
- Introduction
- What is Delta Lake?
- Working with Delta Tables
- What is Delta Log
- Acquisition of table information by DESCRIBE command
- Check Delta Logs
- Why small files are created and file layout optimization
- Restoring past table states with time travel
- Reference article
- Conclusion
Introduction
This is Abe from the Lakehouse Department of the GLB Division. A data lake is used as a storage for accumulating raw data, but when migrating data from a database to a data lake, the meta information is lost, so there was the problem that it became a black box for storing data. Delta Lake solved these issues . In this article, I would like to explain Delta Lake while working with Delta tables.
What is Delta Lake?
A brief description of Delta Lake. Delta Lake is open source software and technology for building a data lake house on existing cloud storage. It supports database operations with ACID properties ( ACID transactions ), providing reliable and consistent data. Below are the ACID properties.
- Atomicity: The transaction may or may not be fully executed, and will revert to its original state if it fails part way through.
- Consistency : Execute transactions based on predefined rules for a table to keep the table consistent.
- Isolation : Multiple users executing transactions against the same table are isolated as separate transactions and do not interfere with each other.
- Durability : The property of being able to withstand system failures, and if transactions are completed normally, data will be saved forever even if failures occur.
The default format for tables created in Databricks is Delta and we call them Delta tables .
Delta itself consists of parquet file data and json file transaction log ( Delta Log ).
parquet The file is read and converted to Delta format when creating the Delta table.
Delta Log will be discussed later.
If you want to understand more about Delta Lake, please refer to the official Azure documentation
Working with Delta Tables
We will use SQL to manipulate the Delta table. To create a new notebook, select your user name from Users in the workspace, right-click on the user name, and select Notebook from the displayed operation list.
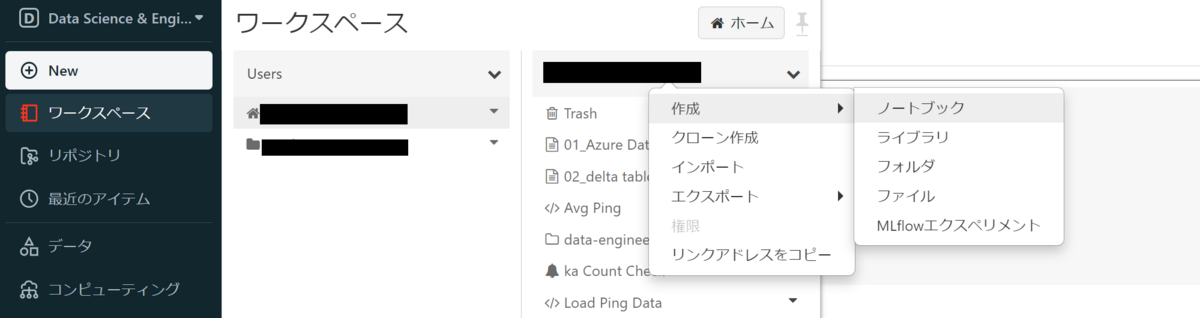
SQL is the main language used in the created notebook, so select SQL from the Default Language pull-down.
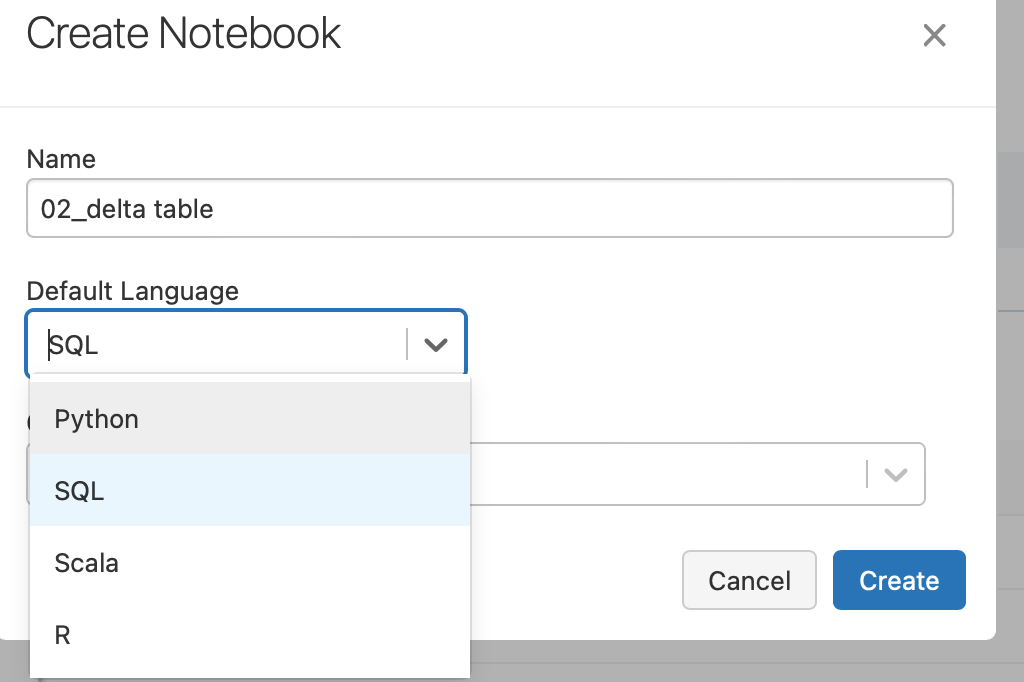
Start by creating a Delta table called wine with the following schema.
| フィールド名 | フィールド型 |
|---|---|
| alcohol | FLOAT |
| color | STRING |
| volume | FLOAT |
| delicious | BOOLEAN |
Create table
Create a wine table.
CREATE TABLE wine (alcohol FLOAT, color STRING, volume FLOAT, delicious BOOLEAN)
I have created a table.
insert record
Next, insert a record into the Delta table you just created.
INSERT INTO wine VALUES (15.1, 'red', 150, true), (12.6, 'white', 180, true), (10.9, 'amber', 40, false), (16.1, 'yellow', 400, false); SELECT * FROM wine
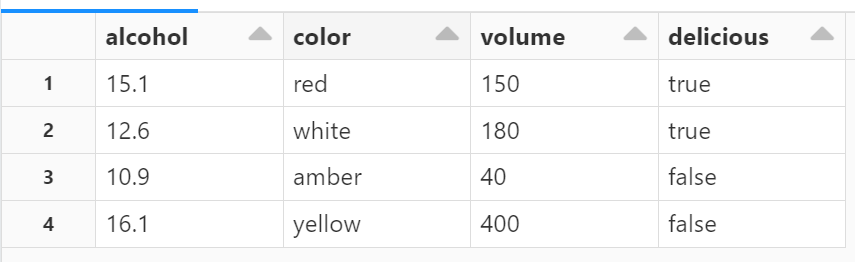
I was able to confirm that the record was inserted. It is also possible to download the table data referenced from the table pulldown in CSV format and add it to the dashboard .
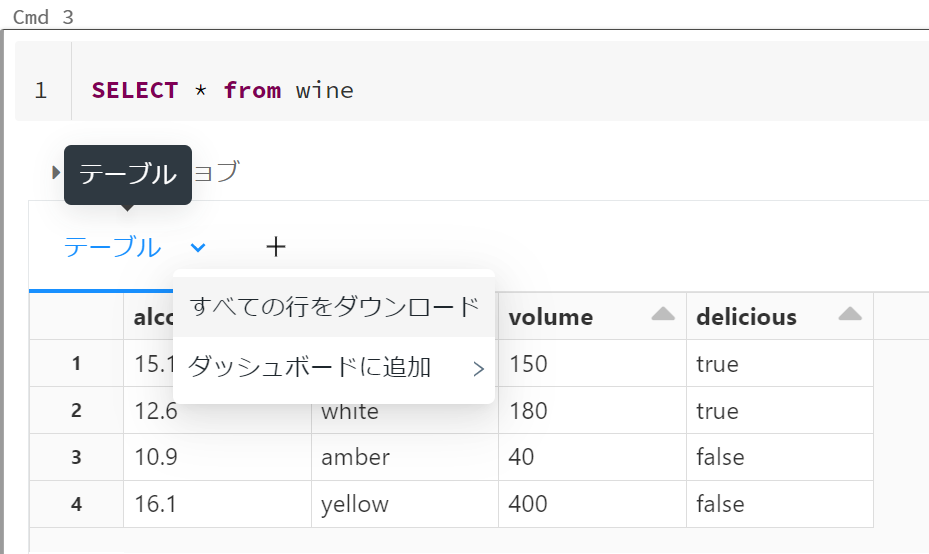
You can also click the + tab to see visualizations and data profiles.
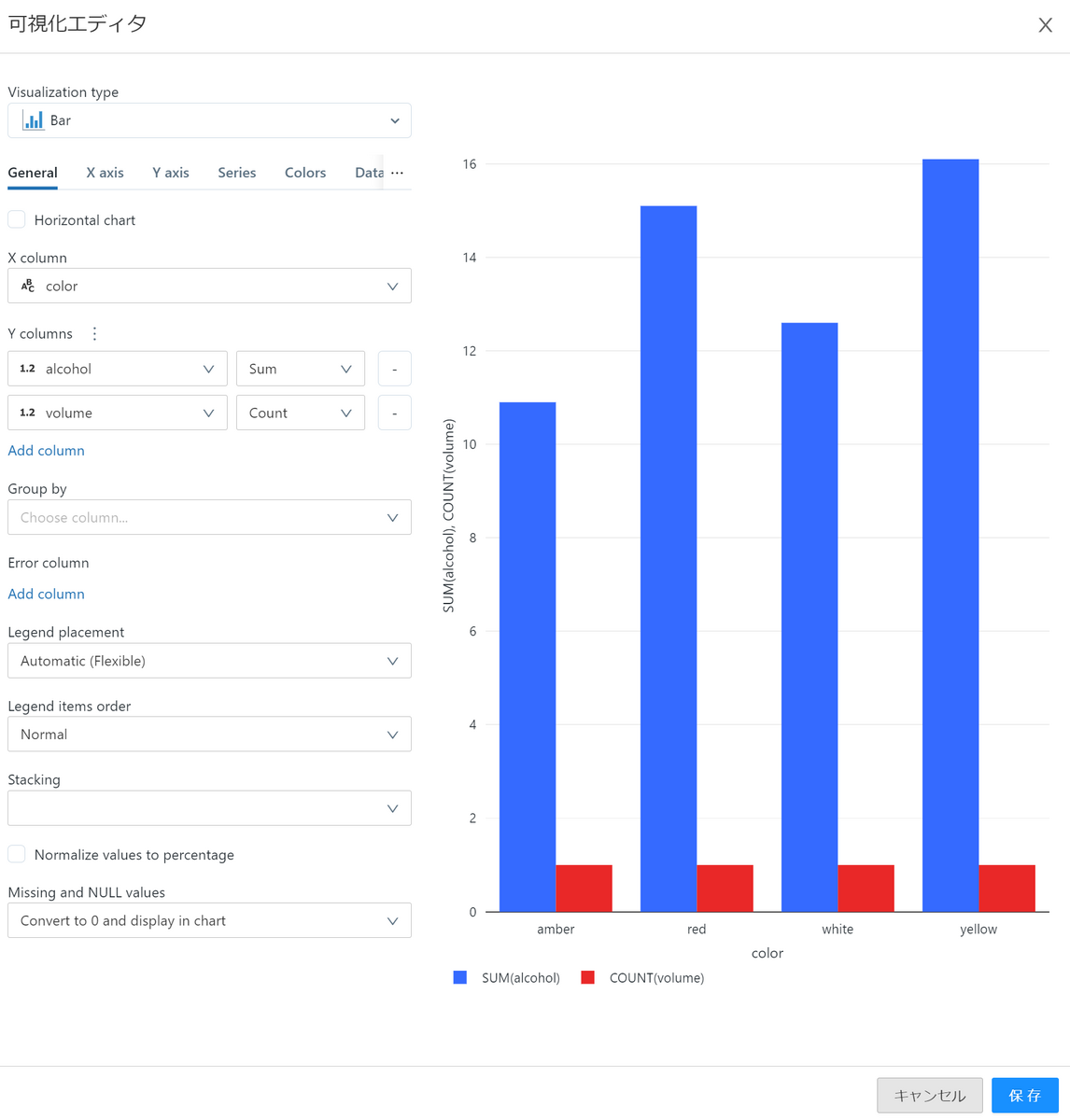
Visualization is a feature that allows you to easily graph your data. Create a bar chart for each color of the wine table.
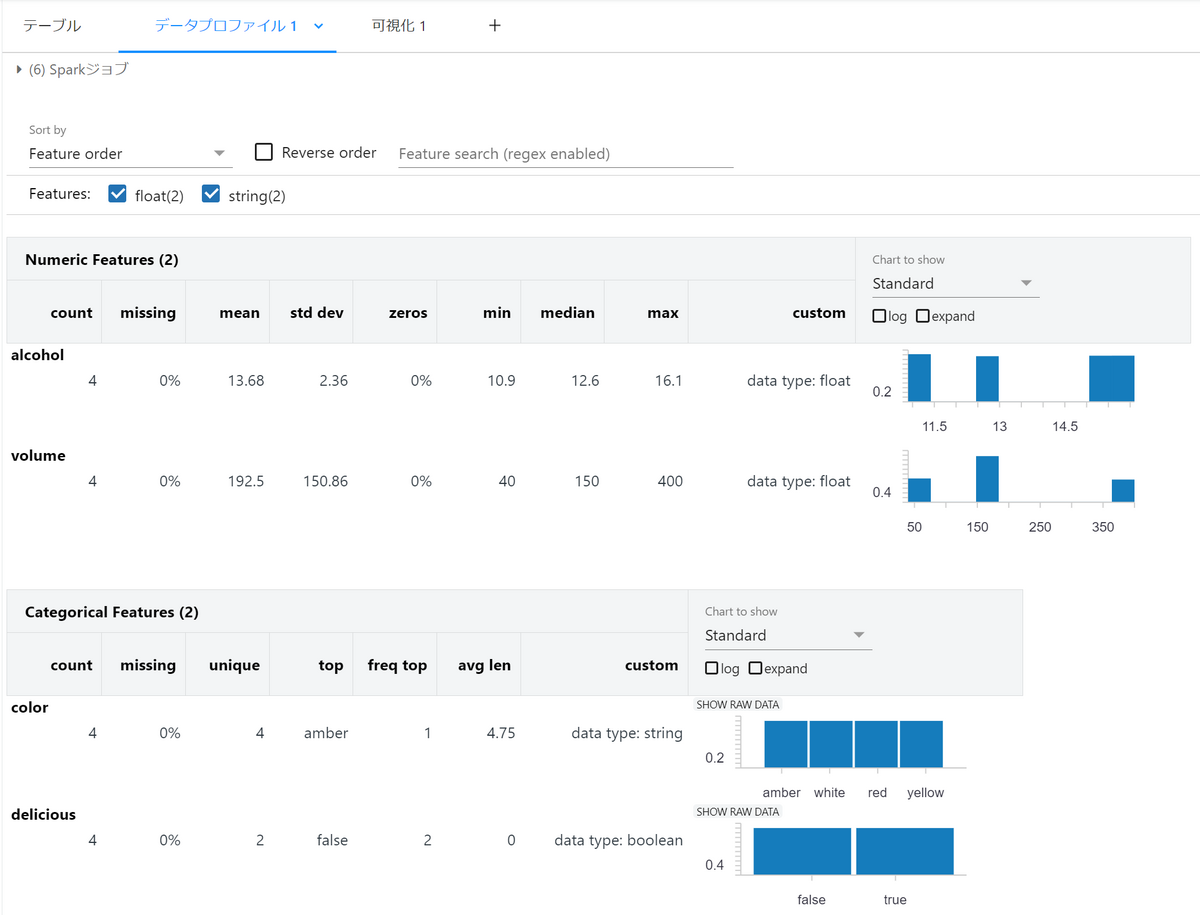
Data Profiles allow you to view the distribution and basic statistics of your data. However, it takes time to display, so be careful when the amount of data is large.
update table
Wines with color amber have false deliciousness, but now they are true.
UPDATE + table name Update the table with the command and SET change the delicious column false to true with the command.
UPDATE wine SET delicious = true WHERE color = 'amber'; SELECT * FROM wine
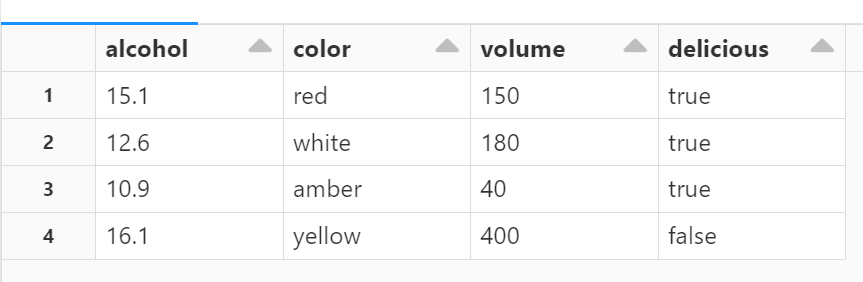
I can confirm that the record has been updated.
Delete record
I would like to remove wines with “false” in the delicious column from the records.
DELETE FROM wine WHERE delicious = false; SELECT * FROM wine

I can confirm that the record has been deleted.
Upsert records by joining tables and views
Now create a new view and join with the existing wine table. At that time, if the color is the same wine, add the volume and update of the existing wine table. Also, if it's good wine, insert that record. First, create a view called new_wine.
CREATE OR REPLACE TEMP VIEW new_wine(alcohol, color, volume, delicious) AS VALUES (15.1, 'red', 200, true), (20.4, 'rose', 40.0, true), (10.6, 'orange', 58.5, true), (18.9, 'black', 300.2, false); SELECT * FROM new_wine
A view has been created. Then set a condition in the WHEN clause and join with the wine table.
MERGE INTO wine a USING new_wine b ON a.color = b.color WHEN MATCHED THEN UPDATE SET volume = a.volume + b.volume WHEN NOT MATCHED AND b.delicious = true THEN INSERT *; SELECT * FROM new_wine
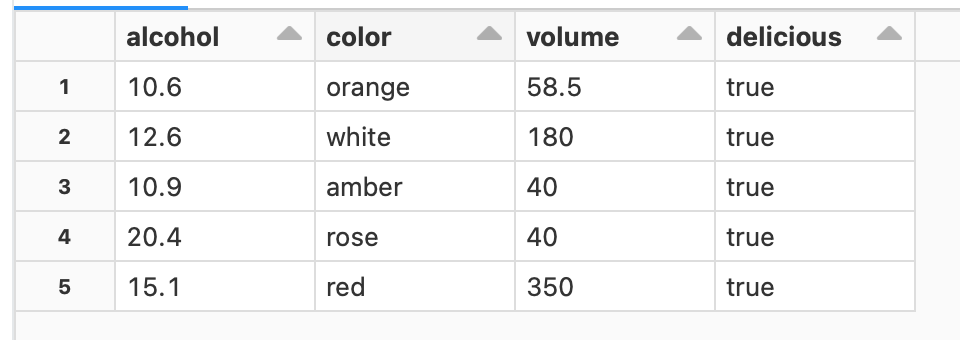
I was able to add the volumes of the red wines together.
Delete table
Deleting a table DROP TABLE + table name is done with
DROP TABLE wine
I deleted the table.
What is Delta Log
From here we will manipulate the table using Delta Log. Delta Log is Delta Lake's transaction log, which records changes to a table (transaction log) in chronological order. This enables atomicity guarantees, table metadata management, time travel, etc. Time travel is described later, but it is a function that allows you to refer to previous versions of tables by going back in time. In the second half of this article, I will check the Delta Log and explain how to execute time travel.
Acquisition of table information by DESCRIBE command
Recreate the table that was deleted before checking the Delta Log of the wine table, and execute the transactions so far. This time, we added an id column and changed the MERGE condition from color match to id match or not. I also added a comment to the alcohol column because I can add a comment to the column when creating the table.
CREATE TABLE wine( id INT, alcohol FLOAT COMMENT 'Low alcohol degree!', color STRING, volume FLOAT, delicious BOOLEAN); INSERT INTO wine VALUES (1, 15.1, 'red', 150, true), (2, 12.6, 'white', 180, true), (3, 10.9, 'amber', 40, false), (4, 16.1, 'yellow', 400, false); UPDATE wine SET delicious = true WHERE color = 'amber'; DELETE FROM wine WHERE delicious = false; CREATE OR REPLACE TEMP VIEW new_wine(id, alcohol, color, volume, delicious) AS VALUES (1, 15.1, 'red', 200, true), (6, 20.4, 'rose', 40.0, true), (7, 10.6, 'orange', 58.5, true), (8, 18.9, 'black', 300.2, false); MERGE INTO wine a USING new_wine b ON a.id = b.id WHEN MATCHED THEN UPDATE SET volume = a.volume + b.volume WHEN NOT MATCHED AND b.delicious = true THEN INSERT *;
DESCRIBE + table name to check the table information.
DESCRIBE wine
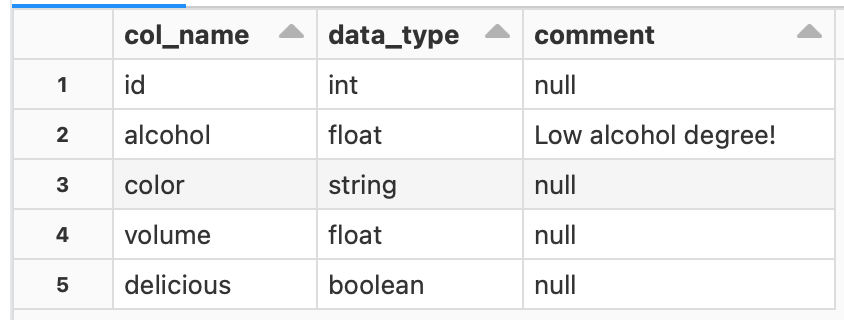
You can see the data type and comment content for each column.
If you want to check only the information of a certain column, DESCRIBE + table name + database name.table name.column name write
DESCRIBE wine default.wine.alcohol
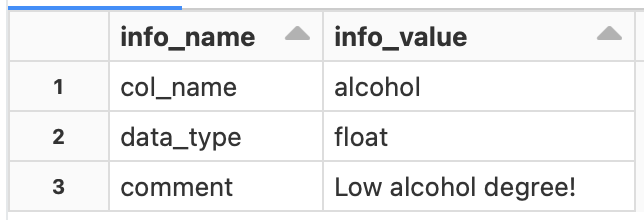
I was able to get the information of the alcohol column.
If you want to check the meta information of the table, DESCRIBE + EXTENDED + table name write
DESCRIBE DETAIL wine
Indicates the CSV file that downloaded the execution results. (Because it is difficult to see on the UI because it is necessary to scroll the table)
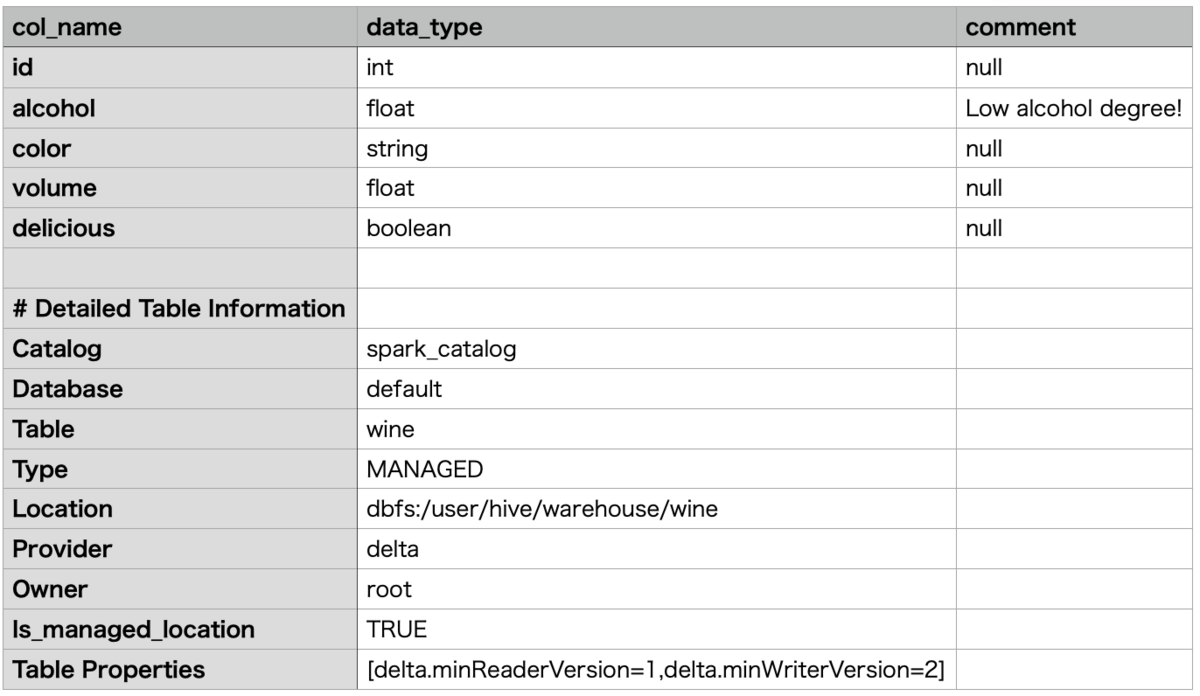
I was able to get the meta information of the table. Each meta information is described below.
- Catalog: catalog name
- Database: database name
- Table: table name
- Type: The type of table. Table types include managed tables and unmanaged tables (external tables).
- Location: where the table is stored
- Provider: data format
- Owner: table owner
- Table Properties: Table properties. The delta table is versioned by Delta Log, showing the lowest readable and writable version of each.
*Simply put, the difference between managed and unmanaged tables is whether you manage both table data and meta information. For more information, please refer to the following article, which is explained in an easy-to-understand manner.
Another command to check the meta information of a table DESCRIBE + DETAIL + table name.
Due to the display range, some of the execution results are shown below.
 Location etc. can be confirmed in the same way as before.
Location etc. can be confirmed in the same way as before.
Check Delta Logs
One way to check the Delta Log for a table is to use the Databricks Utilities (dbutils) File System Utilities ( ). To check the Delta Log of the wine table, use the command to get a directory listing of the Databricks File System (DBFS).dbutils.fs
dbutils.fsls
For details on dbutils and DBFS, please refer to the official azure documentation.
What is the Databricks File System (DBFS)?
Delta Logs are files stored in the _delta_log directory under the table's directory. You can specify the file path and display it as follows.
%python
display(dbutils.fs.ls("dbfs:/user/hive/warehouse/wine/_delta_log"))
When creating the notebook, the default language was SQL, so when using Python commands, you need to write %python and MAGIC commands at the beginning like the code above. The MAGIC command is also summarized in the following article.
Databricks-02. From cluster creation to code execution - APC 技術ブログ
Below is a CSV file that downloads the execution results.

The _delta_log directory consists of two types of files ( crc, ) corresponding to each transaction . Since the files are indexed from 0 to 4, we know that there were 5 transactions.json
I will explain each file.
The 3, 4 checkpoint files are the files created every 10th commit to the table, and this time they are not created because it is a 5th transaction.
However, the checkpoint file creation frequency is optimized and RESTORE will be created when you run the command described below.
jsonFile: The transaction log isjsonrecorded as a file, automatically created in the _delta_log directory when the Delta table is created.crc(Cyclic Redundancy Check) file: Contains table version statistics and is used to check data integrity .Checkpoint file:
parquetSince the version information of the table is aggregated in the checkpoint file of Checkpoint file, it is only necessary to read the Delta Log after the Checkpoint file when referring to the table, which reduces the calculation cost. There is also a function to delete past transaction logs after a certain period of time.Last Checkpoint file: stores the most recent checkpoint, reducing computational costs when retrieving the latest table state.
The __tmp_path_dir directory stores temporary data backups and temporary files during write processing. This is the directory where temporary files are stored, so the files do not exist after writing is completed. json As an example, to check the Delta Log corresponding to the last transaction, MERGE, we can see that we can refer to the file indexed as 4.
SELECT * FROM json.`dbfs:/user/hive/warehouse/wine/_delta_log/00000000000000000004.json`
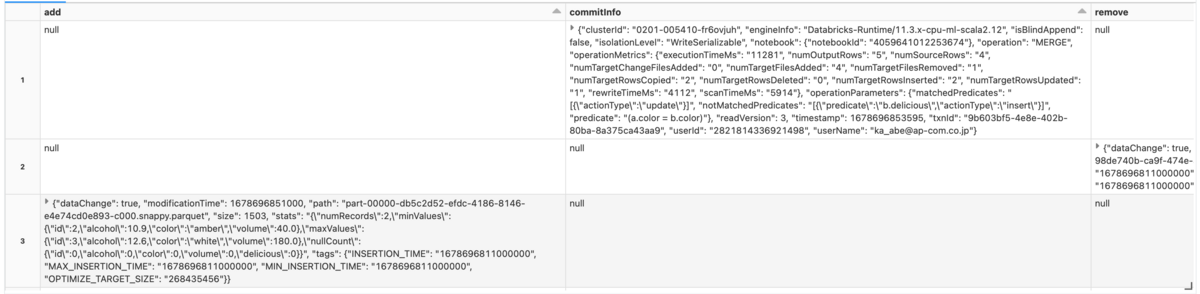
You can check the add column and remove column from the execution result.
The remove column records the files that were removed if the original data was removed, of course, DELETE etc. This time, the data is updated by , and the original data is deleted. Also, the add column is recorded when data is added or recreated without deleted data.UPDATE
UPDATE
Why small files are created and file layout optimization
parqet As I mentioned at the beginning, Delta Lake consists of data files and transaction logs (Delta log).
parquet A file is generated every time data is added, for example, INSERT streaming from a data source, outputting data by batch processing, etc. will create an endless number of files for the output data.
That's why we describe Parquet files that are created repeatedly as small files.
parquet When creating a dataframe from a Delta Table, read all the generated files.
Therefore, the generation of a large number of small files degrades data loading efficiency, that is, query performance.
OPTIMIZE There is a command on how to group such small files into one file and optimize the file layout .
Takes as a parameter ZORDER BY + column name to optimize the file layout using the specified column name(s).
ZORDER An image of the file layout before and after execution is shown below.

(Delta 2.0 - The Foundation of your Data Lakehouse is Open | Delta LakeQuoted from Delta 2.0 - The Foundation of your Data Lakehouse is Open | Delta Lake 's Support Z-Order clustering of data to reduce the amount of data read)
When reading all files, OPTIMIZE you can see that the later file layout seems to be more efficient to read.
As an example, run file optimization with ZORDER on the wine table.
For column names, specify ones with high cardinality (the number of data types), so examples include customer IDs and product IDs.
OPTIMIZE wine
ZORDER BY id

This time, the data handled is very small, so the effect of OPTIMIZE cannot be felt, but the more data, the more noticeable the improvement in query performance.
Restoring past table states with time travel
Time travel is the ability to view previous versions of data and restore tables to their original state, with Delta Log automatically versioning changes made to your data.
To see the transaction history, DESCRIBE + HISTORY + table name run
DESCRIBE HISTORY wine

Displayed the processing contents of each transaction. You can see that version management is performed for each transaction from the
creation of the wine table .OPTIMIZE
The current table version is 5, but if you want to refer to the version 3 table before MERGE, execute as follows.
SELECT * FROM wine VERSION AS OF 3
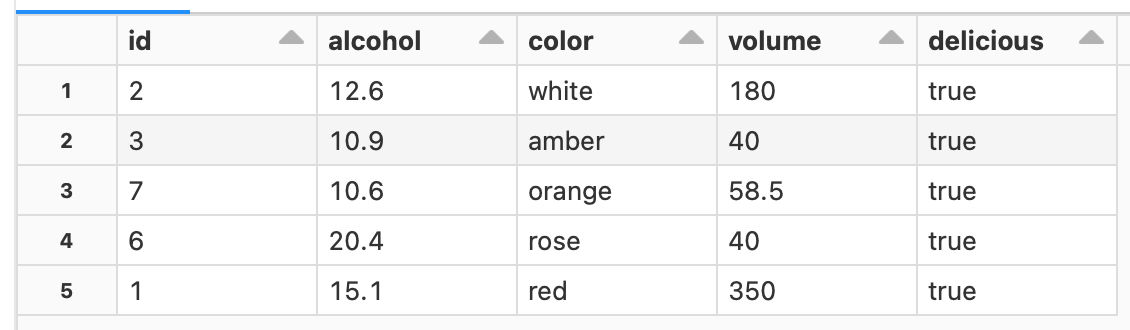
This code is just a reference, and the version 3 table has not been restored.
If you want to restore the table, RESTORE TABLE + table name + TO VERSION AS OF + version name write
RESTORE TABLE wine TO VERSION AS OF 3

I introduced how to restore a table by specifying a version, but I will also show you how to restore using the delta log timestamp. Display the timestamp when the files under the _delta_log directory were created.
%python !ls -lt /dbfs/user/hive/warehouse/wine/_delta_log
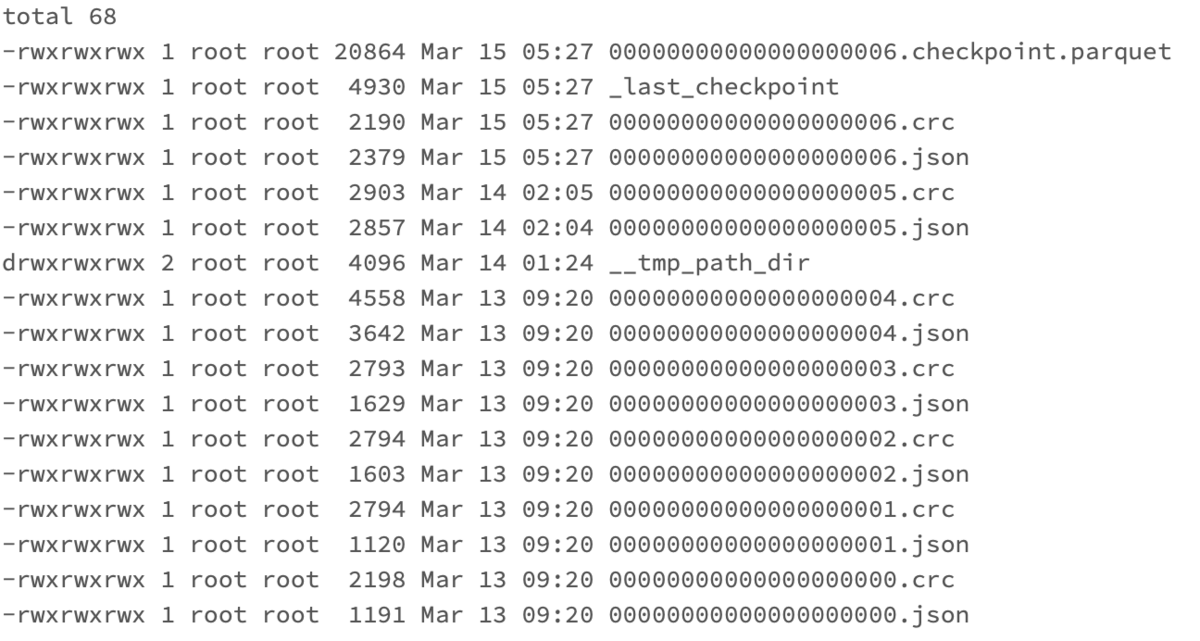
You can see the creation of the checkpoint file, which was not there before. Similarly, since the version of the table to be restored is 3, we can see that the Delta Log as of 09:20 on March 13, 2023 should be referenced. By specifying the time with timestamp instead of the version name, you can restore the table at that point in time.
RESTORE TABLE wine TO TIMESTAMP AS OF '2023-03-13 09:20:01'
Browse the wine table to see if you were able to restore to the previous version.
SELECT * FROM wine

I was able to restore the table.
Reference article
Delta 2.0 - The Foundation of your Data Lakehouse is Open
Conclusion
In this article, in order to understand Delta Lake, we touched on Delta table operations and table history confirmation and restoration using Delta Log.
The entity of Delta Lake consists of parquet file data and json file transaction log (Delta Log). Delta Log enables ACID transaction support and table restoration.
I would like to continue posting the details of verification using Databricks in the future, so please take a look at it again.
We provide a wide range of support, from the introduction of a data analysis platform using Databricks to support for in-house production.
If you are interested, please contact us.
We are also looking for people to work with us! We look forward to hearing from anyone who is interested in APC.
Translated by Johann