はじめに
GLB事業部Lakehouse部の阿部です。現地でのData + AI SUMMIT2023(DAIS)に参加した市村の報告をもとに、セッションの内容をまとめた記事を書きました。
今回は、Delta Live Tablesを使用したメタデータ駆動のデータパイプラインの構築方法についての講演を取り上げます。この講演は、DatabricksのMojgan Mazouchi氏とRavi Gawai氏によって行われました。
早速Delta Live Tablesの概要や、ユーザーがよく使用する機能について見ていきましょう。
Delta Live Tablesの概要と、ETL開発のためのツールとしての機能
Delta Live Tables(DLT)は、データパイプラインを効率的に構築するための新しい技術です。この講演では、DLTを使用したメタデータ駆動のデータパイプラインの構築方法が紹介されました。ETL(Extract, Transform, Load)開発のためのツールとして、以下のような機能が提供されています。
- バッチとストリーミングワークロードの統合
- インフラストラクチャの自動管理
- パイプラインの高品質を保証
これらの機能により、データエンジニアはデータパイプラインの開発や運用を効率化し、データ品質の向上に注力できます。

バッチとストリーミングワークロードの統合
DLTは、バッチ処理とストリーミング処理をシームレスに統合できます。これにより、データエンジニアは、バッチ処理とストリーミング処理を別々に管理する必要がなくなり、一元的にデータパイプラインを構築・運用できます。また、バッチ処理とストリーミング処理の両方をサポートすることで、データの取り込みや処理の遅延を最小限に抑えることができます。

インフラストラクチャの自動管理
予測不可能なデータセットのボリュームが存在する場合、またはパフォーマンスや厳密なSLAを満たす必要がある場合、クラスターのサイズの調整は難しいです。しかし、DLTを使用すると、最小値と最大値の間でインスタンス数を設定でき、設定に基づいてDLTは処理時のクラスター利用状況を元に、コンピューティングのスケーリングアップまたはスケーリングダウンが適切かどうかを判断します。この結果、過剰なプロビジョニングまたは過少なプロビジョニングを避けることができます。
パイプラインの高品質を保証
データ品質管理とモニタリングの機能を活用することで、パイプラインの信頼できるデータソースの作成が格段に容易になります。Expectationsと呼ばれる機能を使用すると、不要なデータが侵入することを防ぎ、パイプライン全体のすべてのデータ品質メトリックを集約できます。さらに、パイプラインのダイアグラム表示し、依存関係を追跡してデータを流れるすべてのテーブルを監視できます。
DLTメタアプローチとメタプログラミング
DLTフレームワークでは、主キーと特定の条件に基づいて挿入、更新、または削除できる行を指定できます。その宣言型APIであるapply changes intoは、暗黙的に順序を処理し、イベントが正しい順序で処理されることを保証する点でユニークです。さらに、スキーマ進化を可能にするAuto Loaderともうまく統合されています。
数百のテーブルで開発を拡大する場合、DLTフレームワークを使用したメタデータ駆動アプローチが使用できます。このアプローチでは、入力および出力メタデータ、データ品質ルール、およびSQLとしての変換ロジックをキャプチャできます。これにより、シルバーレイヤーとしてのエンリッチメントレイヤーが可能になります。
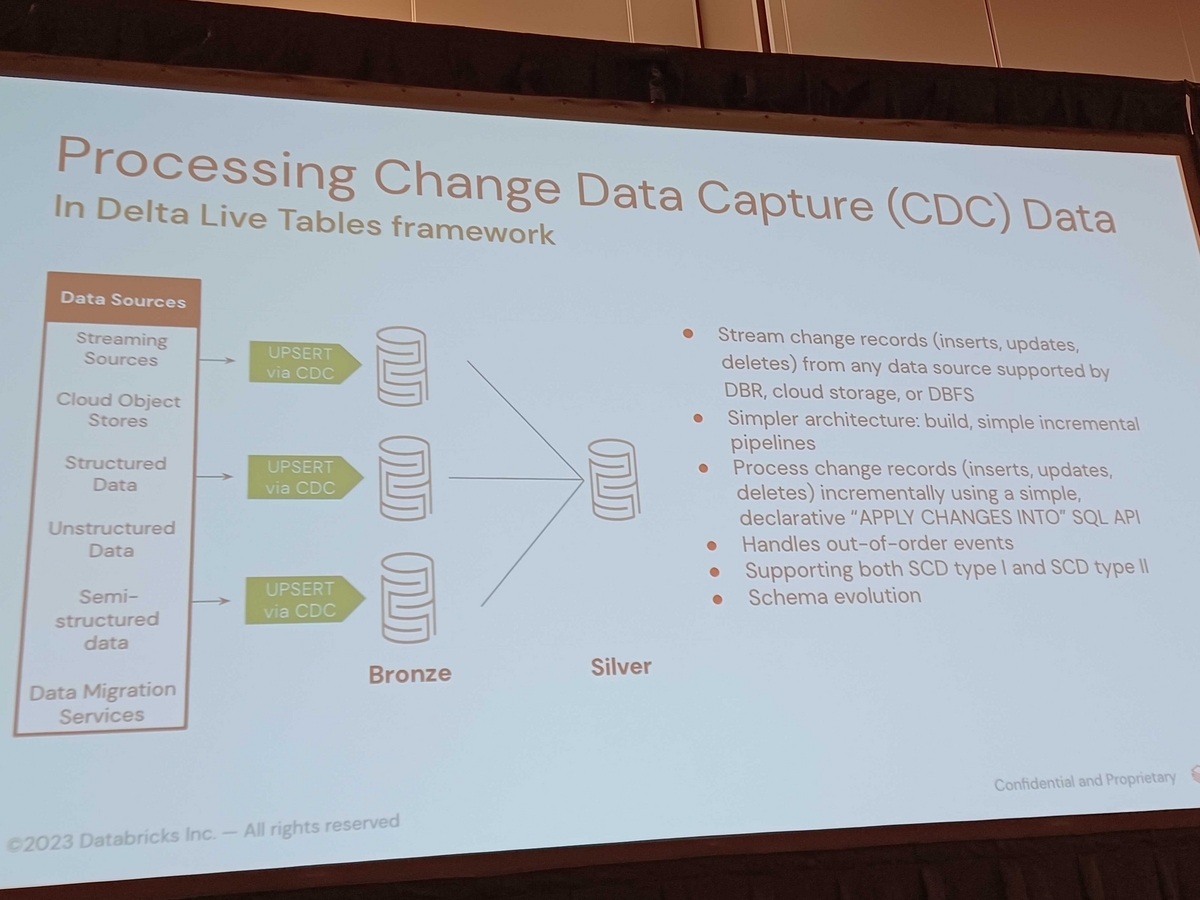
以下に例を示します。
まず、3つの主要な入力ファイルがあります。オンボーディングJSONファイル、データ品質ルールJSON、およびシルバートランスフォーメーションJSONロジックです。これらのファイルは、メタAPIによってメタデータ情報をデータフロースペックとして知られるDeltaテーブルに変換しています。
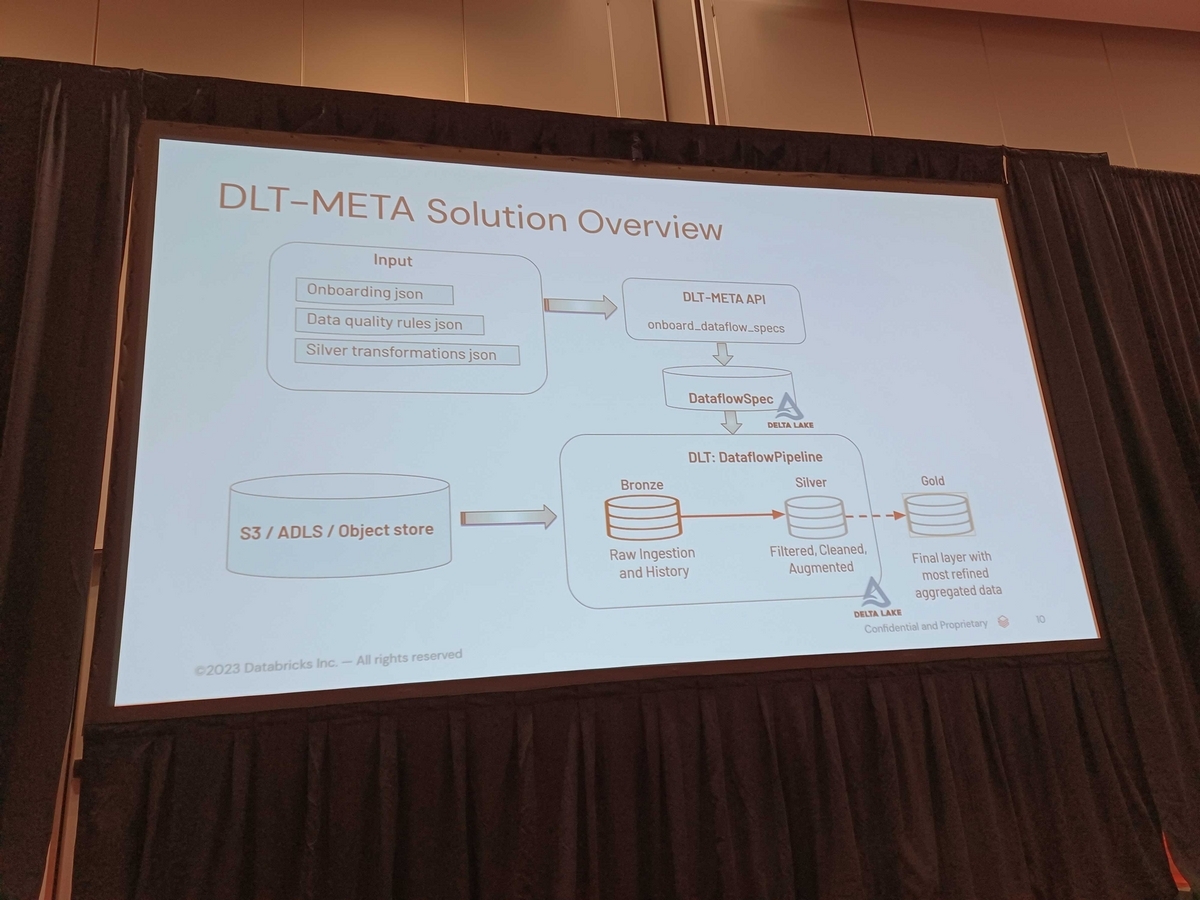
これにより、パイプラインを通過するデータの仕様がキャプチャされます。DLTメタAPIを使用することで、一般的なDLTパイプラインを生成して、パイプラインのブロンズ層とシルバー層の両方を作成できます。追加の集計が必要な場合は、ゴールド層の上にカスタマイズされた集計を構築できます。これは、DLTの優れた機能の一部です。
まとめ
Delta Live Tables(DLT)を使用したメタデータ駆動のデータパイプラインの構築方法は、データエンジニアにとって非常に有益です。バッチとストリーミングのワークロードの統合、インフラストラクチャの自動管理、データ品質管理とモニタリングのサポート機能により、データパイプラインの開発や運用が効率化され、データ品質の向上が実現されます。これにより、ビジネスユーザーはより正確なデータに基づいた意思決定を行うことができるようになります。
おわりに
現地でのDAIS参加メンバーからの報告をもとに、セッションの内容を解説しました。セッションに関する記事を以下の特設サイトに順次上げていきますので、見ていただけると幸いです。
https://www.ap-com.co.jp/data_ai_summit-2023/
引き続きどうぞよろしくお願いします!
