Introduction
This is Abe from the Lakehouse Department of the GLB Division. With the advent of Chat GPT and the release of open source LLMs by companies in Japan, the term LLM (Large Scale Language Model) has become more common. Recently, the term LLMOps has come to be heard here and there, but I would like to write this article as a sorting out while studying about the difference from MLOps and how to operate like Ops.
What is LLMOps
It is a coined word of LLM (Large Language Model) + Ops (Operations).
There is no clear definition of LLMOps, but I think that pipeline development and operation of LLM like DevOps and MLOps will make the development and operation cycle run smoothly. The term LLMOps is not used much because the definition of LLMOps is ambiguous and the operation method is not fixed. Looking at the trend by specifying LLM and LLMOps as keywords in Google Trends for Japan, it can be seen that the number of searches for "LLMOps" is considerably low while the number of searches for "LLM" is increasing. (Based on the release of Chat GPT in November 2022, the target period is the date and time immediately before that and at the time of writing the article.)
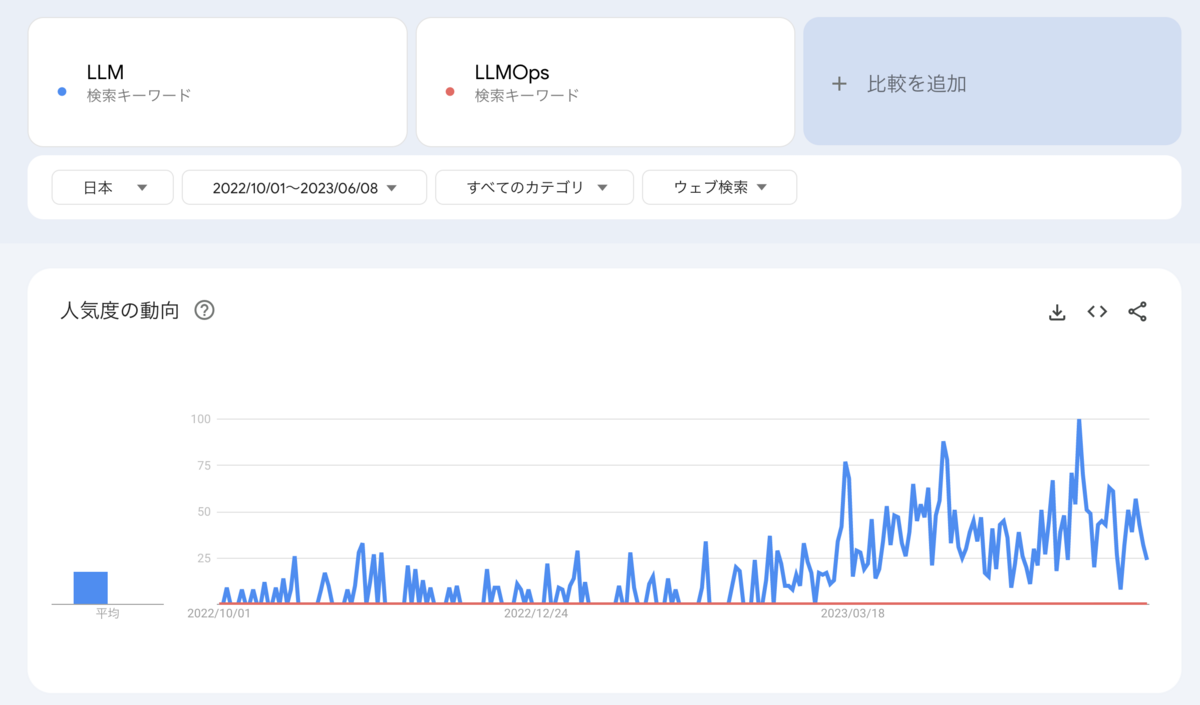
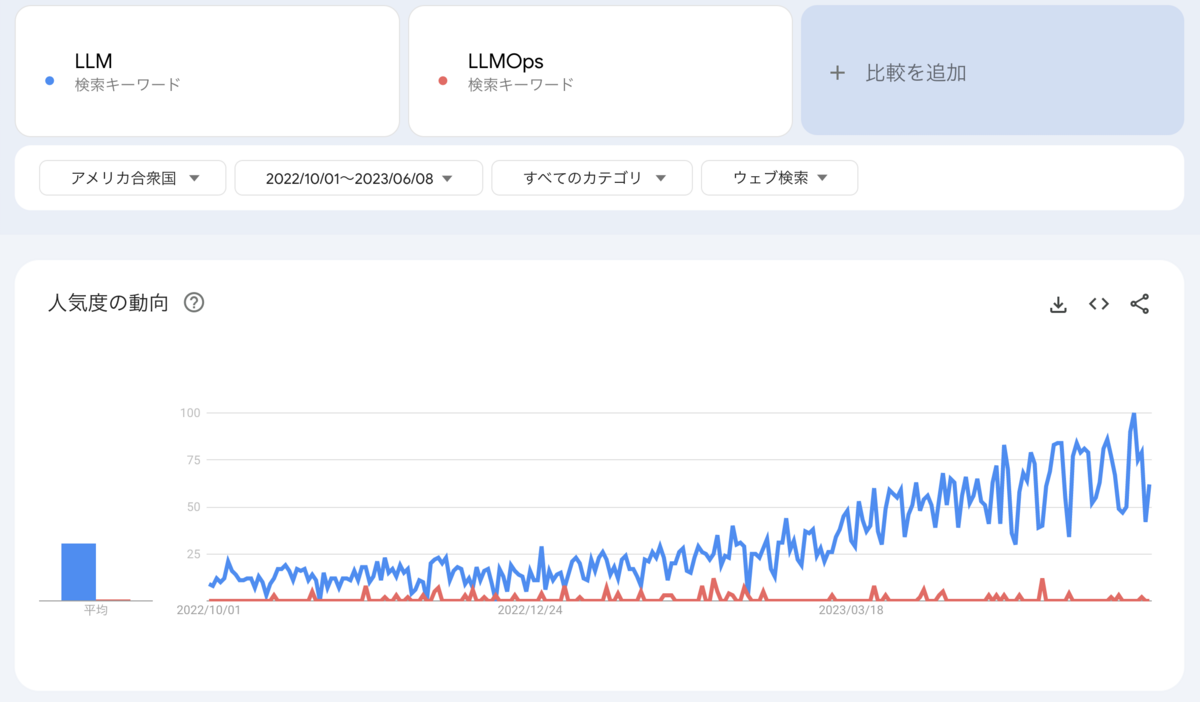
I don't know the reason for the peak in the number of LLM searches, but it is possible that Chat GPT has started to be used and domestic companies have released open source LLM. On the other hand, the number of searches for LLMOps is very low compared to LLM in Japan, and I believe that the reason for this is that unlike MLOps, there are no established best practices for operation, and the term LLMOps itself is not used much. . By the way, in the United States, the number of searches for LLM is increasing, and LLMOps is also being searched sporadically, but the number of searches is still relatively small.
As you can see from Ops, it can be imagined that it is an LLM operation, but at the moment there are no best practices in operation methods and there are almost no examples, so it is not possible to assert that "LLMOps is!" For that reason, the content of LLMOps discussed in this article should only be used as a reference.
Accuracy improvement method different from MLOps
I believe there are three ways to improve the accuracy of LLM. The big difference from MLOps is that there are methods other than fine-tuning for improving accuracy, and they may be more suitable. By the way, you can also consider doing them simultaneously rather than just one at a time.
1. Prompt adjustment
The first option is to adjust the prompts through prompt engineering.
It takes less time and effort than fine-tuning, which selects and learns data again, so I think it is the first choice as a measure to improve model accuracy.
In addition, it is likely that there will be a certain number of cases that can be handled by just adjusting the prompts, so it can be done more quickly than fine-tuning MLOps.
2. Updating data in the vector database (vector store)
Updating the vector database is also a candidate if you are using vector search to insert similar documents into the context of the prompt. (As a result, I think it will be a prompt adjustment.)
It takes a little more time than adjusting the prompts, but it's easier than fine-tuning (described later).
It is possible to replace the data or change the data format, but if you want to create a new QA dataset, preparing the data is difficult.
3. Fine tuning (relearning)
Personally, I think it's the last resort from the viewpoint of time and effort.
MLOps is used when the expected output cannot be obtained due to changes in the distribution of training data over time or changes in the external environment.
LLM is also one of the means, but the condition is that it is an open LLM, and I feel that it is less cost-effective than the above two methods, and it is the first choice of those who are actually developing LLM I do not think.
In this way, it can be said that there are more options for improving accuracy compared to MLOps.
How to manage prompts
In addition to data and model management like MLOps, I think we need to manage model accuracy per prompt. The reason is that, as mentioned earlier, you might want to evaluate the output after adjusting the prompt. A possible way to manage prompts is to tie the prompts to the output results or evaluation indicators of the model, and it is necessary to consider the output results due to differences in prompts.
Evaluation method issues
There are issues such as how to evaluate, what to do with the evaluation index, and what to do with the evaluation criteria for whether the output is as expected. There is no method to evaluate whether the expected output is obtained or not, and currently there is no other way than human evaluation. The first stages of LLMOps are likely to involve human intervention.
Issues in operation and monitoring
I think there are two issues in operation and monitoring. The first is that even if the distribution of the input data changes, the method of calculating the distribution is not fixed in the case of natural language. Even if the distribution of input data (data to be put into a vector database or data for fine tuning) changes, there is a problem in the method of calculating the data distribution because it is a natural language. As a distribution calculation method, it is possible to think about specific vocabulary, n-gram appearance frequency, sentence length, etc., but I think it is difficult to judge how much it is due to accuracy. The second is how to evaluate the output results from LLM. As I mentioned in the evaluation index section, currently there is no choice but to evaluate whether or not the expected answer is given by a human being. Furthermore, due to customer needs or other environmental changes, LLM may not provide the expected output. In order to respond to such environmental changes, it may be necessary to periodically review the training data used for fine tuning and the data stored in the vector database when using vector search.
How to achieve LLMOps on Databricks
Although there is no end-to-end function for LLMOps yet, it seems that prompts and models can be linked by using ML Flow similar to MLOps. There are likely to be issues with UI and UX, but I look forward to future evolutions.
Introducing MLflow 2.3: LLM native support and enhancements with new features
APC Data + AI Summit 2023 Special Site
Data + AI Summit 2023 will be held on June 26-29, 2023. At "Data + AI Summit 2023", AP Communications, which has a partnership agreement with Databricks, plans to deliver keynote speeches and the latest update information from the local site sequentially from our special site!
During the period until the event, we plan to post the charm and highlights of Databricks. We will also cooperate with the people of Databricks, so if you are even slightly interested, we would appreciate it if you could join us for about a month.
Highlights of the Data AI Summit
One of the highlights of the Data AI Summit is still the LLM. There are many sessions about LLM, and I picked up the sessions about LLM that I personally care about.
During the period until the event, we plan to post the charm and highlights of Databricks. We will also cooperate with the people of Databricks, so if you are even slightly interested, we would appreciate it if you could join us for about a month.
Conclusion
In this article, I explained about LLMOps based on my personal opinion. At present, the best practices for LLM development and operation have not been established, and the definition of LLMOps is not clear, so it may not be a word that is often heard in Japan. However, from the results of Google Trends, there is excitement mainly in the United States, and I think that the idea of LLMOps will spread in Japan in the near future. I would like to keep an eye on the trends of LLMOps in the future.
Thank you for watching until the end. We provide a wide range of support, from the introduction of a data analysis platform using Databricks to support for in-house production. If you are interested, please contact us.
We are also looking for people to work with us! We look forward to hearing from anyone who is interested in APC.
Translated by Johann