
Introduction
This is Abe from the Lakehouse Department of the GLB Division. Databricks Lakehouse Platform provides demos, dbdemos, with sample datasets and code for each demo that you can use by importing notebooks into your workspace.
In this article, I would like to explain how to build a chatbot using Dolly using dbdemos. We hope that it will be helpful for system design and prompt engineering using LLM.
Dolly and its reasoning were explained in the previous article.
The notebook in the demo below is used as a reference and explained. Build your Chat Bot with Dolly
table of contents
- Introduction
- table of contents
- About the architecture of LLM with vector database
- Demo overview
- dbdemos setup
- Q&A data set and procedure to create vector database
- Prepare gardening questions and best answers
- Model loading that converts the document to a vector representation
- Create an index of documents (rows) in a vector database.
- Reference article
- Conclusion
About the architecture of LLM with vector database
Before going into the demo, I will explain inference processing using document embedding and vector databases. Let's assume the case of storing text data in a vector database.
Preparing for LLM system construction
(LangChain ChatのSimilar Workから引用)
First, as a preparation for building the LLM system, I will explain the flow up to storing text data in the vector database.
Obtained from text data collected by an API that imports text data such as documents , or from an external database.
Splitting a document into small chunks ( Split into chunks ) Because LLM has a limit on the number of tokens when using the API, it is often not possible to input long documents as they are. Therefore, dividing the document into semantic chunks of appropriate length is effective in avoiding the token limit. By the way, what is divided is called a chunk. In addition, by dividing into chunks, it is possible to efficiently search for documents in the vector database during inference.
Compute vector of document ( Create Embeddings ) and convert all chunks into vector representation. Vector representation of text is called embedding , which is stored in a vector database ( Vectorstore ) and used for similarity calculation with queries (prompts) during inference.
(LangChain ChatのSimilar Workから引用)
The above is the procedure for storing text data in the vector database. The vector database plays a role in improving the accuracy of answers by calculating the similarity with the prompts that are performed during inference.
Inference using vector databases
Next, I will explain the inference that outputs the answer based on the input query.
Passing Queries to the LLM System and Vector Database After receiving a query (Question in the figure) from the user, it is passed to the LLM system and vector database. Queries are passed to vector databases as vector representations.
Similarity Search Calculates the similarity between the documents in the vector database and the query vector. As a result, you can identify documents related to your query.
Pass the document along with the original query to LLM to generate the answer The LLM system is passed both the document retrieved from the vector database and the original query, and generates an answer based on these two pieces of information. There is a method of prompt engineering that improves the accuracy of answers by including documents from the vector database as the context of the prompt, and this demo incorporates this method.
You can build an LLM system with the above steps.
Demo overview
Create a chatbot about gardening based on Dolly. Intended for use in a gardening shop, it appears to be a bot that adds a bot to its application to ask customer questions and recommend plant care tips.
This demo is divided into two sections.
1. Data preparation: Ingest and clean the Q&A dataset and store the document embeddings in a vector database.
2. Q&A Reasoning: Give Dolly a query (prompt) to answer the question.
Leverage Q&A data from the Vector database to add context to your prompts.
(([Build your Chat Bot with Dolly]https://www.dbdemos.ai/demo-notebooks.html?demoName=llm-dolly-chatbot)の01-Dolly-introductionのノートブックから引用)
This article covers the data preparation section and explains how to prepare a vector database. The Q&A reasoning section will be covered in the next article.
dbdemos setup
To prepare for the demo, create a new notebook and dbdemos install it to use for the demo.
%pip install dbdemos
After the installation is complete, dbdemos import and llm-dolly-chatbot install the to provide the data used to train the chatbot
import dbdemos dbdemos.install('llm-dolly-chatbot')
Execution result.
dbdemos setup is complete. A demo cluster and folder have been created.
Check the created cluster.

Check the created folder.

We will attach a demo cluster to the notebook we will be using and proceed with the demo.
Q&A data set and procedure to create vector database
In this article, we will prepare the data to be used for training and create a vector database, but let's check the flow of data preparation again.
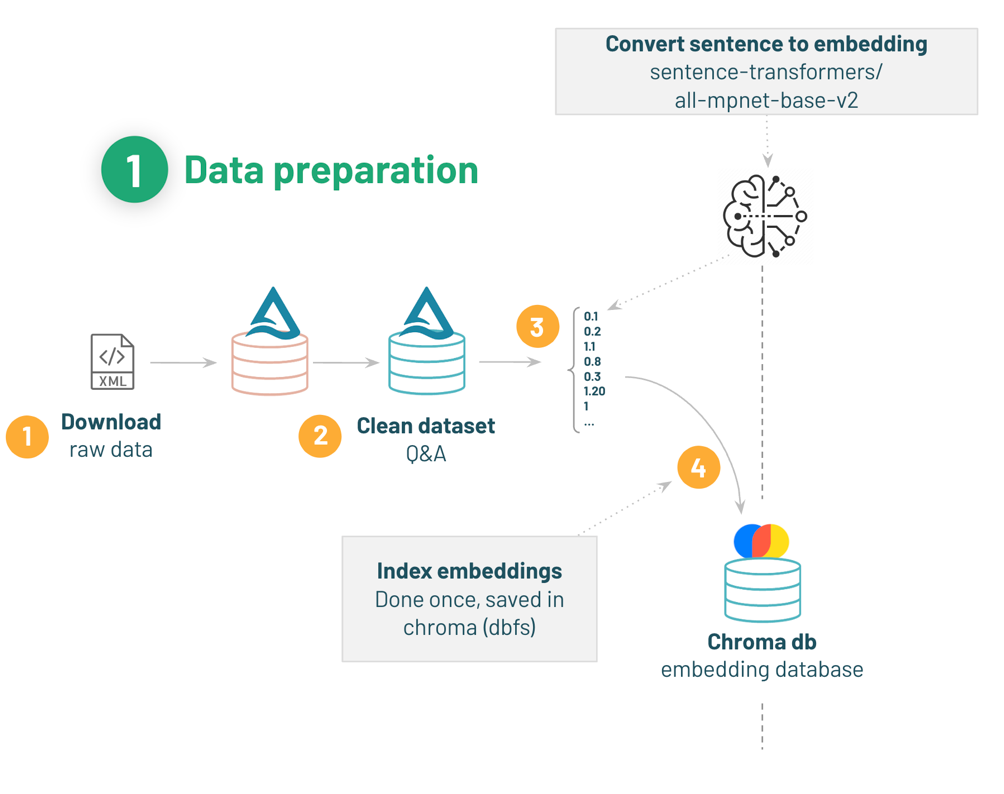
(Taken from Build your Chat Bot with Dolly02-Data-preparation)
- Download the Q&A dataset.
- Have gardening questions and corresponding best answers.
- Load the model from Hugging Face and convert the document to vector.
- Index vectors in the vector database (Chroma).
First, install the necessary libraries.
%pip install -U chromadb langchain transformers
I will briefly explain the installed library.
chromadb: OSS vector database. In this article, the Q&A dataset embedded in the document is stored here.langchain: A Python library for translating text between multiple languages for various linguistic processing tasks.transformers: A Python package for doing natural language processing tasks, providing pretrained LLMs.
Then run the notebook with the command that _resources it is in a folder in the same directory .00-init%run
%run ./_resources/00-init $catalog=hive_metastore $db=dbdemos_llm
00-init As you can see, the value of the widget is obtained as shown below, so the value is assigned to the %run variable at runtime .catalogdb
dbutils.widgets.text("catalog", "hive_metastore", "Catalog") dbutils.widgets.text("db", "dbdemos_llm", "Database") catalog = dbutils.widgets.get("catalog") db = dbutils.widgets.get("db") db_name = db
It uses the dbutils.widgets.text() method to create two widgets, catalog and db.
Each widget has an initial value and a description, with the names hive_metastore and `dbdemos_llm```` respectively. are set.
dbutils.widgets.get("catalog") uses a function called Widget to get the value of the widget with the given name.
This time we'll focus on gardening questions and download the gardening dataset.
Here, we use the bash command to download the gardening dataset archive, unzip it, and Posts.xml copy the dataset files to the created dbfs directory.
%sh #To keep it simple, we'll download and extract the dataset using standard bash commands #Install 7zip to extract the file apt-get install -y p7zip-full rm -r /tmp/gardening mkdir -p /tmp/gardening cd /tmp/gardening #Download & extract the gardening archive curl -L https://archive.org/download/stackexchange/gardening.stackexchange.com.7z -o gardening.7z 7z x gardening.7z #Move the dataset to our main bucket mkdir -p /dbfs/dbdemos/product/llm/gardening/raw cp -f Posts.xml /dbfs/dbdemos/product/llm/gardening/raw
A real-life scenario is described as retrieving data from an external system.
The Q&A dataset is ready. Check the dataset information.
%fs ls /dbdemos/product/llm/gardening/raw

I was able to check the size of the dataset.
Prepare gardening questions and best answers
Let's ingest data using spark xml. To clean and prepare your gardening questions and best answers follow these steps:
- Leave only the questions and answers with reasonable scores as best answers.
- Parse HTML to plain text.
- Concatenate questions and answers to form question-answer pairs.
Check out the Q&A dataset
Read the file placed in the specified directory Posts.xml and check the question data.
gardening_raw_path = demo_path+"/gardening/raw" print(f"loading raw xml dataset under {gardening_raw_path}") raw_gardening = spark.read.format("xml").option("rowTag", "row").load(f"{gardening_raw_path}/Posts.xml") display(raw_gardening)
option("rowTag", "row") specifies that the tag name of the element representing a row in the XML file is "row".
View the dataset.

You can check the ID of the answer, the number of answers, the question text, etc.
Then check the answers to the questions.
The code below defines a Pandas UDF (User-Defined Function) that converts an HTML formatted string to text, and uses BeautifulSoup to parse the HTML and extract the text.
from bs4 import BeautifulSoup #UDF to transform html content as text @pandas_udf("string") def html_to_text(html): return html.apply(lambda x: BeautifulSoup(x).get_text()) gardening_df =(raw_gardening .filter("_Score >= 5") # keep only good answer/question .filter(length("_Body") <= 1000) #remove too long questions .withColumn("body", html_to_text("_Body")) #Convert html to text .withColumnsRenamed({"_Id": "id", "_ParentId": "parent_id"}) .select("id", "body", "parent_id")) # Save 'raw' content for later loading of questions gardening_df.write.mode("overwrite").saveAsTable(f"gardening_dataset") display(spark.table("gardening_dataset"))
As data pre-processing, we are doing the following:
filterUse a function to filter rowsraw_gardeningfrom the DataFrame with a value greater than or equal to 5 in the "Score" column and rows with less than 1000 characters in the " Body" column.withColumnThe functionhtml_to_textcreates a new "body" column with a UDF that converts the HTML contained in the "_Body" column to text format.withColumnsRrenamedNow create a new dataframe by renaming the " _Id" column to "id" column and " ParentId" column to "parent_id" column and selecting the required columns.gardening_df
Finally, save as gardening_df a Hive table gardening_dataset and view the table.

I have a table of question IDs and answers.
match questions and answers
Load the previously saved dataset gardening_dataset to create a question and answer dataset.
gardening_df = spark.table("gardening_dataset") # Self-join to match questions and answers qa_df = gardening_df.alias("a").filter("parent_id IS NULL") \ .join(gardening_df.alias("b"), on=[col("a.id") == col("b.parent_id")]) \ .select("b.id", "a.body", "b.body") \ .toDF("answer_id", "question", "answer")
The read dataframe is self-joined to pair answers and questions.
Specifically, after parent_id filtering only the dataframes (questions) that do not have an alias name a and using gardening_df the alias name of the original b, join each other's dataframes only for records with matching question and answer IDs.
After that select the three columns b.id (answer id), a.body (question text) and b.body (answer text) and finally use the toDF() method to rename these columns with new names ```qa_df```` I am creating a new dataframe by changing to 'answer_id', 'question' and 'answer'.
# トレーニングデータセットを用意する:ベストアンサーで以下の問題を出題する。
docs_df = qa_df.select(col("answer_id"), F.concat(col("question"), F.lit("\n\n"), col("answer"))).toDF("source", "text")
display(docs_df)
qa_df It then concatenates the question and answer columns for the dataframe docs_df to create a new dataframe with source and text columns.
docs_df is displayed.

I created a QA sentence by using answer_id as the source column and including the question sentence and the answer sentence in the same sentence in the text column.
Text summarization for faster inference
The dataset consists of one question and best answer, which can be quite long text. Using long texts as context can slow down LLM inference. One option to get around that problem is to use the Summarizer LLM to summarize these Q&As and replace the existing Q&A sentences with the results. The operation to create a summary takes a very long time, and the cluster prepared for demonstration did not finish in an hour, so this time we will proceed without summarizing the text.
from typing import Iterator import pandas as pd from transformers import pipeline @pandas_udf("string") def summarize(iterator: Iterator[pd.Series]) -> Iterator[pd.Series]: # Load the model for summarization summarizer = pipeline("summarization", model="sshleifer/distilbart-cnn-12-6") def summarize_txt(text): if len(text) > 400: return summarizer(text) return text for serie in iterator: # get a summary for each row yield serie.apply(summarize_txt) # データセット全体で時間がかかる可能性があるため、実行はしない # docs_df = docs_df.withColumn("text_short", summarize("text")) docs_df.write.mode("overwrite").saveAsTable(f"gardening_training_dataset") display(docs_df)
We use the pipeline class to load a model that handles the task of text summarization , and define a function distilbart-cnn-12-6 that performs text summarization if the length of the text is greater than 400 characters, and returns the original text if it is less than 400 characters. summarize_txt().
Then for each row in the iterator we summarize_txt() apply the function and return a Pandas DataFrame with a new column containing the summary we created.
I am not doing a text summary this time, but I will understand that there is also such a method.
Model loading that converts the document to a vector representation
Download HuggingFaceEmbeddings a pretrained model trained on multilingual documents using a class that converts sentences to vector representations .sentence-transformers/all-mpnet-base-v2
from langchain.embeddings import HuggingFaceEmbeddings # Download model from Hugging face hf_embed = HuggingFaceEmbeddings(model_name="sentence-transformers/all-mpnet-base-v2")
Embed the document using this downloaded model.
Create an index of documents (rows) in a vector database.
Now it's time to load the generated text and create a searchable text database for use in the Langchain pipeline. These documents are embedded so that they can be matched against vectors of later queries and related text chunks.
This is the procedure for creating a vector database.
- Collect text chunks in Spark.
- Create an in-memory Chroma vector DB.
sentence-transformersInstantiate the embedded function from.- Enter and persist data in the database.
Preparing Databricks Widgets for Embedded Controls
First, prepare a directory to store the database, and dbfs set the above arbitrary path.
This code uses a Databricks widget to control whether the text data embedding is recalculated.
dbutils.widgets.dropdown("reset_vector_database", "false", ["false", "true"], "Recompute embeddings for chromadb") gardening_vector_db_path = demo_path+"/vector_db" # Don't recompute the embeddings if the're already available compute_embeddings = dbutils.widgets.get("reset_vector_database") == "true" or is_folder_empty(gardening_vector_db_path) if compute_embeddings: print(f"creating folder {gardening_vector_db_path} under our blob storage (dbfs)") dbutils.fs.rm(gardening_vector_db_path, True) dbutils.fs.mkdirs(gardening_vector_db_path)
First, dbutils.widgets.dropdown I am using the method to create a dropdown widget named "reset_vector_database".
This widget allows the user to choose whether to recalculate the text data embedding.
Then compute_embeddings define a variable named "reset_vector_database" which will be set if the widget true is or gardening_vector_db_path the file does not exist . Indicates that the text data embeddings should be recomputed when .TrueTrue
Finally, if compute_embeddings the variable True is , gardening_vector_db_path delete the folder in the path specified by and create a new folder.
This prepares the text data for embeddings to be recomputed.
Create document database
Create a document database by storing the Q&A dataset in a vector database.
Steps to create a document database:
1. Load a text dataset and create a document.
2. Break long sentences into smaller manageable chunks.
This time, the original Q&A sentences were not so long, so we did not divide them into chunks.
Also, it explains that if the amount of sentences is smaller after executing text summarization, there is no need to divide into chunks. However, the answer returned by LLM will probably change depending on whether or not there is chunk division, so it seems that this area still needs verification.
The code below is for calculating document embeddings using Chroma and storing them in a database.
from langchain.docstore.document import Document from langchain.vectorstores import Chroma # Import if you want to divide Chunk. # from langchain.text_splitter import CharacterTextSplitter all_texts = spark.table("gardening_training_dataset") print(f"Saving document embeddings under /dbfs{gardening_vector_db_path}") if compute_embeddings: # Convert lines as langchain Documents. # If you want to index for shorter time periods, use the text_short field instead. documents = [Document(page_content=r["text"], metadata={"source": r["source"]}) for r in all_texts.collect()] # Long sentences may need to be split. But it's best to summarize as above. # text_splitter = CharacterTextSplitter(separator="\n", chunk_size=1000, chunk_overlap=100) # documents = text_splitter.split_documents(documents) # Initialize chromadb with sentence-transformers/all-mpnet-base-v2 model loaded from hugging face (hf_embed). db = Chroma.from_documents(collection_name="gardening_docs", documents=documents, embedding=hf_embed, persist_directory="/dbfs"+gardening_vector_db_path) db.similarity_search("dummy") # tickle it to persist metadata (?) db.persist()
Here is the explanation of the code.
if compute_embeddings If True (if you need embeddings), for each Document line of the document use a class to take the text data and its metadata and compute the embeddings.
Page_content is one of the attributes representing the body of the document, text passing the column values for each row. Metadata is an attribute for storing document metadata, source passing the columns as a dictionary.
And then Chroma.from_documents() uses the method to initialize the database.
Chroma.from_documents() It's about method arguments.
- collection_name : Name of collection to be created
- documents : List of documents
- embedding : Used to embed documents
- persist_directory : Path of directory for persisting vector store
similarity_search() The method calculates the degree of similarity between the vectors in the Chroma database and the vectors of the given query (the documents to be searched) and returns the text with the highest degree of similarity. This time we will run a dummy query (prompt) to calculate the vectors of the documents to be stored in the vector database and cache the metadata.
Finally, persist() uses the method to create a persistent vector store.
This method saves the current vector store state from in-memory to disk (a file) and maintains the vector store state across program restarts to ensure data persistence.
Thank you for your hard work so far. The Q&A dataset is now ready!
Reference article
Conclusion
In this article, we prepared a Q&A dataset to be stored in a vector database for building a chatbot with Dolly. In the next and subsequent articles, I would like to perform prompt engineering using the created vector database, perform inference processing with Dolly, and check the behavior of the chatbot.
Thank you for reading until the end. We provide a wide range of support, from the introduction of a data analysis platform using Databricks to support for in-house production. If you are interested, please contact us.
We are also looking for people to work with us! We look forward to hearing from anyone who is interested in APC. Translated by Johann