
AOAI版のWhisperとOpenAIを利用してアプリケーションを実装した際の個人的な覚書です。
Whisperは面白いのですが利活用検討するにあたって、様々な制約事項を考慮しながら実装をしないといけませんでした。
以前から生成AIに取り組まれていた数少ないエキスパートを除くと、業務に取り入れるのは大変ではないかと思います。
私自身は大層な身分ではなく開発中で成功体験を共有とは言えないのですが、これから実装の最前線に立つドメインエキスパートとしてのエンジニアやマネージャー向けに、 及ばずながらも似たような立場として先にWhisper使ってアプリケーションを開発した気づきが一つでも役立てればと思い記事を書きます。
目次
- 目次
- 注意事項
- Whisperについて
- 文字起こしとしては70%くらいの出来と受け止める
- 30%をどうやって埋めるかを考える
- 60分当たり15000文字
- 不要な文字を削除する
- アウトプットの品質を高める
- 最後に
- ACS事業部のご紹介
注意事項
- 開発しての感想です参考程度に。
- OpenAIの詳細な仕組みについては記載しません。
- OpenAIのエコシステムのみで完結する利用を前提で記述しており、独自LLMや追加のML処理を使わないです。
Whisperについて
Whisperについては以下のリンクから内容をご確認ください。
文字起こしとしては70%くらいの出来と受け止める
Whisperは音源から文脈を読み取りながら文字起こしを行う生成AIです。 AIで行う文字起こしとしては極めて品質が高く、
- 非参加者が音源だけ聞いて文字起こしをした
- 60分を数分で片づけた
- アプリケーションに組み込める
と考えると驚異的な品質だと考えてます。
とはいえ、そのままの文字起こしを組織が利用するにはまだ不足があります。 主なユースケースとして、議事録やコールセンターでの業務やその他さまざまな業務が考えられますが、 アプリケーションの目的達成のためには、生成される文字起こしの品質は不足しております。 感覚値としてWhisperでもそうですが、生成AIの生成物は7割くらいの出来と受け止めるのがよいのかなと思っておりますが、 このあたりの感覚値は立場によるので、
ユースケースに沿って、文字起こしから要約処理までプレイグラウンドで実際に動かす
これを経たうえでご自身の立場で判断してください。
30%をどうやって埋めるかを考える
AIによる生成物を7割の出来と考えると、目的達成に向けた問いを立てやすくなりました。
- 残り30%の品質をどこまでAIで埋めますか?(プロンプトやパラメータやデータ)
- 残り30%の品質をほかの誰が埋めますか?(フローごとにOpenAIの処理を分割、ロジックでの工夫、ユーザーによる修正)
- 残り30%の品質は目的達成のために全て埋める必要はありますか?(質が足りなくても、それを前提として業務を運用することで生産性は上がりませんか?)
これら受け止めたうえで、自分たちのゴール設定を考えていく必要があると感じました。
60分当たり15000文字
個人的に一番大事です。
正確な計算はとってないですが、60分の動画を起こすと概ねテキスト数は13000-20000文字ちょっとでした。 文字起こしを利用したアプリを要件定義する際は60分 15000文字程度で計算するとコスト計算や、OpenAIを利用した要約処理の設計に役立つと思います。
実際15000字をGPTモデルにそのまま渡して、何某かの要約処理を行っても業務に沿ったいい感じのもの(完全性/網羅性の高い)は生成されないです。 GPT-4(32k)でも15000字の全体感がいい感じに語られる程度です。 そこから深堀しようとすると、15000字+α複数回の問い合わせが発生しコストはかかる上に、それでも要求は満たせないことになります。
そこで文字起こしをチャンク分割し、小分けにして文字起こしの内容の要約を行うと思います。
では何文字がよいのか?ということに明確な答えはなく、文字起こしを要約する際の指示内容の複雑度や文章としての書きっぷりによるので一概には言えず、 このあたりを探ることが要件を考えるポイントの一つになると思います。
私なりに作業していて感じたのはGPTモデルの当初のトークン上限である、
GPT3.5(4K)やGPT-4(8K)を基準に考えると
チャンク分割する際の粗っぽい基準点が見えてくると思います。トークン数は文脈を認識できる範囲で少ないほど良いので、コストや処理時間との見合いながらチャンクサイズを探していきました。
また、サマライズの際はチャンク毎に直前の要約内容を含めたり、抽出、分類、サマライズといった命令を1度のOpenAIへ要求で実現せず、それぞれ極力単一目的の処理になるようにOpenAIへの要求を分解する、基本に従った対応をすることが大事です。
これを守ると使いやすいアウトプットに加工することができました。
不要な文字を削除する
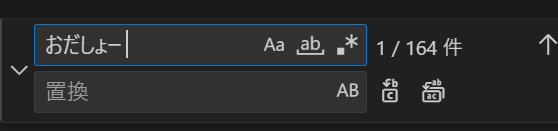
使っている人であれば皆さん知っていると思うのですが、プレビュー版の現在のAOAI Whisperでは恐らくローカライズされた際の時の学習データに利用されたワードが出力されることがあります。
”おだしょー”

という謎のワードですね。 ※MSの方のHNか? 私が見たところ「お疲れ様でした」という表現や、「おxxxxx」という表現が乱れて拾われていると思うのですが、 結構な割合で出てきます。
私が見た最大値では、60分18000字程度の文字起こしにおいては1000文字程度の「おだしょー 」、164か所出てきたことがありました。
出力される数はピンキリですが、要約の際に全件削除してGPTモデルに渡すことで要約の品質が向上したり、歩留まりから落ちるものが減ると思います。


アウトプットの品質を高める
Whisperモデルは高い精度で文字起こしを行いますがAIで読み取る以上完璧ではありません。 Garbage In, Garbage Outの原則は機械学習では、特に強く意識されているそうでインプットの質がアウトプットの質に直結するそうです。 Whisperを利用するアプリの場合は、書き起こしの品質低下、誤字脱字の要因としてアウトプットの品質低下を招くことになります。
以下2つのインプットの品質問題がすぐに目につくかと思います。
- 音質
- パラメーターにない専門用語
これらによって以下のような、読み取り違いが時折発生します。
実際に出てきたものです。
| 誤り | 正解 |
|---|---|
| xxxを臨時にかける | xxxを稟議にかける |
| イリス作業の実施 | リリース作業の実施 |
| 福岡市圏の実施 | 負荷試験の実施 |
※これらは毎回読み違えるわけではなく、正しく出力されることもあります。OpenAIの性質から考えるとワードの文脈をどの程度認識できたのかだと思います。
先にインプットの品質問題の対策への個人的な感想を申しますと、100%の対策はできないと感じてます。 インプットの質を高めることだけでなく、インプットの質の低下を補完することや、利用方法を念頭に価値のあるアウトプットを見出すにはどうすればよいか、どの程度の文字起こしの品質でよいかを考えるのが適切だと考えております。
対策①:音源の品質を上げる
前述のおだしょーの話の対策でもありますが、音源の品質向上でインプットの品質について対応できる部分は多いと思います。 中でも以下2点はWhisperの利活用には必須と思います。
- ネットワークの品質向上
- マイク経由のノイズを無くす
対応としては、理論上は音源の加工も考えられますが、業務上では現実的ではないので音源によるインプットの品質対策は上記二つが思いつくところです。
音源のビットレートについてですが、128k/bpsずつの変換するのがいいのかなと思います。 Azure OpenAI版のWhisperは25MB制限がありますので、これに適応すると128k/bpsで25分ずつのトラック(24MB)を作成し順次Whisperに流し込んで、文字起こしを受け取るような処理になると思います。
128k/bpsのmp3音源の品質は人間の立場で聞きづらいと感じることは少ないと思います。おそらく、コンタクトセンターの音質はここまで高くないでしょうし、会議ツール例えばteamsのオーディオの上限値が128kbpsであることを考えると、一般的なユースケースではこれを上限として設定することになると考えてます。 32kbpsや64kbpsについては詳細に試してないので、気になる方は試してみてください。(64くらいなら大丈夫だと思いますが)
また、音源を取り扱う際にffmpegをよく使うことになると思いますが、この辺の実装は抑えるといいと思います。
対策②:会議や会話のやり方をAIに合わせる
文字起こしのシステム利用を端的に言うと発言内容、会話の構造を読み取り加工したうえで 任意の処理を実行することだと思います。 当たり前のことですが、文字だけでこれらが分かるように発言すると品質は上がります。 よしんばWhisperでの文字起こしで誤字が出ても、要約する際に会議の文脈が分かり適切なプロンプトが入力されれば、 その中でワードの誤りが補完される確率が高まり最終的にアウトプットとしての妥当性が向上するからです。
- 発音に気を付ける
- 言葉や言葉のスコープを極力省略せずに発言する
- 会議や会話の全体枠(アジェンダ)を意識し流れに沿って会話する。
- 流れから脱線する場合はきちんとそれを明示しながら会話をすること。
とはいえ、人間の営みにも限界があるので、マナー講師的にあれこれ縛り付けるのは違うと思います。
対策③:(2023/10/30時点では慎重に)Whisper実行時のプロンプト対応
専門用語の対策としては、Whisperを呼び出す際に文脈や専門用語を渡す、inital_promptといったテクニックもあります。 これによって文字起こしの品質を高めることができるというものですが、まだあまり試せていないです。
以下のようにWhisperを呼び出す際に渡します

現状で言えることとしては、
- 渡せるトークン数が224と少なく、ユースケース次第で辞書や会話の文脈としては不十分な可能性。
- OpenSource版のWhisperでのinitial promptを起因としたバグの存在がある。
- Azure OpenAIのWhisperについては現在プレビュー版であること
これら踏まえると、initial_promptで打ち取ることは、2023/10/30現在では慎重にチェックした上で対応したほうが良いと思います。 Azure Speech to talkでのWhisperにて今後チューニング周りの機能追加の予定があるとのことで、AIの調整でのインプット品質の対策は様子を見るものいいかなと思います。
Azure Ai Speech版のWhisperのチューニング対応予定について
日時記載はありませんが、対応予定と記載があります。

OpenSource版のWhisperのinitial_promptのバグ
OpenSource版のWhisperのバグについては以下のツイートに主だったものがまとまってました。 文字起こしの欠落につながるものや、initial_promptの内容が連続して出力されるといったものです。 Azure版についての情報は持っていないので、参考程度に見てください。
There was a huge breakthrough this week at @gladia_io
— 🎙Jean-Louis Queguiner (@JiliJeanlouis) 2023年10月3日
- You can now prompt the audio to guide the transcription using Gladia's Whisper Large-v2 model with NO RISK to have hallucinations:
The Open Source Whisper model has big problems with initial prompts. See here:
-… pic.twitter.com/9EyzGEOnKu
対策④:誤字を前提にする
誤字を受け入れ、運用でカバーするのはも対策だと思います。 生成AIの大前提として、内容は人間が責任を持つことはでありそれに従い必ず人の目が入れるならば、文字起こしのバグを全て打ち取る必要はなく、その際のUXを向上したり検証する際の付加価値を探した方がいいと思います。
文字起こし、要約、分類、加工、人間チェックのどこで打ち取るかを意識すると、生成AIの良し受け入れつつ使うことができると思います。
- 文字起こしが誤ることを前提に、要約のプロンプトを詳細化、最適化したり、パラメータ調整する。
- 生成物は最後は人間が直すことを前提としてアプリケーションや業務フローを設計する。
ということを念頭に置いて、品質とメリットのトレードオフを考えるといいと思います。 後者についてはベストプラクティスの無い黎明期なので、出たものを人間に素直に見せて簡単に直せるくらいの体験から入ると良さそうな予感がしてます。
最後に
OpenAIに対してはシステムを基準に考えるよりも、補完対象である作業を行う人間と業務目的を中心に考えたときに幸せになれる予感がしております。
ACS事業部のご紹介
私達ACS事業部はAzure・AKSなどのクラウドネイティブ技術を活用した内製化のご支援をしております。
また、一緒に働いていただける仲間も募集中です!
今年もまだまだ組織規模拡大中なので、ご興味持っていただけましたらぜひお声がけください。