
はじめに
こんにちは、GLB事業部Lakehouse部の陳(チェン)です。
本日はDatabricksプラットフォーム上でのLinear RegressionをベースとしたMeachine Learningモデル(MLモデル)の構築についてご紹介いたします。 PySparkのコーディングで、Pipelineを利用したMLモデルの構築ですので、Databricksプラットフォームのみならず、他のプラットフォームでの利用も可能です。ご参考になれればと思います。
目次
前作業
データ取得
Kaggleから取得できる過去のコンペデータを利用します。 下記のウェブページからデータを取得し、取得したデータを用いて航空券価格を予測するMLモデルの構築を行っていきます。 なお、データの取得に関しては色んな方法がありますので、ご自身の慣れ親しんだ方法で取得してください。
データ内容確認
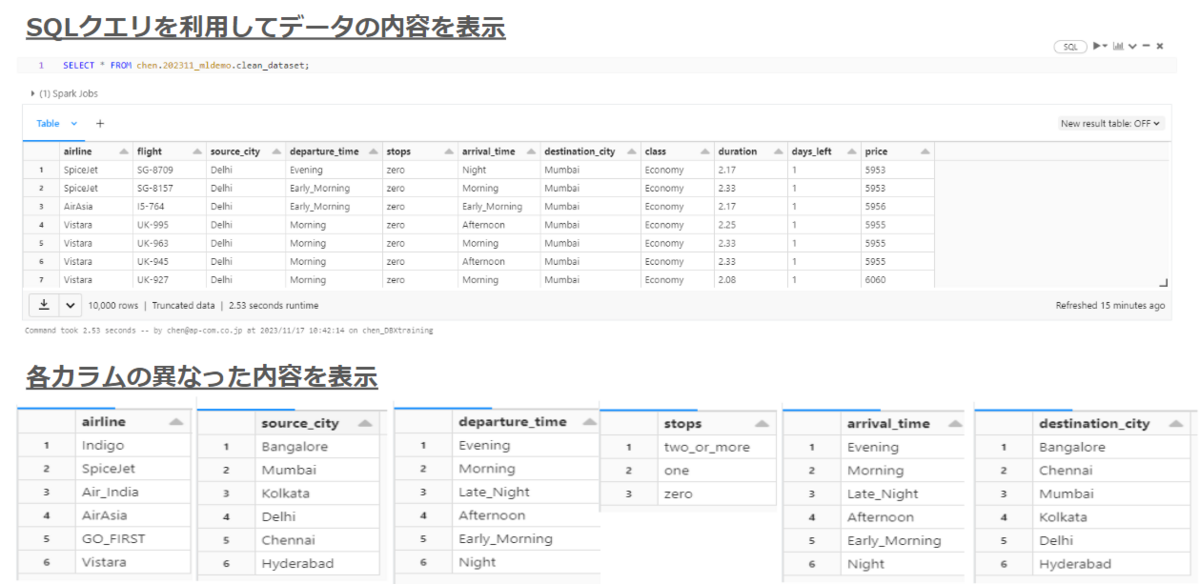
図aはデータの内容を示しています。データの中に航空会社(airline)、便名(flight)、出発地(source_city)、出発時間(departure_time)、乗り継ぎ回数(stops)、到着時間(arrival_time)、目的地(destination_city)、座席クラス(class)、飛行時間(duration)、出発までの残日数(days_left)、および価格(price)が含まれています。各カラムの異なった内容も示しています。
データの型変換
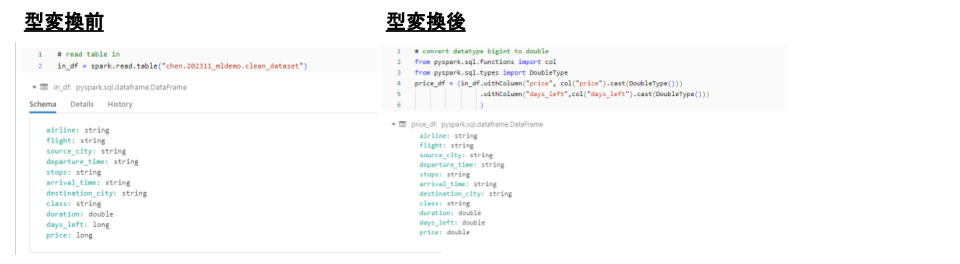
各カラムの型は図bに示しています。主に数値型と文字型であり、数値型の中にdoubleやlongがあります。数値型をdoubleに揃えたいため、データ型の変換を行います。データ型の調べ方、データ型の変換のし方及び変換前後の比較は図bに示されています。
以上、データ内容の確認のデータ型の整備でした。
MLモデル構築
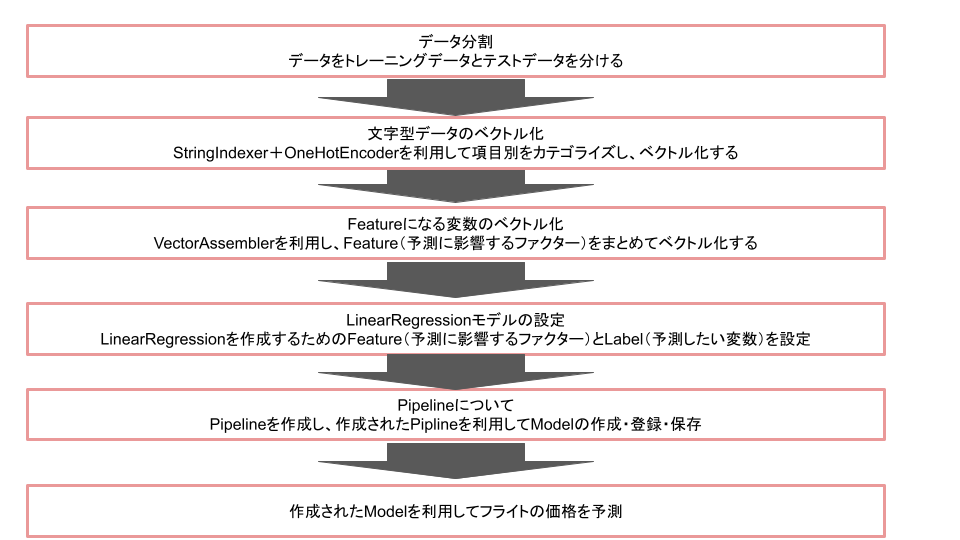
MLモデル構築の流れは図cに示されます。ごく一般的かつシンプルなMLモデル構築の流れにもなります。この流れに沿ってこれからの各小節は実際のコードに合わせて順番を見ていきます。
データ分割
データを訓練用データ(training data)とテスト用データ(test data)に分けます(図d)。ランダムに訓練データを8割、テストデータを2割に分割します。検証の観点から、いつでもに同様な分割結果が再現できるのが望ましいため、ランダム分割に使用された乱数表を「seed=42」というオプションを付けて指定しています。

文字型データのベクトル化
ここでは、StringIndexerとOneHotEncoderを利用してStringの情報をカテゴライズしたうえでベクトル化をします。
その前に、文字型データをベクトル化するための出力カラムを用意しておきます(図e)。 データタイプはstringのカラム名をcategorical_colとして抽出します。その後、StringIndexerのための出力カラム名を「<元のカラム名> + "_Index"」として用意しておきます。同様に、OneHotEncoderのための出力カラム名を「<元のカラム名> + "_OHE"」として用意しておきます。

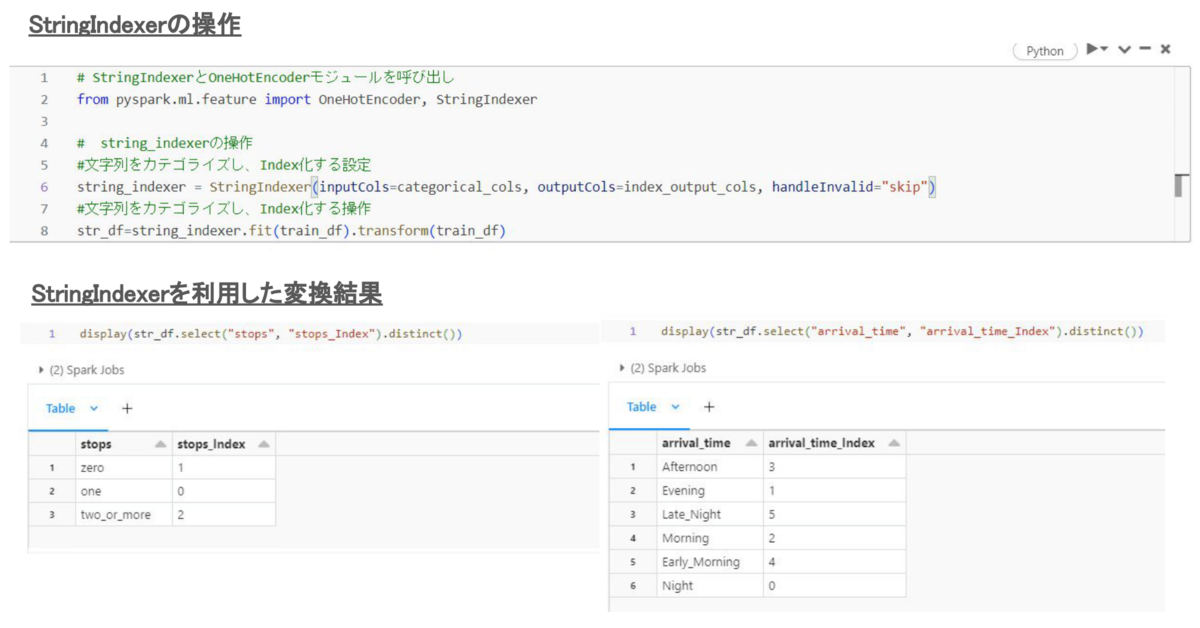
StringIndexerはカラム文字列を分類します。同じ文字列の出現頻度を順番に0、1、2 ...、に番号を付けます。 利用法は図fの通り、inputColに入力カラムを設定して、outputColに出力カラム名を設定してから変換を行います。例としてStringIndexerによって変換前(stops、arrivial_time)の情報と変換後(stops_Index、arrivial_time_Index)の結果を並べました。文字列毎に数値に変換(カテゴライズ)されることが分かります。
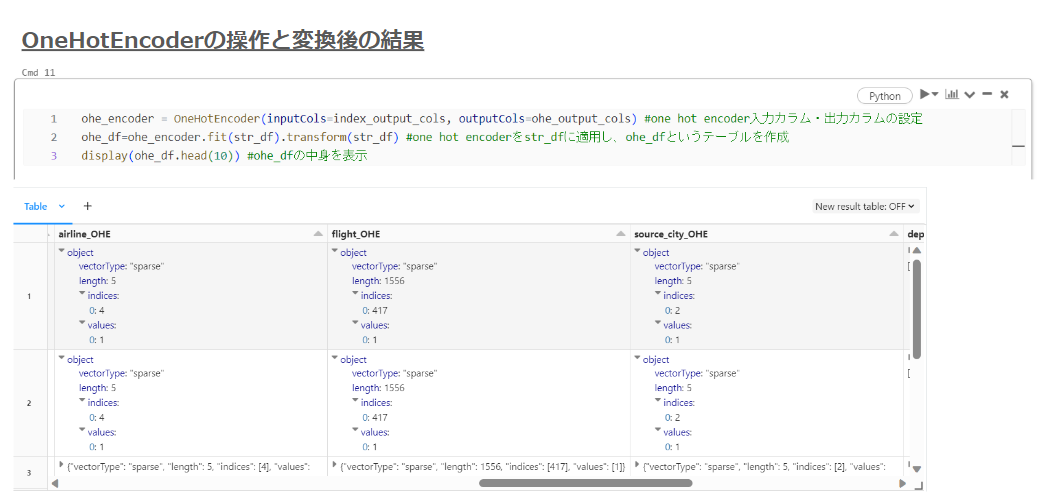
次に、StringIndexerの出力カラム(<元のカラム名>_Index)をOneHotEncoderの入力カラムの情報を基づいて、ベクトル(SparseVector)化をし、カラム「「<元のカラム名>_OHE」」として出力します。これらの操作は図gに示されており、変換後の結果の一部(airline_OHE、flight_OHE、source_city_OHE)が示されています。
Featureになる変数のベクトル化
VectorAssemblerを利用してFeatureになるカラムをベクトル化します。Featureは日本語で特徴量と訳されています。予測のための根拠になる変数の集合です。ここでは、OneHotEncoderによりベクトルされた文字型の情報と数値型の情報をまとめてベクトル化します。priceは予測変数のため、特徴量に含まれていません。

LinearRegressionモデルの設定
LinearRegressionモデルを作成するための設定を行います。priceをlabelCol(予測変数)として、VectorAssemblerで作成されたベクトル量のカラムFeaturesをfeaturesCol(予測の根拠になる変数)として指定し、これらの情報を基づいてLinearRegressionモデルを作成するよう設定します。

Pipelineについて
Pipelineの設定、Pipelineを利用してもモデルの構築、そして、構築されたモデルの保存・呼び出しは本小節で説明します。実際のコードは図jを参照してください。
Pipelineを利用する利点は、用意済みの手順の再利用が可能となります。今後、新たなデータが追加される場合、Pipelineをそのまま再利用して、MLモデルの再構築を簡単にします。
Pipelineを作成する際、こちらの順番で作成を行います。 ここでは、前節までに用意した「文字型データのベクトル化(string_indexer, ohe_encoder)」、「Featureになる変数のベクトル化(vec_assembler)」、「LinearRegressionモデルの設定(lr)」の3つ(厳密というと4つ)のステージとしてpipelineを設定します。 そして、このpiplineのステージに沿って、train_dfを用いてLinearRegressionのMLモデルを構築します。このモデルを「pipeline_model」として名を付けます。
pipelineを利用したMLモデルを構成します。構成されたMLモデルを指定の場所に保存・呼び出しはできます。ここでは、「saved_pipeline_model」として呼び出して予測に利用します。

モデルを用いて予測
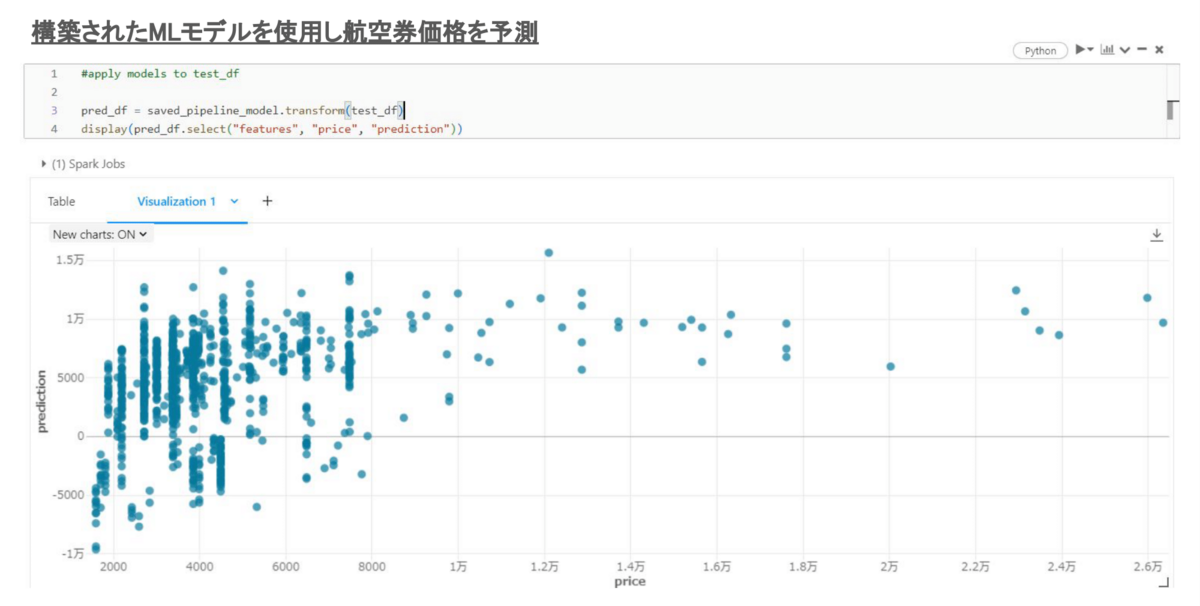
図kは作成されたモデルを利用して予測を行います。そして実際の航空券価格(横軸)と予測された航空券価格(縦軸)の関係を示す図を作成します。
結果考察
モデルの結果について
ここまで一通りにLinearRegressionのMLモデルの構築からテストデータを用いて予測を行いました。
図kが示した通り、一見、実際の価格(price、横軸)と予測された価格(prediction、縦軸)の間では一定の関係を持たされています。 ですが、予測された価格は実際の価格より大幅に下回ることになっています。 特に価格帯が8000以下の航空券価格は予測では負の価格として予測されたことが目立っています。実際に運用に適切ではないモデルになりました。
今回はあえてよくない例を紹介いたします。 なぜなら、現実世界でのデータは複雑で、予測モデルの作成の基本や考え方は変わりませんが、データの質や使い方によって結果が大きく変わることを理解していただきたいです。
特にモデル構築に関しては、データの性質や内容などを細心の注意を払って前処理を行わず、そのままに使ってモデルを構築すると今回のようにひどいものになります。
では、このモデルは使い物にならないのでしょうか。作った私としては、実用的ではないですが、参考程度にとどまることにしたいとおもいます。
元データを詳しく見て、データの品質を向上すれば、より実用的な価格予測モデルになる可能性があります。今後、試行錯誤して改善できた場合に改めてご紹介できればと思います。
モデルの結果の応用について
少しモデルが実用的なものになったら、との話をさせていただきます。
旅行や出張の場面において、航空券などを購入するときに、価格が気になりますね。どの時期、どの時間帯、どの航空会社......などの要素に基づいて航空券価格の見通しができれば、使用者としての予算や計画を立てやすくなります。ビジネスとして、例えば、旅行代理店としては、航空会社から正式な航空券価格がリリースされなくても、これまでの傾向に基づいて、航空会社が航空券価格を提示する前に、旅行計画や販売計画の立案予備が可能になり、商品化までのリードタイムを短縮することが可能となります。使い方や見方によって個人にも、ビジネスにもメリットにあるモデルになりうることです。
おわりに
今回はオープンソースのデータを用いて航空券価格予測MLモデルの試作をご紹介しました。いかがでしたか。
GLB事業部Lakehouse部はユーザのニーズに合わせて、データ情報基盤の整備からデータ解析・MLモデルの構築まで様々なニーズに対応する部署です。 お客さんと会話しながら、一緒にお客さんの課題を解決していきますので、気軽に問い合わせていただければと思います。

私たちはDatabricksを用いたデータ分析基盤の導入から内製化支援まで幅広く支援をしております。もしご興味がある方は、お問い合わせ頂ければ幸いです。
また、一緒に働いていただける仲間も募集中です! APCにご興味がある方の連絡をお待ちしております。