
Introduction
This is Abe from the Lakehouse Department of the GLB Division. This article is a continuation of Dolly's previous chatbot build using dbdemos.
We hope that moving Dolly will be a reference for prompt engineering and LLM learning. This article is based on the following notebooks on dmdemos.
03-Q&A-promt-engineering-for-dolly
table of contents
- Introduction
- table of contents
- Overview of this demo
- Preparation
- Use chains to answer simple questions
- Check the behavior of prompts and answers to questions
- Distributed processing for Question Answering using Spark
- Reference articles
- Conclusion
Overview of this demo
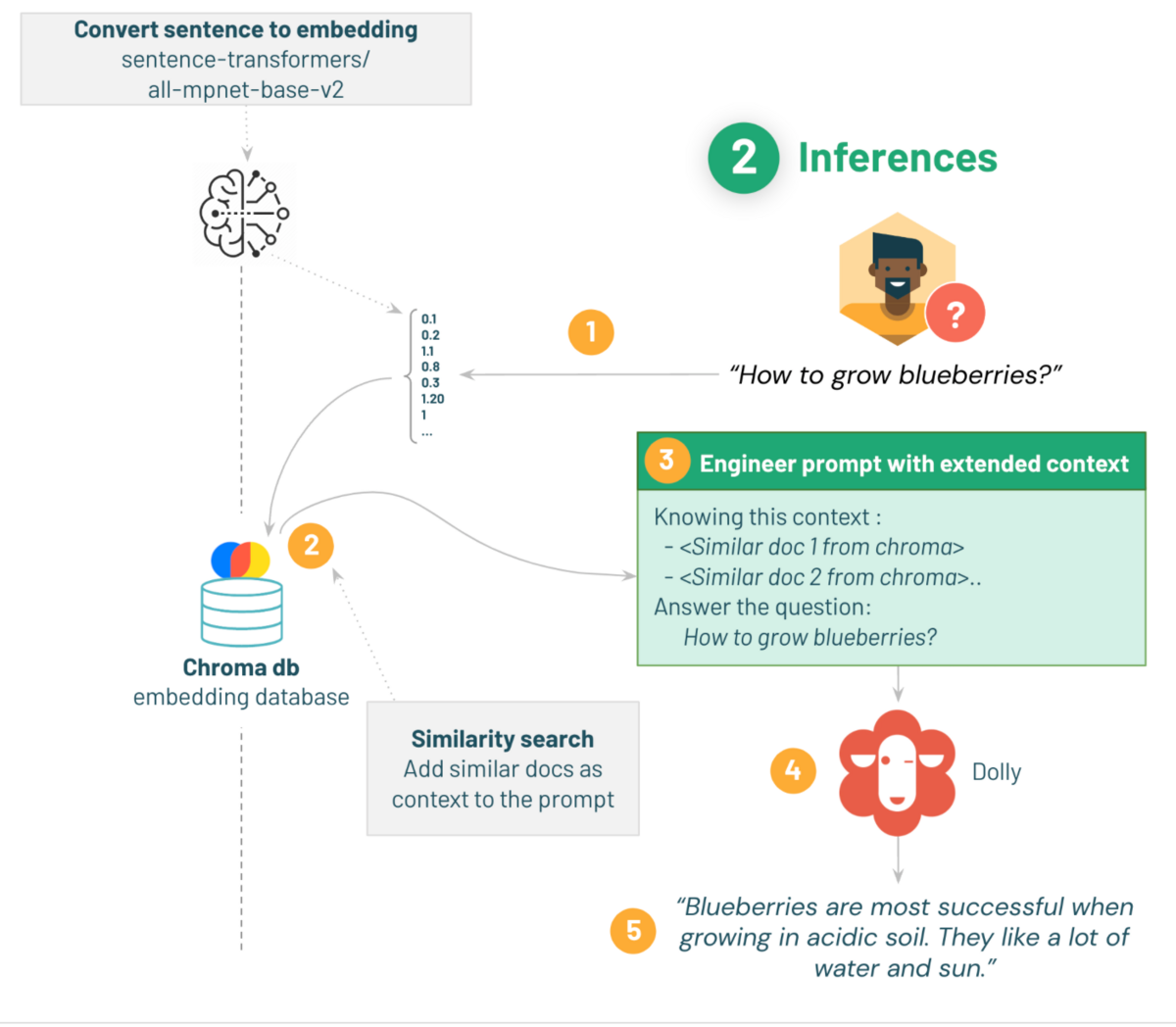
In this demo, prompt engineering is performed using langchain and Dolly 2.0 loaded from Hugging Face is used to answer frequently typed questions in a chatbot. The demo concludes with an introduction to how Apache Spark can be applied to answer not just one question, but many.
The demo proceeds as follows:
1. Embed the acquired questions using the same embedding model as when preparing the Q&A dataset.
2. Perform a similarity search with the acquired question for the chroma document and find similarity.
3. Do a Prompt Template that includes the question and similar documents as context.
4. Pass the templated prompt to dolly.
5. Get gardening advice for questions.
The cluster I used uses the cluster created when setting up dbdemos.
- Databricks Runtime Version: 13.0ML
- Node type: StandardStandard_NC8as_T4_v3(56GB Memory, 1GPU)
As will be described later, if a memory error occurs in the middle, you need to change to a GPU cluster with a larger memory.
Preparation
First, install the necessary libraries.
%pip install -U transformers langchain chromadb accelerate bitsandbytes
Put variables in catalog and db as in the previous article and define catalog and DB.
%run ./_resources/00-init $catalog=hive_metastore $db=dbdemos_llm

After loading the embedding model from Hugging Face, load Choromadb, the vector database created in the previous article.
# Start here to load a previously-saved DB from langchain.embeddings import HuggingFaceEmbeddings from langchain.vectorstores import Chroma if len(get_available_gpus()) == 0: Exception("Running dolly without GPU will be slow. We recommend you switch to a Single Node cluster with at least 1 GPU to properly run this demo.") gardening_vector_db_path = "/dbfs"+demo_path+"/vector_db" hf_embed = HuggingFaceEmbeddings(model_name="sentence-transformers/all-mpnet-base-v2") db = Chroma(collection_name="gardening_docs", embedding_function=hf_embed, persist_directory=gardening_vector_db_path)
A single-node cluster with a GPU is recommended for this demo, so an error message will be displayed if the GPU is not used.
As a test, ask a simple question to extract similar documents in the vector database.
A similarity search is db.similarity_search() done in a method where question specifies the text to search for and k (similar_doc_count)specifies the number of similar documents to return.
def get_similar_docs(question, similar_doc_count): return db.similarity_search(question, k=similar_doc_count) # Let's test it with blackberries: for doc in get_similar_docs("how to grow blackberry?", 2): print(doc.page_content)
Below you will find documents similar to "how to grow blackberry?"
I have a breed of blackberry bush in my backyard that is unlike any other blackberries I've had in the past and I'd very much like to plant more just like it. What part of the plant do I need to plant to make a new bush and what's the best way to do this? Added photo as requested: If we're talking about commonly referred to Rubus, most plants in the genus can be propagated 3 ways, by cuttings, by sectioning off suckers - the easiest if there are suckers present already, or by tip layering - burying the tip of a stem a few inches below ground to encourage the plant to produce a sucker. On a whim, I bought a pair of plants for my container garden. They were labelled raspberry and blackberry; however, I'm not certain about the blackberry plant. The blackberry that used to grow by my old house looked a lot more like the raspberry than the blackberry I just bought: (Now that I look at it again that's a terrible photo. I can take a better one if you want.) Obviously that raspberry plant is going to want a trellis, and they'll both need bigger pots. But will the blackberry also want a trellis? Or will it grow into more of a bush shape? When you plant them, be sure that they are no deeper than they were before. Use a porous, well drained potting mix, and water deeply. The blackberry is going to need a trellis, as well as the raspberry. You should use no less than 25 gallons of soil for each plant in the permanent container, but you can gradually get there if you want, by repotting into a pot one size larger every couple months during the growing season until you reach full size. You should also fertilize every other week with a balanced fruit and flower fertilizer (like 12-14-10).
This time, two sentences are returned after a similarity search, and the second similar document starts from the third paragraph, “On a whim.”
langchain Let's create a chain by combining LLM and Prompt Template .
A chain is for connecting models, prompts, and chains and handling them as a single unit.
Prompt Template is a function that makes a prompt a template by making a part of the prompt variable as needed. Other Prompt Templates include FewShotPromptTemplate
, which includes several demonstration (few-shot) examples such as question and answer examples in the prompt, and ChatPromptTemplate, which is a template for chat models . By the way, you can also read prompt templates from LangChain official GitHub.
The code below is a function that returns the chain created after executing the Prompt Template.
from transformers import AutoTokenizer, AutoModelForCausalLM, pipeline import torch from langchain import PromptTemplate from langchain.llms import HuggingFacePipeline from langchain.chains.question_answering import load_qa_chain def build_qa_chain(): torch.cuda.empty_cache() model_name = "databricks/dolly-v2-3b" # can use dolly-v2-3b or dolly-v2-7b for smaller model and faster inferences. instruct_pipeline = pipeline(model=model_name, torch_dtype=torch.bfloat16, trust_remote_code=True, device_map="auto", return_full_text=True, max_new_tokens=256, top_p=0.95, top_k=50) # 注意: ドリー12B以下のモデルを使用しているが、24GB以下のRAMを持つGPUを使用している場合、8bitを使用してください。これには %pip install bitsandbytes が必要です。 # instruct_pipeline = pipeline(model=model_name, load_in_8bit=True, trust_remote_code=True, device_map="auto") # T4やV100のようにbfloat16をサポートしていないGPUでは、以下のようにtorch_dtype=torch.float16を使用してください。 # model = AutoModelForCausalLM.from_pretrained(model_name, device_map="auto", torch_dtype=torch.float16, trust_remote_code=True) # プロンプトのテンプレートを定義する。 template = """Below is an instruction that describes a task. Write a response that appropriately completes the request. Instruction: You are a gardener and your job is to help providing the best gardening answer. Use only information in the following paragraphs to answer the question at the end. Explain the answer with reference to these paragraphs. If you don't know, say that you do not know. {context} Question: {question} Response: """ prompt = PromptTemplate(input_variables=['context', 'question'], template=template) hf_pipe = HuggingFacePipeline(pipeline=instruct_pipeline) # Set verbose=True to see the full prompt: return load_qa_chain(llm=hf_pipe, chain_type="stuff", prompt=prompt, verbose=True)
By using the PromptTemplate() method, the prompt is templated with context and question as variables.
The load_qa_chain() method is used at the end of the code to chain the LLM and the prompt together.
About the loaded Dolly model ::
Dolly is downloaded using the pipeline class, but considering the speed and memory of inference
It calls dolly-v2-3b which has the fewest number of parameters.
As a background, the memory of the cluster prepared for demonstration is 56 GB, but a memory error occurred when reading the memory of 7b, so I decided to call the 3b model.
Arguments for the pipeline class are also listed here.
- return_full_text: Specifies whether to include the prompt in the output results in addition to the generated text.
- max_new_tokens: Specifies the maximum number of tokens in the generated text.
- top_p: Specifies the probability threshold used when generating tokens.
- top_k: Select only k tokens with the highest probabilities when generating tokens.
load_qa_chain() method argument.
- llm: llm used for answer
- chain_type: You can specify how chunks are processed by LLM.
Here, stuff we specify that chunk splitting is not performed, and all context is passed to the prompt and input to LLM.
- verbose: True makes the whole preprocessing and prompt visible.
build_qa_chain()to load Dolly and build the chain.
qa_chain = build_qa_chain()
This process takes a long time, nearly 10 minutes in my environment.
Use chains to answer simple questions
Define the processing up to this point as a function and output in HTML format.
I have defined a function that retrieves the question and related similar documents from a vector database and returns them in HTML format, answering the question with the source of the answer.
def answer_question(question): similar_docs = get_similar_docs(question, similar_doc_count=2) result = qa_chain({"input_documents": similar_docs, "question": question}) result_html = f"<p><blockquote style=\"font-size:24\">{question}</blockquote></p>" result_html += f"<p><blockquote style=\"font-size:18px\">{result['output_text']}</blockquote></p>" result_html += "<p><hr/></p>" # 水平線を表示 for d in result["input_documents"]: # 類似文書の内容を取り出す source_id = d.metadata["source"] # 類似文書のメタデータであるsourceを取り出す result_html += f"<p><blockquote>{d.page_content}<br/>(Source: <a href=\"https://gardening.stackexchange.com/a/{source_id}\">{source_id}</a>)</blockquote></p>" displayHTML(result_html)
Questions, answers, and similar documents inserted as context at the end are displayed in HTML format.
Check the behavior of prompts and answers to questions
Thank you for waiting for a long time. Ask a question and check the answers.
answer_question("What is the best kind of soil to grow blueberries in?")
You can see that the context db.similarity_search returns two documents similar to the query.
Now, let's check the answers specified in HTML format that are output at the same time.
> Entering new StuffDocumentsChain chain... > Entering new LLMChain chain... Prompt after formatting: Below is an instruction that describes a task. Write a response that appropriately completes the request. Instruction: You are a gardener and your job is to help providing the best gardening answer. Use only information in the following paragraphs to answer the question at the end. Explain the answer with reference to these paragraphs. If you don't know, say that you do not know. What are the best soil amendments for blueberries grown in containers? What's the best mulch? Last year I used chopped leaves from a friend's landscaping job that is no longer around. I also remember hearing about adding coffee grounds to the soil to help with acidity. I haven't tested the soil yet, but have a bunch of coffee grounds from a local coffee shop. Do they raise the ph so much that I shouldn't add them if I haven't tested the soil? A good soil mix for pot grown blueberries is a porous, acidic mix high in organic matter. A good mix could be made by mixing these materials by weight: 5/8 topsoil 2/8 peat moss 1/16 vermiculite 1/16 coarse sand Plus some slow release plant food. To help with the acidity, mix 1/4 pound of aluminum sulfate into the top 6" of soil. There are several mulches that fit the needs of the blueberry bushes. Bark mulch is acidic, long lasting and attractive. Also, shredded wood, aged sawdust, and pine straw are good mulches. Coffee grounds are only very slightly acidic, so they will not be useful in maintaining ph. But they do make good compost, and if composted with an acidic material high in carbon, such as the mulching materials mentioned above, they would make an excellent mulch that would feed the plants and help maintain soil ph. I've got a blueberry in a pot that was repotted without amending the soil. Now it seems to be growing okay but rather then repotting it again, I'm wondering if I can apply a coffee grounds mulch while it still has a few berries, and i mean only a very few berries compared with the numbers on it when i bought it just on a year ago. Or should I wait? I haven't tested the soil pH, and I don't use tap water for watering, but fish water from my gold fish. I did put some citrus fertiliser on it once late last year, and we're now in mid summer. Amendments for blueberries in the fall. Goldfish pond water is probably good because the organic material in the water lowers the ph some. However blueberries like acidic soil. They grow under the canopies of great trees in the wild which keeps the soil pretty acidic. Blueberries also like lots of water. You want a very loose humus that will dump all the water and not stay wet, but you need to water often. Question: What is the best kind of soil to grow blueberries in? Response: > Finished chain. > Finished chain.
In context, you can see that two documents similar to the query are returned by db.similarity_search.
Now, let's check the answers specified in HTML format that are output at the same time.

Below the question title is the answer, and below the horizontal line are two similar documents and the source.
Distributed processing for Question Answering using Spark
So far, we have implemented LLM, which is often used in chat bots, to return an answer to one question. Here, I will also introduce another way to use Spark to perform distributed processing and answer multiple questions.
Note
Since the dataset in question is not that large, I am using a single-node GPU cluster to process it,
The use of multi-node GPU clusters is assumed as the number of questions increases and the processing time increases.
The code below defines a Spark UDF to answer a dataframe of questions.
from pyspark.sql.functions import pandas_udf import pandas as pd from typing import Iterator import os @pandas_udf('answer string, sources array<string>') def answer_question_udf(question_sets: Iterator[pd.Series]) -> Iterator[pd.DataFrame]: os.environ['TRANSFORMERS_CACHE'] = hugging_face_cache hf_embed_udf = HuggingFaceEmbeddings(model_name="sentence-transformers/all-mpnet-base-v2") db_udf = Chroma(collection_name="gardening_docs", embedding_function=hf_embed_udf, persist_directory=gardening_vector_db_path) qa_chain_udf = build_qa_chain() for questions in question_sets: responses = [] for question in questions: # k is the number of docs to retrieve to feed as context similar_docs = db_udf.similarity_search(question, k=2) result = qa_chain_udf({"input_documents": similar_docs, "question": question}) responses.append({"answer": result["output_text"], "sources": [str(d.metadata["source"]) for d in result["input_documents"]]}) yield pd.DataFrame(responses)
The series of processing so far is defined as a UDF, and it is defined to answer a data frame of multiple questions. Load the saved question dataframe "gardening_dataset" and repartition it. The number of repetitions matches the number of nodes during distributed processing, but this time we will proceed with a single node, so set it to "1".
For distributed processing, use a multi-node cluster and specify the number of repartitions to match the number of nodes.
new_questions_df = spark.table("gardening_dataset") \ .filter("parent_id IS NULL") \ .select("body") \ .toDF("question") \ .limit(10) #Saving a subset of question to answer for faster processing new_questions_df.repartition(1).write.mode("overwrite").saveAsTable("question_to_answer") new_questions_df = spark.table("question_to_answer").repartition(1) # Repartition to number of GPUs (multi node or single node with N gpu) display(new_questions_df)
Display the dataframe of the loaded question.

Then for each question create a new column with the answer and its source.
response_df = new_questions_df.select(col("question"), answer_question_udf("question").alias("response")).select("question", "response.*") display(response_df)

You can see that even for multiple questions, the sources and answers of similar documents (Questions) extracted from the vector database are returned.
This is the end of building the chatbot.
Thank you for reading my previous article. However, chatbots need to memorize past conversations in order to answer based on the content of the conversation. One of the features that makes this possible is LangChain's memory. In the next article, I would like to introduce LangChain's memory to the chatbot built in this demo and build a chatbot.
Reference articles
Getting Started with Huggingface Transformers (6) - Text Generation
LangChain HOW-TO EXAMPLES (4) - Data Augmentation Generation
Improve accuracy and stability by doing Chunk division and ChainType with Langchain
Conclusion
In this article, I explained the flow from inserting similar documents retrieved from the vector database into the prompt as context and answering.
Since LangChain, the LLM library, is regularly updated, it is possible that the code used this time will not be usable in the future. In that case, please refer to the official documentation of LangChain.
Thank you for readinguntil the end. We provide a wide range of support, from the introduction of a data analysis platform using Databricks to support for in-house production. If you are interested, please contact us.
We are also looking for people to work with us! We look forward to hearing from anyone who is interested in APC.
Translated by Johann