
はじめに
GLB事業部Lakehouse部の陳(チェン)です。
本日はDatabricks社より公開されたEnglish SDK for Apache Spark(以下English SDK)を利用し、気象情報を可視化することを試してみました。
本記事では、DatabricksのMarketplaceからのデータ取得から、ノートブック上でのAPI設定、データの可視化までの流れをご紹介いたします。
目次
- はじめに
- 目次
- English SDK for Apache Sparkというのは
- データ取得
- English SDKの設定 (with Databricks Secret)
- 気象情報を可視化してみる
- おわりに
English SDK for Apache Sparkというのは
SDK (Software Development Kit) は、ソフトウェアの開発に必要なプログラム・API(Application Programming Interface)・文書などをまとめてパッケージ化したものです。
「English SDK for Apache Spark」はEnglish SDK の正式名称であり、Pythonプログラムに英語で記述した指示を組み込んで、Apache Sparkの操作を可能にする開発ツールです。主にデータ収集・データフレーム操作、ユーザ定義関数の作成、キャッシングの4種類の機能が期待されています。
上記の利用法や検証はウェブ上で見つかります。本記事は、English SDKによるデータの可視化を試したご紹介です。
データ取得
まず、データを取得しましょう。
本記事では、DatabricksのMarketplaceから、アメリカの「AccuWeather」社が無料で提供したサンプル気象データを使用します。ここからは取得方法を説明します。
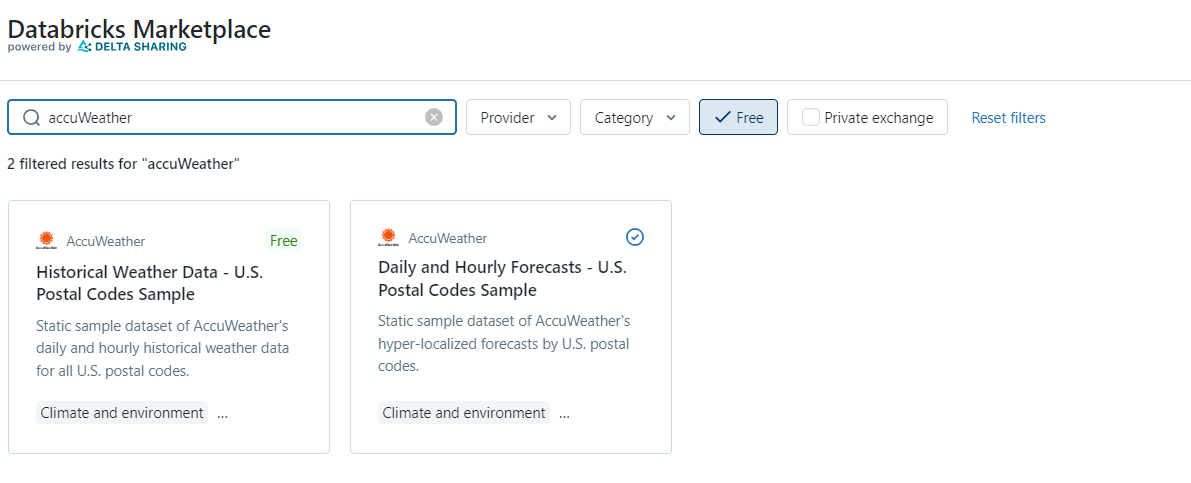
Databricksプラットフォームにログインし、左側のバーナーで「Marketplace」のリンクをクリックして、「Marketplace」に遷移します。「Marketplace」で提供されたデータに「有料」と「無料」の二種類があり、本日はお試しのため「Free」のボックスにチェックを入れると無料で利用可能なデータが表示されます(Fig1)。
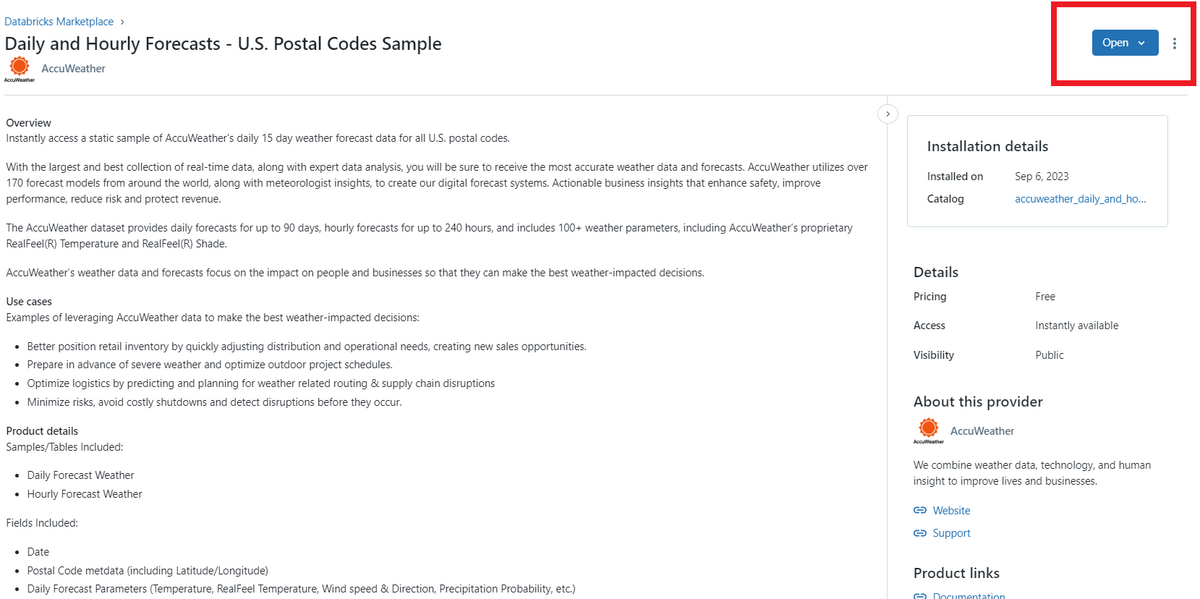
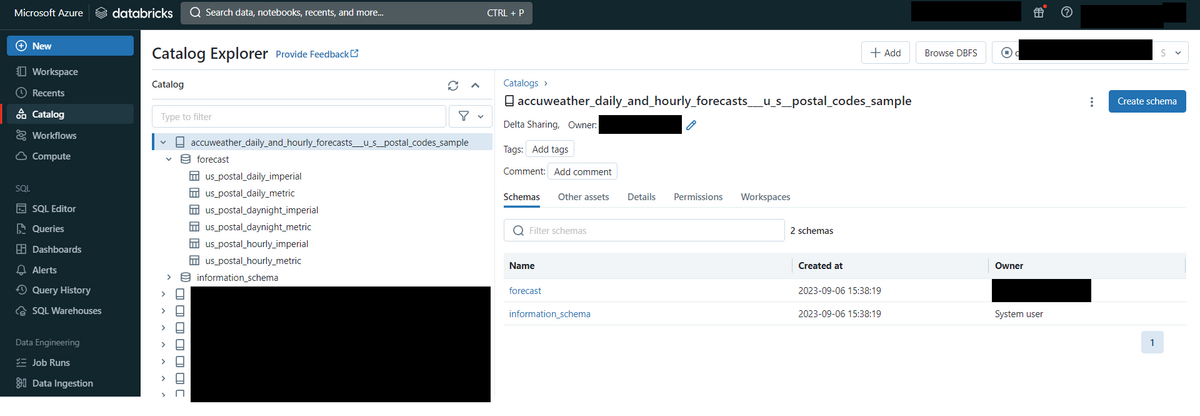
取得希望のデータをクリックして、データ説明を読んでからデータ取得の手続きを行います(Fig2)。取得する際、Fig2の赤枠に囲まれているボタンを押したらFig3のように自分のカタログデータにデータがシェアされます。ここからは利用可能になります。
English SDKの設定 (with Databricks Secret)
Databricks上でノートブックを開いてから作業を行います。
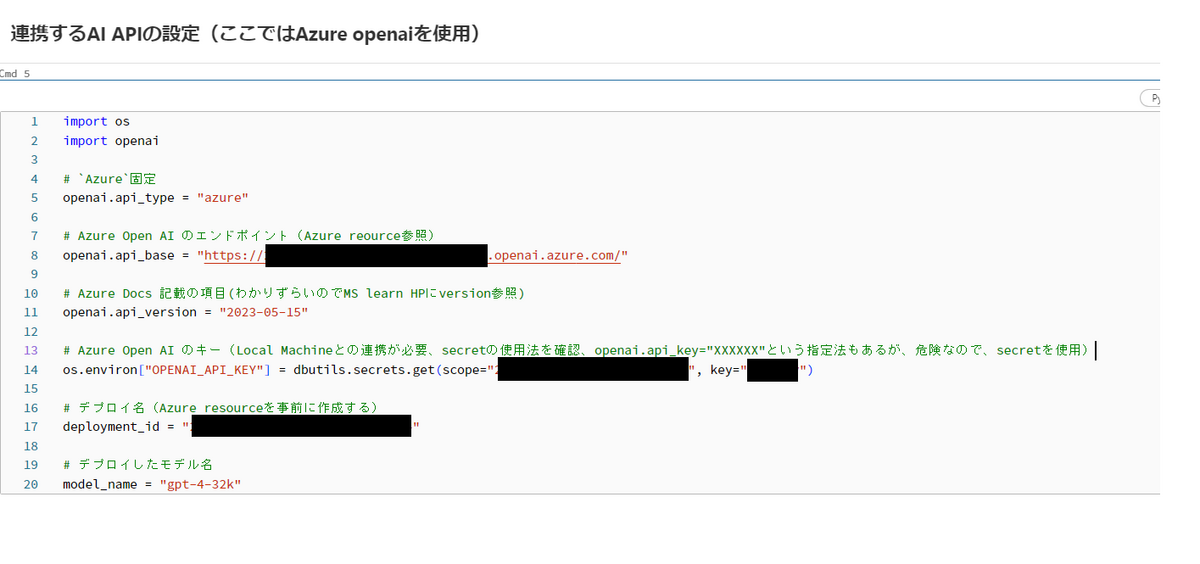
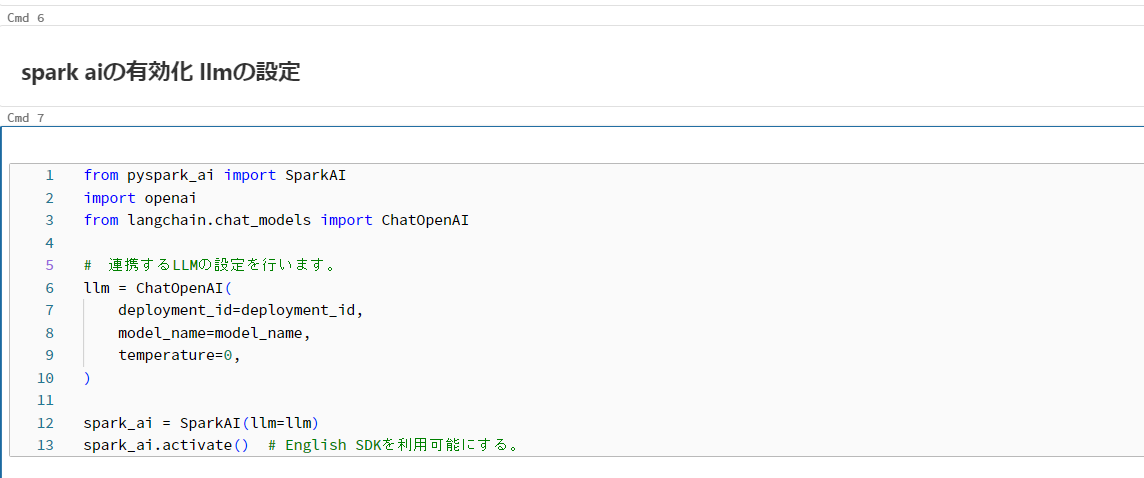
English SDKを利用するために、Databricks Secretを利用したAzure OpenAI と提携をした環境を構築しました (Fig4)。 Azureの環境で、gpt4.0が利用可能な状態にしておきます。同時に、自分のローカル環境Databricks Secrectの環境を整えてから、必要な情報をFig4のように整備しておきます。 ここでは、gpt4.0のモデル名は「gpt-4-32k」としています。
API環境の整備が整ってから、Fig5のように、notebook上に必要なモジュールをインストールし、設定を行えばEnglish SDKが利用可能となります。(連携するllmの変更が可能です。ご興味がありましたら様々なllmを差し替えて挙動の変化を実感するのもお勧めです。)
気象情報を可視化してみる
ここでは、科学的な意味を求めずに、データ解析でよく利用される箱ひげ図、時系列の図、および地図上に分布図を描いてもらいました。
- pysparkによるデータ操作
テーブルに様々なデータが入っているため、前作業として、必要とするデータのみを切り出します。
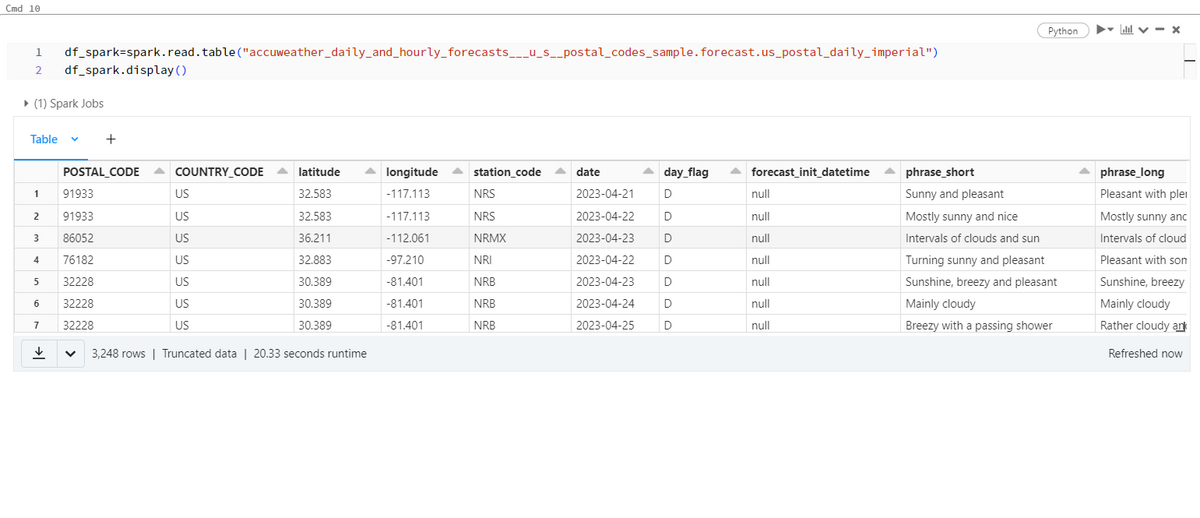
Fig6のように一旦テーブルを読み込んで、中身を表示します。 観測点名(sation_code)や気象情報説明(phrase_short, phrase_long)などの様々な情報が入っているのが分かります。このままテーブルを利用すると計算が遅くなるため、必要最小限のデータを取り出して、新たなテーブルを作成してから図の作成に移ります。
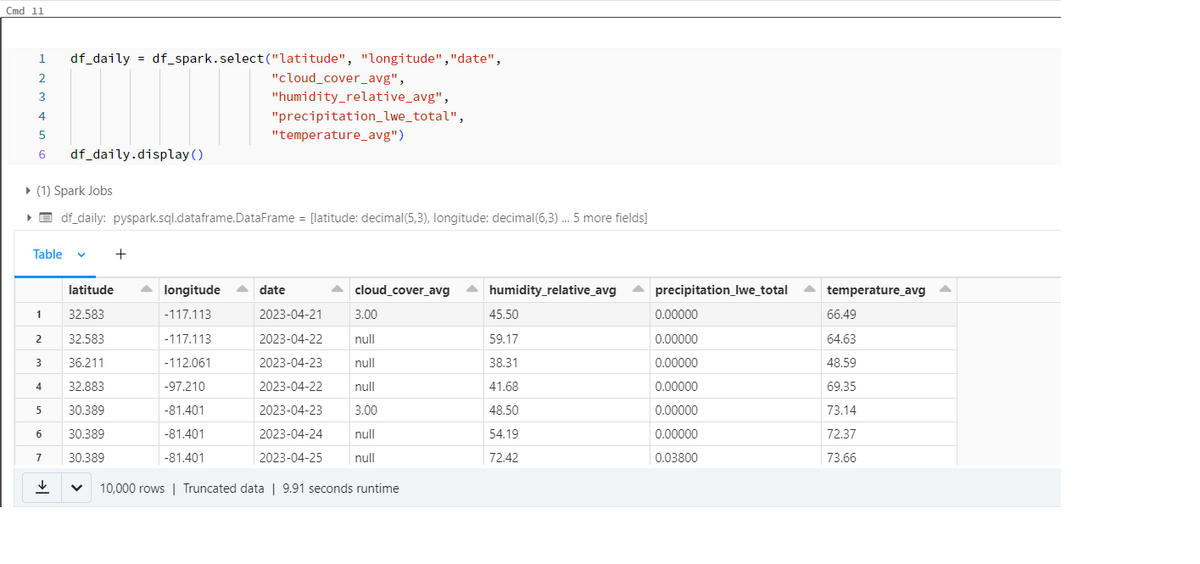
元テーブルから、位置情報(緯度/Longitude・経度/Latitude)、時間情報(日付/Date)、気象情報に関連するカラム(雲量/cloud_cover_avg、相対湿度/humidity_relative_avg、降水量/precipitation_lwe_total、温度/temperature_avg)のデータのみ抽出します(Fig7)。
- 箱ひげ図
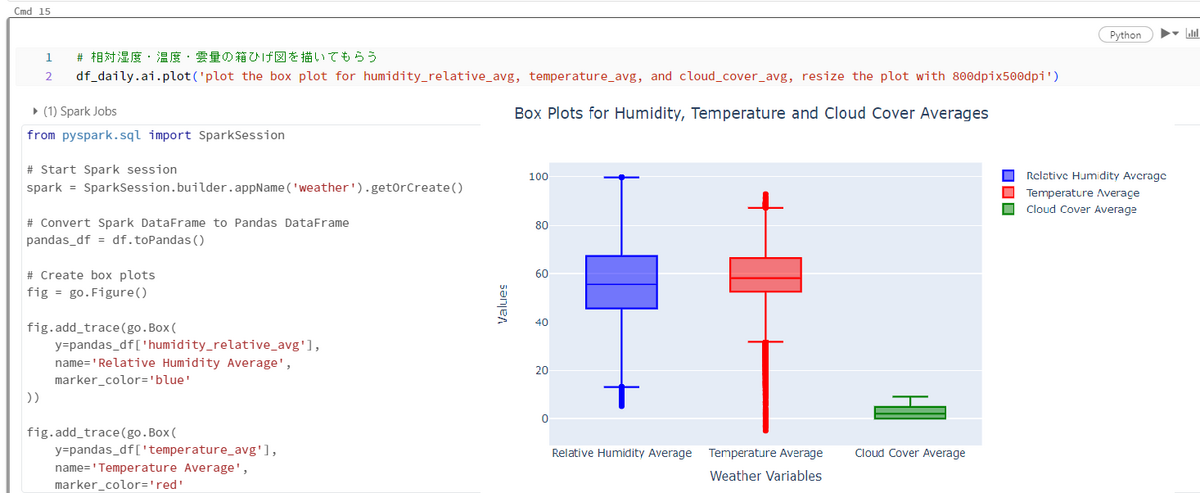
箱ひげ図を作成するために、英語で「plot the box plot for humidity_relative_avg, temperature_avg, and cloud_cover_avg」という指示を出しました。 期待通りに相対湿度、温度、雲量の箱ひげ図を作成してくれました(Fig8)。 実行時に、図を作成するためのPythonコードも表示してくれます。 Pythonだと、それなりの量のコードを作成しなければなりませんが、English SDKだと指示一つで箱ひげ図を作成してくれます!手間を省くことができます。 さらに、こちらのPythonコードを再利用して、より理想に近い図を作成する手助けにもなります。
- 時系列
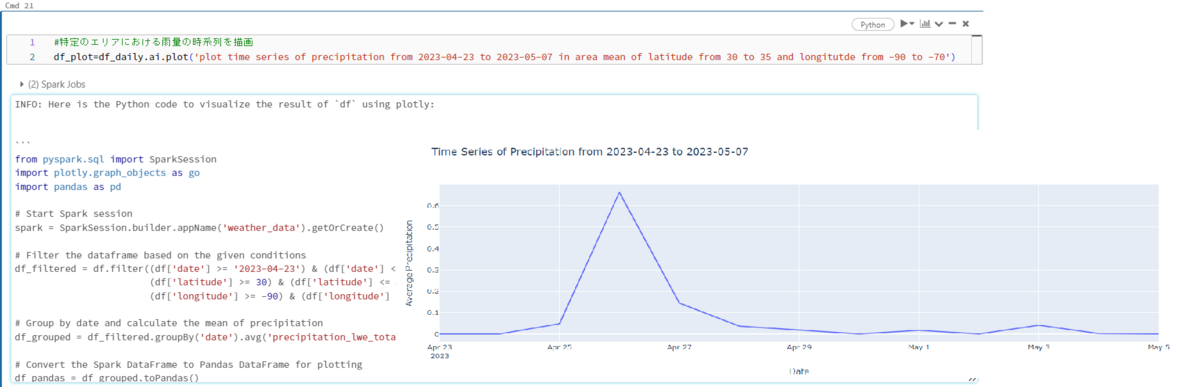
英語で「plot time series of precipitation from 2023-04-23 to 2023-05-07 in area mean of latitude from 30 to 35 and longitutde from -90 to -70」という指示を出しました。緯度「-90°から-70°」と経度「北緯30°から北緯35°」の範囲での雨量の時系列を作画してもらいました。予想通りの図(Fig9)が作成されました。
指示に応じてデータの抽出コード(PySpark)や作画用コード(Python)も実行の同時に出力されます。これでPySparkにおけるデータフレーム操作の考え方や図を作成するヒントにもなりますので、一石二鳥ですね。
- 分布図
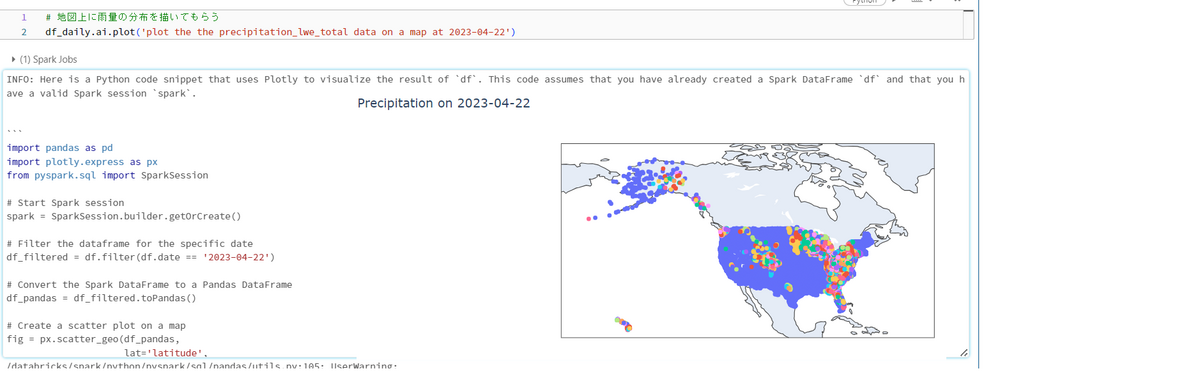
英語で「'plot the the precipitation_lwe_total data on a map at 2023-04-22」という指示を出して、2023年4月22日の降水分布を地図上に描いてもらいました。 Fig10の通りに各観測地点での雨量を描いてくれました。
おわりに
本記事は以上となります。いかがでしたか。
API連携により、English SDKを利用可能となります。コーディング面が煩雑な図の作成は指示一つで終わります。便利です!
私たち、エーピーコミュニケーションズは9/14に開催されるDATA+AI ワールドツアー 東京 2023のゴールドスポンサーになっており、EXPOに出展します。 本記事で紹介されていない、English SDKの日本語指示の対応や格子点の操作(内挿、平均など)や他のLLMに関するデモを行う予定です。 English SDKを試したい、もっと詳しく知りたい方、そして、LLMの活用に関するご興味のある方はぜひ気軽に私たちのブースに立ち寄ってください。

「大規模言語モデル 導入支援サービス」を始めました。 ご興味がある方は気軽にお問い合わせください。
Databricksを用いたデータ分析基盤の導入から内製化支援まで幅広く支援をしております。
ご興味がある方は、お問い合わせ頂ければ幸いです。
また、一緒に働いていただける仲間も募集中です!
APCにご興味がある方の連絡をお待ちしております。