
はじめに
こんにちは、GLB事業部Lakehouse部の陳(チェン)です。
Lakehouse部では、Databricksプラットフォーム上でKDB.AIを利用した検証を行っています。 弊社の鄭(ジョン)の記事で、KDB.AIの紹介や利用開始の登録法が紹介されています。
ご興味のある方は鄭の記事をご覧になってください。
本記事では、Databricks上でコーティングを行って、音楽推奨システムの構築から利用までのご紹介です。 Kaggleからのデータ取得(前作業)とDatabricks上でのコーティング(本作業)に分けて、順番に紹介しています。 より詳しい内容はKDB.AIのlearning hubをご参照してください。 kdb.ai
目次
前作業
Kaggleからの楽曲データ取得についてのご紹介です。
楽曲データ取得
Kaggleというデータ系のプラットフォームから取得できる、Sportifyが提供している楽曲のデータセットを使用します。 取得先は「 Spotify dataset | Kaggle 」になります。 取得するために、Kaggleのユーザ登録が必要となります。詳細は割愛とさせていただきます。 幾つかのファイルがデータセットに含まれており、本デモでは「data.csv」のみ使用します。 事前に、「data.csv」をDatabricksのDBFSにアップロードしておきます。
data.csvの中に様々な情報が入っており、本デモで使われるカラムについて紹介します。文字列として保存され、楽曲の情報に関するカラムはartists(アーティスト名)、name(楽曲名)を使用します。解析の中にこれらのカラムに含まれている文字列がベクトル化されます。曲調に関するカラムはvalence、acousticness、danceability、energy、instrumentalness、liveness、loudness mode、popularity、speechiness、tempoであり、こちらの情報は数値化として保存されて、解析の中でそれぞれのカラムを正規化(標準化)します。
本作業
Databricksのプラットフォーム上でコーティングしていきます。必要なモジュールの読み込み、User Defined Function(UDF)の準備、データの読み込み・整形、Vector Embeddingの作成、KDB.AI上のVector DBの登録、実際利用について紹介します。 なお、Databricks上のクラスタは14.0ML以上のものを使用するのがお勧めです。
モジュールの準備
Fig_1では、必要なライブラリ(gemsinとkdbai_client)のインストールとモジュール(pandas、numpy、nltkなど)のインポートを行います。

UDFの作成
作成されるデータフレームやEmbeddingの中身を確認するためのUDFを前もって用意しておきます。 「show_df」はデータフレームの形とデータフレームのヘッダーを表示するUDFです。 「show_embeddings」は、embeddingsに含まれている総数、カラム数、カラム名を表示するUDFです。

データの読み込み・整形
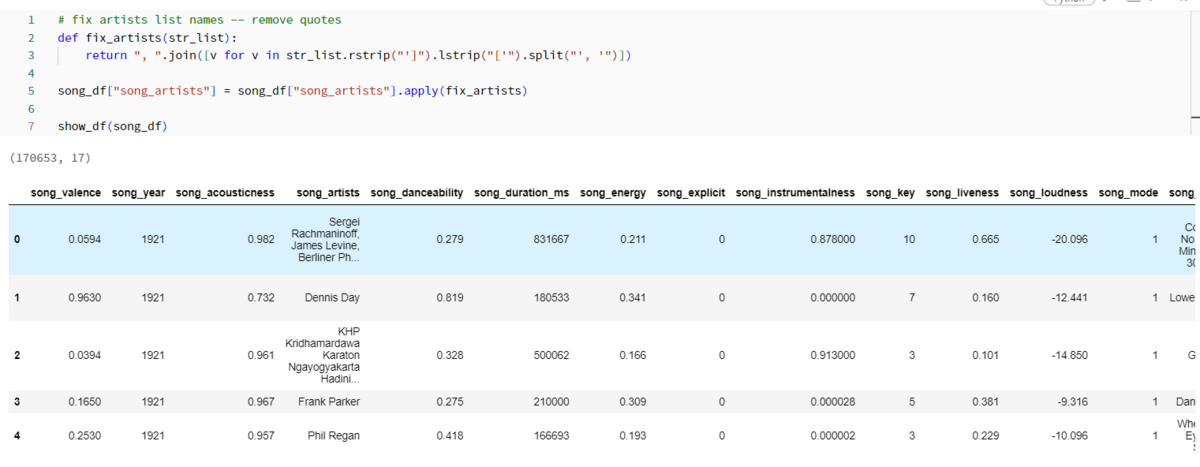
Fig_3の通り、data.csvをDataFrameとして読み込んだ後に、すべてのカラム名の前に「song_」というプリフィックスを付けます。同時に、不要なカラム「song_id」と「song_release_date」を削除します。

Fig_4ではカラム「song_artists」に含まれている不要な文字「['」と「']」を削除します。 同時に、カラム「song_name」と「song_artist」を結合し、カラム「song_description」を作成します。最後に、重複削除を行って、データ整形が終わりました。
Vector Embeddingsの作成
文書(sentence)を意味ある単位を分割します(Cmd19)。英語の場合、ほとんどはスペースを区切りとして文書を単語化することになります。 例として、Cmd20のような文書はCmd21の通り、単語毎に分解されました。

次に、Word2Vecを利用し、embedding modelを作成します。このプロセスは、文章に含まれる単語を「数値ベクトル」に変換し、その意味を把握していく自然言語処理の手法です。パラメータの設定により結果が変わりるため、ご興味のある方はパラメータを変更して結果の変化を体感してください。

Fig_7では、Fig_6で作成したembedding modelにtokenised_song_descsを入れ、tokenisedされた単語群をベクトル化します。このベクトル化された単語群をcategorical_embeddingsという配列に入れます。

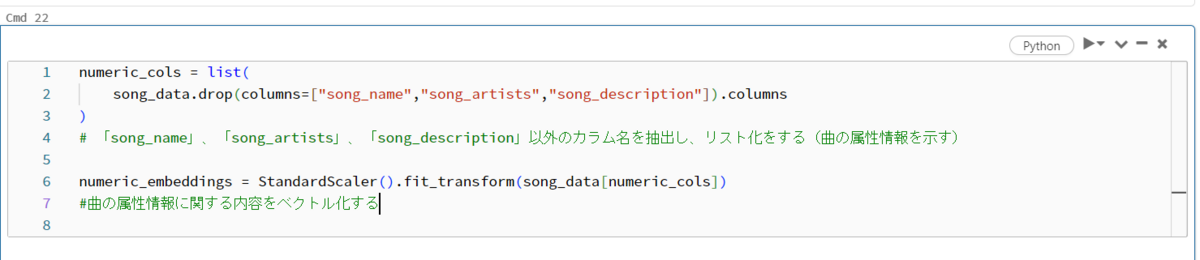
Fig_8は数値データの標準化・正規化の作業を行います。まず、元テーブルから文字列のカラム(「song_name」、「song_artists」、「song_description」)を除外し、新しいテーブル(numerical_col)を作成します。テーブルnumerical_colの数値を正規化・標準化をし、embedingとしてnumeric_embeddingsに入れます。
これまでに作成された二つのEmbedding、「numeric_embeddings」と「categorical_embeddings」を一つに結合します(Fig_9)。

最後に、「song_name」、「song_artists」、「song_description」の情報をそのまま残しておいて、Embeddingと結合して、Embeddingsのデータベースの準備が完了しました(Fig_10)。

KDB.AI上にVector Databaseを作成
KDB.AI Sessionに接続
Fig_11の通り、EndpointとAPI KEYを利用し、KDB.AIに接続します。セルのコマンド1~3まで入力し、実行することによって、EndpointとAPI KEYの入力をリクエストされます。相応する内容を入力してください。エラーなどが起きなければ、実行完了後にDatabrics上でKDBのEmbedded Databaseに接続することになります。

KDB.AI上にDatabaseを登録
先ほど作成したembedded_song_dfのカラム毎のデータ型を確認します。四つのカラム(song_name, song_artists, song_year, song_embeddings)が含まれていて、型も明示されています(Fig_12)。

Fig_13ではカラムと型をもとにスキーマを定義します。カラム「song_embeddings」は階層構造になっており、定義の仕方が他のカラムと異なっていることにご注意ください。

定義済みのスキーマを利用してDatabase用のテーブル(song)の枠を作成します。登録が成功した場合、KDB.AI上も確認できます。

次に、データをデータベースに書き込む(インサート)作業を行います。その前に、テーブルに必要なメモリを算出します。そして、チャンクサイズの調整も行います。最後に、Fig_14で作成されたテーブルをデータベースに書き込みます(Fig_15)。

登録したデータベースを利用してみる
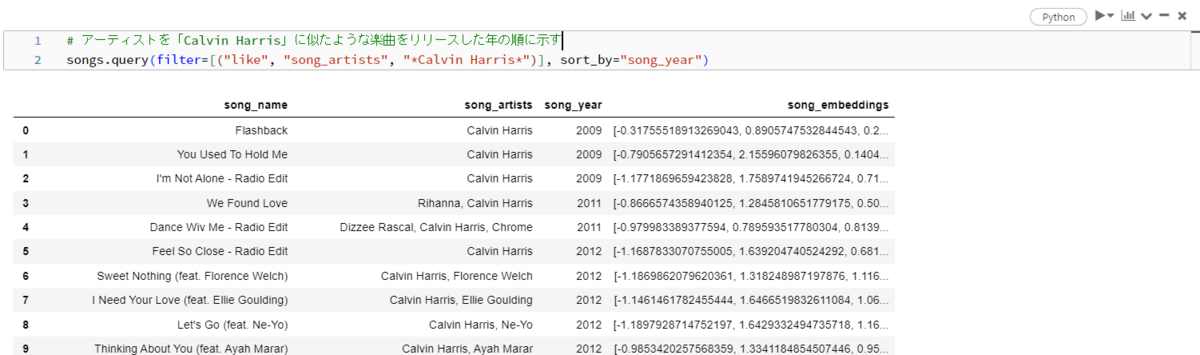
データベースからアーティストの名前を指定して情報を示してもらいます。ここでは「Calvin Harris」と指定します。アーティスト欄に「Calvin Harris」が含まれている楽曲の情報が表示されています。
さらに、アーティストの名前と楽曲の名前を指定して情報を示してもらいます。Fig_17では、アーティストを「Calvin Harris」に加え、楽曲を「We Found Love」と指定しています。希望通りに、アーティスト名と楽曲名が一致している情報が表示されます。

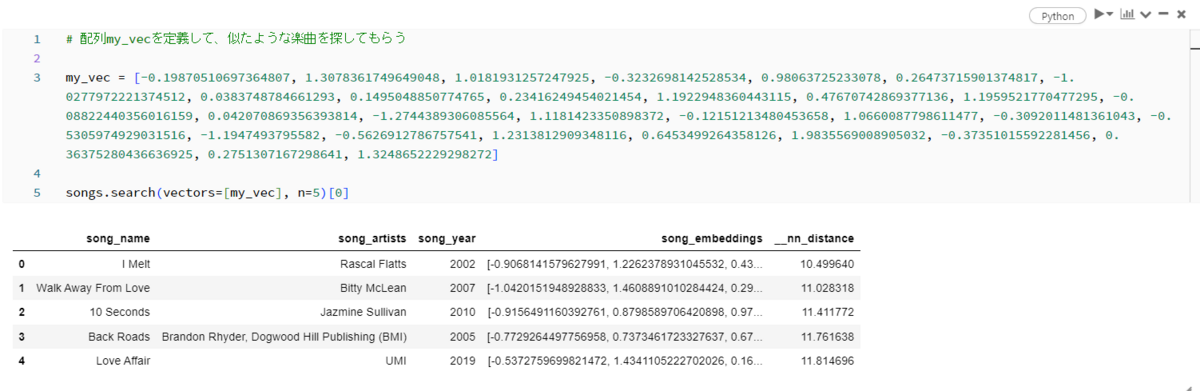
最後に、Fig_18みたいに配列に数値を指定して、その配列をベクトルとして指定して、その配列に似たような楽曲を示してもらいます。色な楽曲の情報が示されていることが分かります。
楽曲の推薦
ここからは、楽曲の推薦用のFunctionを作成し、Functionにリクエストを入れて楽曲を推薦してもらいます。
推薦用のFunctionは下記の通りに作成できます。 使用するEmbeddedデータベースを指定して、他にアーティスト名や楽曲名を入れておけば、似たような雰囲気の曲を勧めてくれます。

Functionを利用して、色なリクエストを入れて楽曲を推薦してもらいましょう!
- 使い方1:楽曲名とアーティスト名を指定して、似たような雰囲気の楽曲を推薦してもらう(Fig_20)

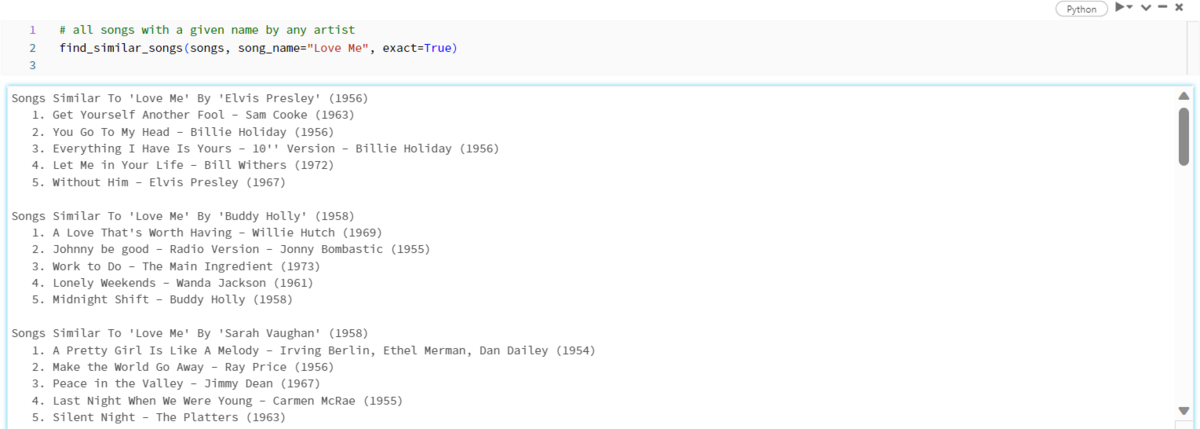
- 使い方2:楽曲名を指定し、似たような雰囲気の曲を推薦してもらう(Fig_21)
おわりに
本記事は以上となります。いかがでしたか。
本記事では、データ取得から、KDB.AI上にベクトルデータベースを登録し、楽曲の推薦するUDFの作成までのご紹介です。これを参考に、他にも色々な使い方があると思います。ご興味のある方に是非試して頂きたいと思います。

私たちはDatabricksを用いたデータ分析基盤の導入から内製化支援まで幅広く支援をしております。もしご興味がある方は、お問い合わせ頂ければ幸いです。
また、一緒に働いていただける仲間も募集中です! APCにご興味がある方の連絡をお待ちしております。