
レガシーシステムに関する課題についての洞察
皆さん、こんにちは!セッション「UdemyのデータとAIの旅:管理されたビッドデータプラットフォームからDatabricksへの移行」では、古いシステムを扱う難しさについて掘り下げました。この最初のセクション「レガシーシステムの課題」では、Udemyが直面した困難とその戦略的対応を強調しています。
1. 古いシステムからの移行
Udemyは以前のシステムで、データ管理が単一の形式に限定される大きな障壁に直面しました。MyCBC 4.8からMyCBC 5.5へのアップグレード努力は、S3への適応の複雑さをもたらしました。オンプレミスからEMR 5への一時的な成功はありましたが、根本的な問題を解決することはできませんでした。
2. クラスターの問題と影響
クラスターを自動スケーリングで管理するアプローチは、AC2の静的リソースに厳しく制限され、必要な柔軟性が制限されました。これはデータ管理の効率を大幅に制限しました。
3. 古いアプリケーションとノイジーネイバーシンドローム
HiveやScoopのような古いアプリケーションの継続的な使用は、「ノイジーネイバーシンドローム」を引き起こし、リソース競合を引き起こし、システムパフォーマンスに深刻な影響を与えました。これらの問題に対処するため、先進技術が明らかに必要でした。
このセッションを通じて、Udemyがレガシーシステムに束縛されることなく、データ民主化を促進するための近代技術の活用に向けて積極的に進んでいることが明らかになりました。次のセクションでは、この移行が彼らのデータ管理と分析をどのように革命的に変えたかを探ります。お楽しみに!
評価と意思決定プロセス
高品質な学習体験を保証するために、Udemyは評価プロセスにかなりの時間を投資し、Databricksの採用について情報に基づいた決定を下す上で重要であることが証明されました。この広範な評価はなぜ必要だったのでしょうか?

コストに関する懸念
Databricksを検討し始めた初期段階では、コストが重要な懸念事項でした。AWS Lambdaのようなサーバーレスソリューションと比較して、Databricksは従来のインフラを採用しており、初めはコスト効率が低いと感じられました。しかし、総保有コスト(TCO)の評価により、長期的な利益が初期コストを上回る可能性が明らかになりました。
Airflowに関する懸念
評価プロセスのもう一つの重要な側面は、データワークフローを自動化し、オーケストレーションするために不可欠なツールであるAirflowを中心に展開されました。主要な懸念事項は、Databricksへの移行がその利用にどのように影響を与え、統合がスムーズに進むかどうかでした。
コストの影響と技術的な互換性の両方を入念に評価した結果、UdemyはDatabricksが提供する機能が彼らのニーズとよく合致していると結論付け、移行を決定しました。
この徹底的な調査と意思決定プロセスは、Udemyが複雑さを乗り越えてデータ管理とAI能力を最適化する方法をどのように管理したかを浮き彫りにし、データの民主化を推進しました。リアルタイムデータ処理と分析の向上は、Udemyの教育提供をさらに強化することになります。
UdemyのDatabricksへの移行戦略と実装
Udemyが管理された大規模データプラットフォームからDatabricksへの移行を戦略的に決定したのは、データアクセスの向上と分析の民主化を目指すためでした。このセクションでは、移行戦略と実装中に行われた具体的なステップについて概説します。
主要な移行戦略
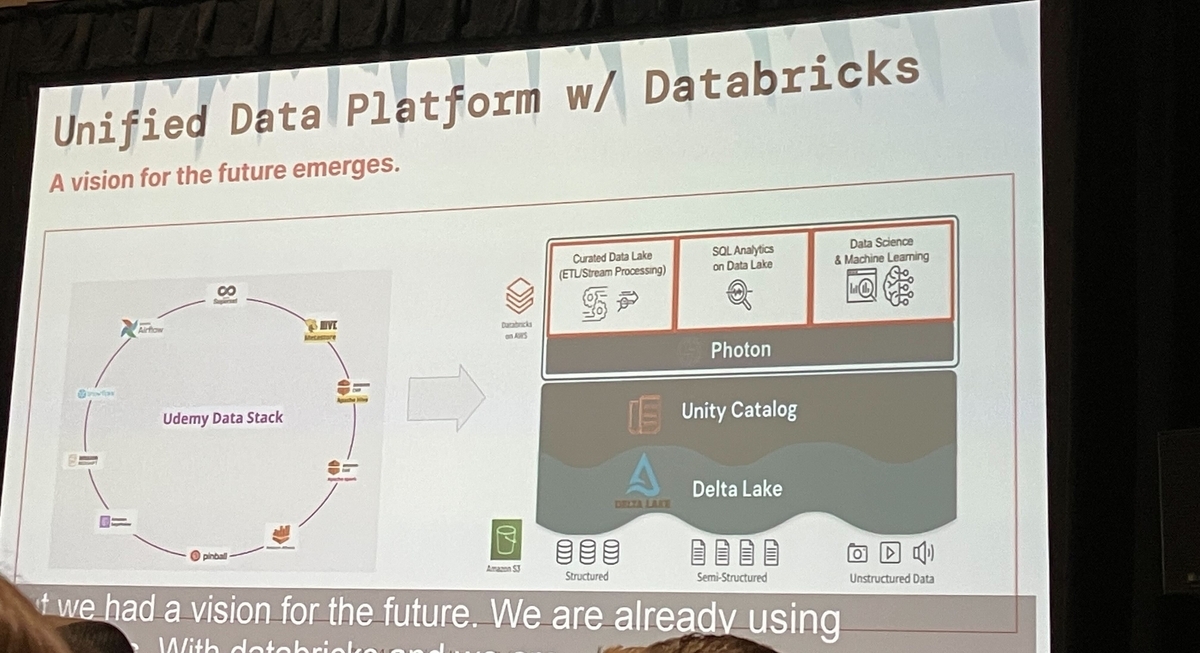
移行の焦点は、Unity Catalog、DBSQL、Delta LakeなどDatabricksの高度な機能を活用して、データ管理と分析能力を大幅に向上させることでした。これらの機能は、幅広いデータワークフローをサポートし、堅牢なデータガバナンスを確保する上で重要でした。
実装の詳細
実装フェーズを通じて、Databricksが提供する専門知識とサポートが重要でした。注目すべき改善点には、最適化されたSparkパフォーマンスと、統一カタログによって容易にされた協力とガバナンスの強化が含まれます。
現在、このプラットフォームは約500ユーザーをサポートしており、Databricksのスケーラビリティと効率の高さを示しています。サポート負担の削減は、Udemyチームにとって大きな利点でした。
課題に対処し、新機能を迅速に統合するために、問題の迅速な解決を可能にするシステムが確立されました。オフィスアワーと主題の専門家の専門知識を組み合わせることで、コンセプト(POC)の検証についてより深く掘り下げることが可能になりました。さらに、組み込みAI機能の統合がこれらの努力を支援する上で重要な役割を果たしています。
サポート構造
チームは、Spark 5内の24時間健康サポートから大いに恩恵を受けており、ログ情報への簡単なアクセスが提供されています。このセットアップは、運用上の問題に対する迅速な対応を保証し、プラットフォームの信頼性と効率を高めます。
サポート負担を絶えず軽減し、組み込みAIシステムとDatabricksの専門知識を活用することで、Udemyは現在のニーズに応えるだけでなく、将来の拡張にも対応可能なより強固なデータプラットフォームへの移行に成功しました。
ここでは、UdemyがどのようにしてDatabricksに成功裏に移行したか、特に「自動化と最適化」という観点から、データ管理や分析アプローチがどのように一新されたかに焦点を当てて詳しく説明します。

自動化と最適化の進化
以前は管理されたビッグデータプラットフォームに依存していたUdemyは、Databricksへの移行により、顕著な改善を遂げました。最も注目すべき向上点は、データ移行タスクの自動化とプロセスの最適化に関わるものでした。
マイグレーショントラッカーの利用: 移行プロジェクト中、動的に更新されるマイグレーショントラッカーが使用されました。この重要なツールは、どのテーブルが移行されたか、そしてその状態が成功か失敗かを記録しました。
自動化された状態チェック: テーブルが既に移行されているかどうかを確認するプロセスは、Sparkを使用して自動化されました。これには、不必要な処理を省略することで効率を最適化することが含まれます。
実行時間の加速: これらの自動化と最適化を実装することで、Sparkアプリケーションの実行時間は以前の3分の1に短縮されました。この短縮は、移行プロセスの効率向上を示しています。
Databricksの機能を活用することで、Udemyは自動化と最適化の顕著な進歩を遂げ、より効果的なデータ管理と分析を実現しました。成功は、移行プロセスの継続的な監視と更新にかかっています。移行後も、Udemyの改善と最適化への取り組みは強力に続いています。

結論
Databricksへの移行は、Udemyにとって単なるプラットフォームの切り替え以上のものでした。それは、データアクセスと処理速度を大幅に改善する敏捷性と自動化されたフレームワークを可能にしました。この変革は、データをより熟練して利用するUdemyの能力を高めただけでなく、運用ワークフローを合理化し、加速しました。Udemyの戦略的なDatabricksへの移行は、洗練された技術統合を通じてデータ戦略を大幅に改革しようと計画している他の企業にとって重要な青写真として機能します。この旅は、データとAIの真の可能性を完全に活用するために、自動化と最適化の改善が継続的に必要であることを強調しています。

Databricks Data + AI Summit(DAIS)2024の会場からセッション内容や様子をお伝えする特設サイトをご用意しました!DAIS2024期間中は毎日更新予定ですので、ぜひご覧ください。
私たちはDatabricksを用いたデータ分析基盤の導入から内製化支援まで幅広く支援をしております。
もしご興味がある方は、お問い合わせ頂ければ幸いです。
また、一緒に働いていただける仲間も募集中です!
APCにご興味がある方の連絡をお待ちしております。