
はじめに
GLB事業部Lakehouse部の鄭(ジョン)です。
この記事では前回記事でご紹介しましたKDB.AIのサンプルコード実習をご紹介しようと思います。
KDB.AIは世界最速の時系列データベース及び分析エンジンであるkdb+で駆動されるVectorデータベースで、EndpointとAPI Keyを通じて接続できます。
Early Access Programが最近開始されて無料アカウントで体験が可能です。
アカウント作成とEndpoints&API Keys作成方法は前回の記事にあります。 techblog.ap-com.co.jp
サンプルコードの実習のため、アカウント、Endpoints、API Keysの作成をお願い致します。
今回はサンプルの中でLangChain and RAGをご紹介致します。
記事の順番はLangChain and RAGの紹介、OpenAI API Key及びHugging Face API Tokenの作成方法、サンプルコード実習の流れです。
目次
サンプルコード(LangChain and RAG)の紹介
LangChain and RAGはLangChainのtextsplitterとKDB.AIを使用した類似性検索の実習サンプル及び使用者の質問に外部の知識を活用した答えが可能なRAGの実習サンプルです。
LLMに使うTXTファイルを読み込んで、LangChainのtextsplitterを利用して読み込んだドキュメントを500文章のかたまりに合わせます。
各500文章のかたまりをリスト化し、Embeddingをした後、KDB.AIのsimilarity_searchを通じて距離基盤の類似性検索を行います。
そしてload_qa_chainとRetrievalQAを使ってRAGを作成した後、similarity_searchと同じ質問をして各結果を比較します。
実習では、次のような過程を行います。
➀ TextLoaderを使ってTXTドキュメントを読み込んで、LangChainのtext splitterを使って、読み込んだドキュメントを500文章のかたまりに合わせます。
➁ ➀で作った500文章のかたまりをリスト化し、OpenAIのモデルでEmbeddingします。
③ KDB.AIにテーブルを作成してEmbeddingを保存します。
④ 気になる内容をKDB.AIのsimilarity_searchを利用して検索します。
➝ 最も類似した文章のかたまりが出ます。
⑤ RAGのOpenAIとHuggingFaceHubを使ってLLMモデルを作成します。
⑥ ④で作成した最も類似度の高い章のかたまりを⑤で作ったLLMモデルに④の質問と一緒に入れます。
➝ OpenAIとHuggingFaceHubのLLMモデルから外部知識に基づいた結果を出します。
⑦ GPT-3.5を使用したRetrievalQAを使ってQAボットを作ります。
as_retrieverというVector Storeを検索機に変換するメソッドにKDB.AIのVector Storeを入力します。
⑧ ⑦で作成したQAボットに④の質問を入力します。
➝ KDB.AIのVector Storeと外部知識に基づいた結果を出します。
事前準備事項及び準備方法
今回の実習ではOpenAI API KeyとHugging Face API Tokenが必要です。
サンプルコードの実習のため、OpenAI API KeyとHugging Face API Tokenの作成をお願い致します。
作成方法は以下でご紹介いたします。
OpenAI API Keyの作成方法
- アカウントの作成
➀ 以下のサイトでアカウントを作成します。
platform.openai.com
ホームページでSign upボタンを押します。
(アカウントをすでにお持ちの方はLoginしていただいた後、「API Keyの作成」からご確認ください。 )

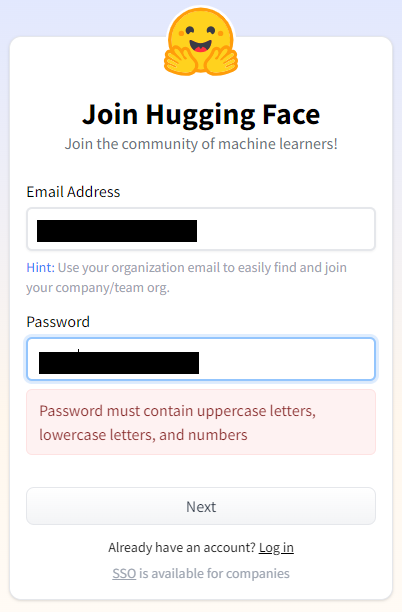
➁ 使用するメールアドレスとパスワードを入力します。
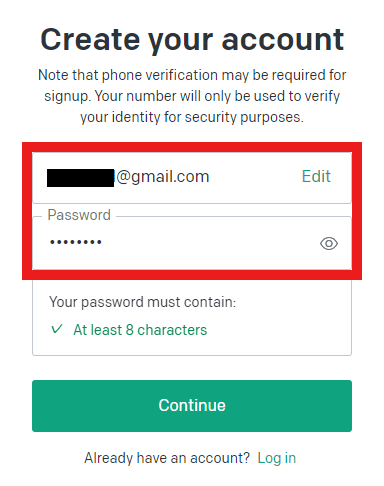
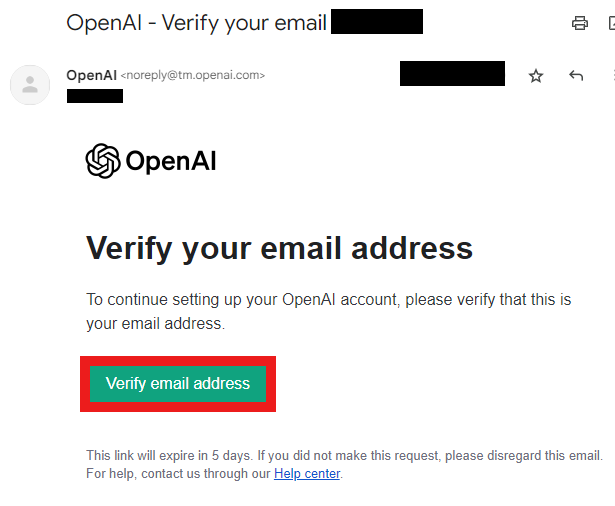
③ メール認証をします。
(「OpenAI - Verify your email」という件名のメールを開いてVerify email addressボタンを押します。 )
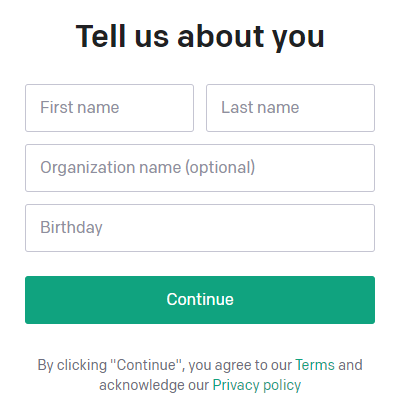
④ OpenAI ホームページに戻ってまたログインした後、自分の個人情報を入力します。
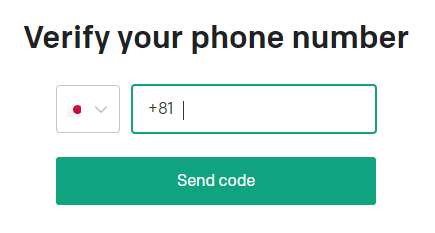
⑤ 電話番号の認証が終わったら、アカウントが作成されます。
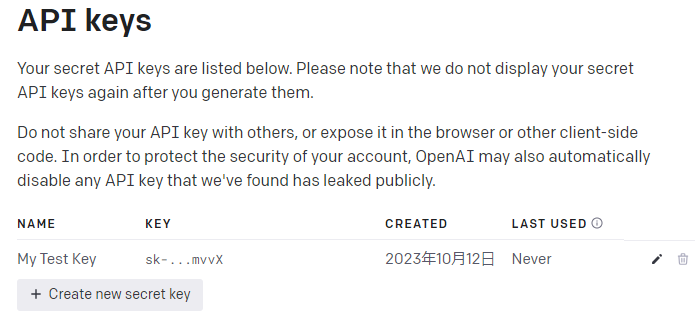
- API Keyの作成
➀ 自分のプロフィールを押した後、View API keysを押します。
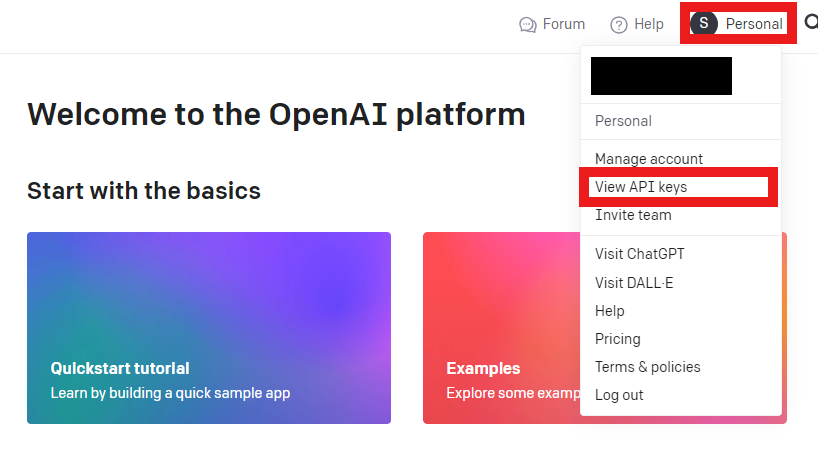
➁ API Keyを作成します。
Create new secret keyボタンを押します。
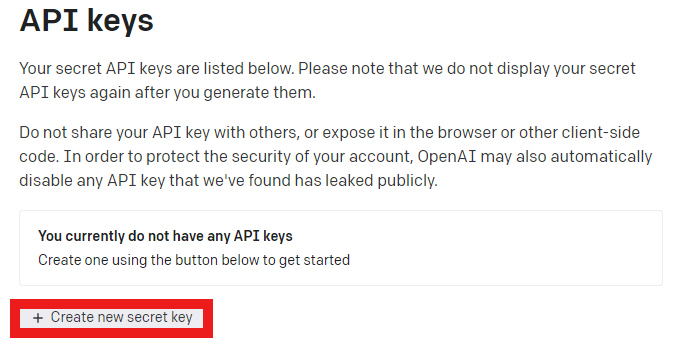
API Keyの名を作成して、Create new secret keyボタンを押します。
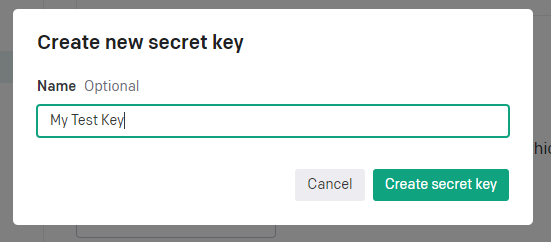
API Keyが作成されます。(もう一度見ることはできませんので、別に保管してください。)
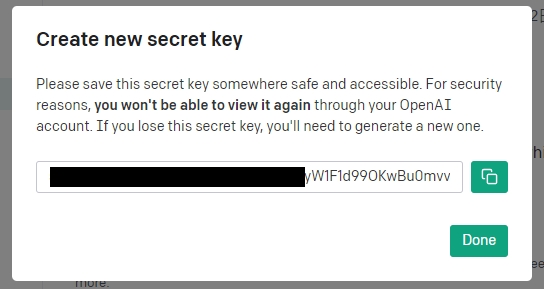
③ API KeysのページでAPI Keyの管理が可能です。
既存のキーの名前の変更または削除、新しいキーの作成ができます。
Hugging Face API Tokenの作成方法
- アカウントの作成
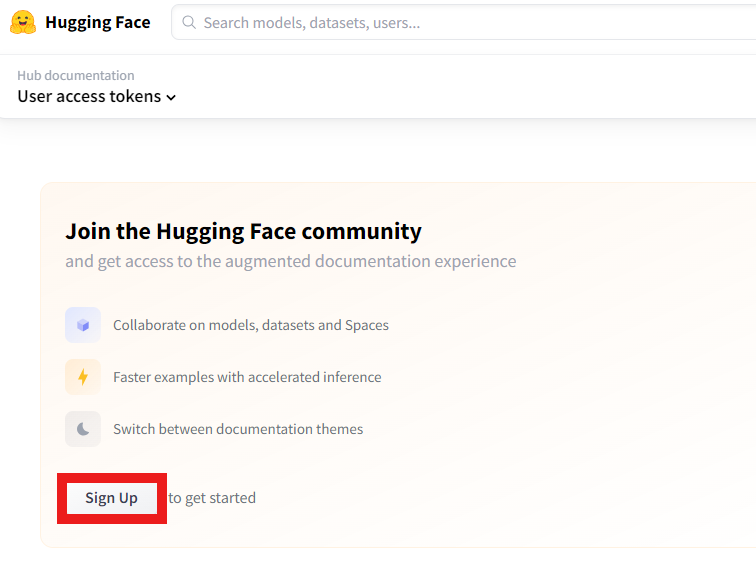
➀ 以下のサイトでアカウントを作成します。
huggingface.co
ホームページでSign upボタンを押します。
(アカウントをすでにお持ちの方はLoginしていただいた後、「API Keyの作成」からご確認ください。 )
➁ 使用するメールアドレスとパスワードを入力します。
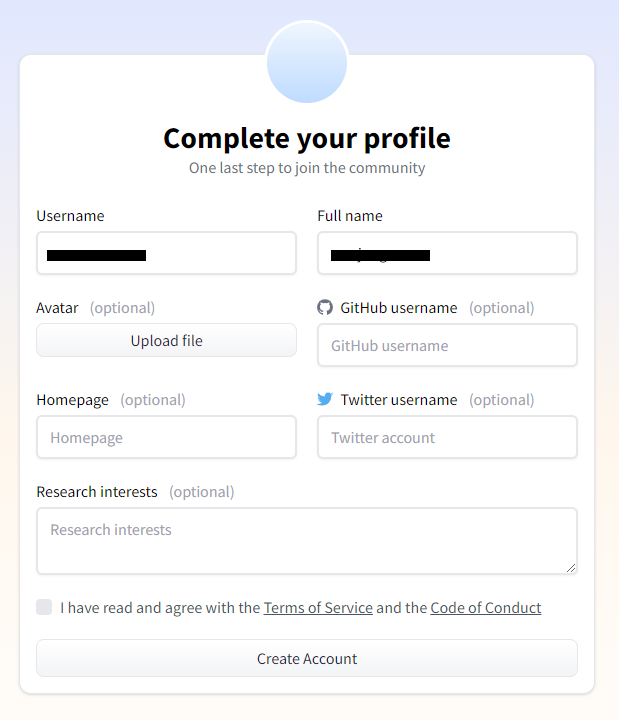
③ 自分のプロフィールを作成します。
④ メール認証をします。
「[Hugging Face] Click this link to confirm your email address」という件名のメールを開いてリンクを押したらアカウントが作成されます。
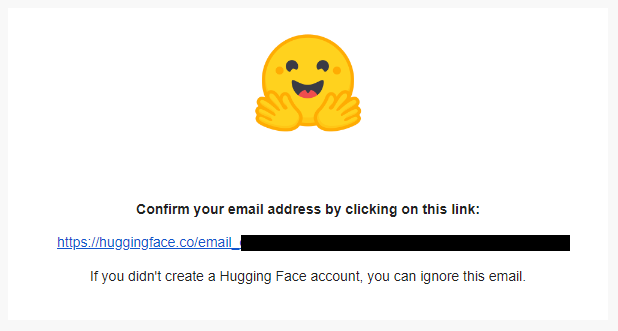
- API Keyの作成
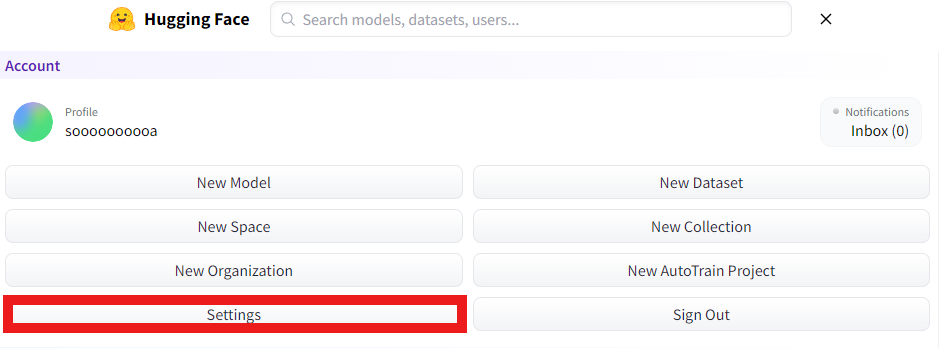
➀ Hugging Faceにログインした後、メニューのボタンを押します。

➁ Settingsを押します。
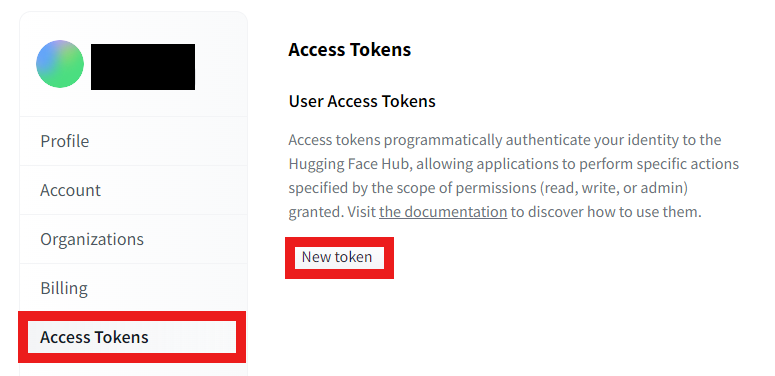
③ Access Tokensを押してNew tokenを押します。
④ Tokenを作成します。
Tokenの名を作成してRoleはwriteを選択します。
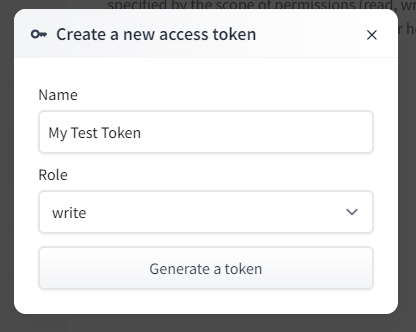
Generate a tokenを押したらTokenが作成されます。
サンプルコード実習
実習はKDB.AIを引用して行いました。 kdb.ai
サンプルコードをDatabricksのWorkspace上で実習してみます。
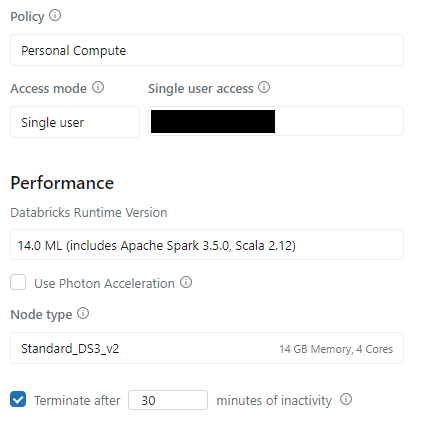
0. DatabricksのCluster
Clusterは14.0 ML (includes Apache Spark 3.5.0, Scala 2.12)を使います。
上記のClusterはPython3.10.12バージョンです。
1. Dependenciesのインストール
いくつかのライブラリをインストールします。
%pip install pandas pyarrow openai pypdf tiktoken kdbai-client git+https://github.com/KxSystems/langchain.git@KDB.AI#subdirectory=libs/langchain -q
- 使うライブラリをインポートします。
# vector DB from getpass import getpass import os import pandas as pd import kdbai_client as kdbai
# langchain packages from langchain.chains import RetrievalQA from langchain.chat_models import ChatOpenAI from langchain.document_loaders import TextLoader from langchain.text_splitter import RecursiveCharacterTextSplitter from langchain.embeddings import OpenAIEmbeddings from langchain.vectorstores import KDBAI from langchain import HuggingFaceHub from langchain.llms import OpenAI from langchain.chains.question_answering import load_qa_chain
2. API Keysの設定
上記で作成したOpenAI API KeyとHugging Face API Tokenを設定します。
# OPENAI_API & HUGGINGFACEHUB KEYの接続 os.environ['OPENAI_API_KEY'] = getpass('OpenAI API Key: ') os.environ['HUGGINGFACEHUB_API_TOKEN'] = getpass('Hugging Face API Token: ')
赤いボックスをクリックして自分のOpenAI API Keyを入力してください。

OpenAI API Keyが正常に作動したら、次のようにHugging Face API Token入力ウィンドウもできます。
Hugging Face API Token入力ウィンドウをクリックして自分のHugging Face API Tokenを入力してください。

OpenAI API KeyとHugging Face API Tokenが設定されました。

3. データの用意
今回は米大統領が米議会に送る国政メッセージをデータで使います。
TXTドキュメントをロードします。
- TextLoaderを使ってTXTドキュメントを読み込みます。
- ドキュメントはLLMに要請することです。
- LangChainのtext splitterの"RucursiveCharacterTextSplitter"を使って、読み込んだドキュメントを500文章のかたまりに合わせます。
- 各500文章のかたまりをリスト化します。
- "TXTをアップロードした自分のpath"にTXTのpathを入力します。
# TextLoaderを使ってTXTドキュメントを読み込む # ドキュメントはLLMに要請すること loader = TextLoader("TXTをアップロードした自分のpath") doc = loader.load() # langchainのtext splitterの"RucursiveCharacterTextSplitter"を使う # 入れたドキュメントを500文章のかたまりに合わせる text_splitter = RecursiveCharacterTextSplitter( chunk_size = 500, chunk_overlap = 0 ) # ロードしたドキュメントを500文章のかたまりに合わせる chunks = text_splitter.split_documents(doc) # 500文章のかたまりをリスト化する texts = [p.page_content for p in chunks] # データの確認 texts[0]

Embeddingsをします。
- Embeddingはテキストのようなデータを1つの座標として表現することで、これらの値は類似のテキスト検索、クラスタリング、推奨サービスなどに活用できます。
- OpenAIEmbeddingsを使ってEmbeddingを作成します。
- OpenAIが推奨するモデルで、簡単で安価な特徴がある「text-embedding-ada-002」のモデルを選択します。
embeddings = OpenAIEmbeddings(model='text-embedding-ada-002')
- Embeddingと「text-embedding-ada-002」に関する詳しい説明は以下のリンクをご確認ください。 platform.openai.com
4. KDB.AIにEmbeddingを保存
EndpointsとAPI Keysを使ってKDB.AIのSessionに接続します。
- EndpointsとAPI Keysの作成方法は前回のブログにあります。
"自分のKDB.AI ENDPOINT"に自分のKDB.AIのENDPOINTを入力します。
"自分のKDB.AI API KEY"に自分のKDB.AIのAPI KEYを入力します。
import kdbai_client as kdbai KDBAI_ENDPOINT = "自分のKDB.AI ENDPOINT" KDBAI_API_KEY = "自分のKDB.AI API KEY" session = kdbai.Session(api_key=KDBAI_API_KEY, endpoint=KDBAI_ENDPOINT)
Embeddingを保存するKDB.AIのテーブルのSchemaを定義します。
検索に使用するindexとmetricを選択します。
今回のサンプルではFLATをindexで使います。
FLATはすべてのVector間の距離を計算する方式なので効率面では落ちる可能性がありますが、正確な値を見つけます。
類似度metricはEuclidean distanceのL2を使います。
Euclidean distanceのL2は高次元スペースで座標の距離を計算します。
KDB.AIで扱うindexの詳細は以下のページをご確認ください。
KDB.AIで扱うmetricの詳細は以下のページをご確認ください。
schema_rag = {
"columns": [
{"name": "id", "pytype": "str"},
{"name": "text", "pytype": "bytes"},
{
"name": "embeddings",
"pytype": "float32",
"vectorIndex": {"dims": 1536, "metric": "L2", "type": "flat"},
},
]
}
テーブルを作成します。
- session.create_table()関数でrag_langchainテーブルを作成します。
table = session.create_table('rag_langchain', schema_rag)
KDBAI.from_textsを利用してテーブルにEmbeddingを入力します。
vecdb_kdbai = KDBAI.from_texts(session, 'rag_langchain', texts=texts, embedding=embeddings)
table.query()
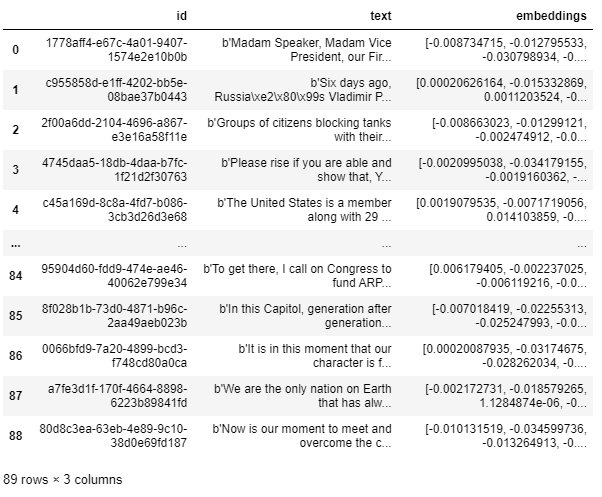
KDB.AIにEmbeddingが保存されましたのでセマンティック検索ができます。
5. 類似性検索
KDB.AIのVector Storeで気になる点を検索してみます。
- 検索はEuclideandistanceを使用して類似性を計算します。
- 最も類似した文章のかたまりが出ます。
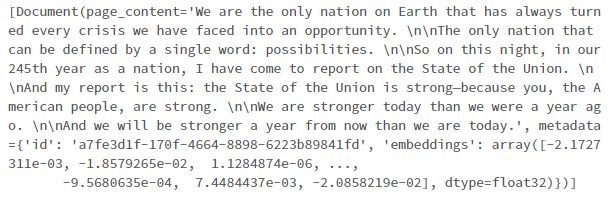
query = "what are the nations strengths?" query_sim = vecdb_kdbai.similarity_search(query) print(query_sim)
6. Retrieval-augmented Generation(RAG、検索により強化した文章生成)
RAGは検索した時に結果に外部の知識に基づいた最新情報を提供する技術です。
今回のサンプルではRAGの中でload_qa_chainとRetrievalQAを使います。
二つの方法の特徴をLangChain公式ホームページのQAチャットボットに聞いてみました。 python.langchain.com
load_qa_chain: load_qa_chainは、OpenAIのようなLLMを使用してあらかじめ構成された質問応答チェーンをロードするLangChainライブラリの機能で、QAチェーンに必要なプロンプト、LLMなどの設定を処理します。
RetrievalQA: 検索増強QAアーキテクチャを具現するラングチェーン内のクラスで、検索機と読み取り機LLMを結合して質問に答えます。

➀ OpenAIとHuggingFaceHubを使用したload_qa_chain
OpenAIとHuggingFaceHubを使ってLLMモデルを作成します。
llm_openai = OpenAI(model="text-davinci-003", max_tokens=512) llm_flan = HuggingFaceHub(repo_id="google/flan-t5-xxl", model_kwargs={"temperature":0.5, "max_length":512})
二つのモデルにload_qa_chainを適用してチェーンを作ります。
chain_openAI = load_qa_chain(llm_openai, chain_type="stuff") chain_HuggingFaceHub = load_qa_chain(llm_flan, chain_type="stuff") query = "what are the nations strengths?" #最も類似度の高い章のかたまりを探す query_sim = vecdb_kdbai.similarity_search(query) #モデル別、チェーンを行う print("OpenAI Response: ") print(chain_openAI.run(input_documents=query_sim, question=query),'\n') print("HuggingFaceHub Response: ") print(chain_HuggingFaceHub.run(input_documents=query_sim, question=query))

➁ GPT-3.5を使用したRetrievalQA
RetrievalQAを使ってQAボットを作ります。
- queryは同じように"what are the nations strengths?"を使います。
- as_retrieverというVector Storeを検索機に変換するメソッドにKDB.AIのVector Storeを入力します。
K = 10 qabot = RetrievalQA.from_chain_type(chain_type='stuff', llm=ChatOpenAI(model='gpt-3.5-turbo-16k', temperature=0.0), retriever=vecdb_kdbai.as_retriever(search_kwargs=dict(k=K)), return_source_documents=True) print(query) print("-----") print(qabot(dict(query=query))["result"])
アメリカ大統領がアメリカ議会の送った国政メッセージに盛り込まれた内容とRetrievalQAを通じて得た外部知識をもとに国家の力に対する回答を受けました。

7. テーブルの削除
テーブルを削除します。
table.drop()
![]()
まとめ
今回の投稿ではDatabricks上で行いましたKDB.AIのサンプルコード、LangChain and RAGの紹介とDatabricksサンプルコード実習についてご紹介しました。
そして実習を通じて次のようなものを学びました。
- LangChainのtext splitterの"RucursiveCharacterTextSplitter"を使って、読み込んだドキュメントを文章のかたまりに合わせる方法
- load_qa_chainを通じてOpenAIとHuggingFaceHubのLLMモデルを作成する方法
- RetrievalQAを使ってQAボットを作成する方法
次回の投稿では、今回の投稿のようにKDB.AIの他のサンプルコードをDatabricks上で検証してみて、これについてご紹介したいと思います。
最後までご覧いただきありがとうございます。
引き続きどうぞよろしくお願い致します!

私たちはDatabricksを用いたデータ分析基盤の導入から内製化支援まで幅広く支援をしております。
もしご興味がある方は、お問い合わせ頂ければ幸いです。
また、一緒に働いていただける仲間も募集中です!
APCにご興味がある方の連絡をお待ちしております。