Preface
In this session, we will explore strategic timing and motivations for training a custom LLM. Leveraging Databricks, which is designed to efficiently and easily handle large-scale data and complex computational tasks, significantly simplifies this endeavor.
- Preface
- Generative AI Methods and Their Applications
- About the special site during DAIS
First, Nancy Hong will guide you through the hands-on steps involved in model training on Databricks. From data preprocessing to the actual training process, a detailed perspective will be provided through a live demonstration, making the learning process interactive and insightful.
Following that, Spencer will present a case study on how M-Science is approaching training models on Databricks for the purpose of automatic generation of research reports. This example highlights not only the practical applications of trained LLMs but also the significant benefits of automating repetitive tasks in a research setting.
Today, as more companies integrate LLMs to streamline operations and innovate service delivery, understanding how platforms like Databricks contribute effectively in training and fine-tuning these models is crucial. The adaptability and scalability offered by Databricks ensure a smooth transition from data processing to model deployment, a critical stage in the model development lifecycle.
Our session provides detailed insights into the practicality and benefits of training and fine-tuning LLMs using Databricks. Look forward to the next section where Nancy will dive deeper into the model training process on Databricks.
Generative AI Methods and Their Applications
The session, "Training or Fine-Tuning a Custom LLM with Your Own Data Using Databricks," includes an extensive discussion on various generative AI technologies, with a particular focus on "Retrieval Augmented Generation (RAG)." This method efficiently integrates enterprise-customized data using an external knowledge retrieval system.
Retrieval Augmented Generation, or RAG, integrates external knowledge during operation, combining this knowledge, typically collected from document content, with training prompts within a large-scale language model. This combination significantly enhances the model's capabilities and extends its knowledge base.
RAG operates without additional training time, which is advantageous. However, it does lead to increased inference costs due to the demands of prompt processing, embedding models, and knowledge retrieval components. Despite the superior task performance and expanded knowledge capacity of RAG systems, these operational costs during inference present a significant challenge compared to technologies solely dependent on prompt engineering.
The session demonstrated that technologies like RAG and prompt engineering enhance model functionality and knowledge extension while still facing challenges such as limited capabilities beyond expansion and notable increases in inference costs. For sophisticated language models implemented on platforms like Databricks, it is crucial for developers and enterprises to carefully balance these costs and benefits and choose efficient methods tailored to customized data needs.
As the field of AI continues to evolve, the methodologies for training and fine-tuning custom LLMs on Databricks are also advancing, providing necessary insights for developers and enterprises to effectively utilize these powerful tools based on specific data needs.
Custom LLM Training and Deployment: From Data Preparation to Deployment on Databricks
The session on training and fine-tuning custom Large Language Models (LLM) on Databricks provided practical insights into training and fine-tuning LLMs based on proprietary data. This article focuses on the "Steps in Custom LLM Training and Deployment," detailing the process of training and deploying custom LLMs step-by-step.
Data Preparation
The initial stage emphasizes data governance and preparation. Properly collecting, shaping, and organizing data is the first step toward success. The quality of data, which directly affects the success or failure of the model, undergoes rigorous checks at this stage, making data cleaning, preprocessing, and security critical factors.
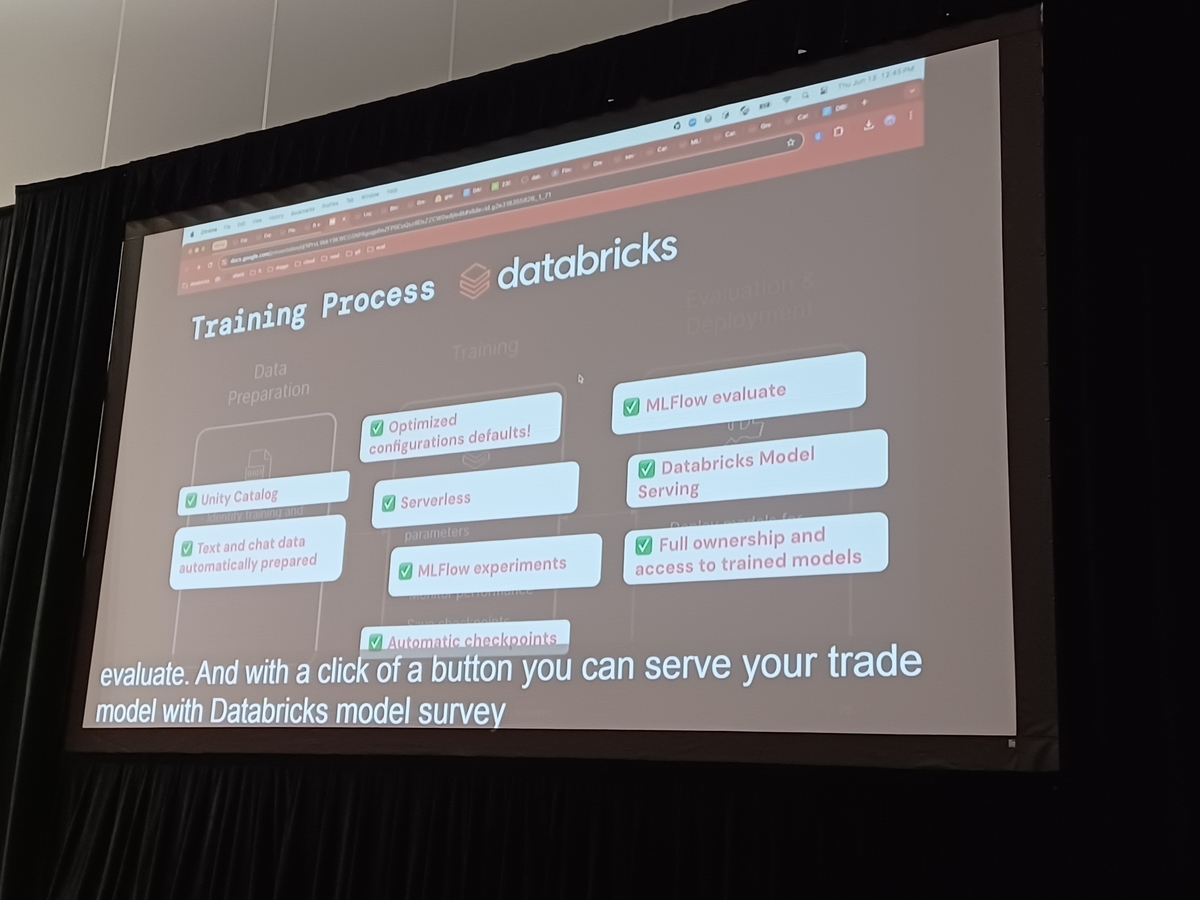
Training Process
Next, the process moves to the training phase, which includes numerous settings from hardware selection to setting the training hyperparameters. Error tolerance settings, establishing job monitoring systems, and setting training job checkpoints are also implemented to ensure a smooth execution. Training is an iterative process that gradually improves the model.
Evaluation and Deployment
In the final stage, the trained model is evaluated and moved to deployment. The evaluation metrics, crucial for determining whether the model performs as expected with real-world data, are important. Ensuring security is also vital, requiring measures for the safe operation of the model. Tasks like setting up infrastructure for using the model as a service and designing APIs are crucial at the deployment stage.
Through this process, it is possible to fully harness the potential of custom LLMs and build powerful models tailored to specific purposes and needs. Proper management of steps from data processing to model operation is key to success.
This content maintains the structural integrity of the specified section within the 'Section Theme List' while thoroughly processing the intended process from the 'Target Section Themes' with precise terminology and focus.
Let's take a closer look at how to train and optimize custom LLMs on Databricks. This section specifically focuses on operations through the user interface, explaining the simple steps necessary for model optimization.
1. Using the Experiment App
Access the "Experiment App" from the Databricks workspace. First, create an experiment for the foundation model that forms the basis of the fine-tuning process.
2. Launching the Fine-tuning UI
The fine-tuning interface can be launched directly from the "Experiment App". This intuitively designed UI simplifies the fine-tuning process, making it accessible to users of different skill levels.
3. Selecting the Task
Choose the specific task for fine-tuning the model. Databricks supports various foundational models, and selecting the right one is crucial for achieving the desired results.
4. Ensuring Screen Visibility
During the live session, it is important to ensure that everyone in the venue can easily see the demonstration on the screen. Adjust the screen settings based on real-time feedback to ensure clarity and visibility.
5. Utilizing Python SDK
For a more hands-on approach, using Databricks' Python SDK allows for direct code execution within the Dataverse and deeper customization. This is suitable for users who want to fine-tune the model with precise settings.
6. Integrating Feedback
Before starting the fine-tuning process, collect direct feedback to adjust the UI display or model parameters, optimizing them. This proactive engagement helps customize the session to meet the audience's needs, enhancing learning outcomes.
By following these steps, you can effectively leverage Databricks to train and fine-tune custom LLMs suited for specific tasks, achieving superior performance.
Case Studies and Practical Applications
To enhance investment research for institutional investors, Emscience heavily relies on analyzing massive datasets, especially billions of online consumer transaction data. This data is crucial for predicting the performance of publicly traded consumer companies. Emscience has developed a tool called "Research Author and Publisher," demonstrating practical applications of training and fine-tuning custom LLMs using the Databricks platform.
The presentation contrasted traditional investment research reports generated by human analysts with reports generated using the "Research Author and Publisher." Initially, traditional formats and content were highlighted, emphasizing the significant human effort and analytical skills required for these reports.
The core of this session was to demonstrate the transformative impact of integrating custom LLMs into Emscience's workflow. The "Research Author and Publisher" tool is crucial in this integration, enabling rapid generation of nuanced, data-driven insights through LLM fine-tuning. Adopting Databricks for fine-tuning allowed Emscience to effectively enhance processing speed and output quality, essential for providing timely investment insights to clients.
Conclusion
Emscience's case study clearly shows that leveraging technological platforms like Databricks to train and fine-tune LLMs can significantly transform and optimize business processes. Such advancements not only ensure efficiency but also maintain high standards of accuracy and detail in analytical reports. This successful application demonstrates the extensive potential for various sectors to rethink and rebuild their data analysis strategies, leading to robust, AI-driven insights for smarter and faster business decisions.

About the special site during DAIS
This year, we have prepared a special site to report on the session contents and the situation from the DAIS site! We plan to update the blog every day during DAIS, so please take a look.