
はじめに
GLB事業部Lakehouse部の阿部です。
chat-gptの台頭により大規模言語モデル(LLM)についてよく聞くようになりましたが、Databricksは2023年4月12日にOpenなLLMであるDolly 2.0を発表しました。
今後はDatabricks Lakehouse PlatformにDollyが導入され、Dollyを用いた開発・運用が考えられます。
本記事ではDollyについて解説し、最後にDollyを動かすことでchat-gptのような指示追従型のLLMを体感したいと思います。
目次
大規模言語モデルとは?
Dollyについて解説する前に、大規模言語モデルについて簡単に解説します。
大規模言語モデルLLM(Large Language Model)は大規模なテキストデータを学習した結果、ニューラルネットワークのパラメーター数が億単位やそれ以上になった自然言語処理のモデルです。
さまざまな自然言語処理のタスク(文章生成、感情分析、要約など)の処理が高精度に可能ですが、その性能を支えているのは膨大なパラメーター数によるものです。
フリープランのChatGPTに使われているモデルであるGPT-3.5の場合、学習データが45TB以上、パラメーター数が3550億と言われています。
学習にはお金や時間を含めて多大なコストがかかりますが、パラメーター数は精度に直結するため現実にはパラメーター数を増やすほど精度は増え、GPTもシリーズごとに増えています。
(https://research.aimultiple.com/gpt/のOpenAI GPT-n models: Shortcomings & Advantages in 2023から一部引用)
グラフを見ると、最初のGPTモデルはパラメーター数が110 Millions(=1億1千万)であるのに対して、GPT-3は1750 Millions(1750億)であることがわかります。
このようなモデルを学習・運用することは高性能なスパコンでもない限り厳しいですが、近年ではDollyのように少ないパラメーター数である程度の精度を出すLLMも登場しています。
Dollyとは
DollyはDatabricksが提供する対話能力を持つ生成AIモデルであり、先月には世界初のオープンソースとなるDolly 2.0を発表しました。
EleutherAIのpythia-12bをベースに構築されており、The PileというEleuther AIがLLM構築のために特別に作成したデータセットを用いて学習しています。
このデータセットは22の多様なソースからのテキストデータが含まれており、大きく分けて学術論文(例:arXiv)、インターネット(例:CommonCrawl)、散文(例:Project Gutenberg)、対話(例:YouTube字幕)、雑学(例:GitHub、Enron Eメール)の5つのカテゴリーから構成されております。
詳しくは、The Pileの論文を参照ください。
そして、pythia-12bをベースに[Databricks-dolly--15k](https://huggingface.co/datasets/databricks/databricks-dolly-15k)を用いてファインチューニングしたモデルがDolly 2.0となります。
Databricks-dolly--15kは、Databricks従業員が作成したQA形式(プロンプトとレスポンス)から構成される15,000個のデータからなり、オープンソースであるためGitHubやHugging Faceに公開されております。
また、翻訳ソフトを用いて日本語に翻訳し公開されている方もいます。
LLMを民主化したDolly
Dollyの特筆すべき点は、下記の課題を解決してLLMを民主化したことです。
低コストな計算リソース
Dollyは低コストで学習が可能な小さいモデルサイズであることが特長の1つです。
GPTファミリーのモデルであるGPT-3.5の場合、パラメーター数が3550億であるのに対してDollyのパラメーター数は120億と10分の1以下であることからモデルサイズが小さく、ある程度のメモリとGPUが積まれたPC1台で学習が済みます。
そのため、少ない計算リソースで誰でも学習を実行できます。OpenなLLMであること
商用利用にライセンスされており、ファインチューニングに使用したデータセットを含めて誰でも利用可能です。
そのため、商用目的でモデルをカスタマイズして所有できます。
また、お客様のある業界での特定の業務に使用するなど、ドメイン特化のモデル構築も考えられます。
Dollyによる推論処理
最後に、Dollyを動かして応答を見ます。
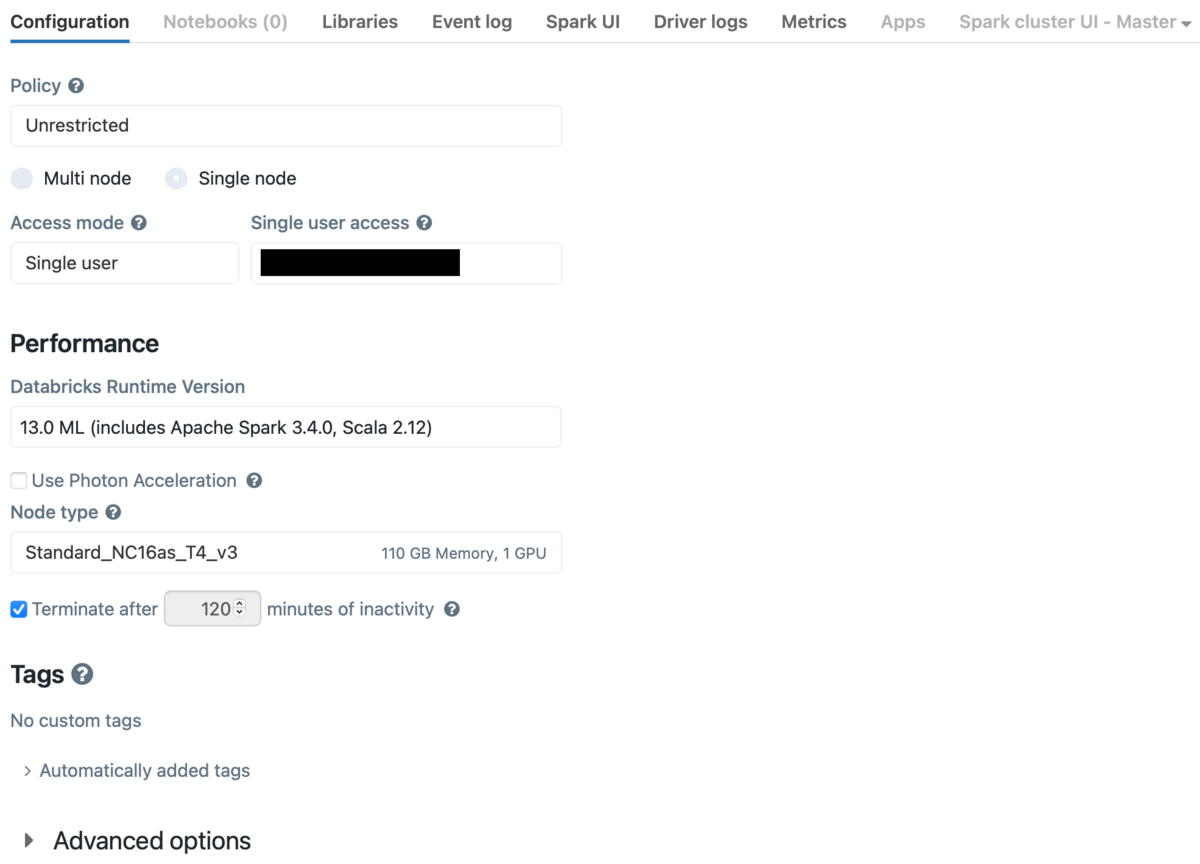
まずはクラスターを準備します。
今回はシングルノードで以下のクラスターを使用しました。
- Databricks Runtime Version: 13.0 ML
- Node type: Standard_NC16as_T4_v3
- CPUの数: 16
- GPUの数: 1
- メモリ: 110.00 GiB
まずはパッケージのインストールをします。
%pip install accelerate>=0.12.0 transformers[torch]==4.25.1
accelerateはHugging Face社が開発した、深層学習ライブラリであるPyTorchを高速化するためのライブラリです。
transformersは自然言語処理のタスクで使用され、Hugging Face社が提供する事前学習済みモデルを含むPyTorchを使用したライブラリです。
次のコードはTransformersライブラリを使用して、事前学習済みのテキスト生成モデルDolly 2.0を呼び出しています。
モデルを呼び出して推論を実行するにはpipelineクラスが便利です。
import torch from transformers import pipeline # パイプラインの準備 generate_text = pipeline( model="databricks/dolly-v2-12b", torch_dtype=torch.bfloat16, trust_remote_code=True, device_map="auto" )
モデルの読み込みには5分程度かかりました。
以下は、各パラメーターの説明です。
model: Hugging Faceから呼び出すモデルの名前
パラメーター数が異なるごとにモデル名も変わります。
例)モデル名ごとのパラメーター数
・ dolly-v2-12b": 120億
・ dolly-v2-7b": 70億
・ dolly-v2-3b": 30億
torch_dtype: Pytorchのテンソルのデータ型trust_remote_code:Trueを指定することでリモートコードを信頼device_map: モデル実行に使用するデバイス
device_map = cpuに設定されていますが、cudaを指定することでGPUを使用できます。
autoを指定することで、利用可能なGPUを自動的に検出して適切なデバイスにモデルを配置します。
Dollyによる推論
それでは、Dollyに入力するプロンプトを指定して推論の結果を見ます。
プロンプトエンジニアリングでは、命令と入力データを分けることや文脈(コンテキスト)や入れること、他にもZero-shot、Few-shotプロンプティングなど、プロンプトを入力する前に推論の精度を高める方法があります。
本来は色々と試行錯誤すべきですが、ここではとくに手を加えずに推論を実行します。
# 入力するプロンプト prompt = "What is the highest mountain in Japan?" # 推論処理 res = generate_text(prompt) print(res[0]["generated_text"])
実行結果です。
The highest mountain in Japan is Mount Everest standing tall at 29032 feet
日本の山について聞いたはずが、世界でもっとも高い山であるエベレストを回答しています。
日本に関することはあまり学習されていないと思い、プロンプトを以下のように変更して世界でもっとも高い山について聞いてみました。
prompt = "What is the highest mountain in the world?"
実行結果です。
The highest mountain in the world is Mount Everest standing tall at 29032 feet
エベレストだと回答し、さらに標高も答えてくれました。
次に、パラメーター数の違いによる回答結果を比較します。
Dollyにはパラメーター数ごとに3つのモデルがあるため、それらの推論結果を比較します。
- 7bの場合
The tallest mountain in the world is Mount Everest standing tall at 29032 feet. This is due to it being a tallest peak on all seven continents.
エベレストだと回答し、世界で一番高いのはすべての大陸でもっとも高いからですよ、と教えてくれます。
- 3bの場合
It depends what you mean by the "highest mountain in the world". Geographical terms such as highest, tallest or highest point are not independent criteria for making judgements of which mountains are the highest. The highest mountains can have multiple tops and are often shared between multiple countries. To determine the highest mountains, you could compare their heights against those of other mountains. You could also compare the volume of ice that these mountains contain to find the most massive. This is dependent on a number of factors including the elevation of the base of the mountain.
色々答えていますが、「世界でもっとも高い山は標高などで決まるのではなく複数の頂を持ち多くの国にまたがる山です」と答えており、
他の山と比較しなければならないとも答えています。
推論結果から期待する回答はしていないことがわかります。
パラメーター数ごとのモデルの回答結果から、7bのパラメーター数のモデルが(人間の感覚で)期待する答えを返したと思います。
期待する答えは明示しておらず評価指標も定義していないですが、直球で返して余計な情報を入れておりません。
今回は比較的簡単な質問でしたが、パラメーター数によって回答の精度が変わることを確認できました。
ちなみに、Hugging FaceのDollyのページに自然言語処理タスクごとの精度が記載されています。
こちらの表では数値が高いほど精度が高いことを示しており、Dollyだけで比較するとパラメーター数が多いほど精度が高いことがわかります。
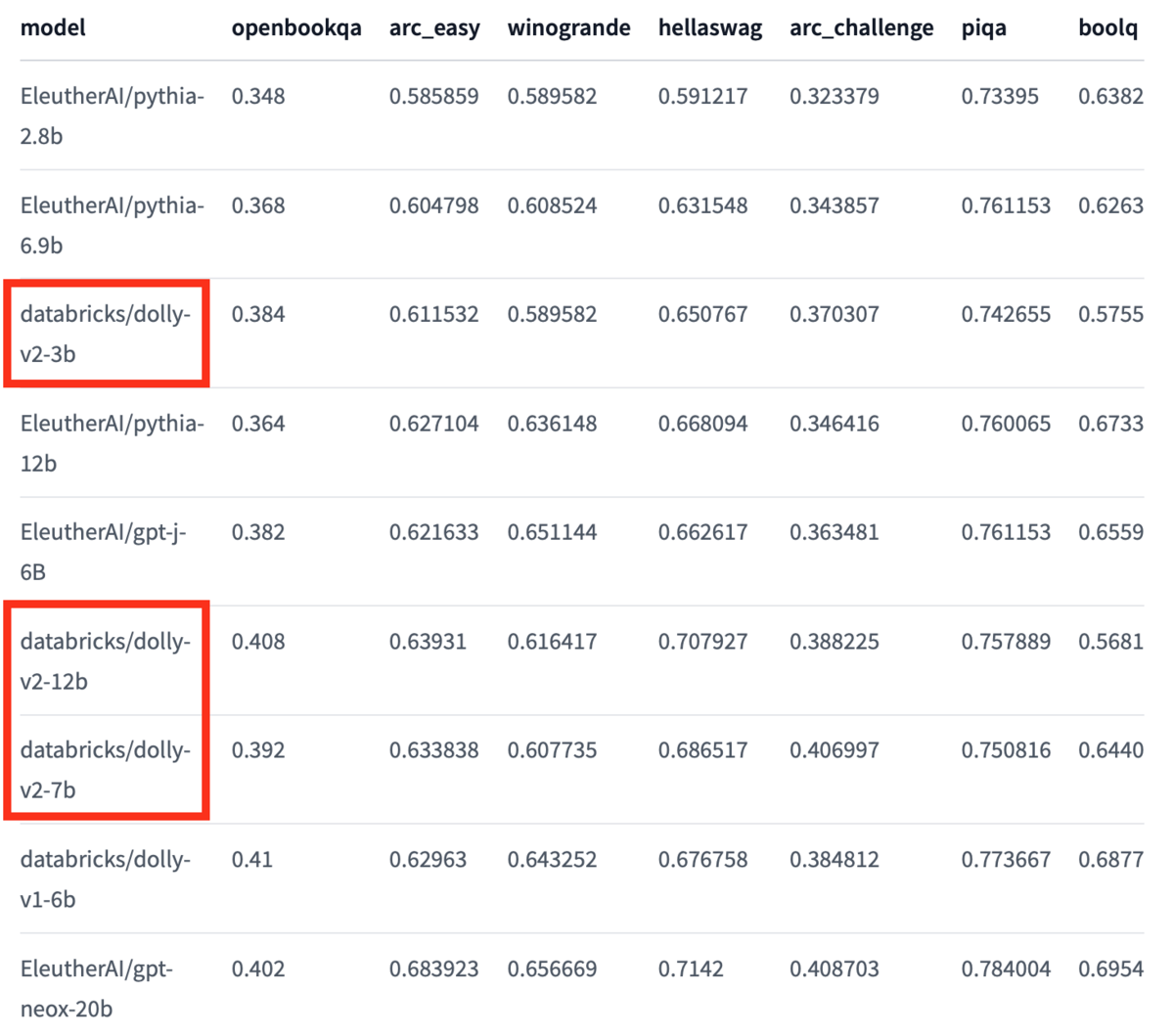
(https://huggingface.co/databricks/dolly-v2-12bのBenchmark Metricsから一部引用)
今後期待されること
Databricks Lakehouse PlatformにDollyを導入することで、さまざまなコンポーネントと掛け合わせて開発のスピードが加速することが考えられます。
あくまで予想ですが、Chat形式で質問して〇〇のケースの場合は〜のコンポーネントを使えばいいとか、そういった使い方が考えられます。
また、OpenなLLMであることからお客様のドメインに特化したLLMを構築し、特定のタスク処理に使用されることも考えられます。
おわりに
本記事では、オープンソースのLLMであるDollyについて解説し、最後にDollyを動かしてパラメーター数ごとの回答を確認しました。
今後DollyによってDatabricks Lakehouse Platformはさらに進化すると思いますが、Dollyの扱い方に加えてファインチューニングやプロンプトエンジニアリングの知識は必要になりそうです。
今後もDollyについては引き続きキャッチアップして発信できたらと思います。
最後までご覧いただきありがとうございます。
私たちはDatabricksを用いたデータ分析基盤の導入から内製化支援まで幅広く支援をしております。
もしご興味がある方は、お問い合わせ頂ければ幸いです。
そして、一緒に働いていただける仲間も募集中です!
APCにご興味がある方の連絡をお待ちしております。