてみます。
- 上から作ったencounters_patientsテーブルをconditions_mlテーブルとjoinを通じて結合してencounters_patients_conditionsテーブルを作ります。
- encounters_patientsテーブルのencounters_Idはconditions_mlテーブルのENCOUNTERです。
%python df2 = spark.table("encounters_patients").join(spark.table("conditions_ml"), col("encounters_Id")==col("ENCOUNTER")) display(df2)

性別によるDESCRIPTION(コンディション)分布を見てみましょう。
- 上位20個の変数です。
%python df = spark.table("encounters_patients").join(spark.table("conditions_ml"), col("encounters_Id")==col("ENCOUNTER")) \ .groupBy(['GENDER', 'conditions_ml.DESCRIPTION']).count() \ .orderBy(F.desc('count')).limit(20).toPandas() px.bar(df, x="DESCRIPTION", y="count", color="GENDER", barmode="group")

- 性別によるDESCRIPTION分布です。

conditions_mlテーブルを使用してcohortテーブルを作成します。
- コホートとは、同じ特性を持つ集団を意味します。 特定の病気に対する発生率と時間の経過による変化を追跡できます。
%python import random def create_save_cohort(name, condition_codes = []): cohort1 = (spark.sql('select patient, to_date(start) as cohort_start_date, to_date(stop) as cohort_end_date from conditions_ml') .withColumn('id', F.lit(random.randint(999999, 99999999))) .withColumn('name', F.lit(name))) if len(condition_codes)> 0: cohort1 = cohort1.where(col('CODE').isin(condition_codes)) cohort1.write.mode("append").saveAsTable('cohort2') create_save_cohort('COVID-19-cohort', [840539006]) create_save_cohort('heart-condition-cohort', [1505002, 32485007, 305351004, 76464004])
cohortテーブルには、特定の病気に関するデータが含まれています。
%sql SELECT * FROM cohort2

まとめ
今回はdbdemosを利用してヘルスケアデータを調べてみました。
Databricksの機能とPythonの関数を利用して探索的データ分析を進めました。
SQLとPython、両方でテーブルをjoinする方法を勉強しました。
特定の病気に対する分析ができるchortテーブルを作成しました。
今回の投稿でヘルスケアデータを見て、医療予測モデルに使うフィーチャーを選べるようになったと思います。
最後までご覧いただきありがとうございます。
引き続きどうぞよろしくお願い致します!

私たちはDatabricksを用いたデータ分析基盤の導入から内製化支援まで幅広く支援をしております。
もしご興味がある方は、お問い合わせ頂ければ幸いです。
また、一緒に働いていただける仲間も募集中です!
APCにご興味がある方の連絡をお待ちしております。