
はじめに
GLB事業部Lakehouse部の鄭(ジョン)です。
この記事ではKXのPyKXを利用し、DatabricksとKXをConnectする方法を紹介いたします。
Databricks上でkdb Insights licenseを使用してKXのプロダクトのkdb+を利用する検証を行います。
kdb+は世界最速の時系列データベース及び分析エンジンです。
KXのプロダクトの詳細情報は記事をご確認ください。 techblog.ap-com.co.jp
目次
PyKXの紹介
PyKXは世界最速の時系列データベースkdb+に対するPythonの初のインターフェースであり、ベクトルプログラミング言語のq言語を基本的に使用します。 PyKXはq/kdb+をPythonと統合するためにPythonファーストのアプローチをとります。 膨大な量のin-memoryおよびdisk上のtime-series dataを効率的にクエリおよび分析できる機能をユーザーに提供します。
- PyKXの説明は以下のKXのドキュメントを引用します。 code.kx.com
検証の流れは次のようです。
➀ kdb Insights licenseをダウンロードする
➁ PyKXをインストールする
③ kdb Insights licenseを利用し、PyKXをインポートする
④ KXのq言語を使ってみる
⑤ DatabricksのEDA機能を使ってみる
⑥ PyKXとPandasの性能比較
検証
1. kdb Insights licenseをダウンロードする
kdb+を使用するためにkdb Insights licenseをダウンロードします。 kdb Insights licenseは、KXのkdb Insights Personal Edition 12 Months Free Trialで無料体験が可能です。
上記のページから個人情報を入力したら、メールにライセンスが届きます。

ライセンスはメールに書いてあるbase64エンコーディングバージョンと、【kdb Insights Personal Edition License Download File】を押したら自動的にインストールされるLICファイルバージョンがあります。
![]()
2. PyKXをインストールする
Databricks上でPyKXをインストールします。
pip install pykx
3. PyKXをインポートする
kdb Insights licenseを利用し、PyKXをインポートします。
import pykx as kx
kdb Insights licenseを登録する方法は二つあります。
➀ライセンスのファイルをノートブックと同じロケーションに保存する方法です。
pythonのバージョンが3.10以上ならできます。
自動的にライセンスを読み込みます。

➁ライセンスを入力する方法です。
入力の方法は下のドキュメントにあります。
【1. kdb Insights licenseをダウンロードする】を行った方はY / Y / 2 を順番で入力した後、メールに届いたlicense keyをコピーし、入力したらImportができます。

4. KXのq言語を使ってみる
PyKXをインポートしたらDatabricksのpythonでKXのq言語を使用できます。
kx.q.til(10)
![]()
Databricksにあるテーブルと同じテーブルをkdb+に作成できます。
- KXの公開データ(Time series)をDatabricksにインストールした後、pandasを利用してロードします。
import pandas as pd weather = pd.read_csv("自分のファイルのパス")
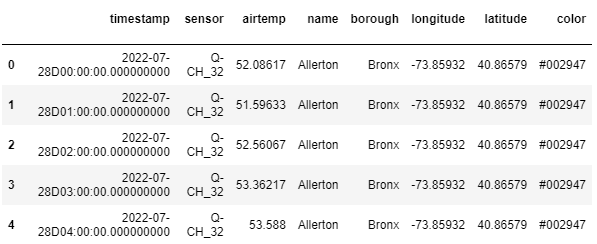
- Databricksにあるデータをロードして、kdb+にインポートします。
# Creating the same table into kdb+ kx.q["weather"] = weather kx.q["weather"]
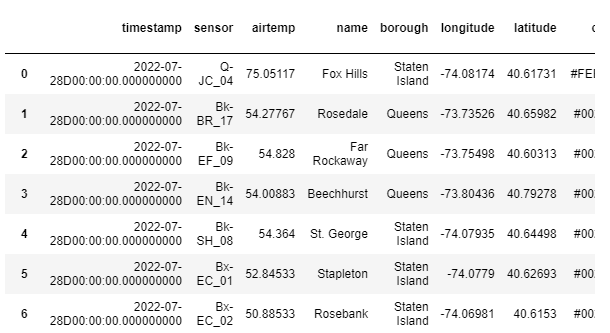
PyKXのSQLを使ってみます。
kx.q.sql("SELECT * FROM weather limit 5")
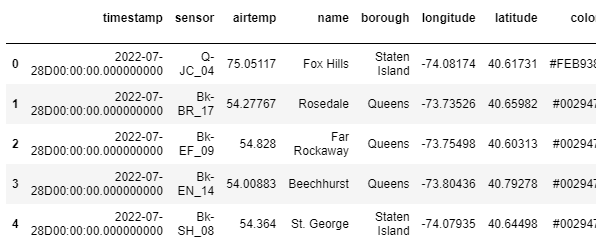
- sqlにあるほとんどの機能は使用可能です。
kx.q.sql("SELECT * FROM weather ORDER BY name limit 5")
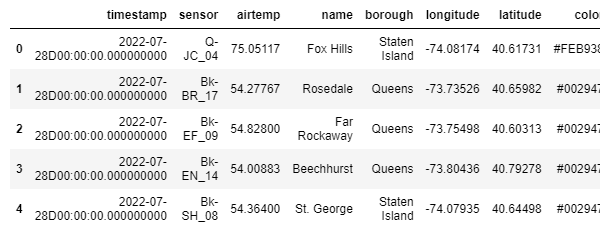
kx.q.sql("SELECT * FROM weather WHERE borough = 'Staten Island' limit 5")
kdb+にあるデータをロードして、pandasのテーブルに変換した後、csvでDatabricksに保存します。
# Creating the same table into pandas df = kx.q["weather"].pd() df.head(5)
kx.q.write.csv('保存するパス/weather_kdb.csv', df)
![]()
5. DatabricksのEDA機能を使ってみる
Databricksはワークスペースの機能を使って簡単なEDAが可能です。
kdb+にあるデータをロードして、Databricksで視覚化をします。
display(df)
【+】ボタンを押したらVisualizationとData Profileが出ます。
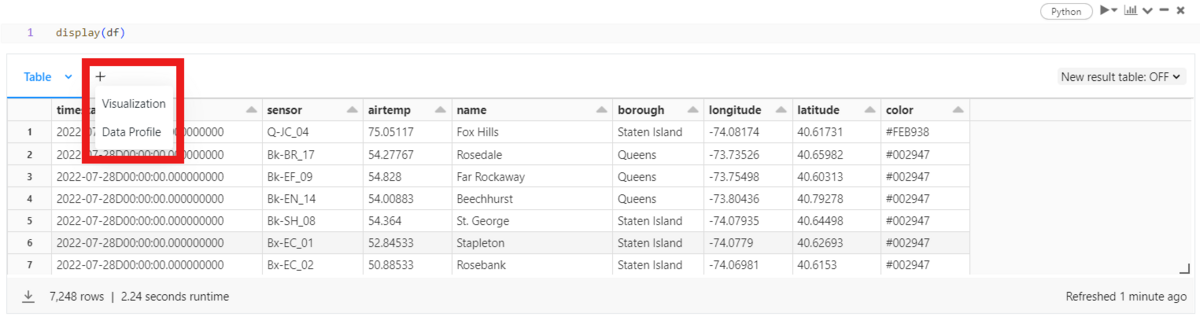
Data Profileを使うとFeaturesの特徴を簡単に探究できます。
Numeric FeaturesとCategorical Featuresで分類して表示します。
Numeric Featuresは欠損値と基本統計量、簡単なグラフを見ることができます。
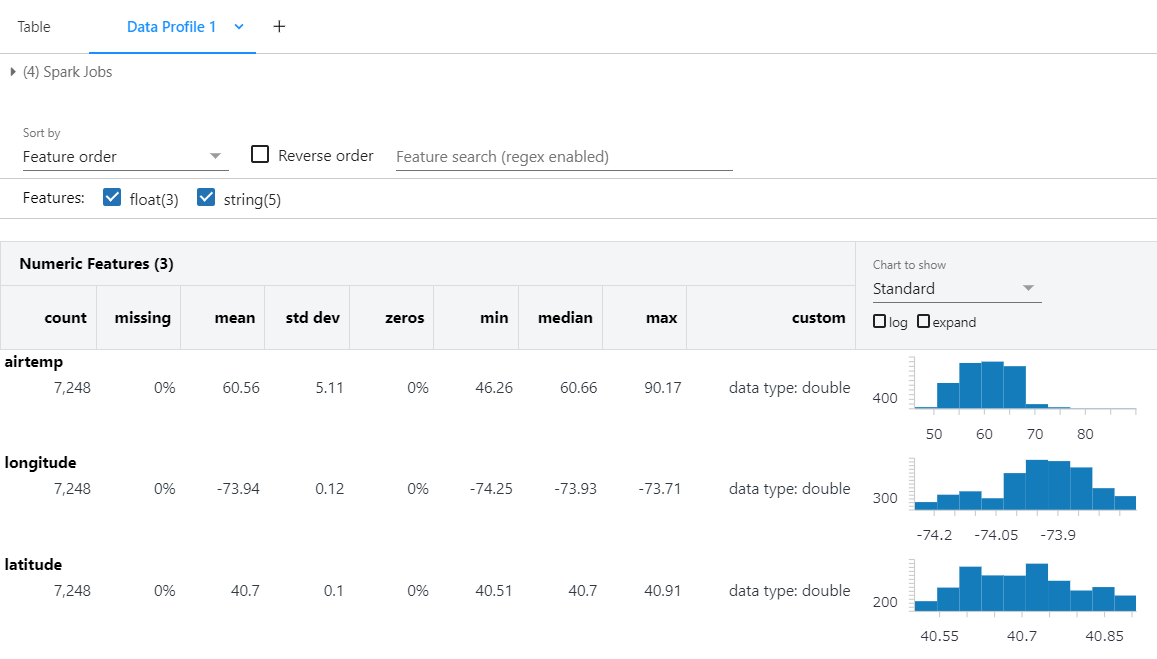
Categorical Featuresでは、ユニークな値の個数、最も多くの変数とその頻度数を簡単に見ることができます。
Visualizationを使ったらUIを利用してノーコードで視覚化が可能です。
Dropdownで多様なグラフを選択できます。
* グラフの種類の詳細は下記URLをご参照ください。
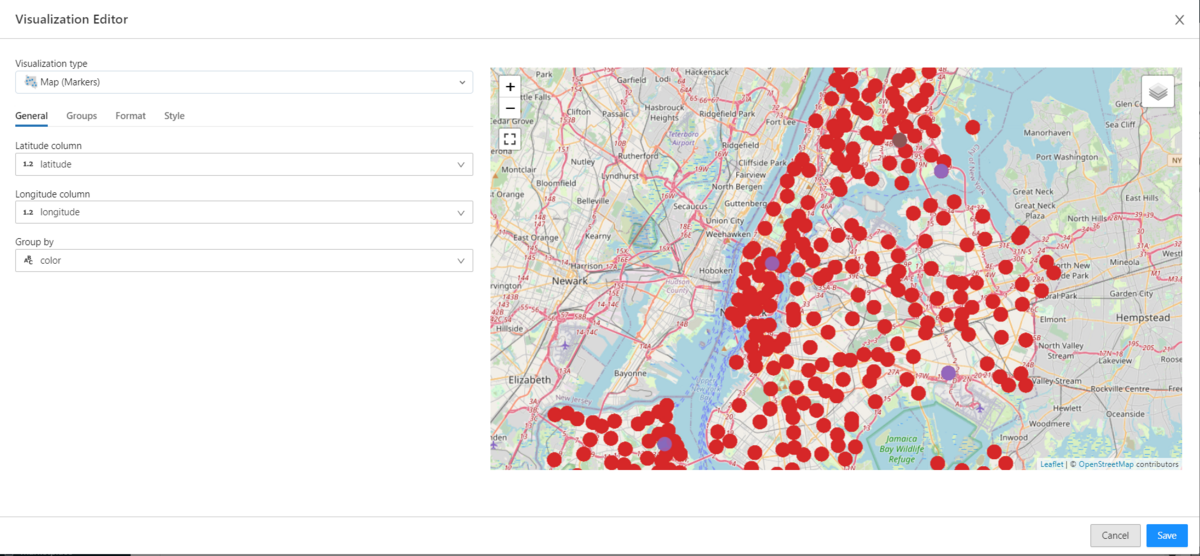
- longitudeとlatitudeがあったらマッピングが可能です。
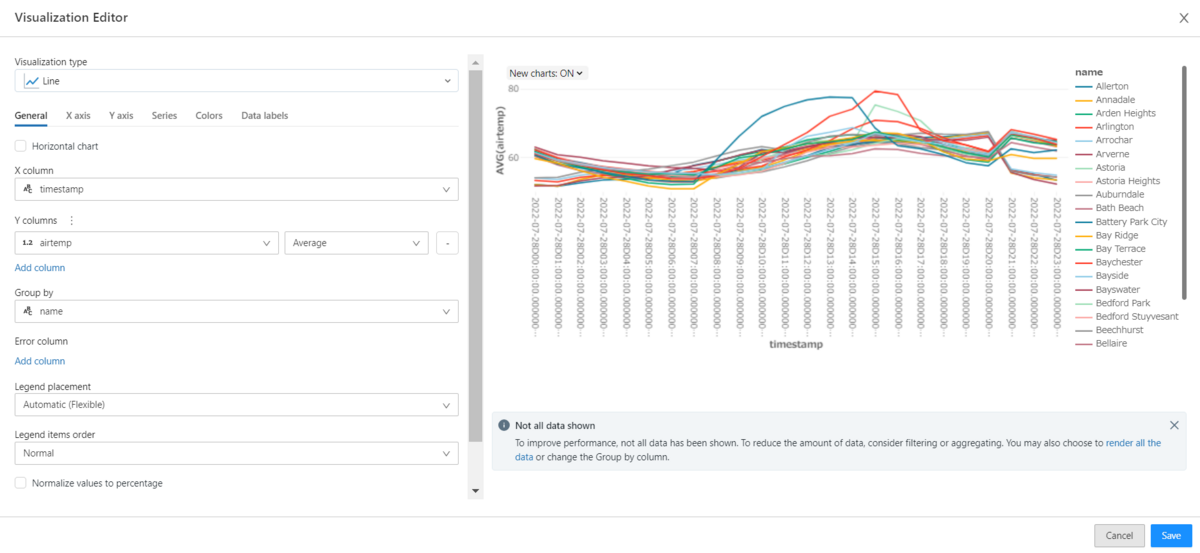
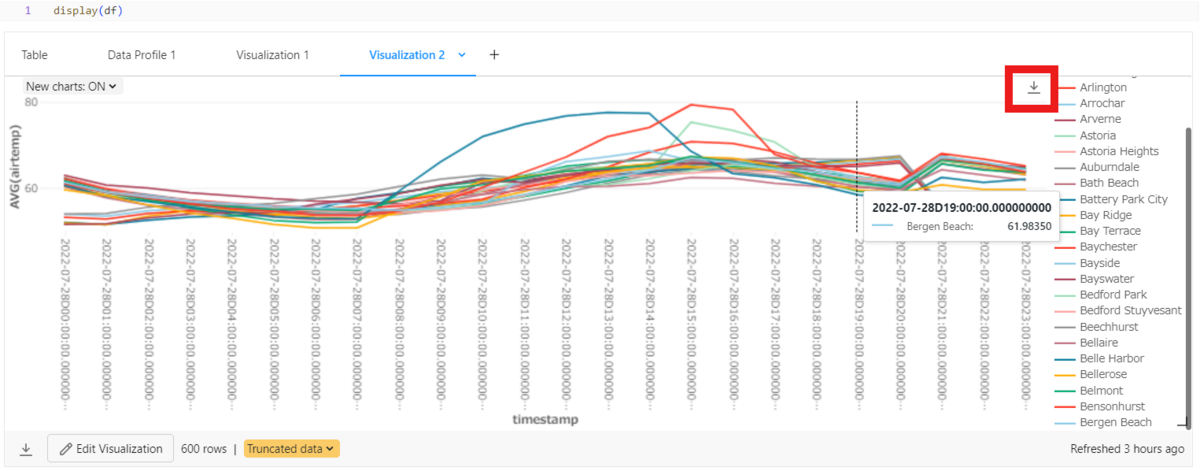
- カラムの設定を通じて簡単にLineグラフを作られます。(X、Y、Group byなどのカラム)
作成したグラフはワークスペースで確認できます。
- マップのlayerはワークスペースでも調整可能です。
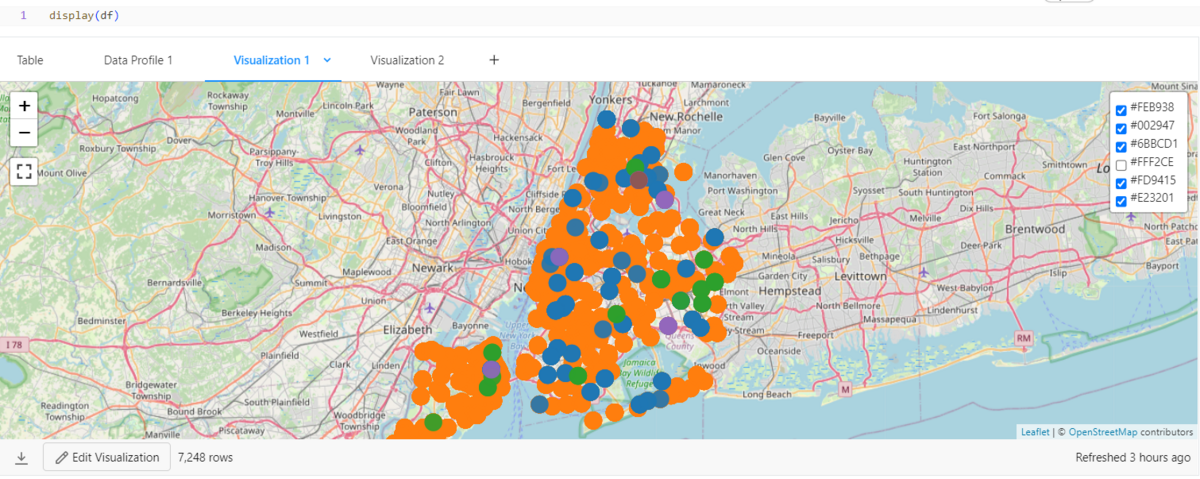
- LineグラフはPNGファイルでイメージを保存できます。
6. PyKXとPandasの性能比較
PyKXとPandasの性能を比較します。
比較の方法は下の資料を参考しました。
- kdb+のq言語とPandasの集計速度の比較:
- PyKXとPandasの速度比較及び視覚化:
PyKXとPandasのcsv read機能を両方使って、データを読み込みます。
csvファイルをPyKXで読み込んだ場合は、PyKXのテーブルとして保存されて、
Pandasで読み込んだ場合は、Pandasのデータフレームとして保存されます。
- PyKXの利用
weather = kx.q.read.csv("自分のファイルのパス") type (weather)
![]()
- Pandasの利用
weather_pd = pd.read_csv("自分のファイルのパス") type (weather_pd)
![]()
データのカラムタイプを確認します。
Pandasでデータを読み込んだ場合は、timestampを他のtypeで認識する可能性があります。
タイプがtimestampでない場合は、日付、時間など時間に関連する機能を使用できません。
もしかして、Pandasのデータフレームが必要な場合は、Pykxでデータを読み込んだ後、Pykxでテーブルをpdに変換すればtimestampを使えます。

timestampのtimeを基準にsumとavg計算した時、掛かる時間で性能を比較します。
timestampは"2022.07.28D00:00:00.000000000"と同じ形です。
集計結果は次のようなテーブルを作成します。
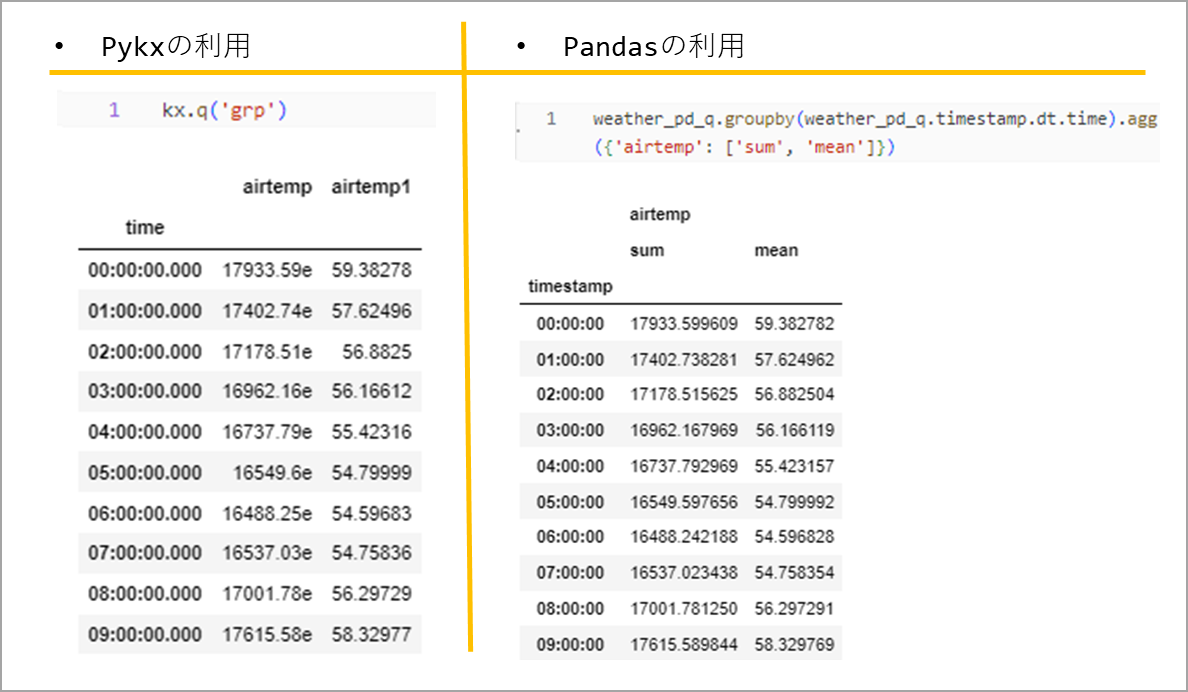
時系列の集計を100番計算した時、掛かる時間を"%%capture"と"%timeit -n 100"を利用して、各変数に保存します。
- PyKXの利用
%%capture pykx_time_res #コードの結果を保存する %timeit -n 100 kx.q('grp:select sum airtemp, avg airtemp by timestamp.time from weather') #100番計算した時、掛かる時間を測定
- Pandasの利用
%%capture pandas_time_res #コードの結果を保存する %timeit -n 100 grp=weather_pd_q.groupby(weather_pd_q.timestamp.dt.time).agg({'airtemp': ['sum', 'mean']}) #100番計算した時、掛かる時間を測定
視覚化に使用する関数を作成します。関数は、KX Academyにある関数を利用しました。
一部のコードは、今回の検証に合わせて変更して使用しました。
- ➀ 文字列処理関数
# ➀ 文字列処理関数 def fix_res_string(v) -> str: return v.stdout.split("\n")[0].replace("+-", "±")
- ➁ 入力された値をPandasとPyKXにディクショナリー化する関数
# ➁ 入力された値をPandasとPyKXにディクショナリー化する関数 def create_res_dict(pandas_time_res, pykx_time_res) -> pd.DataFrame: return pd.DataFrame( { "Time": { "Pandas": fix_res_string(pandas_time_res), "PyKX": fix_res_string(pykx_time_res), } } )
- ③ 入力されたディクショナリーをデータフレーム化する関数
# ③ 入力されたディクショナリーをデータフレーム化する関数 def parse_time_vals(d: dict) -> pd.DataFrame: all_rows = pd.DataFrame() for k, v in d.items(): if "±" not in v: one_row = pd.DataFrame( {"avg_time": "", "avg_dev": "", "runs": "", "loops": ""}, index=[k] ) else: avg_time, rest1, rest2 = v.split(" ± ") avg_dev, _ = rest1.split(" per loop") rest2 = rest2.strip(" std. dev. of ") rest2 = rest2.strip(" loops each)") runs, loops = rest2.split(" runs, ") one_row = pd.DataFrame( {"avg_time": avg_time, "avg_dev": avg_dev, "runs": runs, "loops": loops}, index=[k] ) all_rows = pd.concat([all_rows, one_row]) return all_rows.reset_index().rename(columns={"index": "syntax"})
- ④ "%timeit-n 100"で測定した値を入力すれば、➀・➁番関数を計算した後、③関数のデータフレームを返す関数
# ④ "%timeit-n 100"で測定した値を入力すれば、➀・➁番関数を計算した後、③関数のデータフレームを返す関数 def parse_vals(pandas_time_res, pykx_time_res) -> tuple[pd.DataFrame]: res_df = create_res_dict(pandas_time_res, pykx_time_res) return parse_time_vals(dict(res_df["Time"]))
- ⑤ データフレームを比較する関数(PyKX/Pandas)
# ⑤ データフレームを比較する関数(PyKX/Pandas) def compare(df: pd.DataFrame, metric: str, syntax1: str, syntax2: str) -> float: factor = float(df[df["syntax"] == syntax1][metric].values) / float( df[df["syntax"] == syntax2][metric].values ) str_factor = f"{factor:,.2f} times less" if factor > 1 else f"{1/factor:,.2f} time more" print( color.BOLD + f"\nThe '{metric}' for '{syntax2}' is {str_factor} than '{syntax1}'.\n" + color.END ) return factor
- ⑥ 時間を変換する関数
# ⑥ 時間を変換する関数 def fix_time(l: list[str]) -> list[int]: fixed_l = [] for v in l: if v.endswith(" ns"): fixed_l.append(float(v.strip(" ns")) / 1000 / 1000) elif v.endswith(" µs"): fixed_l.append(float(v.strip(" µs")) / 1000) elif v.endswith(" us"): fixed_l.append(float(v.strip(" us")) / 1000) elif v.endswith(" ms"): fixed_l.append(float(v.strip(" ms"))) elif v.endswith(" s"): fixed_l.append(float(v.strip(" s")) * 1000) elif "min " in v: mins, secs = v.split("min ") total_secs = (float(mins) * 60) + float(secs.strip(" s")) fixed_l.append(total_secs * 1000) else: fixed_l.append(v) return fixed_l
- ⑦ 視覚化する関数
from tabulate import tabulate import matplotlib.pyplot as plt # ⑦ 視覚化する関数 def graph_time_data(df_to_graph: pd.DataFrame) -> pd.DataFrame: print(tabulate(df_to_graph, headers="keys", tablefmt="psql")) fig, ax = plt.subplots(figsize=(7, 3)) df = df_to_graph.copy() df["avg_time"] = fix_time(df["avg_time"]) df["avg_dev"] = fix_time(df["avg_dev"]) df["upper_dev"] = df["avg_time"] + df["avg_dev"] df["lower_dev"] = df["avg_time"] - df["avg_dev"] _ = compare(df, "avg_time", "Pandas", "PyKX") df.plot(ax=ax, kind="bar", x="syntax", y="avg_time", rot=0) # df.plot(ax=ax, kind="scatter", x="syntax", y="upper_dev", color="yellow") # df.plot(ax=ax, kind="scatter", x="syntax", y="lower_dev", color="orange") ax.set_title("Pandas VS Pykx Time Taken") ax.set_ylabel("Average Time (ms)") ax.get_legend().remove() ax.set(xlabel=None) plt.show() return df
- class colorの作成
# class colorの作成 class color: PURPLE = "\033[95m" CYAN = "\033[96m" DARKCYAN = "\033[36m" BLUE = "\033[94m" GREEN = "\033[92m" YELLOW = "\033[93m" RED = "\033[91m" BOLD = "\033[1m" UNDERLINE = "\033[4m" END = "\033[0m"
作成した関数を利用して、視覚化します。
timestampを利用して集計する場合、pykxがpandasより11.7倍速いという結果が出ました。
time_res_df = parse_vals(
pandas_time_res, pykx_time_res
)
numeric_time_res_df = graph_time_data(time_res_df)
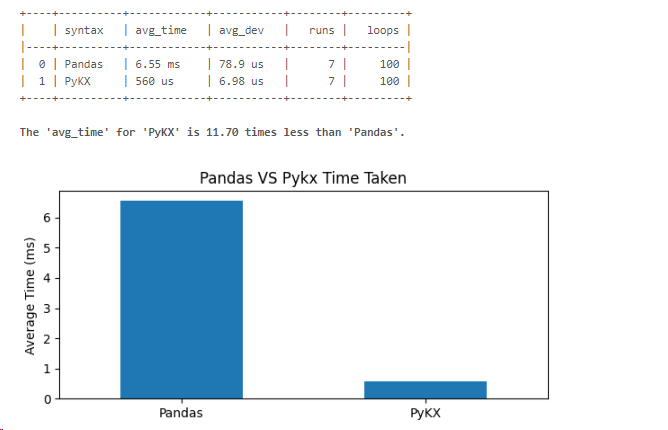
時系列分析ではPyKXの方が、timestampタイプの使用および集計速度で優秀な結果が出ました。
まとめ
今回の投稿ではDatabricks上でkdb Insights licenseを登録してKXのkdbを利用してみました。
PyKXというライブラリを使用すると、PythonからKXのKDBにアクセスでき、q言語を使用できます。
Databricksの様々な機能とKXのKDB+の両方を使いたい方にお勧めします。
最後までご覧いただきありがとうございます。
引き続きどうぞよろしくお願い致します!

私たちはDatabricksを用いたデータ分析基盤の導入から内製化支援まで幅広く支援をしております。
もしご興味がある方は、お問い合わせ頂ければ幸いです。
また、一緒に働いていただける仲間も募集中です!
APCにご興味がある方の連絡をお待ちしております。