はじめに
このセッションでは、データブリックス上でカスタムLLMをトレーニングおよびファインチューニングするプロセスについて紹介いたします。講演者はカスタムLLMがなぜ不可欠なのか、このプロセスにおけるデータブリックスの具体的な役割、およびM-Scienceからの実用的な例を共有しました。
目次
- はじめに
- 目次
- カスタムLLMの必要
- カスタマLLMにおけるデータブリックスの役割
- M-Scienceからの実際の使用事例
- 生成AIメソッドと比較分析
- カスタムLLMトレーニングデータの準備と展開
- モデルのファインチューニングと評価
- ケーススタディ:エムサイエンスと投資研究レポート
カスタムLLMの必要
LLMは、広範なテキストデータから複雑な言語パターンを学び、新しいテキストを理解し生成する中心的な役割を担います。この能力は企業にとって非常に重要であり、文書からの実体の抽出や分析レポートの生成などの自動化されたタスクを可能にし、効率と運用能力を向上させます。
カスタマLLMにおけるデータブリックスの役割
データブリックスは、堅牢なデータ管理から洗練されたモデルトレーニング、合理化されたデプロイメントに至るまでの包括的なプラットフォームサポートを通じて、LLMの作成とファインチューニングを簡素化します。データブリックスで利用可能なファインチューニングおよびプリトレーニングAPIは、特定の組織データと要件に合わせてLLMをパーソナライズするための重要なツールです。これらのAPIは、モデルが意図したタスクときめ細かく共鳴することを保証するための変更と調整を可能にします。
M-Scienceからの実際の使用事例
実際の活用事例で、M-Scienceがリサーチレポートの作成を自動化するために設計されたモデルのトレーニングにデータブリックスを活用しました。この事例は、データブリックスが実際のビジネスニーズにどのように対応し適応するか、報告書生成などの洗練されたタスクの自動化を促進する方法についての洞察を提供しました。
ユーザはデータブリックスを使用して大規模言語モデルをトレーニングし微調整するための基本的な知識と実用的な洞察を装備することができます。それによりプロジェクトでこれらの技術を実装することができます。このセッションは、データブリックスのような最先端の技術を活用することで、ビジネス運営を効率化しデータ駆動型に変革する方法を効果的に示しました。
生成AIメソッドと比較分析
このセクションでは、さまざまな生成AIメソッドを深く掘り下げ、特に「プロンプトエンジニアリング」と「レトリバル拡張生成(RAG)」に焦点を当て、これらの戦略の比較分析を提供します。
プロンプトエンジニアリング
プロンプトエンジニアリングは、特定のタスクを実行するために大規模言語モデルが必要とする特定のプロンプトを作成することを含みます。この方法は、モデルの固有の一般知識とタスク固有の能力を利用して効率を最大化しようとします。その利点にもかかわらず、プロンプトエンジニアリングは全体的なタスク能力と知識の深さにおいて制限があり、推論中に多数のトークンが必要とされ、その結果、かなりのコストがかかることがあります。
レトリバル拡張生成(RAG)
一方、レトリバル拡張生成(RAG)は、外部の知識源の同化を通じてカスタム企業データを組み込むことを特徴としています。本質的には、推論フェーズの間に、大規模言語モデルは文書の内容や訓練プロンプトなどの外部ベースから取得された知識で補強されます。RAGを効果的に実装するためには、外部知識ベースまたはベクトルデータベースを持っていることが重要ですが、追加のトレーニング時間は必要ありません。プロンプトエンジニアリングと比較して、RAGはタスク能力と知識の深さを向上させます。それにもかかわらず、プロンプティング、埋め込みモデルの使用、および取得した情報の管理を伴うため、推論コストは高くなります。
プロンプトエンジニアリングとRAGの両方は、タスクのパフォーマンスを向上させ、膨大な知識を獲得する潜在能力にもかかわらず、特定の領域における能力の制限と高い推論コストという問題に直面しています。後続のセクションでは、これらの制限を抑えながら、実際のシナリオでこれらのテクニックをより効率的に利用する方法論を探求します。これらの洞察を通じて、生成AIメソッドの取り扱いにおける戦略的アプローチを改善し、現実のタスクでの応用を最適化することができます。
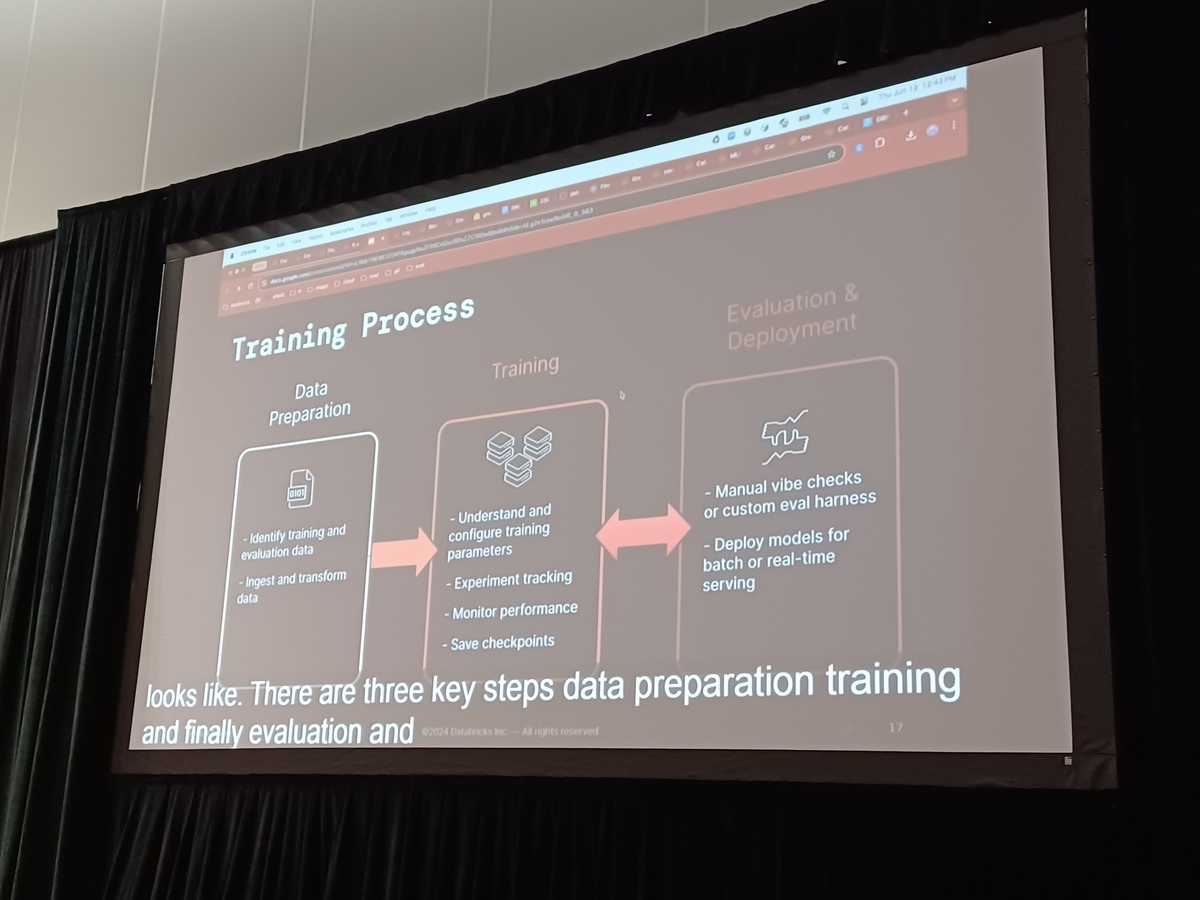
カスタムLLMトレーニングデータの準備と展開
カスタムLLMの準備と展開に不可欠な方法について詳しく解説します。
データ準備
最初の段階では、トレーニングデータが適切にフォーマットされ、計算的に準備されるように堅牢なデータガバナンスが行われます。この準備は、データの品質がモデルの性能に大きく影響するため、非常に重要です。トレーニング
データの準備が終わると、トレーニングに焦点が移ります。正しいトレーニングハイパーパラメーターの設定と適切なハードウェアの構成が重要です。トレーニング操作はエラー耐性があり、リアルタイムでモデルのパフォーマンスを監視する機能が含まれています。さらに、トレーニング中にモデルの重みを保護するためにチェックポイントが実装されています。評価と展開
モデルがトレーニングされると、その効果と展開の適合性を確認するために徹底的な評価を受けます。このプロセスには、必要に応じてモデルを外部で使用する準備が整うよう、安全な展開も含まれています。
トレーニングと評価の段階は反復的で、モデルの精度を継続的に向上させるためにしばしば繰り返されます。DatabricksでカスタムLLMを効果的に開発し管理するためには、これらのフェーズをマスターすることが重要であり、モデルの最適なパフォーマンスと運用へのシームレスな統合が保証されます。
モデルのファインチューニングと評価
今回のセッションでは、「モデルのファインチューニングと評価」に重点を置いています。このセグメントでは、Databricksの実験アプリを使用して、基礎となるモデルの実験を開始する方法について詳細なウォークスルーを提供しました。ここでは、ユーザーインターフェースがファインチューニング手順の直接的な開始を容易にします。このプロセスは、DataverseのPython SDKを使用して実行することもでき、ユーザーにとってのアクセス性を高めます。
セッション中にUIのライブデモンストレーションが行われ、画面上で直接関与するステップの詳細が説明されました。それには、さまざまな技術仕様が表示されていました。インターフェースの使いやすさと直感的な設計が強調され、Databricksプラットフォームに比較的新しいユーザーでも操作が容易であることが強調されました。
UIを通じて、参加者はさまざまなタスクを選択する方法を見ることができ、これはさまざまな基礎モデルをサポートします。講演者は、このタスク選択がファインチューニングプロセスを特定の要件に合わせてカスタマイズすることの重要性を強調し、Databricksのツールセットが大規模な言語モデルを管理する際の多様性と適応性をお知らせました。
ケーススタディ:エムサイエンスと投資研究レポート
エムサイエンスによる投資研究レポートの革新
企業がデータを使用して洞察を加速するためにDatabricksプラットフォームを活用する方法についての包括的な概要が提供されました。注目のケーススタディとして、エムサイエンスによる取り組みが議論されました。
エムサイエンスは、機関投資家向けに投資研究を生成する専門企業で、公共の消費者企業のパフォーマンスを予測するために大量のオンライン消費者取引データを利用しています。伝統的には、この分析は専門のアナリストによって行われていましたが、エムサイエンスはAI駆動の「リサーチ・オーサー・アンド・パブリッシャー」というツールを使ってこのプロセスを強化しています。
リサーチ作成者および掲示者の役割とファインチューニングの必要性
セッションでは、エムサイエンスが運用上のニーズにより適切に応えるため、Databricksプラットフォームでその生成モデルをファインチューニングしている方法を強調しました。この「リサーチ作成者および掲示者」ツールは、データからレポートを自動生成するだけでなく、投資家に価値ある洞察を与えるレポートを豊かにします。
伝統的には、投資研究レポートはアナリストによって手動でキュレーションされました。この責任をAIに移行することで、エムサイエンスはより迅速かつ広範な分析を可能にしました。これには、投資研究の出力における速度と品質を確保するためのファインチューニングが必要です。
ファインチューニングの成功における重要な役割
モデルの特定のデータセットへの感度を調整する上で、ファインチューニングは不可欠です。これにより、レポートの精度が向上します。エムサイエンスにとって、消費者行動のニュアンスを捉え、それを市場傾向にリンクすることは非常に重要です。DatabricksのファインチューニングAPIは、エムサイエンスのユニークな要件をしっかりとサポートするカスタマイズされたLLMの開発を容易にし、投資研究の質を大幅に向上させます。
まとめと将来の展望
このケーススタディは、AIとデータ分析がビジネスプロセスを再形成し、従来の方法では困難だった新しい価値提案を確立する可能性を示しています。エムサイエンスの先駆的な努力は、投資研究の将来の軌道を予測しています。このような進歩は基準を設定し、DatabricksのAPIのような強力なツールが様々なセクターにおけるAIの影響を広げ、データ駆動型意思決定の標準を絶えずリセットする進化する景観を予測します。

Databricks Data + AI Summit(DAIS)2024の会場からセッション内容や様子をお伝えする特設サイトをご用意しました!DAIS2024期間中は毎日更新予定ですので、ぜひご覧ください。
私たちはDatabricksを用いたデータ分析基盤の導入から内製化支援まで幅広く支援をしております。
もしご興味がある方は、お問い合わせ頂ければ幸いです。
また、一緒に働いていただける仲間も募集中です!
APCにご興味がある方の連絡をお待ちしております。