
- Introduction
- Issues of feature management
- What is the Feature Store?
- Benefits of the Feature Store
- Databricks Feature Store
- Procedure to create Feature Table
- Data preparation
- Create a Delta Table
- Create Feature Table
- Override Feature Table
- Create a Feature Table with tags
- Add tags to Feature Table
- Deleting Tags in Feature Table
- Register an existing Delta table as a Feature Table
- Delete Feature Table
- Reference article
- Conclusion
Introduction
This is Abe from the Lakehouse Department of the GLB Division. In this article, I would like to explain the history of the Feature Store and the functionality of the Databricks Feature Store through a notebook. In data analysis, there is a process of "feature engineering" that creates new feature values from existing feature values, but managing feature values tends to be complicated. Having said that, when I forget what kind of logic was used to create the feature values that I created in the past, or accidentally deleted the feature values from the table data, there is a lot of effort I put into restoring the feature values. I will explain the Feature Store that solves such problems.
Issues of feature management
Before explaining the Feature Store, I will explain the challenges of feature management in machine learning system construction and data analysis. The management of feature values used for learning ML models becomes complicated as time passes and the number of members increases, and the following problems arise.
Feature creation is expensive If there is a feature quantity created in the past within the organization, it can be reused, but if the feature quantity is not centrally managed, it must be newly created.
Unclear when and how features created in the past were created It is not possible to manage when, by whom, and with what kind of logic the features were created, and feature creation depends on the individual. This makes it difficult and costly to reproduce features created in the past.
Inconsistency between features during training and inference In many cases, the timing of learning and inference (model serving) are different and separated in time. As a result, the feature values input to the model at each point of training and inference are different, and a model that performs well in training may experience a drop in accuracy during inference. This makes the forecast less reliable.
What is the Feature Store?
Feature Store solves the above problems. The first public feature store, Michelangelo Palette, was launched by Uber in 2017. Since then, big tech companies have entered the market and some companies are offering products equivalent to Feature Stores, while others are producing Feature Stores in-house. As shown below, the Feature Store functions as a platform that can centrally manage feature values by referencing or registering feature values in all phases from feature engineering to model learning and evaluation, inference, and monitoring.
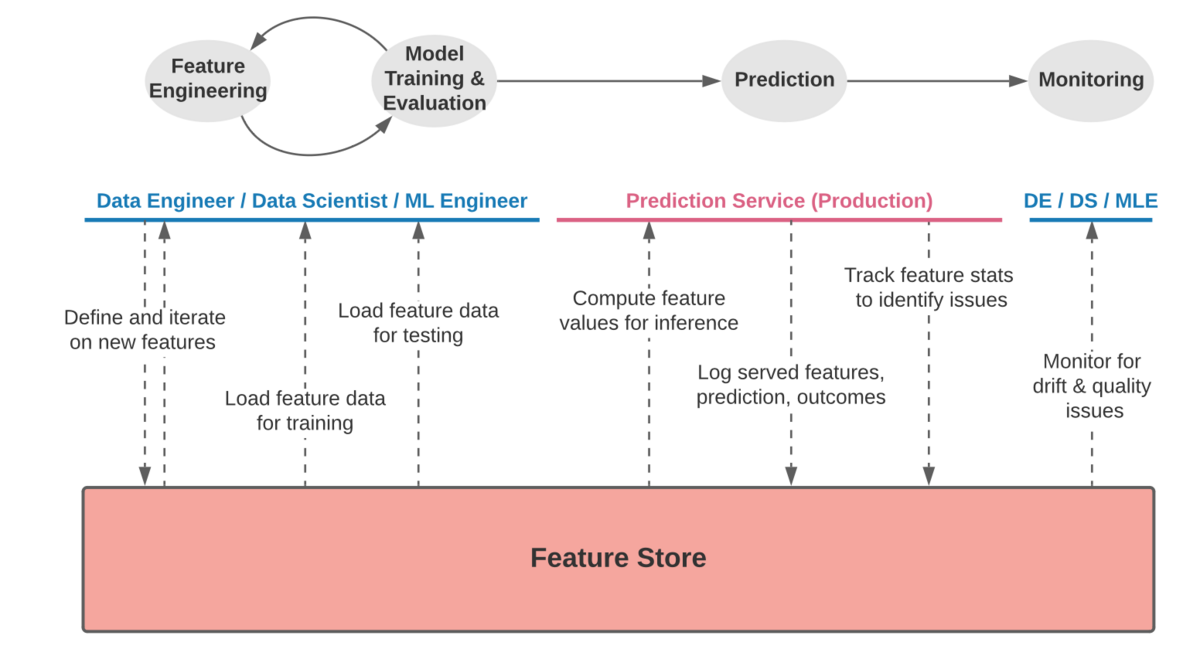
(Excerpt from Enter the feature store at https://feast.dev/blog/what-is-a-feature-store/)
Centralized management of features in this way solves the challenges of feature engineering and inference, and enables feature checking for model drift and model quality monitoring.
Benefits of the Feature Store
By using the Feature Store, you can solve the problems in feature management mentioned earlier. Next, I will describe the advantages of using the Feature Store.
Feature reuse By registering the created features in the Feature Store, it is possible to reuse features between teams. Therefore, with pre-created features, data scientists can quickly create ML models without being overwhelmed by feature creation tasks.
Shared use between teams. Similar to the previous advantage, the Feature Store platform, which can centrally manage features, makes it easy to develop, save, modify, and reuse features shared between teams.
Ensuring feature consistency. You can understand the feature creation logic from the features registered in the Feature Store.
Align feature values for learning and inference. By using features registered in the Feature Store during both training and inference, it contributes to maintaining the high model performance obtained during training.
Strengthening data governance. Feature Store allows you to specify which features were used for learning for each ML model. In addition, data governance will be strengthened by enabling feature store access control for each user.
Databricks Feature Store
Databricks Feature Store workflow is shown below.
- Read raw data as Spark DataFrame from source data
- Output Spark DataFrame to Feature store
- Train a model using features registered in the Feature Store
- Register the model in the model registry For batch processing, the feature values of Feature Store are automatically acquired.
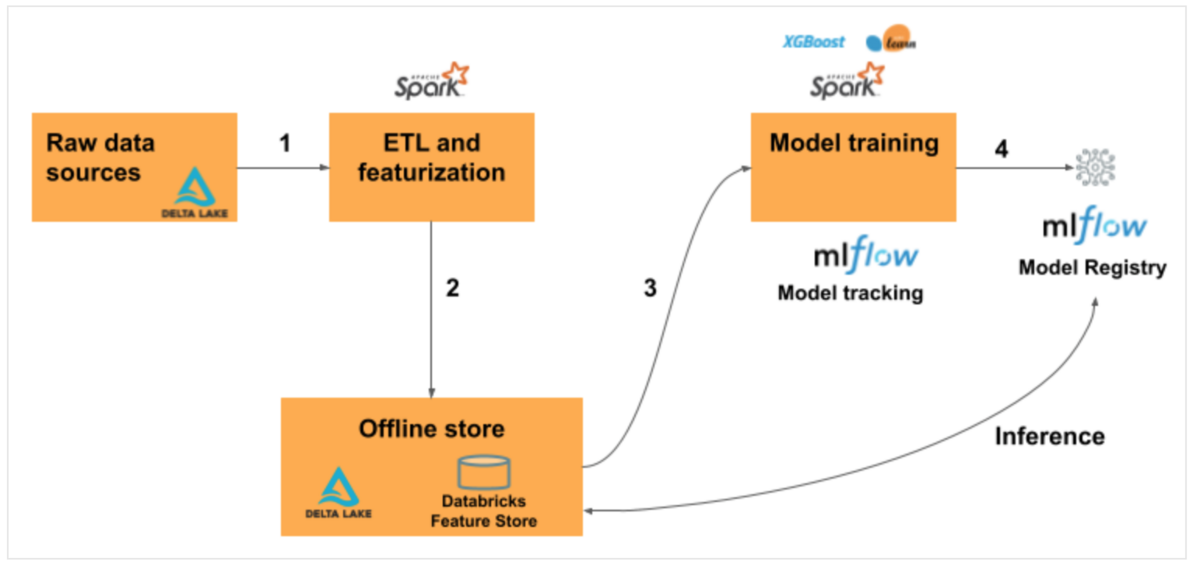
Online stores are used for real-time inference use cases, but are not covered in this article. If you are interested, please refer to the official documentation of Azure.
Feature Store workflow overview
In this article, I will explain as far as the output to the Feature Store.
Procedure to create Feature Table
As a review, the procedure for creating a Feature Table is shown below.
- Step 1. Preparation of Spark DataFrame
- Step 2. Create a Delta Table using the created Spark DataFrame
- Step 3. Read Spark DataFrame from Delta Table
- Step 4. Output loaded Spark DataFrame to Feature Store
You can output the Spark DataFrame to Feature Store as it is without following steps 2 and 3, but we will also create a Delta Table in accordance with the operation method of outputting to Feature Store from the data accumulated in Feature Table.
Data preparation
First prepare the data. This time, we will use the California house price dataset from the scikit-learn dataset. Here is the 1990 California house price data from the 1990 US Census.
from sklearn.datasets import fetch_california_housing import pandas as pd df = fetch_california_housing(as_frame=True) # カリフォルニアのデータセットを読み込む train_X = df.data # 説明変数(特徴量)のデータ train_y = df.target # 目的変数のデータ data = pd.concat([train_X, train_y], axis = 1) data.head(3)

The Data Frame output to the Feature Store must be an Apache Spark DataFrame with a primary key, so create a primary key and convert it to a Spark Dataframe.
# 1から連番のidカラムを作成する data['id'] = range(1, len(data.index) + 1) # idカラムを先頭に持ってくる first_column = data.pop('id') data.insert(0, 'id', first_column) house_df = spark.createDataFrame(data) display(house_df)
View the created Spark DataFrame.

Create a Delta Table
Create a Delta Table using the created Spark DataFrame.
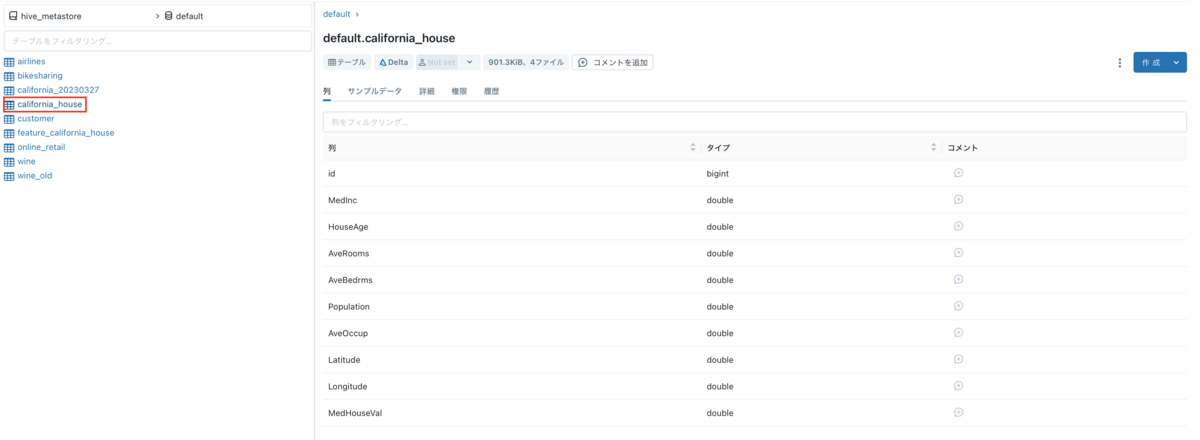
table_name = "california_house" (house_df.write .format("delta") .saveAsTable(table_name))
Created a Delta Table. You can also check it from the data explorer.
Create Feature Table
Read Spark DataFrame from Delta Table.
delta_df = (spark.read.table('default.california_house')
Create a Feature Table with the loaded Spark DataFrame. Set the "id" created earlier as the primary key, and set the partition key to "Latitude".
from databricks import feature_store fs = feature_store.FeatureStoreClient() feature_table_name = "feature_california_house" fs.create_table( name = feature_table_name, primary_keys = ["id"], df = delta_df, partition_columns = ["Latitude"], description = "california houses data" )
Each option of create_feature is as follows
- name: Name of Feature Table to be created in Feature Store
- primary_keys: primary keys
- df: Spark DataFrame
- partition_columns: partition key
- timestamp_keys: columns with time information (date, time, etc.)
- description: Description of the Feature table
Since this dataset is not time-series data, timestamp_keys is not specified, but for time-series data, specify columns with time information.
Get Feature Store metadata.
Acquisition of metadata is executed by fs.get_table(Feature Store table name).description.
print(f"Feature table description : {fs.get_table(feature_table_name).description}") print(f"Feature table data source : {fs.get_table(feature_table_name).path_data_sources}")
Check the created Feature Table from the Feature Store UI.
Go to the Machine Learning workspace and click Feature Store on the sidebar to display the Feature Table list.
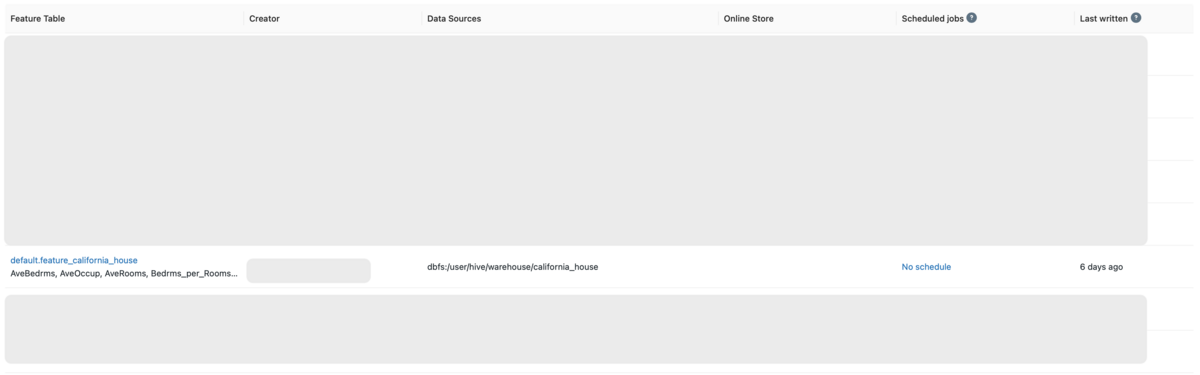
Click the Feature Table name to display the detailed information of the Feature Table. You can see when it was created, who last updated it, and from which Delta Table it was created, which will lead to stronger data governance.
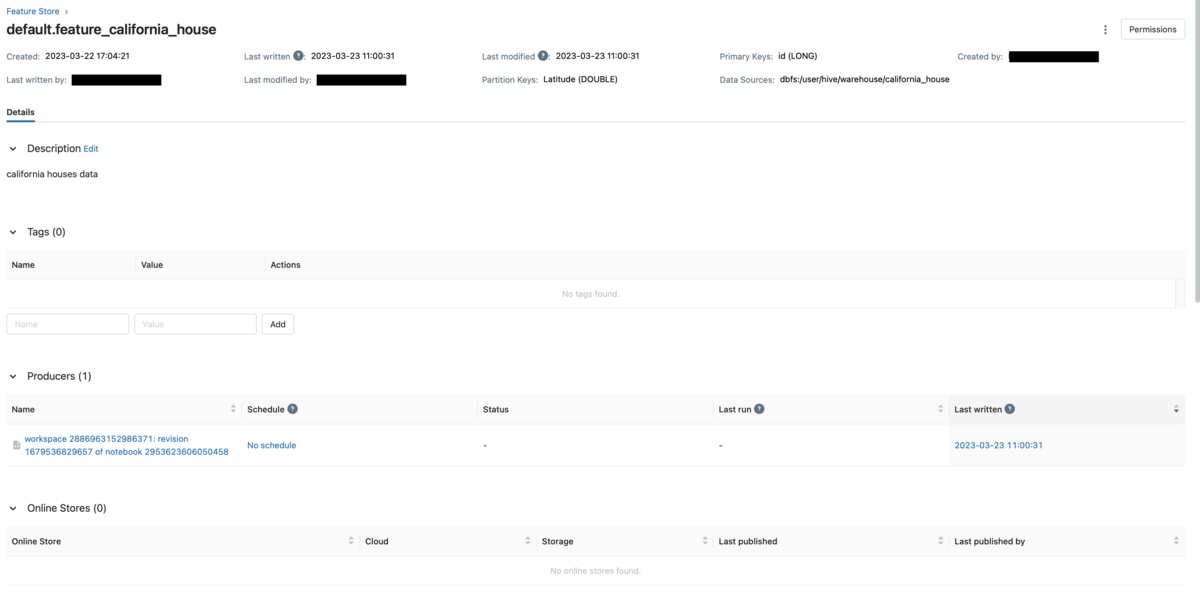
Scroll to see features.
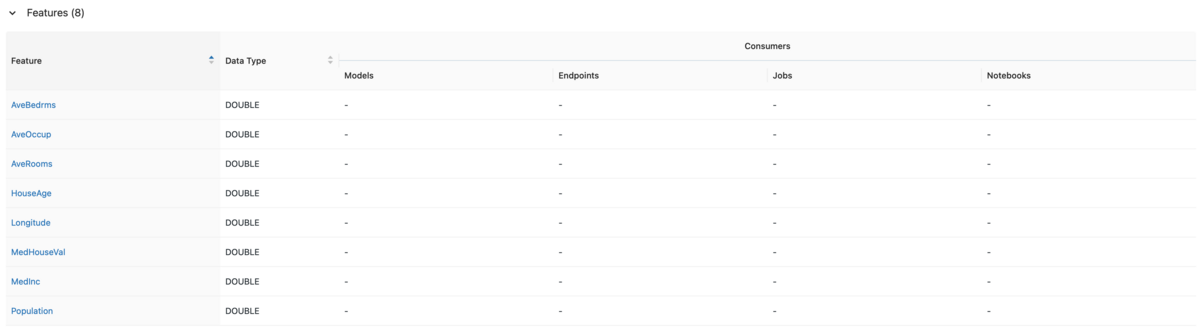
※The objective variable is also output together, but during learning, the flow is to read the data from the Feature Table and separate the explanatory variable and the objective variable.
Override Feature Table
Add a new column to a Spark DataFrame. Here we create a column called Bedrms_per_Rooms that calculates the number of beds per room.
drop_columns = ['AveBedrms', 'AveRooms'] delta_df_new = (delta_df.withColumn('Bedrms_per_Rooms', delta_df['AveBedrms'] / delta_df['AveRooms']) .drop(*drop_columns) )
Output to the Feature Store is done with write_table.
overwrite the Feature Store by specifying overwrite in the mode option.
fs = feature_store.FeatureStoreClient() feature_database = "default" feature_table_name = f"{feature_database}.california_house" fs.write_table(name = feature_table_name, df = delta_df_new, mode = "overwrite")
Go to the Feature Store UI.
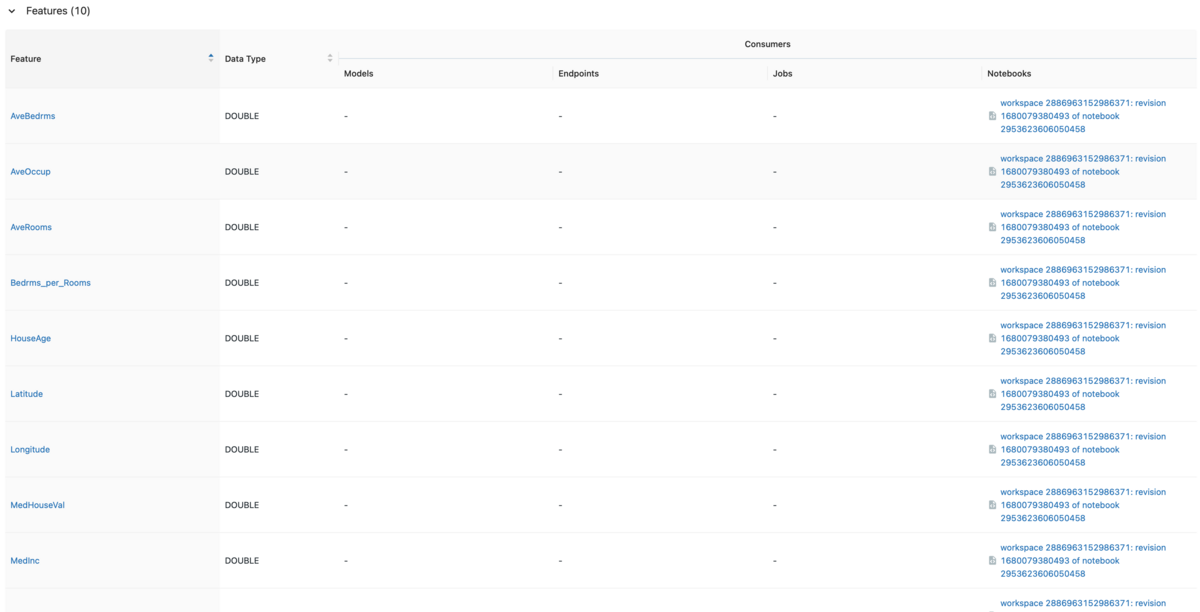
The deleted columns(AveBedrms, AveRooms) are still in the table's schema, but reading the Feature Table with fs.read_table reveals that the values have been replaced with null.
feature_df = fs.read_table(
name = feature_table_name)
display(feature_df)

By the way, specify yesterday's time in as_of_delta_timestamp to read the Feature Table before column deletion.
By specifying the time for as_of_delta_timestamp, you can read the Feature Table at that time, and time travel in Delta Lake is possible.
import datetime yesterday = datetime.date.today() - datetime.timedelta(days = 1) fs = feature_store.FeatureStoreClient() feature_database = "default" feature_table_name = f"{feature_database}.california_house" feature_df = fs.read_table( name = feature_table_name, as_of_delta_timestamp = yesterday )
Create a Feature Table with tags
Adding tags to the Feature Store makes it easier to search within the Feature Store.
To create a Feature Table with tags, specify tags when executing create_table.
Earlier, we created the Delta Table in the Default database, but since creating a database for the Feature Table is best practice, we will create a database called california_db.
CREATE DATABASE IF NOT EXISTS california_db
Create a Feature Table with tags.
feature_database = "california_db" feature_table_name = f"{feature_database}.california_tag" fs.create_table( name = "california_tag", primary_keys = ["id"], df = delta_df, partition_columns = ["Latitude"], tags = {"california_house_dataset_1": "house_price", "california_house_dataset_2": "Bedrms_per_Rooms"}, description = "california houses data" )
For the tag option, enter a lexicographical key-value pair tag.
After navigating to the Feature Store UI, you can see a table called california_tag.
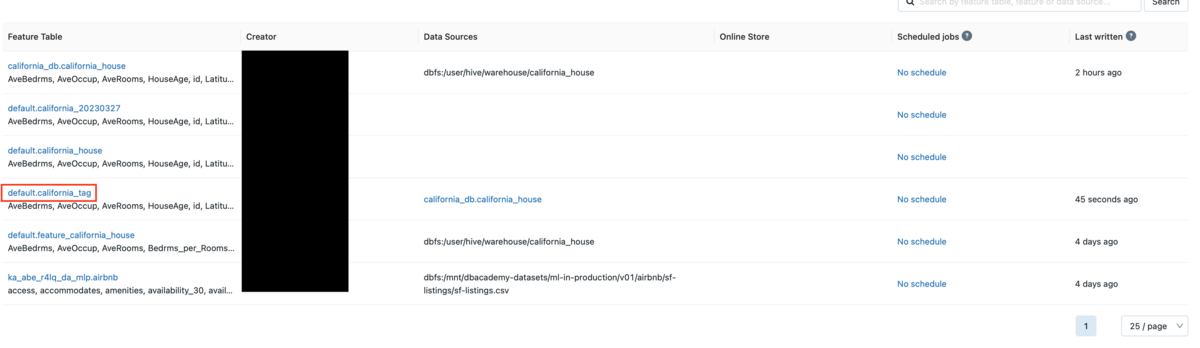
After clicking the table name, check the list of tags.
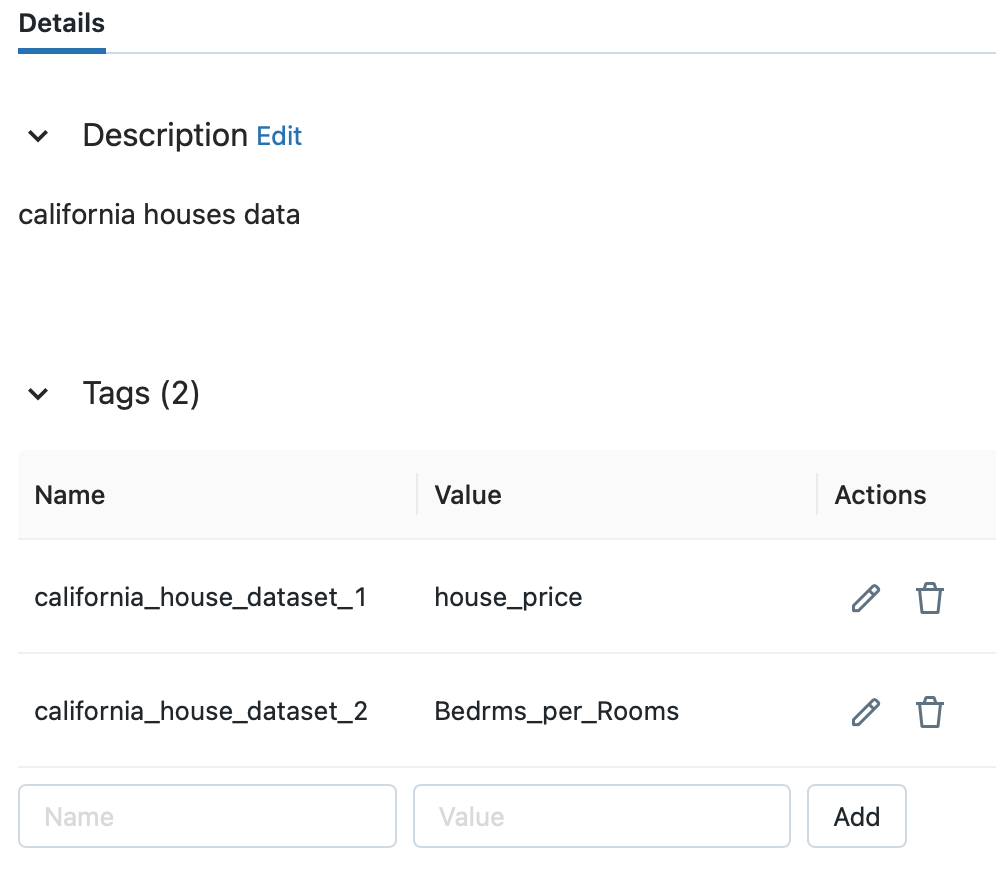
I was able to confirm that the tag I entered earlier was added.
Add tags to Feature Table
You can add tags to Feature Tables using the Feature Store Python API.
The table_name specifies the Feature Table to which the tag is added, and the tag is set as a set of key and value.
Add tags using the set_feature_table_tag method of FeatureStoreClient().
fs = feature_store.FeatureStoreClient() fs.set_feature_table_tag(table_name = 'california_tag', key = 'california_house_dataset_3', value = 'Population')
Select the Feature Table with added tags from the Feature Store.
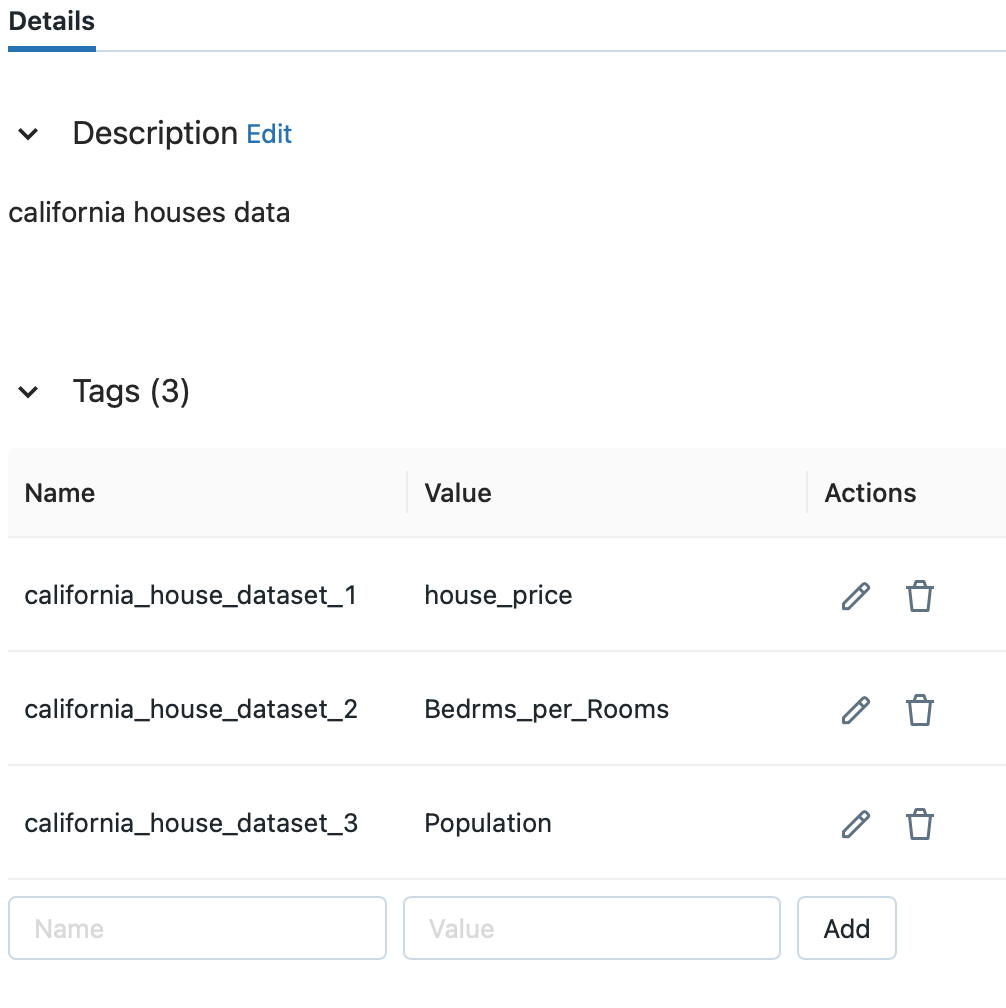
You can see that the tag has been added. As an example, let's say you want to display california_db.california_house with a tag added from the Feature Table list.
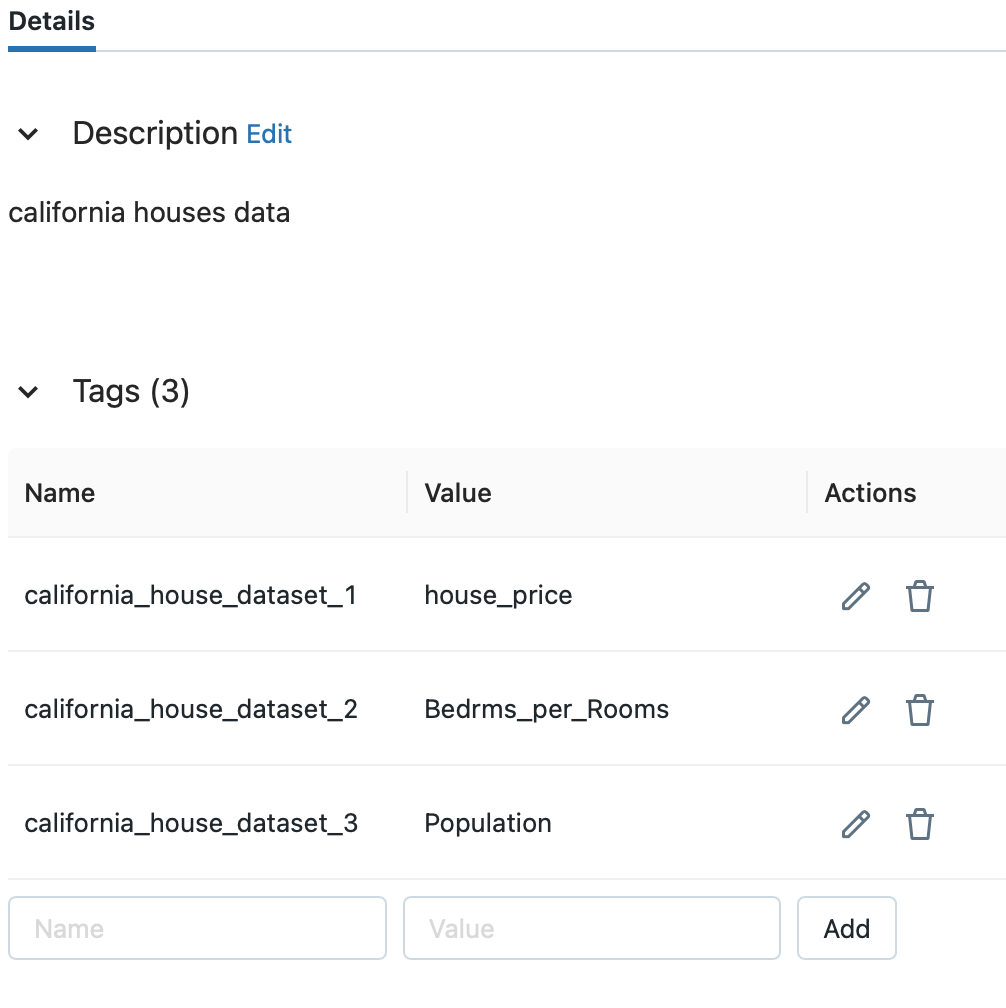 You can see that the same table name is displayed in the Feature Table list although the schema is different.
Especially when there are many similar table names, searching by tags is very powerful.
You can see that the same table name is displayed in the Feature Table list although the schema is different.
Especially when there are many similar table names, searching by tags is very powerful.
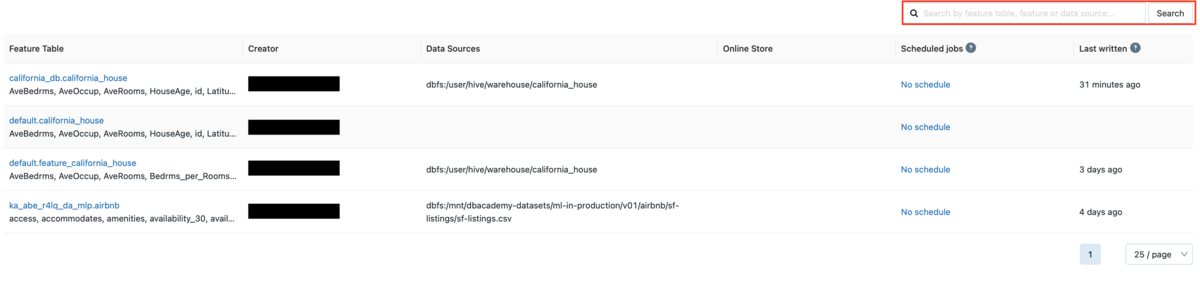
Enter the key or value in the tag you added in the search field. Here we enter the tag key california_house_dataset_3.

You can confirm that only the Feature Table with added tags is displayed.
Adding tags is also possible in the Feature Store UI.
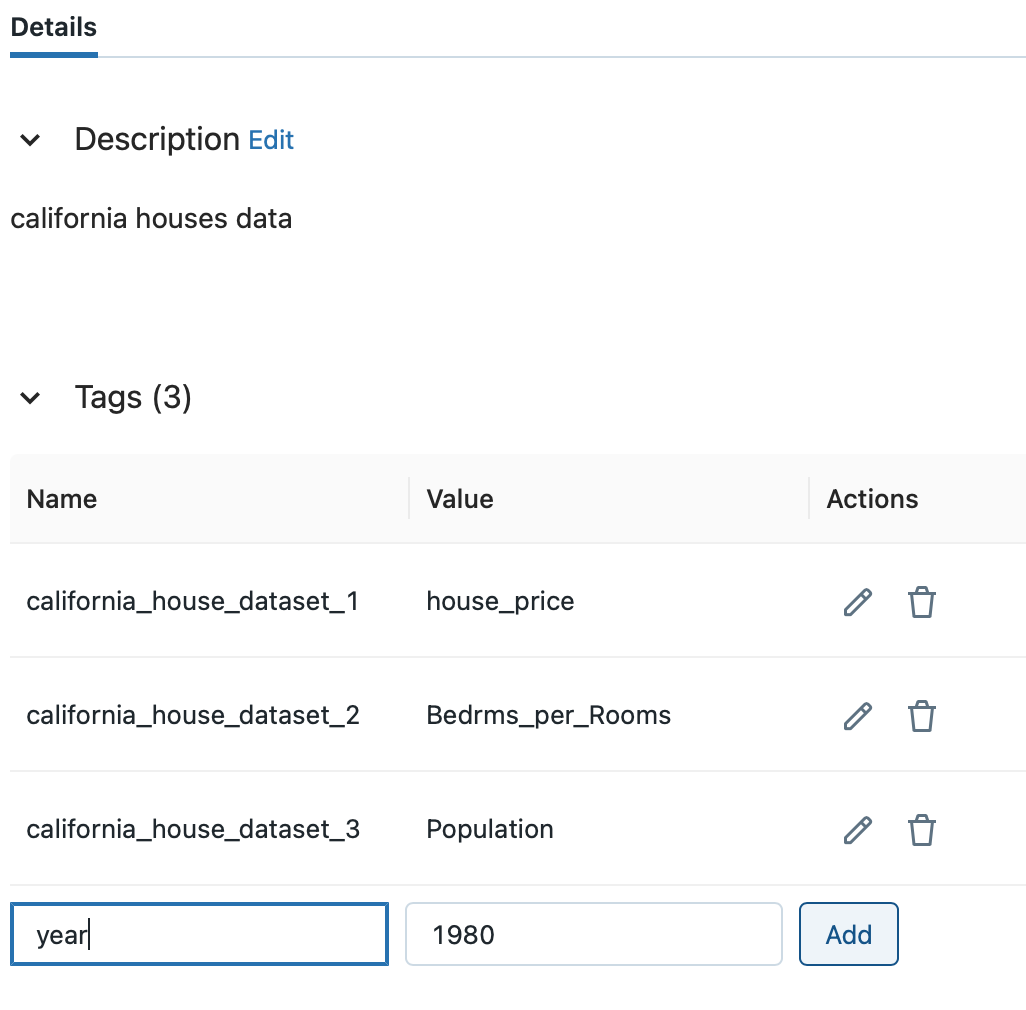
After entering the key and value in the Name and Value fields from the tag list, click the Add button.
Deleting Tags in Feature Table
To delete a tag, use the delete_feature_table_tag method of FeatureStoreClient().
fs = feature_store.FeatureStoreClient()
fs.delete_feature_table_tag(table_name = feature_table_name, key = 'california_house_dataset_3')
You can also delete tags in the Feature Store UI. Click the trash can icon in the Actions column to remove the tag.
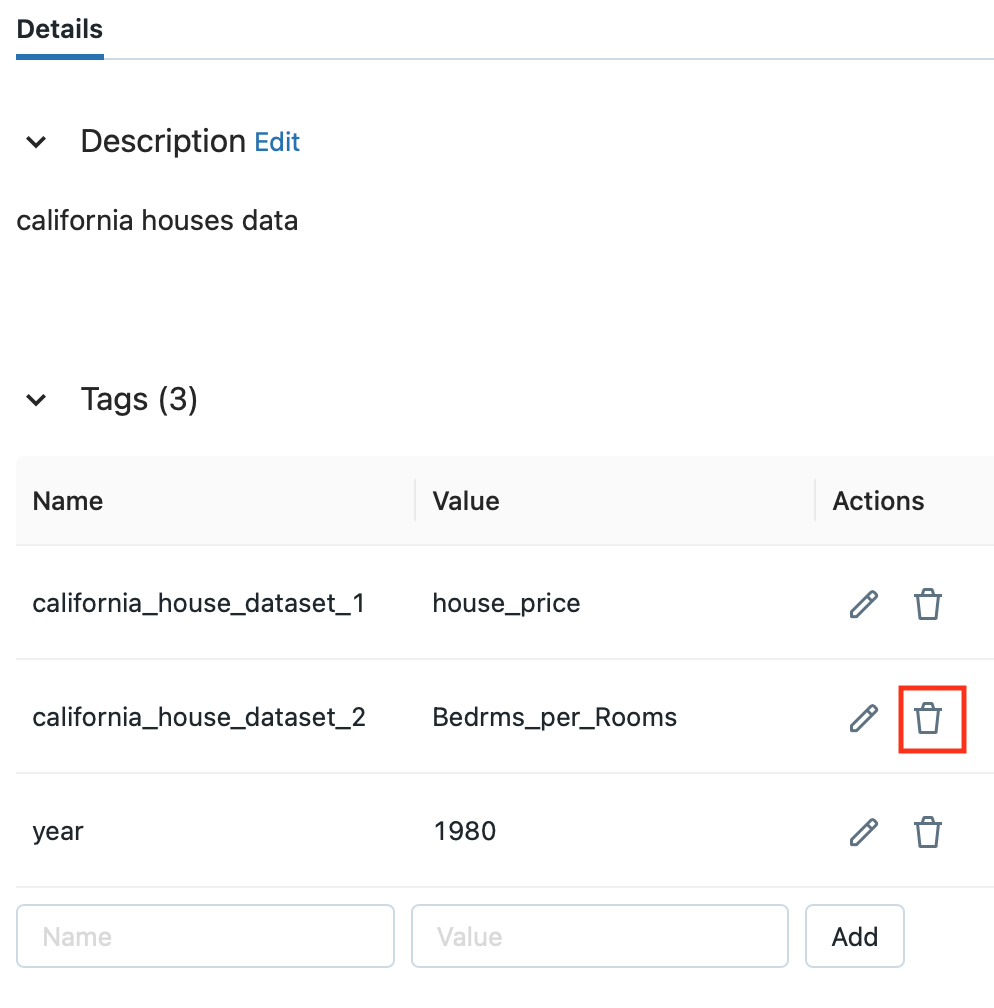
Register an existing Delta table as a Feature Table
I explained the flow of reading a DataFrame, outputting it as a Delta Table, and outputting it to the Feature Store. Looking back on the process so far, the flow is as follows.
- Step 1. Preparation of Spark DataFrame
- Step 2. Create a Delta Table using the created Spark DataFrame
- Step 3. Read Spark DataFrame from Delta Table
- Step 4. Output loaded Spark DataFrame to Feature Store
From here on, I will show you how to register an existing Delta table to the Feature Store without step 3.
Originally, we would like to immediately execute the process of outputting the created Delta Table to the Feature Store, but to distinguish it from the data set of houses in California, prepare another data and start from step 1.
The data uses the sample data of DBFS (Databricks File System). It exists in the path /databricks-datasets.
df = spark.read.format("csv").option("header", True).load("dbfs:/databricks-datasets/online_retail/data-001/data.csv") display(df)

The data here is transaction data for an online store based in the United Kingdom.
Add a sequential ID column to create a primary key.
from pyspark.sql.functions import monotonically_increasing_id #IDを連番で振る df_id = df.withColumn('ID', monotonically_increasing_id() + 1)
Next, specify the timestamp_key to treat the loaded Spark DataFrame as time series data.
Since it is necessary to specify a timestamp or Date type column object for timestamp_key, convert the data type of the InvoiceDate column from string type to timestamp type.
from pyspark.sql.functions import * df = df.withColumn("InvoiceDate", to_timestamp(col("InvoiceDate"), 'M/d/y H:m'))
Specifies the schema in which to create the Delta Table.
%sql
USE SCHEMA default
Create a delta table.
table_name = "online_retail" (df_id.write .format("delta") .saveAsTable(table_name))
Although the preparation has become long, we will output the created Delta Table to the Feature Store.
feature_database = "default" feature_table_name = f"{feature_database}.online_retail" fs.register_table( delta_table = feature_table_name, primary_keys = 'CustomerID', timestamp_keys = 'InvoiceDate', description = 'online_retail of England' )
Check the Feature Table list from the Feature Store in the sidebar.
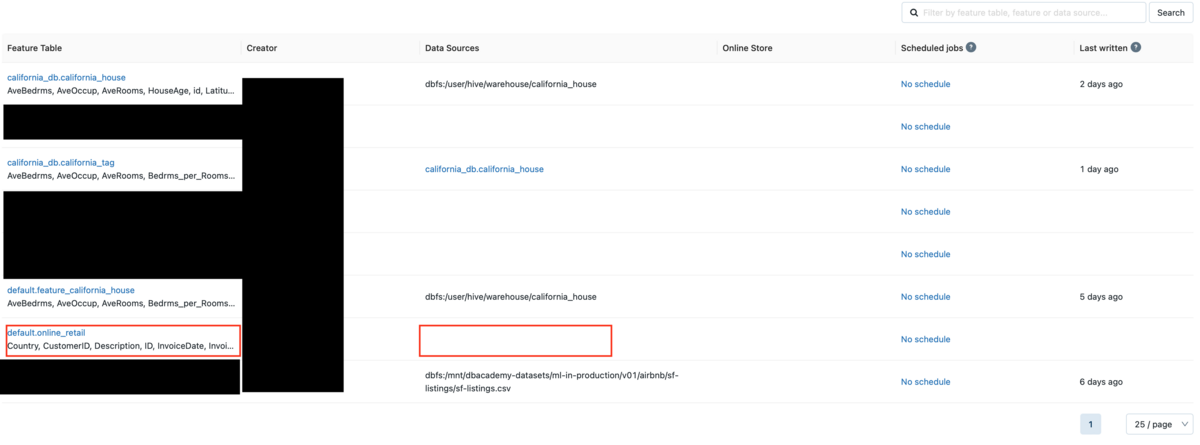
You can see the Feature Table called default.online_retail that you created.
The Data Sources column is blank, but when I run register_table to create a Feature Table from an existing Delta Table, the source Delta Table is not displayed.
Check the metadata of the Feature Table created by register_table.
print(f"Feature table description : {fs.get_table(feature_table_name).description}") print(f"Feature table data source : {fs.get_table(feature_table_name).path_data_sources}")

You can see that the data source is not displayed.
Delete Feature Table
Finally, I would like to close this article by deleting the Feature Table.
Execute DROP TABLE IF EXIST table name.
DROP TABLE IF EXISTS online_retail;
Reference article
- WHAT IS A FEATURE STORE IN MACHINE LEARNING?
- WHAT IS A FEATURE STORE by HOPSWORKS
- What is a Feature Store
- Working with Feature Tables
- Familiarize yourself with the Feature Store
Conclusion
In this article, I explained the issues of feature management, Feature Store that solves those issues, and how to manage features using Databricks Feature Store.
I would like to continue posting the details of verification using Databricks in the future, so please take a look at it again.
We provide a wide range of support, from the introduction of a data analysis platform using Databricks to support for in-house production. If you are interested, please contact us.
We are also looking for people to work with us! We look forward to hearing from anyone who is interested in APC.
Translated by Johann