
Introduction
This is Abe from the Lakehouse Department of the GLB Division. With the rise of chat-gpt, we have heard a lot about Large Language Models (LLMs), and on April 12, 2023, Databricks announced Dolly 2.0, an Open LLM. In the future, Dolly will be introduced to the Databricks Lakehouse Platform, and development and operation using Dolly can be considered. In this article, I will explain Dolly, and finally, by running Dolly, I would like to experience a command-following LLM like chat-gpt.
table of contents
- Introduction
- table of contents
- What is a large scale language model?
- Dolly
- Dolly democratized LLM
- Inference processing with Dolly
- Inference by Dolly
- What to expect in the future
- Conclusion
What is a large scale language model?
Before discussing Dolly, let's take a quick look at large-scale language models. Large-scale language model LLM (Large Language Model) is a model of natural language processing in which the number of parameters of the neural network has reached 100 million units or more as a result of learning large-scale text data. It is capable of processing various natural language processing tasks (sentence generation, sentiment analysis, summarization, etc.) with high accuracy, but its performance is supported by a huge number of parameters. In the case of GPT-3.5, the model used in the free plan ChatGPT, it is said that the training data is over 45TB、and the number of parameters is 355 billion. Learning costs a lot of money and time, but the number of parameters is directly related to accuracy, so in reality, the more parameters you have, the more accuracy you get, and the number of GPTs increases with each series.
(https://research.aimultiple.com/gpt/のOpenAI GPT-n models: Shortcomings & Advantages in 2023から一部引用)
Looking at the graph, we can see that the first GPT model has 110 Millions (=110 million) of parameters, while GPT-3 has 1750 Millions (175 billion).
It is difficult to learn and operate such a model unless it is a high-performance supercomputer, but in recent years, LLMs such as Dolly that achieve a certain degree of accuracy with a small number of parameters have appeared.
Dolly
Dolly is a generative AI model with conversational capabilities from Databricks, which last month announced Dolly 2.0, the world's first open source. It is built on EleutherAI's pythia-12b and trains using a dataset specifically created by Eleuther AI for LLM construction called The Pile. This dataset contains text data from 22 diverse sources, broadly categorized into scholarly articles (e.g. arXiv), the Internet (e.g. CommonCrawl), prose (e.g. Project Gutenberg), and dialogues (e.g. YouTube). Subtitles) and trivia (e.g. GitHub, Enron email).
For more information, see The Pile paper.
Dolly 2.0 is a fine-tuned model based on pythia-12b this. consists of 15,000 pieces of data in QA format (prompts and responses) created by Databricks employees, and is open source and published on GitHub and Hugging Face. In addition, some people have translated it into Japanese using translation software and published it. [Databricks-dolly--15k](https://huggingface.co/datasets/databricks/databricks-dolly-15k)
Databricks-dolly--15k
Dolly democratized LLM
Dolly is notable for democratizing LLM by solving the following challenges:
Low-cost computational resource One of the features of Dolly is that it has a small model size that can be learned at low cost. In the case of GPT-3.5, which is a model of the GPT family, the number of parameters is 355 billion, while the number of parameters of Dolly is 12 billion, which is less than 1/10. Learning is completed with a single PC loaded with Therefore, anyone can perform learning with few computational resources.
Being an Open LLM Licensed for commercial use and available to anyone, including the dataset used for fine-tuning. So you can customize and own the model for commercial purposes. You can also consider building a domain-specific model, such as using it for specific operations in a customer's industry.
Inference processing with Dolly
Finally, move Dolly around and see the response. First prepare the cluster. This time I used the following cluster with a single node.
- Databricks Runtime Version: 13.0 ML
- Node type: Standard_NC16as_T4_v3
- Number of CPUs: 16
- Number of GPUs: 1
- Memory: 110.00 GiB
First, install the package.
%pip install accelerate>=0.12.0 transformers[torch]==4.25.1
accelerate is a library developed by Hugging Face to speed up PyTorch, a deep learning library.
transformers is a PyTorch-powered library containing pretrained models from Hugging Face, used in natural language processing tasks.
The following code Transformers uses the library to call the pretrained text generation model Dolly 2.0.
The pipeline class is useful for calling models and performing inference.
import torch from transformers import pipeline # パイプラインの準備 generate_text = pipeline( model="databricks/dolly-v2-12b", torch_dtype=torch.bfloat16, trust_remote_code=True, device_map="auto" )
It took about 5 minutes to load the model.
Below is a description of each parameter.
model: the name of the model called from Hugging Face
The model name also changes with each different number of parameters. Example) Number of parameters for each model name
・ dolly-v2-12b": 120億
・ dolly-v2-7b": 70億
・ dolly-v2-3b": 30億
torch_dtype: Pytorch tensor data typetrust_remote_code:TrueTrust remote code by specifying :device_map: Device used for model executiondevice_map = cpuAlthough it is set to the device used for model execution ,cudayou can use the GPU by specifying .autoto automatically detect available GPUs and place the model on the appropriate device.
Inference by Dolly
Now, let's specify the prompt to input to Dolly and see the inference result. In prompt engineering, there are methods to improve the accuracy of reasoning before entering a prompt, such as separating instructions and input data, putting them in context, and zero-shot and few-shot prompting. Originally, it should be done by trial and error, but here we will perform the inference without any special modifications.
# 入力するプロンプト prompt = "What is the highest mountain in Japan?" # 推論処理 res = generate_text(prompt) print(res[0]["generated_text"])
Execution result.
The highest mountain in Japan is Mount Everest standing tall at 29032 feet
You should have heard about mountains in Japan, but you answered Mt. Everest, the highest mountain in the world.
Thinking that they didn't learn much about Japan, I changed the prompt to ask about the highest mountain in the world.
prompt = "What is the highest mountain in the world?"
Execution result.
The highest mountain in the world is Mount Everest standing tall at 29032 feet
I answered that it was Everest, and also answered the altitude. Next, we will compare the answer results due to the difference in the number of parameters. Since Dolly has three models for each number of parameters, we compare their inference results.。
- for 7b
The tallest mountain in the world is Mount Everest standing tall at 29032 feet. This is due to it being a tallest peak on all seven continents.
It replies that it is Mount Everest, and it tells me that it is the highest mountain in the world because it is the highest of all continents.
- for 3b
It depends what you mean by the "highest mountain in the world". Geographical terms such as highest, tallest or highest point are not independent criteria for making judgements of which mountains are the highest. The highest mountains can have multiple tops and are often shared between multiple countries. To determine the highest mountains, you could compare their heights against those of other mountains. You could also compare the volume of ice that these mountains contain to find the most massive. This is dependent on a number of factors including the elevation of the base of the mountain.
I answered variously, but I answered that "the highest mountain in the world is not determined by altitude etc., it is a mountain that has multiple peaks and spreads over many countries", and I also answered that I have to compare it with other mountains. You can see from the inference result that the expected answer is not given.
Based on the answer results of the model for each number of parameters, I think the 12b number of parameters model returned the expected answer (in human sense). The expected answer is not specified and the evaluation index is not defined, but it is a straight ball and does not include unnecessary information. This time it was a relatively simple question, but I was able to confirm that the accuracy of the answer changes depending on the number of parameters.
By the way, Hugging Face's Dolly page describes the accuracy for each natural language processing task. In this table, the higher the number, the higher the accuracy, and if you compare Dolly alone, you can see that the more parameters, the higher the accuracy.
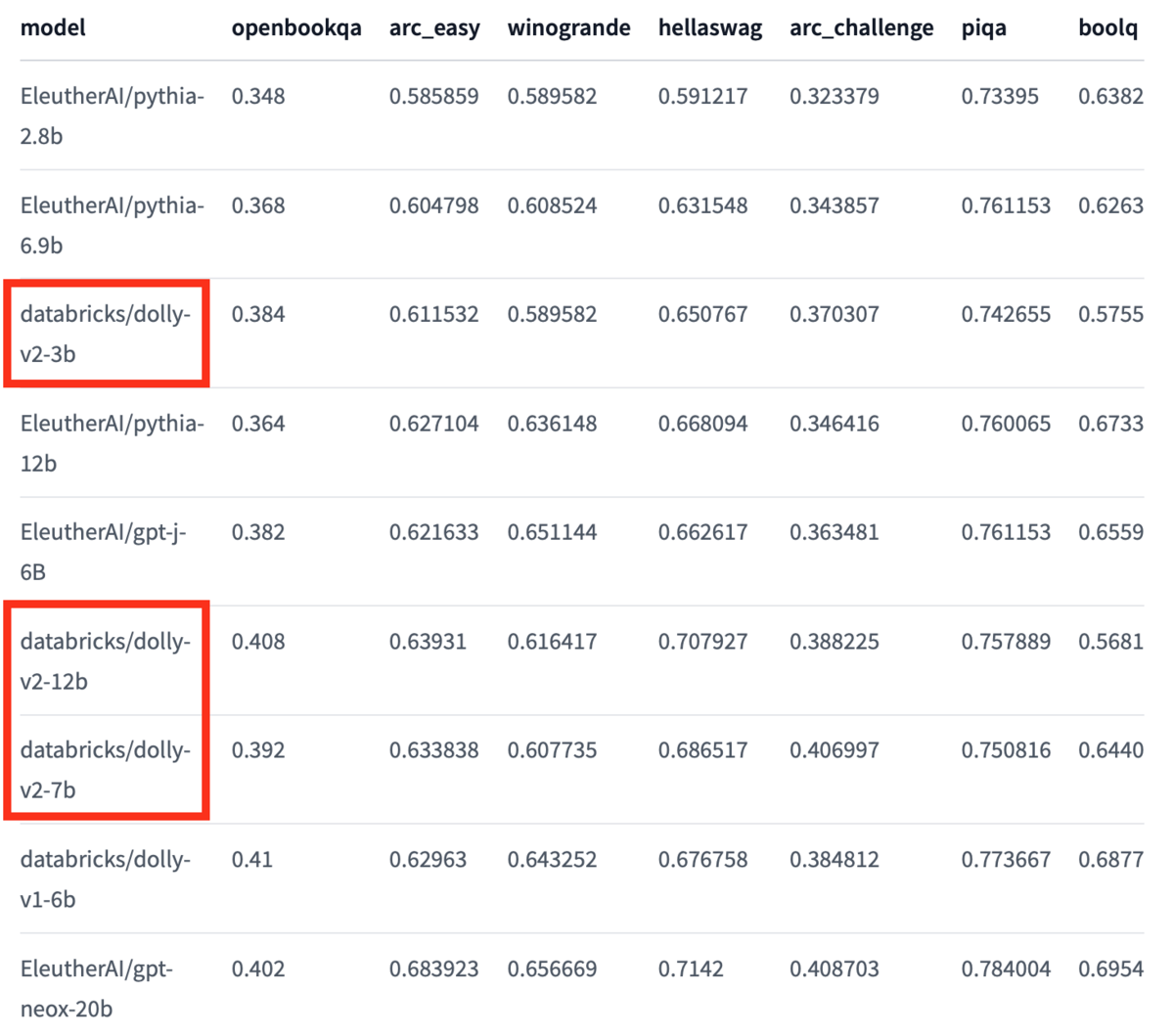
(Partially quoted from Benchmark Metrics at https://huggingface.co/databricks/dolly-v2-12b)
What to expect in the future
By introducing Dolly to the Databricks Lakehouse Platform, it is possible to accelerate the speed of development by combining it with various components. It's just a guess, but I can think of how to use it, such as asking a question in Chat format and using a component in the case of 〇〇. In addition, since it is an open LLM, it is conceivable that an LLM specialized for the customer's domain may be constructed and used for specific task processing.
Conclusion
In this article, we explained Dolly, an open source LLM, and finally moved Dolly to check the answers for each number of parameters. I think that the Databricks Lakehouse Platform will evolve further with Dolly in the future, but in addition to how to handle Dolly, it seems that knowledge of fine tuning and prompt engineering will be required. I hope that I can continue to catch up with Dolly in the future. Thank you for watching until the end. We provide a wide range of support, from the introduction of a data analysis platform using Databricks to support for in-house production. If you are interested, please contact us.
We are also looking for people to work with us! We look forward to hearing from anyone who is interested in APC.
Translated by Johann