
はじめに
GLB事業部Lakehouse部の阿部です。
Databricks Lakehouse Platformが提供するデモであるdbdemosには、デモごとにサンプルのデータセットやコードが用意されており、ワークスペースにノートブックをインポートして使用できます。
本記事ではdbdemosを使い、Dollyによるチャットbotの構築手順を解説したいと思います。
LLMを使ったシステム設計やプロンプトエンジニアリングの参考になれば幸いです。
Dollyとその推論については前回の記事で解説しております。
techblog.ap-com.co.jp
以下のデモ内のノートブックを参考にしており、その解説をしております。
Build your Chat Bot with Dolly
目次
- はじめに
- 目次
- ベクトルデータベースを使ったLLMのアーキテクチャについて
- デモの概要
- dbdemosのセットアップ
- Q&Aデータセットとベクトルデータベース作成までの手順
- ガーデニングに関する質問とベストアンサーを用意する
- ドキュメントをベクトル表現に変換するモデル読み込み
- ベクトルデータベースの文書(行)のインデックスを作成する。
- 参考記事
- おわりに
ベクトルデータベースを使ったLLMのアーキテクチャについて
デモに入る前に、文書埋め込みやベクトルデータベースを使った推論処理について解説します。
ここでは、テキストデータをベクトルデータベースに格納するケースを想定します。
LLMシステム構築の前準備
(LangChain ChatのSimilar Workから引用)
まずは、LLMシステム構築の前準備として、ベクトルデータベースにテキストデータを格納するまでの流れについて解説します。
文書などのテキストデータを取り込む
APIによってデータ収集したテキストや、外部のデータベースなどから取得します。文書を小さなチャンクに分割(Split into chunks)
LLMにはAPI使用時のtoken数の制限があるため、長いドキュメントをそのまま入力することはできないことが多いです。
そのため、ドキュメントを適切な長さの意味のまとまりに分割することがtoken数の制限回避に有効です。
ちなみに分割されたものをChunk(チャンク)と言います。
また、チャンクに分割することで推論時におけるベクトルデータベース内の文書検索が効率的に行えます。文書のベクトルを計算(Create Embeddings)
分割したすべてのチャンクをベクトル表現に変換します。
テキストなどをベクトル表現にすることをembedding(埋め込み)といい、ベクトルデータベース(Vectorstore)に格納して推論時のクエリ(プロンプト)との類似度計算に使用します。
(LangChain ChatのSimilar Workから引用)
以上がベクトルデータベースにテキストデータを格納するまでの手順です。
ベクトルデータベースとは、推論時に行うプロンプトとの類似度計算を行うことで回答の精度を高める役割を担います。
ベクトルデータベースを使った推論
次に、入力されたクエリを元に答えを出力する推論について解説します。
クエリをLLMシステムとベクトルデータベースに渡す
ユーザーからのクエリ(図中のQuestion)を受付後、LLMとベクトルデータベースに渡されます。
ベクトルデータベースにはベクトル表現にしたクエリが渡されます。ベクトルデータベース内で類似した文書を探索(Similarity Search)
ベクトルデータベース内の文書とクエリのベクトルとの類似度を計算します。
その結果、クエリに関連する文書を特定できます。文書を元のクエリと共にLLMに渡して回答を生成
LLMシステムにベクトルデータベースから取得した文書と元のクエリが両方渡され、これらの2つの情報をもとに回答を生成します。
ベクトルデータベースからの文書はプロンプトのコンテキストとして含めることで、回答の精度を高めるプロンプトエンジニアリングの方法があり、本デモではこの手法を取り入れております。
以上の手順でLLMシステムを構築できます。
デモの概要
Dollyをベースとしたガーデニングに関するチャットボットを作成します。
ガーデニングショップでの使用を想定しており、アプリケーションにbotを追加して顧客の質問や植物の手入れ方法を勧めるbotのようです。
このデモは2つのセクションに分かれています。
1. データ準備:Q&Aデータセットの取り込みとクリーニングを行い、文書埋め込みしたものをベクトルデータベースに格納します。
2. Q&A推論:Dollyにクエリ(プロンプト)を渡して質問に答えるようにします。
ベクトルデータベースにあるQ&Aのデータを活用してプロンプトにコンテキストを追加します。
(([Build your Chat Bot with Dolly]https://www.dbdemos.ai/demo-notebooks.html?demoName=llm-dolly-chatbot)の01-Dolly-introductionのノートブックから引用)
本記事ではデータ準備のセクションを対象とし、ベクトルデータベースの用意までを解説しております。
Q&A推論のセクションは次回記事で解説予定です。
dbdemosのセットアップ
デモの準備として、ノートブックを新規作成してデモに使用するdbdemosをインストールします。
%pip install dbdemos
インストール完了後、dbdemosをインポートしてChatbotの訓練に使用するデータを提供するllm-dolly-chatbotをインストールします。
import dbdemos dbdemos.install('llm-dolly-chatbot')
実行結果です。
dbdemosのセットアップが完了しました。
デモ用のクラスターとフォルダーが作成されています。
作成されたクラスターを確認します。

作成されたフォルダーを確認します。

これから使用するノートブックにはデモ用のクラスターをアタッチしてデモを進めます。
Q&Aデータセットとベクトルデータベース作成までの手順
本記事では、学習に使用するデータの準備とベクトルデータベースの作成までを行いますが、データ準備のフローをもう一度確認します。
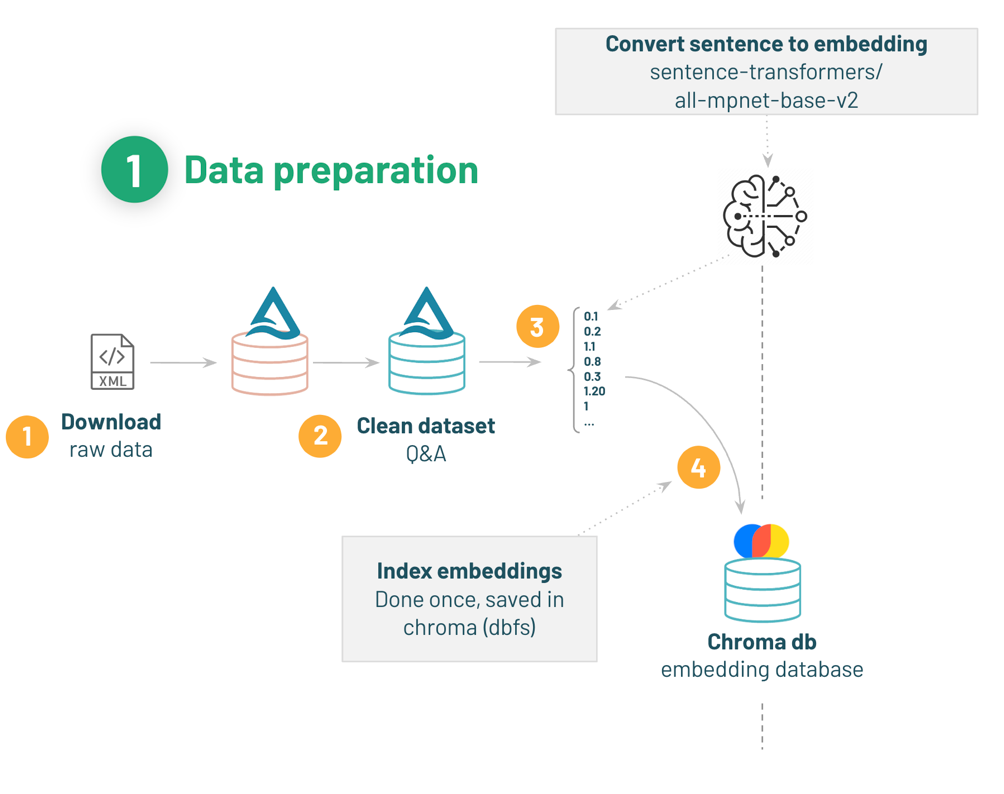
(Build your Chat Bot with Dollyの02-Data-preparationのノートブックから引用)
- Q&Aデータセットをダウンロードする。
- ガーデニングの質問と対応するベストアンサーを用意する。
- Hugging Faceからモデルを読み込み、文書をベクトルに変換する。
- ベクトルデータベース(Chroma)のベクトルをインデックス化する。
まずは必要なライブラリをインストールします。
%pip install -U chromadb langchain transformers
インストールしたライブラリについて簡単に解説します。
chromadb: OSSのベクトルデータベースです。 本記事ではこちらに文書埋め込みしたQ&Aデータセットを格納します。langchain: さまざまな言語処理タスクにおいて、多言語間のテキストを変換するためのPythonライブラリです。transformers: 自然言語処理タスクを行うためのPythonパッケージで、事前学習済みのLLMを提供します。
次に、同じディレクトリに_resourcesフォルダーにある00-initというノートブックを%runコマンドで実行します。
%run ./_resources/00-init $catalog=hive_metastore $db=dbdemos_llm
00-initを見るとわかりますが、下記のようにウィジェットの値を取得していため、%run実行時に変数catalogとdbに値を代入しています。
dbutils.widgets.text("catalog", "hive_metastore", "Catalog") dbutils.widgets.text("db", "dbdemos_llm", "Database") catalog = dbutils.widgets.get("catalog") db = dbutils.widgets.get("db") db_name = db
dbutils.widgets.text()メソッドを使って2つのウィジェットcatalogとdbを作成しています。
それぞれのウィジェットには初期値と説明が設定されており、それぞれhive_metastoreと dbdemos_llmという名前に対してCatalogとDatabaseという説明が設定されています。
dbutils.widgets.get("catalog")は、ウィジェットと呼ばれる機能を使用し、指定された名前のウィジェットの値を取得します。
今回はガーデニングの質問に焦点を当て、ガーデニングのデータセットをダウンロードします。
ここではbashコマンドを使用してgardeningデータセットのアーカイブをダウンロードして解凍し、作成したdbfsのディレクトリにデータセットのPosts.xmlファイルをコピーしています。
%sh #To keep it simple, we'll download and extract the dataset using standard bash commands #Install 7zip to extract the file apt-get install -y p7zip-full rm -r /tmp/gardening mkdir -p /tmp/gardening cd /tmp/gardening #Download & extract the gardening archive curl -L https://archive.org/download/stackexchange/gardening.stackexchange.com.7z -o gardening.7z 7z x gardening.7z #Move the dataset to our main bucket mkdir -p /dbfs/dbdemos/product/llm/gardening/raw cp -f Posts.xml /dbfs/dbdemos/product/llm/gardening/raw
実際のシナリオでは、外部のシステムからデータを取得すると説明されています。
Q&Aのデータセットが準備できました。 データセットの情報を確認します。
%fs ls /dbdemos/product/llm/gardening/raw

データセットのサイズを確認できました。
ガーデニングに関する質問とベストアンサーを用意する
spark xmlを使ってデータをインジェストしてみましょう。
ガーデニングの質問とベストな答えのクリーニングおよび準備は、以下の手順で実行します。
- ベストアンサーとして妥当なスコアを持つ質問と回答のみを残す。
- HTMLをプレーンテキストにパースする。
- 質問と答えをつなぎ合わせて、質問と答えのペアを形成する。
Q&Aデータセットを確認する
指定のディレクトリに置かれているPosts.xmlファイルを読み込み、Questionのデータを確認します。
gardening_raw_path = demo_path+"/gardening/raw" print(f"loading raw xml dataset under {gardening_raw_path}") raw_gardening = spark.read.format("xml").option("rowTag", "row").load(f"{gardening_raw_path}/Posts.xml") display(raw_gardening)
option("rowTag", "row")は、XMLファイルの中で行を表す要素のタグ名が "row"であることを指定しています。
データセットを表示します。

回答のID、回答数、質問文などが確認できます。
次に、質問に対する回答文を確認します。
以下のコードでは、HTML形式の文字列をテキストに変換するPandas UDF(User-Defined Function)を定義しており、BeautifulSoupでHTMLを解析してテキストを抽出しています。
from bs4 import BeautifulSoup #UDF to transform html content as text @pandas_udf("string") def html_to_text(html): return html.apply(lambda x: BeautifulSoup(x).get_text()) gardening_df =(raw_gardening .filter("_Score >= 5") # keep only good answer/question .filter(length("_Body") <= 1000) #remove too long questions .withColumn("body", html_to_text("_Body")) #Convert html to text .withColumnsRenamed({"_Id": "id", "_ParentId": "parent_id"}) .select("id", "body", "parent_id")) # Save 'raw' content for later loading of questions gardening_df.write.mode("overwrite").saveAsTable(f"gardening_dataset") display(spark.table("gardening_dataset"))
データの前処理として、以下のことを実施しています。
filter関数を使用してraw_gardeningDataFrameから"Score"列の値が5以上の行と、"Body"列の文字数が1000文字以下の行をフィルタリングします。withColumn関数では、"_Body"列に含まれるHTMLをテキスト形式に変換するUDFであるhtml_to_textによって新たに"body"列を作成します。withColumnsRrenamedでは、"_Id"列を"id"列に、"ParentId"列を"parent_id"列にカラム名を変更し、必要な列を選択して新しいデータフレームgardening_dfを作成します。
最後に、gardening_dfをHiveテーブルgardening_datasetとして上書き保存し、テーブルを表示します。

質問のIDと回答文のテーブルを用意できました。
質問と回答を対応させる
先ほど保存したデータセットgardening_datasetを読み込み、質問と回答のデータセットを作成します。
gardening_df = spark.table("gardening_dataset") # 質問と回答を対応させるためにセルフジョインする qa_df = gardening_df.alias("a").filter("parent_id IS NULL") \ .join(gardening_df.alias("b"), on=[col("a.id") == col("b.parent_id")]) \ .select("b.id", "a.body", "b.body") \ .toDF("answer_id", "question", "answer")
読み込んだデータフレームをセルフジョインして回答と質問をペアにしています。
具体的には、parent_idがないデータフレーム(質問)のみをフィルタリングしてエイリアス名をaとし、元々のgardening_dfのエイリアス名をbとした後に、お互いのデータフレームを質問と回答のIDが一致するレコードのみを結合しています。
その後にb.id(回答のID)、a.body(質問文)、b.body(回答文)の3つのカラムを選択し、最終的にtoDF()メソッドを使用してこれらカラムを新しい名前「answer_id」、「question」、「answer」に変更して新しいデータフレームqa_dfを作成しています。
# トレーニングデータセットを用意する:ベストアンサーで以下の問題を出題する。
docs_df = qa_df.select(col("answer_id"), F.concat(col("question"), F.lit("\n\n"), col("answer"))).toDF("source", "text")
display(docs_df)
そして、データフレームqa_dfに対してquestion列とanswer列を連結して、source列とtext列を持つ新しいデータフレームdocs_dfを作成しています。
docs_dfを表示します。

answer_idをsourceカラムとし、textカラムには質問文と回答文を同じ文章に含めることでQAの文章を作成しました。
推論を高速化するためのテキスト要約
データセットは1つの質問とベストアンサーで構成されていますが、かなり長いテキストになる可能性があります。
長いテキストをコンテキストとして使用すると、LLMの推論が遅くなる可能性があります。
その問題を回避する1つの選択肢として、サマライザーLLMを使ってこれらのQ&Aを要約し、その結果を既存のQ&Aの文章と置き換えます。
要約を作成する操作は非常に時間がかかり、デモ用に用意されたクラスターでは1時間かけても終わらなかったため今回はテキストを要約せずに進めます。
from typing import Iterator import pandas as pd from transformers import pipeline @pandas_udf("string") def summarize(iterator: Iterator[pd.Series]) -> Iterator[pd.Series]: # Load the model for summarization summarizer = pipeline("summarization", model="sshleifer/distilbart-cnn-12-6") def summarize_txt(text): if len(text) > 400: return summarizer(text) return text for serie in iterator: # get a summary for each row yield serie.apply(summarize_txt) # データセット全体で時間がかかる可能性があるため、実行はしない # docs_df = docs_df.withColumn("text_short", summarize("text")) docs_df.write.mode("overwrite").saveAsTable(f"gardening_training_dataset") display(docs_df)
pipelineクラスを使用して文章要約のタスクを処理するモデルdistilbart-cnn-12-6を読み込み、テキストの長さが400文字よりも大きい場合には文章要約を行い、400文字以下の場合は元の文章を返すsummarize_txt()関数を定義しています。
そして、イテレーター内の各行に対してsummarize_txt()関数を適用し、作成した要約を含む新しい列を持つPandas DataFrameを返します。
今回はテキスト要約をしておりませんが、このような方法もあるのだと理解することにします。
ドキュメントをベクトル表現に変換するモデル読み込み
文章をベクトル表現に変換するHuggingFaceEmbeddingsクラスを使用し、多言語の文書を学習した事前学習済みモデルsentence-transformers/all-mpnet-base-v2をダウンロードします。
from langchain.embeddings import HuggingFaceEmbeddings # Download model from Hugging face hf_embed = HuggingFaceEmbeddings(model_name="sentence-transformers/all-mpnet-base-v2")
ダウンロードしたこちらのモデルを使って文書埋め込みをします。
ベクトルデータベースの文書(行)のインデックスを作成する。
さて、いよいよ生成されたテキストを読み込み、ラングチェーンパイプラインで使用するための検索可能なテキストデータベースを作成する段階です。
これらのドキュメントは埋め込みされているため、後のクエリのベクトルと関連するテキストチャンクにマッチさせることができます。
ベクトルデータベースの作成手順です。
1. Sparkでテキストチャンクを収集します。
2. インメモリChromaベクトルDBを作成する。
3. sentence-transformersから埋め込み関数をインスタンス化する。
4. データベースにデータを入力して永続化する。
埋め込み制御用のDatabricksウィジェットの準備
まずはデータベースを格納するディレクトリを用意し、dbfs上の任意のパスとします。
このコードは、Databricksのウィジェットを使用して、テキストデータの埋め込みを再計算するかどうかを制御しています。
dbutils.widgets.dropdown("reset_vector_database", "false", ["false", "true"], "Recompute embeddings for chromadb") gardening_vector_db_path = demo_path+"/vector_db" # Don't recompute the embeddings if the're already available compute_embeddings = dbutils.widgets.get("reset_vector_database") == "true" or is_folder_empty(gardening_vector_db_path) if compute_embeddings: print(f"creating folder {gardening_vector_db_path} under our blob storage (dbfs)") dbutils.fs.rm(gardening_vector_db_path, True) dbutils.fs.mkdirs(gardening_vector_db_path)
最初に、dbutils.widgets.dropdownメソッドを使用して、"reset_vector_database"という名前のドロップダウンウィジェットを作成しています。
このウィジェットを使用することで、ユーザーがテキストデータの埋め込みを再計算するかどうかを選択できます。
次に、compute_embeddingsという名前の変数を定義し、"reset_vector_database"ウィジェットがtrueであるか、またはgardening_vector_db_pathにファイルが存在しない場合にTrueに設定されます。
Trueの場合にテキストデータの埋め込みを再計算する必要があることを示します。
最後に、compute_embeddings変数がTrueである場合、gardening_vector_db_pathで指定されたパスにあるフォルダーを削除し、新しいフォルダーを作成します。
これにより、テキストデータの埋め込みを再計算するための準備が整います。
ドキュメントデータベースを作成
Q&Aデータセットをベクトルデータベースに格納することで、ドキュメントデータベースを作成します。
ドキュメントデータベース作成の手順:
1. テキストデータセットを読み込み、ドキュメントを作成する。
2. 長い文章を扱いやすい小さいチャンクに分割する。
今回は元々のQ&Aの文章がそれほど長くないため、Chunk分割をしておりません。
また、テキスト要約を実行して文章量がさらに少ないならChunk分割をしなくてもいいと説明しています。
しかし、Chunk分割の有無によってLLMが返す回答もおそらく変わるため、この辺りはまだまだ検証が必要そうです。
以下のコードは、Chromaを使用して文書埋め込みを計算し、データベースに格納するためのコードです。
from langchain.docstore.document import Document from langchain.vectorstores import Chroma # Chunk分割をする場合はインポートする。 # from langchain.text_splitter import CharacterTextSplitter all_texts = spark.table("gardening_training_dataset") print(f"Saving document embeddings under /dbfs{gardening_vector_db_path}") if compute_embeddings: # 行をlangchain Documentsとして変換します。 # より短い期間のインデックスを作成したい場合は、代わりにtext_shortフィールドを使用します。 documents = [Document(page_content=r["text"], metadata={"source": r["source"]}) for r in all_texts.collect()] # 文章が長い場合、分割する必要があるかもしれません。しかし、上記のように要約するのが一番です。 # text_splitter = CharacterTextSplitter(separator="\n", chunk_size=1000, chunk_overlap=100) # documents = text_splitter.split_documents(documents) # hugging face (hf_embed)から読み込んだsentence-transformers/all-mpnet-base-v2モデルでchromadbを初期化する。 db = Chroma.from_documents(collection_name="gardening_docs", documents=documents, embedding=hf_embed, persist_directory="/dbfs"+gardening_vector_db_path) db.similarity_search("dummy") # tickle it to persist metadata (?) db.persist()
コードの解説です。
if compute_embeddingsがTrue(埋め込みの必要がある場合)の場合は、各行の文書に対してDocumentクラスを用いてテキストデータとそのメタデータを受け取って埋め込みを計算します。
page_contentは文書の本文を表す属性の1つであり、各行のtextカラムの値を渡しています。
metadataは文書のメタデータを格納するための属性であり、sourceカラムを辞書として渡しています。
そして、Chroma.from_documents()メソッドを使用してデータベースの初期化を行います。
Chroma.from_documents()メソッドの引数についてです。
- collection_name : 作成されるコレクションの名前
- documents : ドキュメントのリスト
- embedding : ドキュメントを埋め込むために使用
- persist_directory : ベクトルストアを永続化するためのディレクトリのパス
similarity_search()メソッドは、Chromaデータベース内のベクトルと、与えられたクエリー(検索対象の文書)のベクトルとの類似度を計算し、類似度の高いテキストを返します。
今回はダミーのクエリ(プロンプト)を実行し、ベクトルデータベース内に格納する文書のベクトルを計算してメタデータをキャッシュします。
最後に、persist()メソッドを使用して、永続的なベクトルストアを作成します。
このメソッドによって現在のベクトルストアの状態がインメモリからディスク(ファイル)に保存され、 プログラムの再起動後もベクトルストアの状態を維持してデータの永続性を確保します。
ここまでお疲れ様でした。
以上でQ&Aデータセットの準備は完了です!
参考記事
おわりに
本記事では、Dollyによるチャットbot構築のためにベクトルデータベースに格納するQ&Aデータセットの準備をしました。
次回以降の記事では、作成したベクトルデータベースを用いてプロンプトエンジニアリングを行いながら、Dollyによる推論処理を行いチャットbotの挙動を確認したいと思います。
最後までご覧いただきありがとうございます。
私たちはDatabricksを用いたデータ分析基盤の導入から内製化支援まで幅広く支援をしております。
もしご興味がある方は、お問い合わせ頂ければ幸いです。
そして、一緒に働いていただける仲間も募集中です!
APCにご興味がある方の連絡をお待ちしております。