
FreewheelとBizWaxの紹介
おはようございます。この会議の最初のセッションの一つにご参加いただきありがとうございます。本日のトピックは、Databricksを使用した大規模なストリーミングアプリケーションの移行と最適化についてです。詳細に富んだ本日のセッションを進めていく中で、Freewheelのリードソフトウェアエンジニアであるシャリフ・ドグミとドンフイ・リが主なプレゼンターとなります。
彼らは今日、広告業界で重要な役割を果たしているFreewheelとBizWaxについての広範な概要を提供します。Freewheelは、様々なプラットフォームにわたる強力な広告ソリューションを提供することで、デジタルメディア広告とリニアメディア広告との間のギャップを効果的に埋める主要な企業です。一方、BizWaxはリアルタイムの広告データ分析に優れ、強力な広告戦略を形成する洞察を提供します。
このセッションでは、これら二つのエンティティがどのようにしてシームレスに協力して膨大な量の広告イベントデータを管理・処理し、最適化されたパフォーマンスと精度を達成しているのかを詳しく調べます。私たちは彼らの広告セクター内での重要な役割を探求し、彼らの革新的な技術使用が優れたデータ取り扱いと広告配信プロセスをどのように促進するかについて議論します。
今日共有される洞察は、リアルタイムデータ処理に伴う技術的複雑さと運用上の課題をさらに明らかにし、FreewheelとBizWaxの技術的統合がダイナミックな広告ソリューションを可能にする方法を強調します。
「Migrating and Optimizing Large-Scale Streaming Applications with Databricks」と題されたセッションでは、Beeswaxデータプラットフォームのアーキテクチャに重点が置かれました。この探求は、広告イベントの膨大なボリュームを処理および扱う複雑さを理解するのに役立ちます。このセッションからの洞察に基づいて、このアーキテクチャのコンポーネントと機能を探求しましょう。
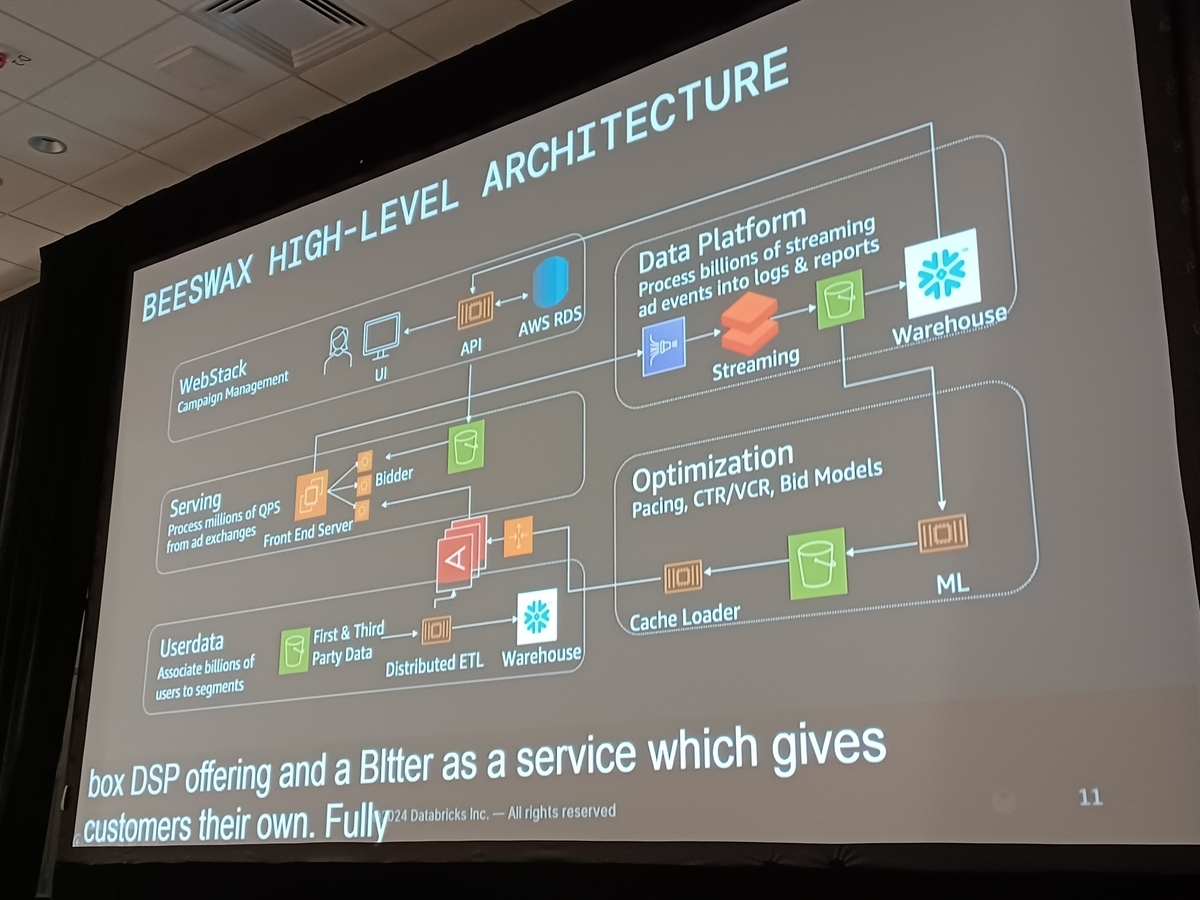
Beeswaxデータプラットフォームアーキテクチャ
Beeswaxデータプラットフォームの初期アーキテクチャは、主にImpressions、Clicks、Activities、Conversionsとして分類されるポストオークションイベントを含むさまざまな広告イベントを効率的に管理するように設計されました。これらは通常、勝利イベントとして言及されます。
- ImpressionsとClicks: これらのイベントは、広告が表示された頻度またはクリックを通じてどの程度相互作用があったかを記録します。これらはリアルタイム処理に不可欠で、広告の効果を測定するための重要なデータを提供します。
- Activities: Activitiesは、ビデオ広告とユーザーの相互作用、例えばビデオの一時停止、再開、または巻き戻しを表します。これらのアクションの監視は、広告とのエンゲージメントレベルを分析するために重要です。
- Conversions: これらのイベントは、ユーザーが購入のような望ましい行動を取ることに成功したことを示します。Conversionsは通常、かなりの遅延の後に発生し、正確なキャプチャのためにリアルタイムとバッチ処理の混合が必要です。
プレゼンテーション中に使用された視覚的な図は、Beeswaxデータプラットフォームがさまざまな種類のデータを数多くの目的地にどのように処理およびルーティングするかの明確な描写を提供するために使用されました。これらのグラフィック表現は、複雑な構造を描写する際にテキストだけよりもしばしば効果的です。
セッションではまた、移行前および移行後のBeeswaxデータプラットフォームのアーキテクチャも取り上げられ、最適化プロセスに光を当てました。これらのアーキテクチャ要素を理解することで、そのような広範なプラットフォームの複雑なデータ管理要件に対する私たちの評価が深まります。
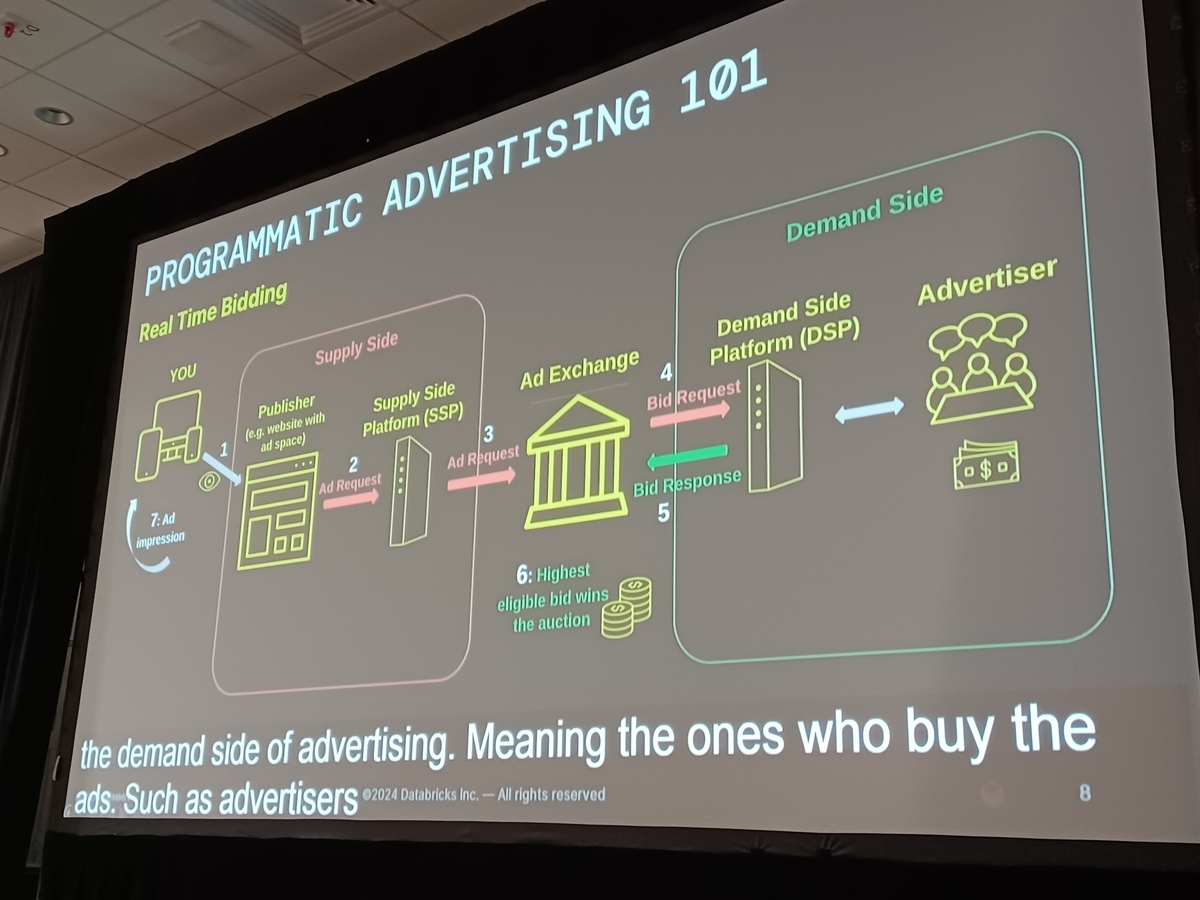
Databricksへの移行に関する詳細な説明
もともとWaggleとして知られていたアプリケーションは、Java KCL(Kinesisクライアントライブラリ)を使用し、外部サービスによる管理が組み込まれたAWS EC2クラスター上で運用されていました。Databricksへの移行は、私たちのデータ処理プロセス内で重要な変革をマークします。
現在、システムのアップグレード版であるWaggleは「Waggle V2」と名付けられています。この新バージョンは、以前のKinesisクライアントライブラリの代わりにSpark Structured Streamingを利用しています。Spark Structured Streamingへの移行は、データ処理速度の向上だけでなく、全体的な効率の向上も促進します。
Waggle V2は、私たちのAWS環境内に位置するDatabricks Classicインフラストラクチャの下で運用されています。この設定により、より大きな制御とカスタマイズが可能になり、管理作業が簡素化されます。さらに、Waggle V2をDatabricksのサーバーレスコンピューティングモデルに移行することを検討中です。サーバーレス構造を採用することで、リソース管理をさらに簡素化し、運用コストを削減することが可能です。
Databricksがサーバーレス機能を拡張してストリーミングワークフローを効果的にサポートする場合、特にスケーラビリティとコスト効率の面で大きな利点を提供するでしょう。
Databricksへの切り替えにより、私たちのデータ処理メカニズムが大幅に改善されました。それにより、よりタイムリーかつ正確なリアルタイムアナリティクスと、より豊かなバッチレポーティングが可能になりました。さらに、データを多様な送信先にルーティングする能力が顕著に強化されました。この改善は、本質的に、私たちのストリーミングアプリケーションの全体的なパフォーマンスと多用途性を向上させました。

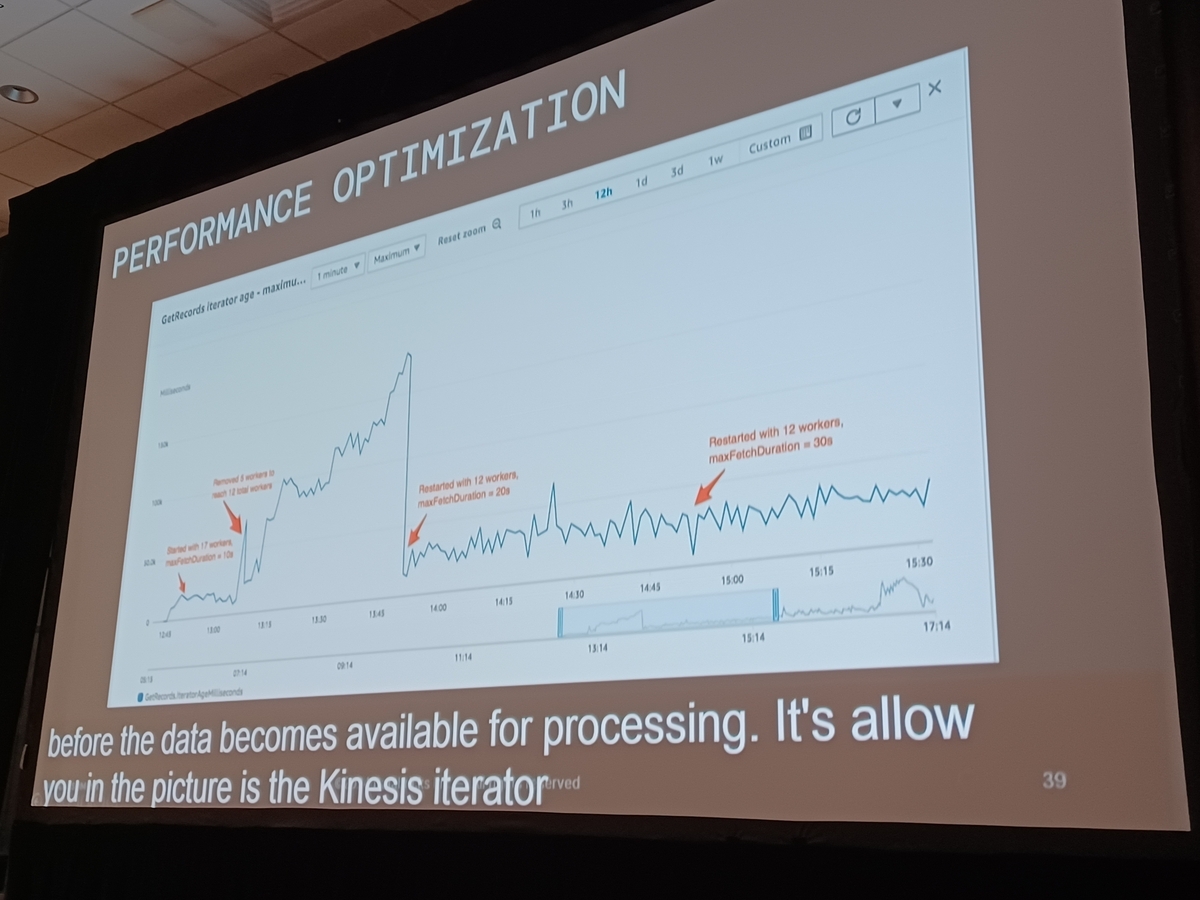
パフォーマンス最適化テクニック
「Databricksを使用した大規模ストリーミングアプリケーションの移行と最適化」というセッションで強調されたように、大量のリアルタイムデータを処理するためのパフォーマンスを向上させる方法に焦点が当てられています。この議論では、大規模ストリーミングアプリケーションを効果的に最適化するための具体的な戦略が提供されました。以下に、処理能力を顕著に向上させる方法を詳述します:
1. Spark StreamingとKinesis Stream
Kinesis StreamからSpark Streamingを使用してデータフレームを効率的に取得することは、大規模なリアルタイムデータフローを管理する上で基本的なステップです。このステップは、最適で遅延のないデータフレームを生成することにより、パフォーマンスを保証し、スムーズなデータ処理環境を維持するために重要です。
2. DataStreamWriterの設定
ストリーミングデータフレームを使用したDataStreamWriterオブジェクトの適切な設定が、パフォーマンスチューニングにおける重要な役割で強調されています。具体的なトリガー間隔を設定することで、例えば60秒間隔で各マイクロバッチをターゲティングすることにより、運用要件とパフォーマンス目標に基づいて柔軟に調整することが可能です。このカスタマイズされた設定は、データスループットと処理効率の微調整に役立ちます。
3. ForEachBatchメソッドの利用
セッションでは、ForEachBatchメソッドの適用について詳細に説明されました。これは、専用のストリーミングシンクがストレージシステムに存在しない場合や、データを複数の目的地にルーティングする必要がある場合に特に有利です。ForEachBatchメソッドは、他の関数を引数として受け入れることができる高次メソッドとして機能し、動的かつ効率的なデータ操作のカスタマイズを容易にします。この方法内で無名関数を使用することにより、ストリーミングデータフレームからバッチデータフレームへの変換機能を可能にし、ストリーミング操作に関連する典型的な制限を克服します。
これらの戦略は、大規模ストリーミングアプリケーションのパフォーマンスを強化するだけでなく、さまざまなリアルタイムデータ処理シナリオでのスケーラビリティや適応性を保証します。これらの最適化テクニックは、リアルタイム分析とレポートを業務に大きく依存している企業にとって重要です。
Databricksの将来の拡張機能について
最近のセッションでは、開発効率を向上させ、利便性を高める新機能に関する多くの興味深い更新がありました。Databricksは、開発体験を進化させることにより、次世代のデータ処理プラットフォームとしての地位を固めています。
DataFrame API
まず、セッションではDataFrame APIの使いやすさに焦点を当てました。このAPIは、バッチおよびストリーム処理アプリケーションのための統一されたシンプルなインターフェースを提供します。さまざまなデータソースやストレージシステムとシームレスに統合することができます。
Databricks Terraformプロバイダ
さらに、Databricks Terraformプロバイダについて議論がありました。このプロバイダを使用することで、インフラストラクチャとリソースをコードを通じて迅速かつ容易に定義することができます。インフラの設定からリソースの管理まで、コードベースを通じて行うことには大きな利点があります。
Databricks Asset Bundles
セッションで紹介された新機能の1つがDatabricks Asset Bundlesです。これはCI/CD機能で、インフラストラクチャとしてのコード(IAC)アプローチを採用しています。YAMLファイルを使用してジョブ、ノートブック、その他のプロジェクトアーティファクトを定義し、CLIツールを使用して簡単にデプロイ、実行、管理することができます。
Databricks IQパワード機能
また、AI技術を使用したDatabricks IQの機能強化も披露されました。DatabricksアシスタントやAI生成コモンズなどの技術は、開発体験をさらに洗練させるためにAIを利用しています。
これらの強化により、Databricksはさらに強力でユーザーフレンドリーなプラットフォームへと進化し続けるでしょう。これらの機能が開発環境で直面する課題をどのように解決するかを見るのが楽しみです。このセッションで学んだことを活用して、これらの機能をプロジェクトに取り入れてください。

Databricks Data + AI Summit(DAIS)2024の会場からセッション内容や様子をお伝えする特設サイトをご用意しました!DAIS2024期間中は毎日更新予定ですので、ぜひご覧ください。
私たちはDatabricksを用いたデータ分析基盤の導入から内製化支援まで幅広く支援をしております。
もしご興味がある方は、お問い合わせ頂ければ幸いです。
また、一緒に働いていただける仲間も募集中です!
APCにご興味がある方の連絡をお待ちしております。