Introduction
This is Abe from the Lakehouse Department of the GLB Division. I wrote an article summarizing the content of the session based on the report by Mr. Ichimura who participated in Data + AI SUMMIT2023 (DAIS) on site.
This time, I'll cover a talk on how to build metadata-driven data pipelines using Delta Live Tables. This talk was presented by Mojgan Mazouchi and Ravi Gawai of Databricks.
Let's take a quick look at what Delta Live Tables is and some of the features that users often use.
An overview of Delta Live Tables and how it functions as a tool for ETL development
Delta Live Tables (DLT) is a new technology for efficiently building data pipelines. This talk showed how to build metadata-driven data pipelines using DLT. The following functions are provided as tools for ETL (Extract, Transform, Load) development.
- Integrate batch and streaming workloads
- Automated infrastructure management
- Ensure high pipeline quality
These features enable data engineers to streamline the development and operation of data pipelines and focus on improving data quality.

Integrating batch and streaming workloads
DLT can seamlessly integrate batch and streaming processing. This eliminates the need for data engineers to manage batch processing and streaming processing separately, allowing them to centrally build and operate data pipelines. And by supporting both batch and streaming processing, data ingestion and processing delays can be minimized.

Automated infrastructure management
Tuning your cluster size is difficult when you have unpredictable dataset volumes or need to meet performance or stringent SLAs. However, with DLT, you can set the number of instances between a minimum and maximum value, and based on your settings, DLT will decide whether it is appropriate to scale compute up or down based on cluster utilization during processing. Judge. As a result, you can avoid overprovisioning or underprovisioning.
Ensure high pipeline quality
Leveraging data quality control and monitoring capabilities makes creating a trusted data source for your pipeline much easier. A feature called Expectations allows you to prevent unwanted data from intruding and aggregate all data quality metrics across your pipeline. In addition, you can view pipeline diagrams and track dependencies to monitor all the tables through which data flows.
DLT meta-approach and meta-programming
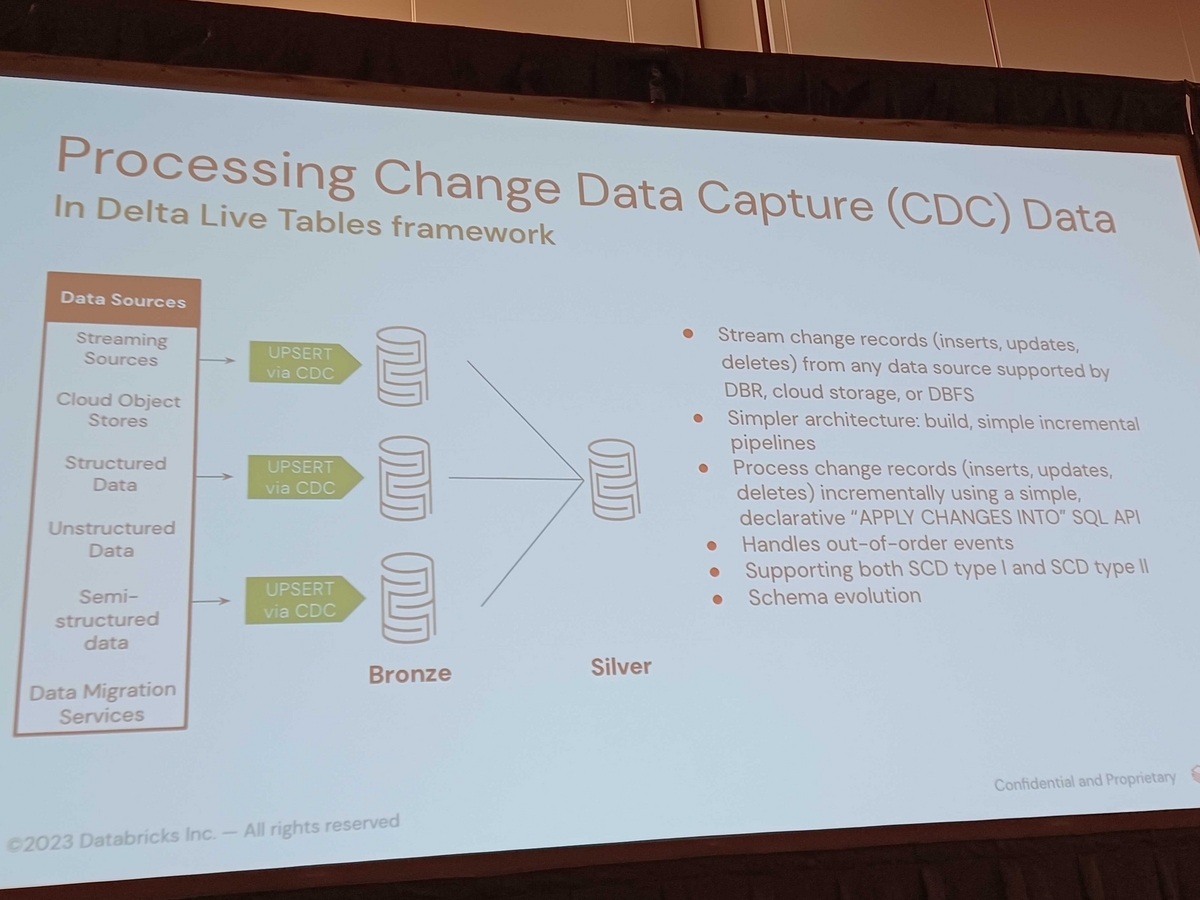
The DLT framework allows you to specify which rows can be inserted, updated or deleted based on primary keys and certain conditions. Its declarative API, apply changes into, is unique in that it implicitly handles order and ensures that events are processed in the correct order. Additionally, it integrates well with Auto Loader, which allows for schema evolution.
When scaling development with hundreds of tables, a metadata-driven approach using a DLT framework can be used. This approach allows you to capture input and output metadata, data quality rules, and transformation logic as SQL. This allows the enrichment layer as a silver layer.
An example is shown below. First, we have three main input files. Onboarding JSON file, Data Quality Rules JSON, and Silver Transformation JSON Logic. These files are transformed by the Meta API into Delta tables known as dataflow specs.
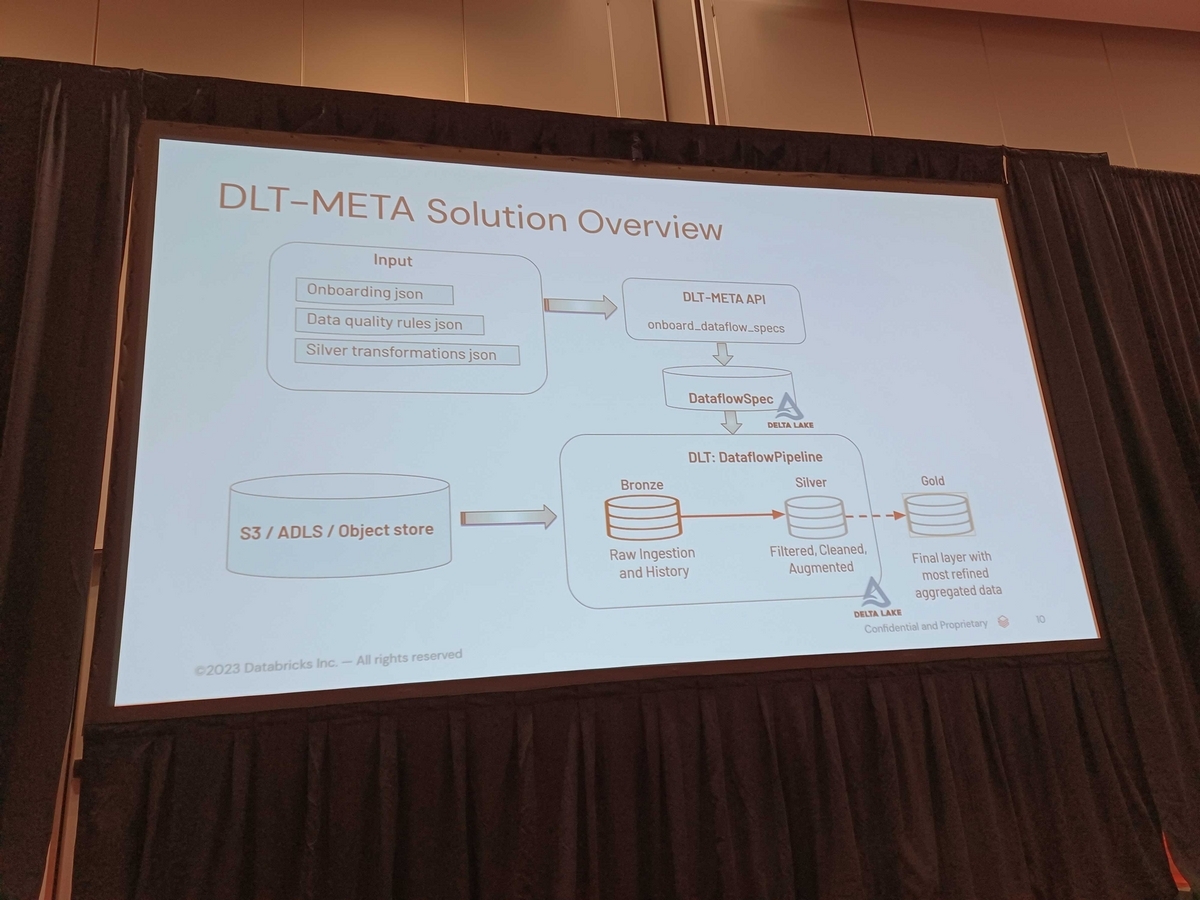
This captures the specification of the data passing through the pipeline. By using the DLT Meta API, you can generate a generic DLT pipeline and create both the bronze and silver tiers of your pipeline. If you need additional aggregations, you can build customized aggregations on top of the gold tier. This is some of the great features of DLT.
Summary
How to build metadata-driven data pipelines using Delta Live Tables (DLT) is very beneficial for data engineers. The ability to integrate batch and streaming workloads, automatically manage infrastructure, and support data quality management and monitoring streamlines data pipeline development and operations to improve data quality. This enables business users to make more accurate data-driven decisions.
Conclusion
This content based on reports from members on site participating in DAIS sessions. During the DAIS period, articles related to the sessions will be posted on the special site below, so please take a look.
Translated by Johann
Thank you for your continued support!
