
Introduction
This is Abe from the Lakehouse Department of the GLB Division. In this article, I will explain how to improve the chatbot with reference to dbdemos on the Databricks demo page. As an improvement method, we use LangChain's memory function and translation application.
This is the previous post before the update.
The article from preparing the question dataset including setting up dbdemos to creating a vector database is below.
This article is based on the following notebooks on dmdemos. 04-Q&A-promt-engineering-dolly
I also referred to this book when building a chat bot that supports Japanese.
Databricks assortment! -I dug deep into the features that I'm interested in-
People from Databricks Japan are the authors, and I learned a lot from basic stories to applied techniques that can be used in actual projects.
The official dbdemos page is a chatbot that responds in English to English answers, but in this article, we will build a chatbot that supports Japanese.
table of contents
- Introduction
- table of contents
- What is LangChain's memory?
- Preparation
- Prompt engineering using memory function
- Define chatbot class
- Preparation for Japanese translation
- Translate English to Japanese
- Impressions after finishing the demo
- Conclusion
What is LangChain's memory?
Before entering the contents of the demo, I will explain the function of LangChain's memory. Memory is a generic term for a class that remembers past interaction history between users and LLMs. By remembering past dialogue history and inserting it into the current dialogue as context, LLM can take past dialogues into account when answering.
There are two main ways to use Memory, and I would like to introduce those methods and get into the content of the demo.
ChatMessageHistory
ChatMessageHistory is a function to manage chat history between human and LLM.
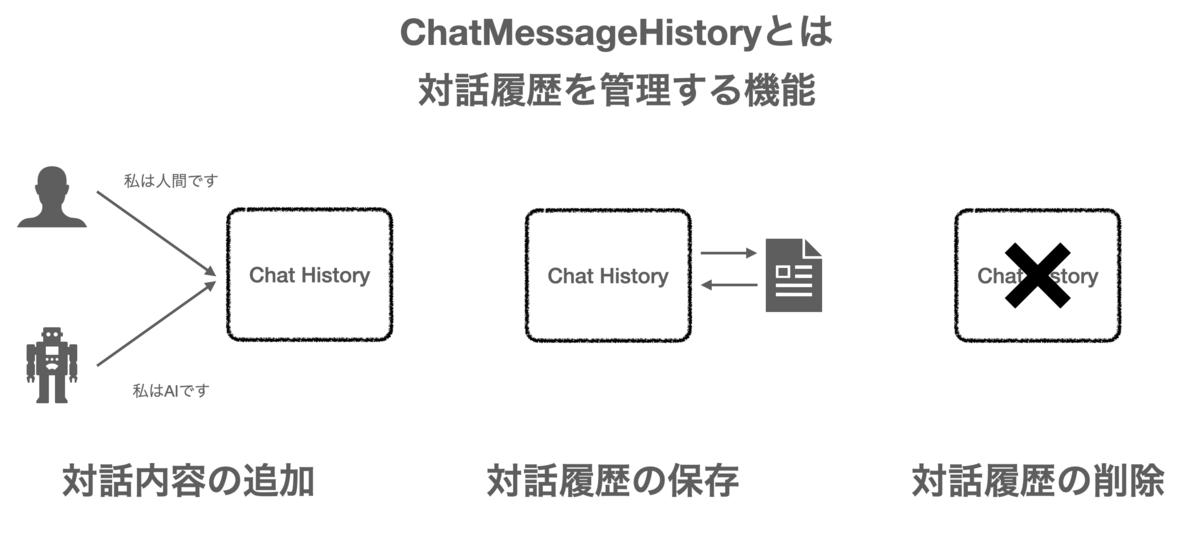
You can add or delete conversations in your Chat history.
Refer to the source code of LangChain's official documentation to introduce it.
from langchain.memory import ChatMessageHistory history = ChatMessageHistory() history.add_user_message("hi!") history.add_ai_message("whats up?") history.messages
Display the execution result.
Out[5]: [HumanMessage(content='こんにちは!私の名前はKenです', additional_kwargs={}, example=False),
AIMessage(content='初めまして、私の名前はBobです', additional_kwargs={}, example=False)]
You can also delete your interaction history.
history.clear() history.messages
Out[9]: []
In this way, messages can be added or removed from the interaction history.
ConversationBufferMemory
ConversationBufferMemory is a function that stores past conversation history and uses it for the next conversation. The memory function handled in this demo is shown below as an example.

Even if the dialogue progresses, by inserting the memorized dialogue history into the prompt as context, it is possible to answer based on the past dialogue history. Here's the code from LangChain's official documentation as an example of using ConversationBufferMemory.
from langchain.memory import ConversationBufferMemory memory = ConversationBufferMemory() memory.chat_memory.add_user_message("hi!") memory.chat_memory.add_ai_message("whats up?") memory.load_memory_variables({})
Display the loaded dialogue history.
{'history': 'Human: hi!\nAI: whats up?'}
Since each conversation is one at a time, the conversation is not based on the conversation history, but in the demo, we will show you the answers that actually use the memory function.
Specifically, use ConversationBufferMemory as a Chain and insert it into the context of the prompt.
Demo overview
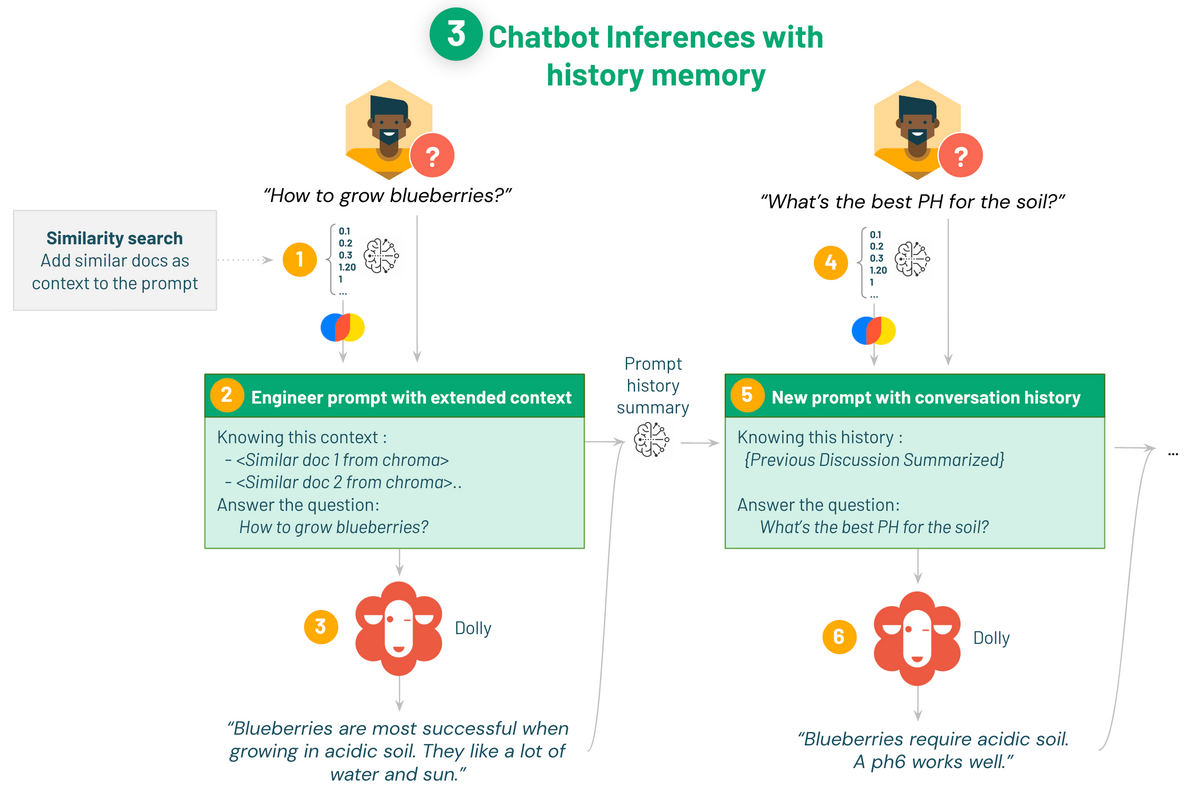
We will improve the Q&A chat bot created in the previous demo. There are two improvements:
By using
ConversationBufferMemoryto insert past conversation history as a context, LLM can refer to past conversations to answer.I used a translation application so that I could respond to Japanese, and I was able to answer Japanese questions in Japanese.
By the way, I am using the cluster that was created when dbdemos was set up.
- Databricks Runtime Version: 13.0 ML
- Node type: StandardStandard_NC8as_T4_v3(56 GB Memory, 1 GPU)
Preparation
Perform the following three preparations. (same as last post)
- Installing Python Libraries
- Catalog and DB setup
- Load Hembedding model, Load created Choromadb (vector database)
Installing Python Libraries
%pip install -U transformers langchain chromadb accelerate bitsandbytes
Catalog and DB setup
%run ./_resources/00-init $catalog=hive_metastore $db=dbdemos_llm
Load Hembedding model, Load created Choromadb (vector database)
if len(get_available_gpus()) == 0: Exception("Running dolly without GPU will be slow. We recommend you switch to a Single Node cluster with at least 1 GPU to properly run this demo.") from langchain.embeddings import HuggingFaceEmbeddings from langchain.vectorstores import Chroma gardening_vector_db_path = "/dbfs"+demo_path+"/vector_db" hf_embed = HuggingFaceEmbeddings(model_name="sentence-transformers/all-mpnet-base-v2") chroma_db = Chroma(collection_name="gardening_docs", embedding_function=hf_embed, persist_directory=gardening_vector_db_path)
Now that we're ready, let's look at the prompt engineering part with memory.
Prompt engineering using memory function
By specifying the following three variables in the prompt template, similar documents and dialogue histories are inserted into the prompt by vector search.
-context: Similar documents obtained from vector search
- human_input: Past human questions
- chat_history: Past interaction history
The implemented code is below.
import torch from transformers import AutoTokenizer, AutoModelForCausalLM, pipeline, AutoModelForSeq2SeqLM from langchain import PromptTemplate from langchain.llms import HuggingFacePipeline from langchain.chains.question_answering import load_qa_chain from langchain.memory import ConversationSummaryBufferMemory def build_qa_chain(): torch.cuda.empty_cache() # Defining our prompt content. # langchain will load our similar documents as {context} template = """You are a chatbot having a conversation with a human. Your are asked to answer gardening questions and help cultivating plants. Given the following extracted parts of a long document and a question, answer the user question. If you don't know, say that you do not know. {context} {chat_history} {human_input} Response: """ prompt = PromptTemplate(input_variables=['context', 'human_input', 'chat_history'], template=template) # Larger max_new_tokens gives longer responses. model_name = "databricks/dolly-v2-7b" # can use dolly-v2-3b, dolly-v2-7b or dolly-v2-12b for smaller model and faster inferences. instruct_pipeline = pipeline(model=model_name, torch_dtype=torch.bfloat16, trust_remote_code=True, device_map="auto", return_full_text=True, max_new_tokens=256, top_p=0.95, top_k=50) hf_pipe = HuggingFacePipeline(pipeline=instruct_pipeline) # Summarize your interaction history summarize_model = AutoModelForSeq2SeqLM.from_pretrained("facebook/bart-large-cnn", device_map="auto", torch_dtype=torch.bfloat16, trust_remote_code=True) summarize_tokenizer = AutoTokenizer.from_pretrained("facebook/bart-large-cnn", padding_side="left") pipe_summary = pipeline("summarization", model=summarize_model, tokenizer=summarize_tokenizer) # lThe angchain pipeline doesn't support summarization yet, so I added it as a temporary fix to the included notebook _resources/00-init. hf_summary = HuggingFacePipeline_WithSummarization(pipeline=pipe_summary) #Hold 500 tokens and then request a summary. The model was not trained on specific chat prefixes, so we are removing the prefixes as it can be confusing. memory = ConversationSummaryBufferMemory(llm=hf_summary, memory_key="chat_history", input_key="human_input", max_token_limit=500, human_prefix = "", ai_prefix = "") # Set verbose=True to see the full prompt: print("loading chain, this can take some time...") return load_qa_chain(llm=hf_pipe, chain_type="stuff", prompt=prompt, verbose=True, memory=memory)
If the dialogue history is inserted into the context as it is, the text will gradually become long and unreadable, so we added a process to summarize the dialogue history using a summary model.
After that, using ConversationSummaryBufferMemory, the memory function is implemented with {chat_history} and {human_input} as keys.
Define chatbot class
Defines a class that answers a question with the source of the answer.
class ChatBot(): def __init__(self, db): self.reset_context() self.db = db def reset_context(self): self.sources = [] self.discussion = [] # Building the chain will load Dolly and can take some time depending on the model size and your GPU self.qa_chain = build_qa_chain() def get_similar_docs(self, question, similar_doc_count): return self.db.similarity_search(question, k=similar_doc_count) def chat(self, question): # Keep the last 3 discussion to search similar content self.discussion.append(question) similar_docs = self.get_similar_docs(" \n".join(self.discussion[-3:]), similar_doc_count=2) # Remove similar doc if they're already in the last questions (as it's already in the history) similar_docs = [doc for doc in similar_docs if doc.metadata['source'] not in self.sources[-3:]] return self.qa_chain({"input_documents": similar_docs, "human_input": question}) chat_bot = ChatBot(chroma_db)
Preparation for Japanese translation
Get the translation application's authentication key so that it can be called from a Databricks notebook.
Get Authentication Key for DeepL API
We use DeepL's API for translation. DeepL has a Free plan, which is free for up to 500,000 characters per month. To use it with LLM, it is necessary to obtain a DeepL authentication key, and I obtained the authentication key by referring to this article.
(Available only in Japanese) DeepL翻訳の無料版APIキーの登録発行手順!世界一のAI翻訳サービスをAPI利用 | AutoWorker〜Google Apps Script(GAS)とSikuliで始める業務改善入門
Create a secret
Since the authentication key is a secret, it is not good to write it directly in the notebook. After obtaining the authentication key, register it in the workspace using Databricks Secrets so that the authentication key can be called from the notebook. For that, open a terminal and install the Azure Databricks CLI.
pip install databricks-cli
Configure the CLI with your Databricks host and token. It can be set using the following command:
databricks configure --token
Create a secret scope.
databricks secrets create-scope --scope <scope-name> # databricks secrets create-scope --scope dbdemos_dolly_chat
Enter the name of the scope you want to create in <scope-name>.
Add your secret key to the scope.
databricks secrets put --scope <scope-name> --key <key-name>
Enter the name of the authentication key to be registered in <key-name>.
When executed, the following screen will be displayed.
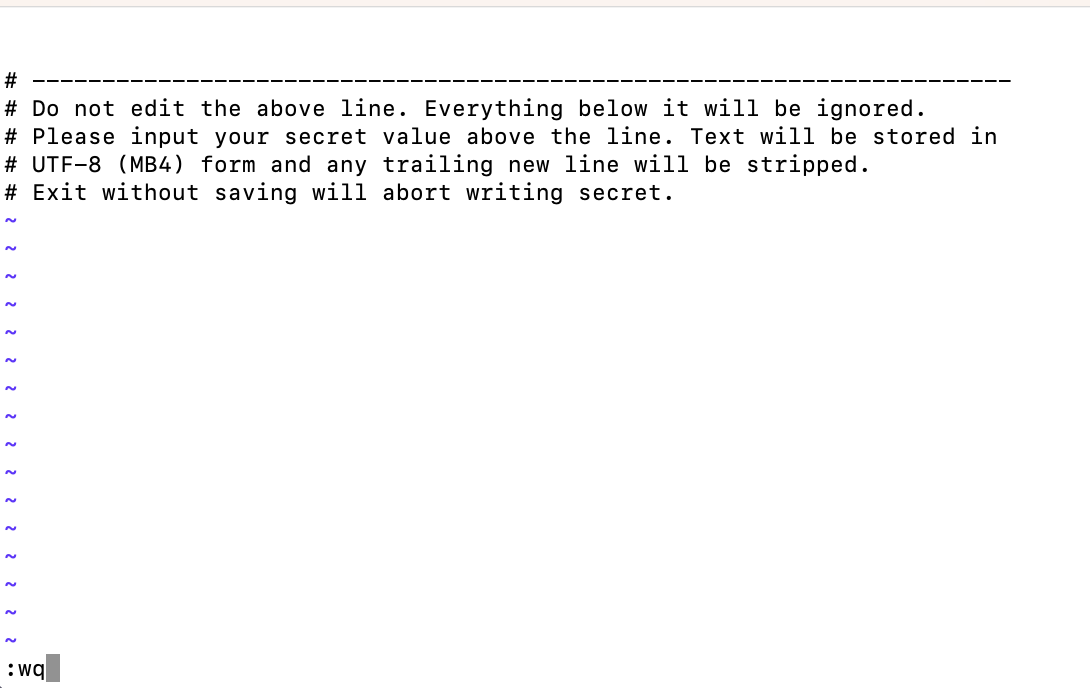
Enter the secret key to be registered at the top of the screen.
This time, after entering the Deepl authentication key, enter :wq to save the contents and exit.
Now you can call and use the DeepL authentication key from your Databricks notebook.
Translate English to Japanese
Call the authentication key for DeepL API KEY and build a chat bot that supports Japanese.
Install the deepl library and use dbutils to get the authentication key.
pip install deepl
# DeepL API key用のSecret(認証キー)を呼び出す。第一引数にはスコープ名、第二引数には認証キーの名前を指定 API_KEY = dbutils.secrets.get("dbdemos_dolly_chat","deepl_key") translator = deepl.Translator(API_KEY)
Check the flow up to the chat bot output that supports Japanese. Remembering that English Q&A is stored in the vector database, the procedure for responding to Japanese questions in Japanese is as follows.
- Convert Japanese questions to English
- Inquiry to chat bot in English and output similar documents and inquiry results
- Convert similar documents and query results to Japanese
It will be the code that implements the above flow.
import deepl from bs4 import BeautifulSoup # Secret call for DeepL API key API_KEY = dbutils.secrets.get("dbdemos_dolly_chat","deepl_key") translator = deepl.Translator(API_KEY) # Japanese -> English def input_trans(text): source_lang = 'JA' target_lang = 'EN-GB' results = translator.translate_text(text, source_lang=source_lang, target_lang=target_lang) return results.text # English -> Japanese def output_trans(text): source_lang = 'EN' target_lang = 'JA' outputs = translator.translate_text(text, source_lang=source_lang, target_lang=target_lang) return outputs.text def chat_ja(text): # Convert Japanese question to English en_input = input_trans(text) # Contact Chatbot result = chat_bot.chat(en_input) en_answer = result['output_text'].capitalize() # Convert query results to Japanese ja_answer = output_trans(en_answer) # display in html result_html = f"<p><blockquote style=\"font-size:24\">{text}</blockquote></p>" result_html += f"<p><blockquote style=\"font-size:18px\">{ja_answer}</blockquote></p>" result_html += "<p><hr/></p>" result_html += "<center><p>参考にした類似コンテンツ</p></center>" result_html += "<p><hr/></p>" sources = [] for d in result["input_documents"]: source_id = d.metadata["source"] sources.append(source_id) # Chromadb内のソースも翻訳 page_contents = BeautifulSoup(d.page_content).text ja_contents = output_trans(page_contents) result_html += f"<p><blockquote>{ja_contents}<br/>(Source: <a href=\"https://gardening.stackexchange.com/a/{source_id}\">{source_id}</a>)</blockquote></p>" displayHTML(result_html)
I will ask the chat bot.
chat_ja("ブルーベリーを育てるのに最適な土は?")
Display the execution result.

You can see that similar documents and answers have been translated into Japanese.
Ask other questions to see if memory is working.
chat_ja("水はどのくらい与えればいいのでしょうか?")

You didn't mention anything that gives you water, but I know it's blueberries from the previous dialogue history.
Also check the contents of the prompt.

The prompt also tells you that it remembers your previous interaction history.
As an additional question, I will ask a slightly abstract question in a different way than the first question.
chat_ja("どんな土壌にすればいい?")

He also answers abstract questions about soil suitable for blueberries.
Check the contents of the prompt as before.
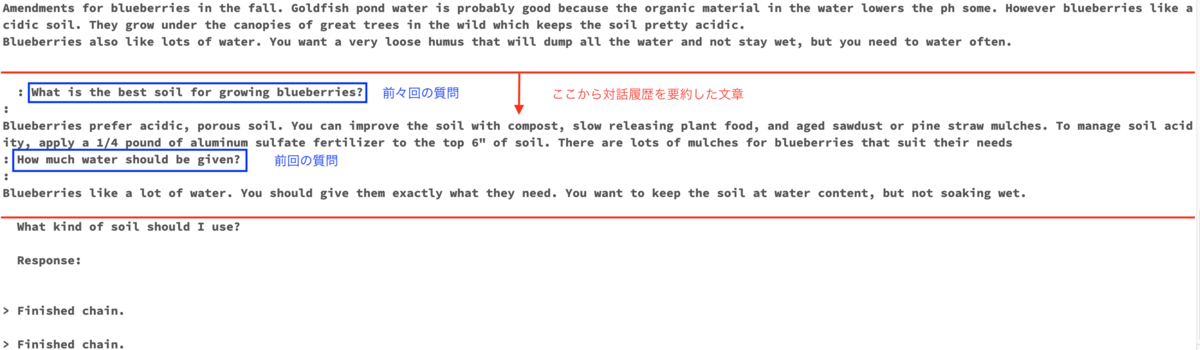
You can see that the conversation history of the time before last and the previous time is memorized.
Using LangChain's memory function, we were able to build a chat bot that responds based on past conversations.
This is the end of the chat bot building demo using Dolly.
Impressions after finishing the demo
I was able to understand the basic and typical structure of the LLM system. I think that this demo can be used as a base when constructing an LLM system using vector search, not just for Dolly.
I listed other possible to-dos as an introduction to LLM.
Check the detailed functions by referring to the official document of transformers.
For the vector database, we used chroma, which can be used locally (dbfs in the Databricksk environment) on OSS, but we will also try cloud-native Pinecone and other vector databases.
Prompt engineering used zero-shot-prompting, where you enter the query without preamble, but you can get used to other techniques. (Few-shot, Chain-of-Thought, etc.)
Experiment with different APIs.
Try open LLMs other than Dolly. Open source LLMs are released regularly from Hugging Face and others.
Conclusion
In this article, we were able to build a chat bot that supports Japanese using the DeepL API. This article about the demo will be the last, but I hope it will be a gateway to getting started with LLM.
Thank you for reading until the end. We provide a wide range of support, from the introduction of a data analysis platform using Databricks to support for in-house production. If you are interested, please contact us.
We are also looking for people to work with us! We look forward to hearing from anyone who is interested in APC.
Translated by Johann