
- はじめに
- 本記事の結論
- GitHub Copilotとは
- VscodeでDatabricksを使うための準備
- GitHub Copilotでdatabricksを動かしてみる
- SQL クエリーを使う準備
- SQL クエリーを実行する
- おわりに
はじめに
GLB事業部Lakehouse部の阿部です。
コメントからコードをサジェストするGitHub Copilotは、コーディングの効率を上げる有効なツールだと思います。
Visual studio codeで開発するdatabricksに対してCopilotを使った場合、コーディングの効率が上がるかどうか検証します。
本記事の結論
- Databricks extension for Visual Studio Codeを使うことで、作業したnotebookをworkspaceと同期できる。
- Copilotによってdatabricksで使われる構文の候補をサジェストしてくれた。
- 使い方としては、Copilotがコードをサジェスト後にVS Codeから実行する。
Workspaceから実行できないコード(Delta Live Tableやnotebook形式のSQLなど)の場合は、VS CodeとWorkspaceのコードを同期し、Workspace上で実行する。
GitHub Copilotとは
登録方法や詳しい説明は割愛しますが、コメントや他に開いているタブのコードを基にコードの候補をサジェストするツールです。
GitHub Copilotの詳しい解説や検証は弊社社員が多くの記事を執筆しておりますので、参考になれば幸いです。
VscodeでDatabricksを使うための準備
以下、2つの準備が必要です。
- Databricks CLIでWorkspaceのホスト名やtokenの登録
- vscode for databricksのインストールとワークスペースの登録
以上2つの手順は割愛しますが、ドキュメントやブログを参考にセットアップが完了しました。
- Databricks CLIのセットアップについては以下のドキュメントを参考に行いました。
- vscode for databricksのインストールとワークスペースの登録などについては こちらの記事を参考にしました。
Databricks extension for Visual Studio Code を試してみる
GitHub Copilotでdatabricksを動かしてみる
先述した手順を踏んだ後、さっそくGitHub Copilotを使ってみましょう。
まずはDatabricksユーティリティであるdbutilsを使ってみます。
ローカルで使うためのライブラリをインポートしておきます。
from databricks.sdk.runtime import *
コメントで「# Databricksユーティリティを使って、databricksのsampleデータセットを確認する」と入力しました。

実行結果です。
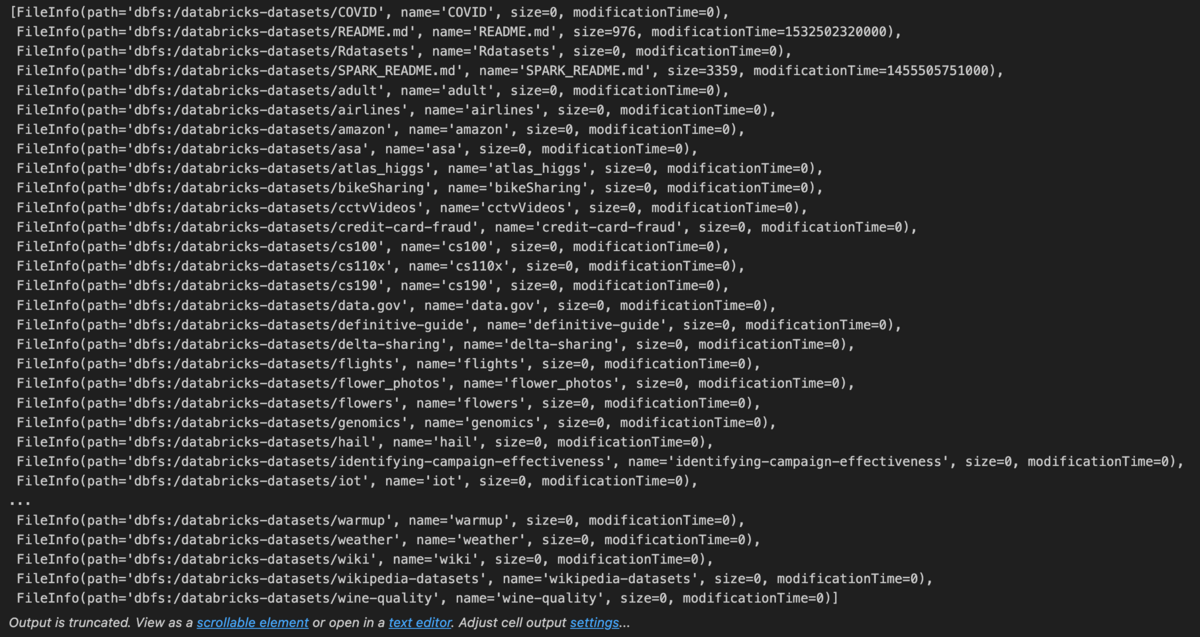
dbutils.fs.lsでディレクトリを確認できています。
次に、Delta Live TableをAuto Loaderで読み込むコードをPythonで記述します。
ちなみに、正解は以下のコードとします。
@dlt.table def customers(): return ( spark.readStream.format("cloudFiles") .option("cloudFiles.format", "csv") .load("/databricks-datasets/retail-org/customers/") )
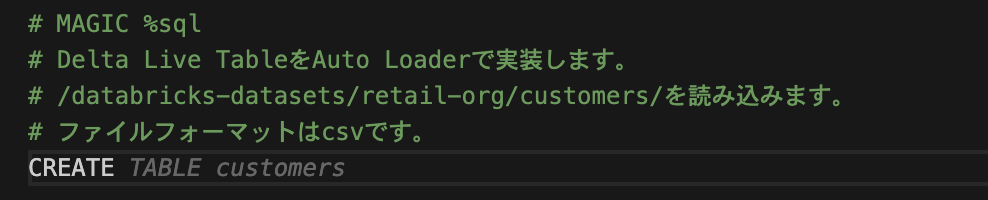
画像のようにコメントを書いて、@dltまで書きました。

dlt.tableが正しいため、ここは自分で修正します。
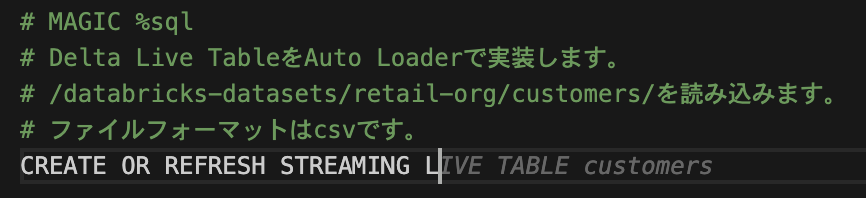
次に、customersという関数を定義するためにdef customers():まで書いたところ、、、

この時点で正しい候補が出てます。
素晴らしい。
次は、同様の処理をSQLで記述します。
SQLの場合はWorkspaceのようにMAGICコマンドで言語を切り替える、またはセルの言語を変えても実行できません。
そのため、Spark SQLを使用するか後述する拡張機能を使ってSQLファイルを実行します。
ここでは、サジェストできるかどうか確認するためnotebookに記述します。
以下、正解のコードとします。
CREATE OR REFRESH STREAMING LIVE TABLE customers AS SELECT * FROM cloud_files("/databricks-datasets/retail-org/customers/", "csv")
Workspaceと同期することを考えてMAGICコマンドを記述し、いくつかコメントを記述しました。
もう少し進めてみます。
ここまで書いたらSTREAMING LIVE TABLEが出てきました。
次の行に進みます。
初回に出てきた候補は間違っていたので、AS SELECTまで書きました。
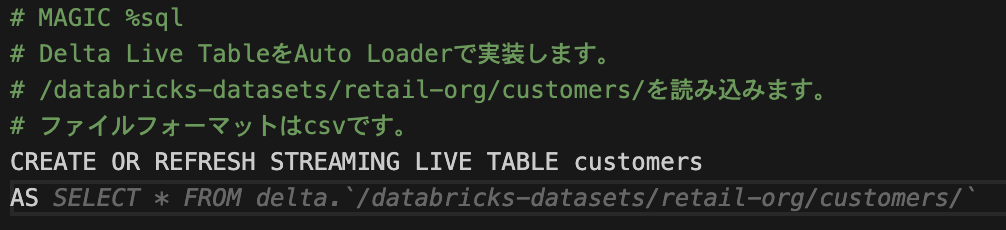
cloud_filesで読み込みたいため、「cloud_files()でファイルを読み込みます」とコメントを追記すると、、、
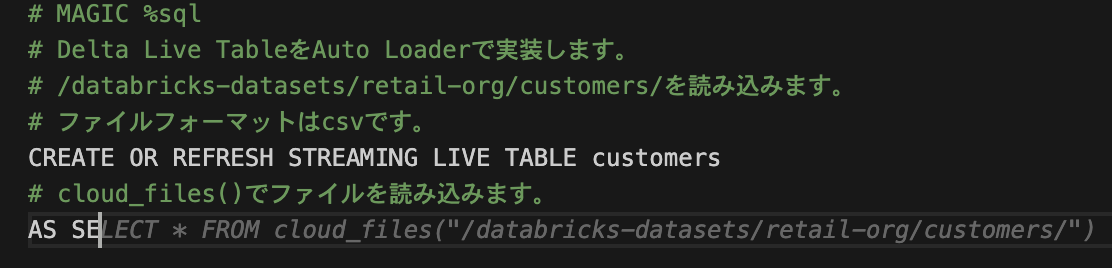
正しい候補を出せています。
Copilotはコメントによって精度がかなり変わるため、コメントの書き方は重要ですね。
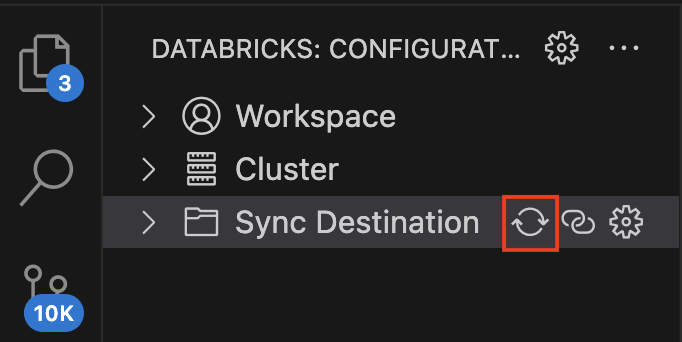
ちなみに、ここまで書いたコードをWorkspaceに保存するには、Sync DestinationのSyncマークをクリックします。
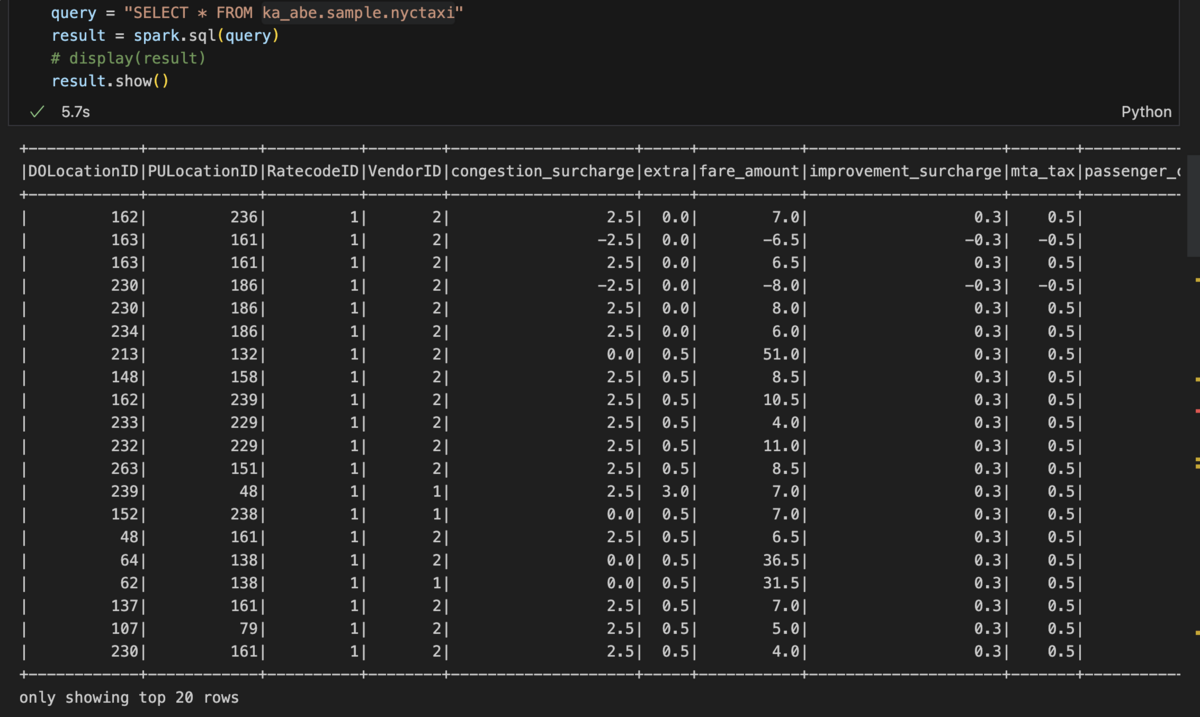
SQLクエリーを実行するにはSpark SQLを使用します。 いか、コメントを記述して実行します。

実行結果です。
SQL クエリーを使う準備
DatabricksでSQLを実行したい場合は、Databricks Driver for SQLTools for Visual Studio Codeをインストールする必要があります。
こちらの設定については、以下のブログとドキュメントを参考にしました。
インストール後、SQLクエリーを使うまでの手順を示します。
①サイドバーのSQL Toolsをクリックし、Add new Connectionをクリックします。
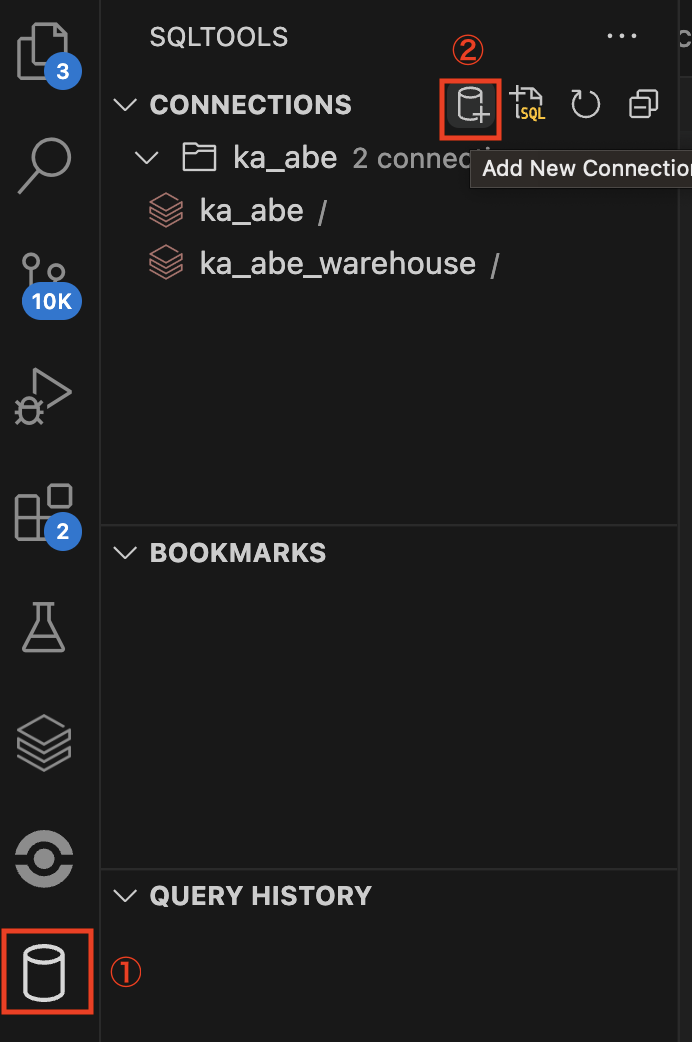
②Catalogをka_abe, Schemaをsampleとします。
③Connection nameとConnection gropuは自分の好きな名前に設定します。
④Connect usingにはhostnameとtokenで接続するか、VS Code Extensionで接続するか選択できます。ここではExtensionを選択します。
⑤PathにはウェアハウスまたはクラスターのHTTPパスを入力します。
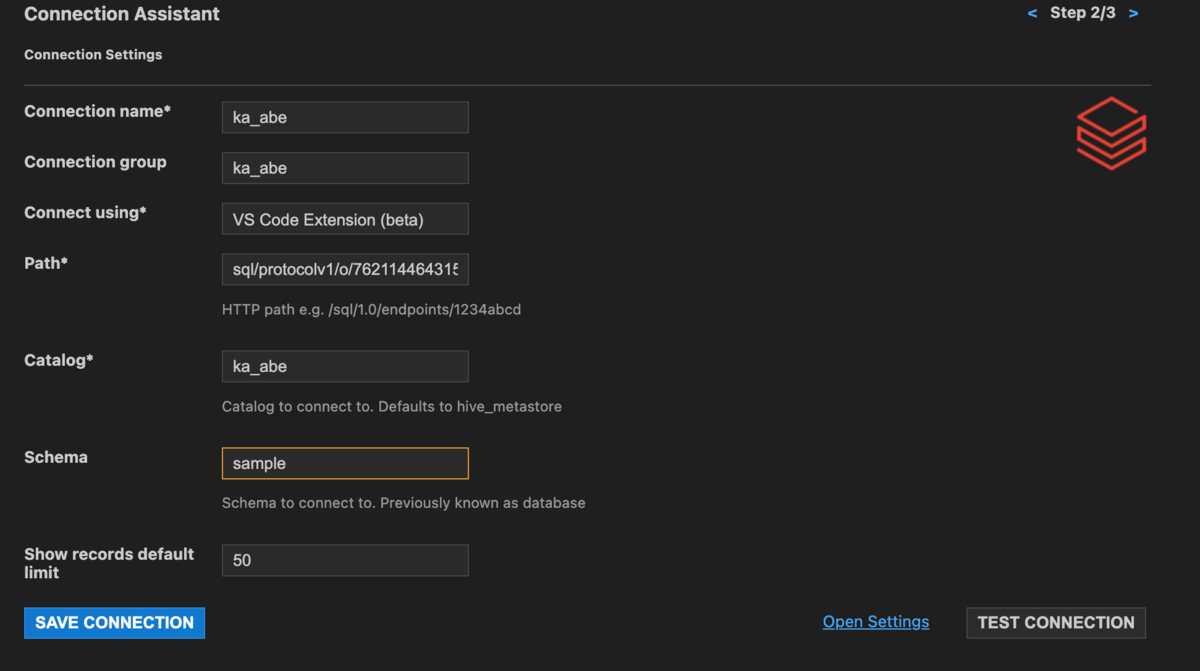
TEST CONNECTIONをクリックして接続のテストをします。
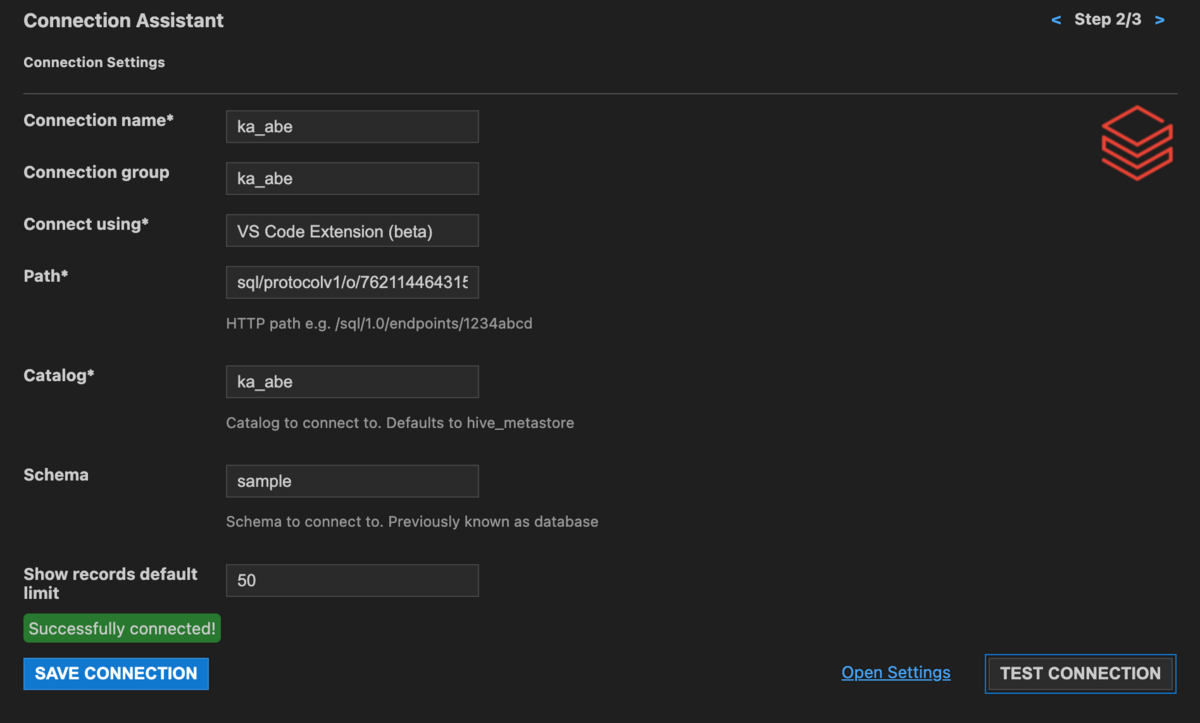
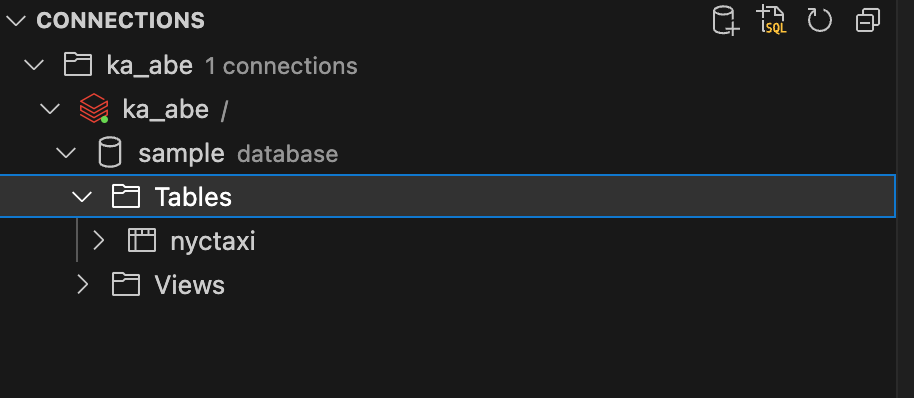
接続テスト完了後、SAVE CONNECTIONをクリックして接続情報を保存すると、サイドバーにスキーマとテーブルが表示されます。
SQL クエリーを実行する
sampleスキーマにあるnyctaxiテーブルを参照します。
試しにカタログ名とスキーマ名、テーブルを指定して参照するコメントを記述します。

しっかりとサジェストできていますね。
以下にクエリーの実行結果を示します。

nyctaxiテーブルを表示できました。
次に、Delta Lakeのバージョン管理を行うために、Delta Lakeのコマンドを実行します。
バージョンを確認するコメントを記述します。

バージョンを指定して参照するコメントを記述します。

テーブルのバージョンを復元するコメントを記述します。

デルタログを削除するコメントを記述します。

はい、ちゃんとサジェストできていますね。
GitHub Copilotはやっぱり優秀でした。
おわりに
Visual studio codeでDatabricksの開発をする際にGitHubを使うことで、Auto LoaderやStructured StreamingなどのDatabricksで使われるコードをサジェストできました。ローカルで作業する方にとっては非常に有効なツールになると思います。
ちなみにGitHub Copilotはコメント内容によってサジェストの精度が大きく変わります。 今回の検証ではコメント内容に神経質になりませんでしたが、コーディングの際にはコードの仕様や文脈を正確に書く必要があります。
また、Databricks Assistantという機能も日本リージョンで使えるようになりました。ローカルで作業する際には使えませんが、Workspace上で作業しますよって方はこちらも便利なのでオススメです。
いずれにしても、コメントは重要ですね!

最後までご覧いただきありがとうございます。
私たちはDatabricksを用いたデータ分析基盤の導入から内製化支援まで幅広く支援をしております。
もしご興味がある方は、お問い合わせ頂ければ幸いです。
www.ap-com.co.jpwww.ap-com.co.jp
Lakehouse部ではデータ&AI案件での開発及びコンサルティングを行うエンジニア/PMを募集しています。求人一覧からご応募をお待ちしております。