

目次
はじめに
こんにちは、クラウド事業部の早房です。
今回は Amazon Comprehend の Custom classification (カスタム分類) を使って日本語テキストから喜怒哀楽の感情分析を行う構成を作ってみました。
ネガポジ分析はデフォルトで搭載されている機能で実施できますが、もう一歩踏み込んでカスタム分類モデルを作成し喜怒哀楽の分析を試してみました。
なお既に日本語テキストを感情分析できるものは存在していますが、今回はComprehend縛りという事で・・・
jupyterbook.hnishi.com
どうぞ最後までご覧ください🧐
どんなひとに読んで欲しい
- Amazon Comprehendって何ぞや。な人
- 機械学習っぽいことに興味がある人
- 自然言語処理(NLP)サービスに興味がある人
Amazon Comprehend とは

AWS Comprehendは、Amazon Web Services(AWS)が提供する自然言語処理(NLP)サービスです。
テキストデータを分析し、以下のような情報を抽出することができます。
主な機能
エンティティ認識
テキストから人名、組織名、場所、日付などのエンティティを自動的に抽出します。
感情分析
テキストの感情を分析し、ポジティブ、ネガティブ、ニュートラル、ミックスの4つのカテゴリに分類します。
キー・フレーズ抽出
テキスト内の重要なフレーズや概念を特定し、抽出します。
言語検出
テキストが書かれている言語を自動的に識別します。
トピックモデリング
大量のテキストデータを分析し、主要なトピックを抽出します。
カスタム分類
今回試したのはこちらです。
ユーザーが定義したカテゴリに基づいてテキストを分類することができます。
私も「テキストから単語とか感情とか色々読み取れるサービスなんだなー」ぐらいのざっくりとしたイメージです。
公式ドキュメントは以下。
docs.aws.amazon.com
料金
以下公式ドキュメントより引用。
自然言語処理: Amazon Comprehend API を使用して、エンティティ認識、感情分析、構文解析、キーフレーズ抽出、および言語検出により、自然言語からインサイトを抽出することができます。これらのリクエストは 100 文字を 1 ユニット (1 ユニット = 100 文字) として計算され、各リクエストにつき 3 ユニット (300 文字) の最低料金が発生します。
個人識別情報 (PII): Detect PII API は、ドキュメント内の個人識別情報 (“PII”) エンティティの位置を特定します。この API はドキュメントの編集済バージョンを生成するために使用できます。Contains PII API はドキュメント内に PII が含まれているかどうかを判定します。これらのリクエストも、100 文字を 1 ユニット (1 ユニット = 100 文字) として計算され、各リクエストにつき 3 ユニット (300 文字) の最低料金が発生します。
カスタム Comprehend: カスタム分類とエンティティ API により、カスタム NLP モデルをトレーニングして、テキストの分類と、カスタムエンティティの抽出が行えます。非同期推論リクエストは 100 文字を 1 ユニットとして計算され、各リクエストにつき 3 ユニット (300 文字) が最低料金となります。モデルトレーニング (秒単位で請求) については 1 時間に 3 USD、カスタムモデル管理には 1 か月に 0.50 USD が課金されます。同期カスタム分類およびエンティティ推論リクエストの場合、エンドポイントに適切なスループットをプロビジョニングします。エンドポイントを起動してから削除されるまで課金されます。
トピックモデリング: トピックモデリングでは、Amazon S3 に保存されたドキュメントのコレクションから、関連表現やトピックが特定されます。コレクション内の最も一般的なトピックを識別し、それらをグループに整理し、次にどのドキュメントがどのトピックに属しているかをマップします。課金はジョブで処理されるドキュメントの合計サイズに基づきます。最初の 100 MB は均一料金です。100 MB を超えると 1 MB ごとに課金されます。
信頼と安全 (新規): Comprehend の毒性検出 API を使用して、テキストから有毒なコンテンツを検出できます。同様に、Comprehend のプロンプト安全性分類機能を使用して、大規模な言語モデルやアプリケーションへの安全でない入力プロンプトを検出できます。これらのリクエストは 100 文字を 1 ユニット (1 ユニット = 100 文字) として計算され、各リクエストにつき 3 ユニット (300 文字) の最低料金が発生します。
課金の要素は沢山ありそうです。
ざっくりと「分析するテキストの文字数・PIIの文字数・モデルおよびエンドポイントの使用時間」といったところでしょうか。
特にエンドポイントは分単位で課金されるようなので注意。
なお、カスタム分類は無料枠がないようです。
docs.aws.amazon.com
こんな構成でやってみた

API Gateway でPOSTリクエストを受け取る。
受け取ったテキストデータを Lambda 関数で処理。
・オリジナルのテキストを DynamoDB に格納
・オリジナルのテキスト (日本語) を Amazon Translate で英語に翻訳
・英語に翻訳されたテキストを DynamoDB に格納
・英語に翻訳されたテキストを Amazon Comprehend の エンドポイントに投げて感情分析
・分析結果を DynamoDB に格納
今回 Translate を噛ませている理由は、現状 Custom classification (カスタム分類) が日本語をサポートしていないためです。
各リソース作成
Lambda 関数
import json
import boto3
import uuid
# AWSクライアントの設定
translate = boto3.client('translate')
comprehend = boto3.client('comprehend')
dynamodb = boto3.client('dynamodb')
def lambda_handler(event, context):
# イベントの内容をログに出力
print("Received event: " + json.dumps(event))
# イベントオブジェクトの形式を確認
body = event.get('body')
if body:
body = json.loads(body)
text_to_translate = body.get('text')
else:
text_to_translate = event.get('text')
if not text_to_translate:
return {
'statusCode': 400,
'body': json.dumps({'error': 'No text provided'})
}
# Amazon Translate APIを使用して翻訳
translate_response = translate.translate_text(
Text=text_to_translate,
SourceLanguageCode='ja',
TargetLanguageCode='en'
)
translated_text = translate_response['TranslatedText']
# Amazon Comprehendのカスタム分類モデルを使用して分類
comprehend_response = comprehend.classify_document(
Text=translated_text,
EndpointArn='<ComprehendエンドポイントのARN>'
)
classification_result = comprehend_response['Classes']
# 最高スコアのラベルを取得
highest_score_class = max(classification_result, key=lambda x: x['Score'])
highest_label = highest_score_class['Name']
highest_score = highest_score_class['Score']
# DynamoDBにデータを格納
request_id = str(uuid.uuid4())
dynamodb.put_item(
TableName='<DynamoDBのリソース名>',
Item={
'RequestId': {'S': request_id},
'OriginalText': {'S': text_to_translate},
'TranslatedText': {'S': translated_text},
'ClassificationResult': {'S': json.dumps(classification_result)},
'HighestLabel': {'S': highest_label},
'HighestScore': {'N': str(highest_score)}
}
)
# ユーザーに返却するレスポンス
return {
'statusCode': 200,
'body': json.dumps({'message': 'Text processed successfully', 'label': highest_label})
}
API Gateway
REST API 用の API Gateway を作成。
メソッドはPOSTで、Lambda 統合を設定しました。
特別な設定はしていないです。

「demo」というステージにデプロイしました。

DynamoDB
こちらも至ってシンプルなテーブルを作成。
パーティションキーは RequestID

Comprehend - カスタム分類モデル
今回の本命です。
Comprehend のコンソール画面から「Custom classification」を選択して「Create new model」をクリック。

モデル名と言語を選びます。
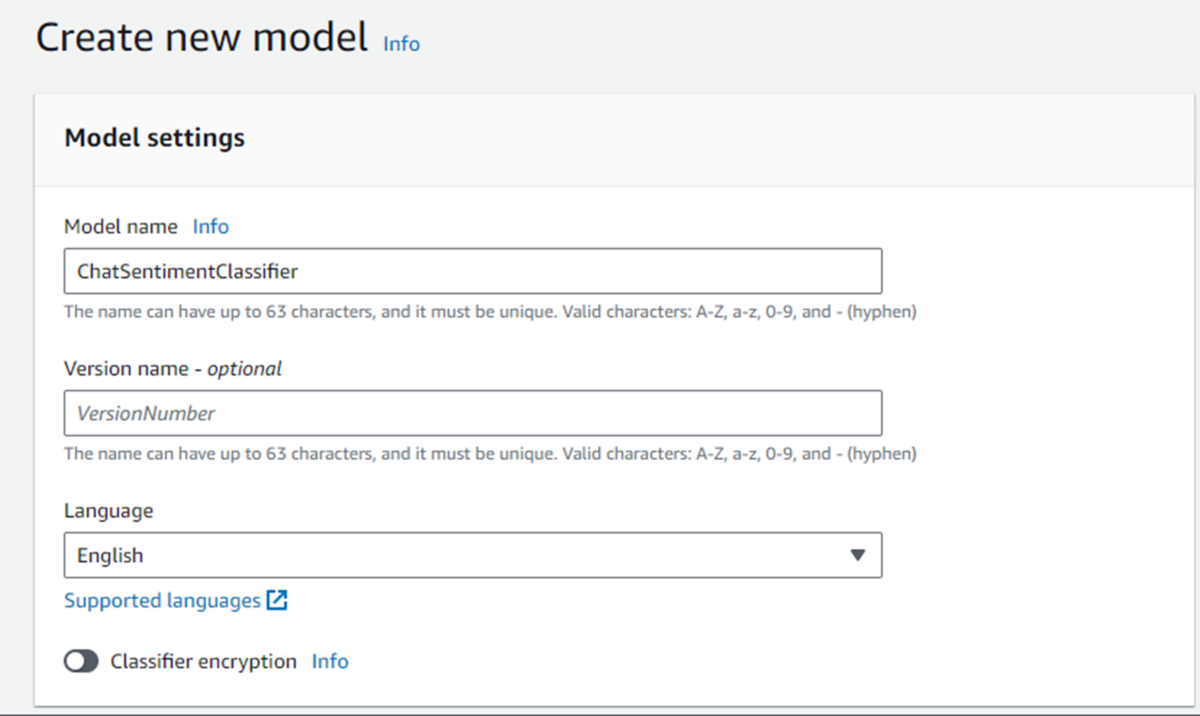
トレーニング用データのフォーマット、ラベル付けの設定、あらかじめS3バケットに格納したトレーニング用データの選択です。

Output data は特に指定せず、トレーニング用データにアクセスするためのサービスロールを新規で作成しました。
これらの設定でモデルの作成およびモデルのトレーニングを開始します。

Status が Trained になればモデルトレーニングが完了です!
完了までに30分程度かかりました。

なお、トレーニング用データはGTPに作ってもらいました。
training_data.csv(クリックすると展開されます)
training_data.csv
Label,Text
happy,I am so happy and excited!
happy,This is absolutely wonderful!
happy,I feel so joyful and content.
happy,This is the best day ever!
happy,I am so thrilled with this result!
happy,I am in such a good mood!
happy,Life is beautiful and I am grateful for it.
happy,I am elated by this fantastic news!
happy,I am on cloud nine right now!
happy,This achievement fills me with immense pride.
happy,I am overjoyed with my success!
happy,I am ecstatic about the opportunities ahead.
happy,This is a truly joyful occasion!
happy,I am bursting with happiness!
happy,I am delighted with the outcome!
happy,My heart is full of happiness.
angry,I am furious about this situation.
angry,This makes me so angry!
angry,I can't believe how mad I am.
angry,I am enraged by this!
angry,This is so frustrating and infuriating.
angry,I am boiling with rage.
angry,I am seething with anger.
angry,I am livid and cannot tolerate this any longer.
angry,My patience has run out and I am furious.
angry,This is absolutely unacceptable and enraging.
angry,I am fuming with anger right now.
angry,I am extremely irritated and annoyed.
angry,This situation is incredibly aggravating.
angry,I am deeply upset and angry.
angry,I feel like screaming with anger.
sad,I am feeling really sad and down.
sad,This is a very depressing day.
sad,I am heartbroken and gloomy.
sad,I feel so lonely and miserable.
sad,This is such a sorrowful moment.
sad,I am overwhelmed with grief.
sad,I am devastated by this loss.
sad,My heart aches with sadness.
sad,I am feeling deeply melancholic.
sad,This situation brings me profound sadness.
sad,I am feeling despondent and hopeless.
sad,I am drowning in sadness.
sad,I am engulfed in sorrow.
sad,My spirit is broken with sadness.
sad,I am feeling a deep sense of loss.
joyful,I am having a lot of fun!
joyful,This is really enjoyable.
joyful,I feel very relaxed and pleased.
joyful,I am having a wonderful time!
joyful,This is such a delightful experience.
joyful,I am filled with cheer and happiness.
joyful,This event is incredibly fun and entertaining.
joyful,I am experiencing pure joy.
joyful,This is a moment of great pleasure.
joyful,I am in a state of euphoria.
joyful,This celebration is truly joyful.
joyful,I am thrilled and happy.
joyful,I am relishing this joyous moment.
joyful,This is an occasion of sheer happiness.
joyful,I am basking in joy and contentment.
joyful,I am exhilarated and joyful.
Comprehend - エンドポイント
エンドポイントの作成です。
先ほど作成したモデルを選択します。Inference units は検証用なので 1 にしました。
これらの設定で作成。作成されるまで20分程度かかりました。(もっとかかったかも)

リクエストを投げてみる
curl -X POST <API Gateway のエンドポイント> -H "Content-Type: application/json" -d '{"text": "AWS最高"}'
curl コマンドで API Gateway のエンドポイントにリクエストを投げます。
結果
DynamoDB に格納された内容がこちらです。
翻訳前のテキスト、翻訳後のテキスト、Comprehendでの分析結果(感情のスコアとそれに伴うラベル付け)が格納されてます。いい感じ!

「笑いすぎて涙が出た」は「涙」に惑わされずに happy に分類されています。「laughed so much」の happy 要素が強かったっぽい?
![]()
「友達が遅刻したので怒っています」は「My friend is angry~」に直訳されてしまったせいか sad に分類されています。
「友達が遅刻したので私は怒っています」にしないと怒っているのが友達になってしまうのか。翻訳あるあるなので仕方ない。。。
![]()
ハマりポイント
今回詰まったところは、Comprehendのトレーニング用データの文字コードと形式でした。
・csv ファイルの文字コードは UTF-8 にすること
サクラエディタなどで、保存時に UTF-8 にしましょう。
・トレーニング用データの形式は「ラベル, テキスト」にすること
こちらはモデル作成時の info に載ってました。

(infoの内容)

上記を満たしていない場合、モデルトレーニングでエラーが起こります。
おわりに
Comprehend の Custom classification (カスタム分類) について紹介しました。
カスタム分類は他にも様々な用途で使えそうです。
例えば、ニュース記事のジャンル分け(政治・スポーツ・経済・エンタメ)や、SNS投稿の分類(キャンペーン・イベント・ブランド)などなど・・・
今回、ネガポジ分析よりも一歩踏み込んだ感情分析ができましたが、違訳されてしまうと想定外の結果になってしまいました。
日本語がサポートされたら Translate を噛ませる必要もなくなりもう少し精度が高くなりそう!
当ブログ記事を読んで興味が湧いた方はぜひ触ってみてはいかがでしょうか😊
お知らせ
APCはAWS Advanced Tier Services(アドバンストティアサービスパートナー)認定を受けております。
その中で私達クラウド事業部はAWSなどのクラウド技術を活用したSI/SESのご支援をしております。
www.ap-com.co.jp
https://www.ap-com.co.jp/service/utilize-aws/
また、一緒に働いていただける仲間も募集中です!
今年もまだまだ組織規模拡大中なので、ご興味持っていただけましたらぜひお声がけください。