
はじめに
GLB事業部Lakehouse部の鄭(ジョン)です。
この記事では前回記事でご紹介しましたKDB.AIのサンプルコード実習をご紹介しようと思います。
KDB.AIは世界最速の時系列データベース及び分析エンジンであるkdb+で駆動されるVectorデータベースで、EndpointとAPI Keyを通じて接続できます。
Early Access Programが最近開始されて無料アカウントで体験が可能です。
アカウント作成とEndpoints&API Keys作成方法は前回の記事にあります。 techblog.ap-com.co.jp
サンプルコードの実習のため、アカウント、Endpoints、API Keysの作成をお願い致します。
今回はサンプルの中でDocument Searchをご紹介致します。
記事の順番はDocument Searchの紹介、サンプルコード実習の流れです。
目次
サンプルコード(Document Search)の紹介
Document Searchは KDB.AIをVector Storeとして使用し、PDFの内容を検索するサンプルです。
構造化されてないテキストPDFからセマンティック検索をする実習をします。
セマンティック検索はユーザーが気になっている検索Queryを理解して理解した内容をもとに検索結果を表す技術です。
データが正確に同一でなくても、類似のベクトルを見つける方法で関連性の高い結果を識別します。
実習では、次のような過程を行います。
➀ PythonのPyPDF2ライブラリとspacyライブラリを利用してPDFを読み、各テキストを文章に分割します。
➁ Sentence Transformersモデルを作成して、➀で分割したテキスト文章をモデルに入力してVector Embeddingを作成します。
③ KDB.AIにテーブルを作成してEmbeddingを保存します。
④ 気になる内容を➁のモデルに入れてEmbeddingします。
⑤ ④のVectorをKDB.AIのsearch関数に入力して、類似の結果を得ます。
➝ つまり、KDB.AIを利用してQueryでセマンティック検索するのです。
サンプルコード実習
実習はKDB.AIを引用して行いました。 kdb.ai
サンプルコードをDatabricksのWorkspace上で実習してみます。
0. DatabricksのCluster
Clusterは14.0 ML (includes Apache Spark 3.5.0, Scala 2.12)を使います。
上記のClusterはPython3.10.12バージョンです。
1. ドキュメントのロードと分割
PDFを読み込んで分割できるようにパッケージをインストールします。
- PDFを扱うためPyPDF2をインストールします。
%pip install PyPDF2 spacy sentence-transformers kdbai_client -q
- 自然言語処理(Advanced Natural Language Processing)のためにspaCyをインストールします。
!python3 -m spacy download en_core_web_sm -q
PDFを読み込んで文章で分割します。
- "pdfをアップロードした自分のpath"にpdfのpathを入力します。
import PyPDF2 import spacy # spaCyモデルをロード nlp = spacy.load("en_core_web_sm") # PDFを文章で分割する関数を作成 def split_pdf_into_sentences(pdf_path): # PDFをオープン with open(pdf_path, "rb") as pdf_file: pdf_reader = PyPDF2.PdfReader(pdf_file) # 各ページからテキストを抽出および組み合わせ full_text = "" for page_number in range(len(pdf_reader.pages)): page = pdf_reader.pages[page_number] full_text += page.extract_text() # テキストをspaCyを使って文章でトークン化処理 doc = nlp(full_text) sentences = [sent.text for sent in doc.sents] return sentences # 使用するPDFのpathを定義 pdf_path = " pdfをアップロードした自分のpath" # 作った関数にPDFを入力 pdf_sentences = split_pdf_into_sentences(pdf_path) # 文章の数 len(pdf_sentences)
![]()
分割された文章を確認します。
pdf_sentences[0]

2. Vector Embeddingの作成
Sentence Transformersのライブラリを使って分割された文章についてのEmbeddingを作成します。
Sentence Transformerのモデルを選択します。
- 今回のサンプルでは事前に訓練されたモデル「all-MiniLM-L6-v2」を使います。
from sentence_transformers import SentenceTransformer model = SentenceTransformer("all-MiniLM-L6-v2")
Embeddingを作成します。
- Sentence Transformerのモデルに分割された文章を入力して、encodeを通じてEmbeddingします。
- KDB.AIで対応できるDataFrameの形に変換します。
import numpy as np import pandas as pd # Embeddingを作成します。 embeddings_array = model.encode(np.array(pdf_sentences)) embeddings_list = embeddings_array.tolist() embeddings_df = pd.DataFrame({"vectors": embeddings_list, "sentences": pdf_sentences}) embeddings_df
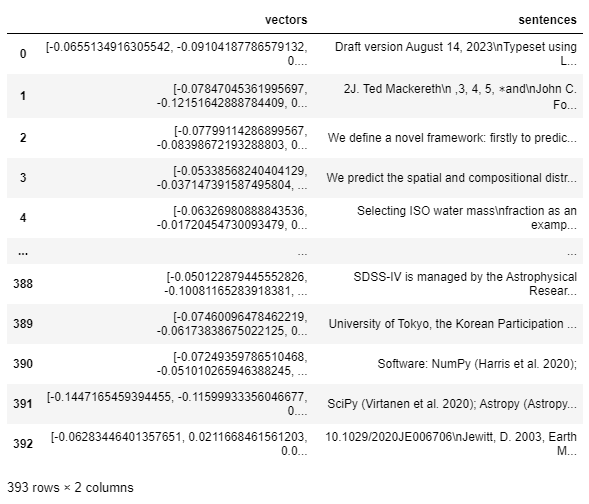
- Embeddingの次元は384です。
- 上の次元はEmbeddingを保存するKDB.AIのテーブルのSchemaを定義時、VectorIndexの次元に使用する予定です。
len(embeddings_df["vectors"][0])
![]()
3. KDB.AIにEmbeddingを保存
EndpointsとAPI Keysを使ってKDB.AIのSessionに接続します。
EndpointsとAPI Keysの作成方法は前回のブログにあります。 techblog.ap-com.co.jp
"自分のKDB.AI ENDPOINT"に自分のKDB.AIのENDPOINTを入力します。
- "自分のKDB.AI API KEY"に自分のKDB.AIのAPI KEYを入力します。
import kdbai_client as kdbai KDBAI_ENDPOINT = "自分のKDB.AI ENDPOINT" KDBAI_API_KEY = "自分のKDB.AI API KEY" session = kdbai.Session(api_key=KDBAI_API_KEY, endpoint=KDBAI_ENDPOINT)
Embeddingを保存するKDB.AIのテーブルのSchemaを定義します。
- 検索に使用するindexとmetricを選択します。
- 今回のサンプルではHNSW(Hierarchical Navigable Small World)をindexで使います。
- HNSWは近接隣接(nearest neighbor)を探索する方法なので、テキストのドキュメントとか自然語のような高次元データも効率的に処理できます。
- 類似度metricはEuclidean distanceのL2を使います。
- Euclidean distanceのL2は高次元スペースで座標の距離を計算します。
- 次元は上で確認した384を入力します。
KDB.AIで扱うindexの詳細は以下のページをご確認ください。 code.kx.com
KDB.AIで扱うmetricの詳細は以下のページをご確認ください。 code.kx.com
pdf_schema = {
"columns": [
{"name": "sentences", "pytype": "str"},
{
"name": "vectors",
"vectorIndex": {"dims": 384, "metric": "L2", "type": "hnsw"},
},
]
}
テーブルを作成します。
- session.create_table()関数でpdfテーブルを作成します。
table = session.create_table("pdf", pdf_schema)
- query()関数でテーブルを確認します。
- まだテーブルは空です。
table.query()

テーブルにEmbeddingを入力します。
table.insert(embeddings_df)
![]()
- またquery()するからテーブルにデータが追加されています。
table.query()

4. KDB.AIを利用したQuery検索
KDB.AIにEmbeddingが保存されましたのでセマンティック検索ができます。
- Sentence Transformerモデルに検索したい検索語を入力してencodeを通じてEmbeddingします。
- モデルから作られたindexをKDB.AIで検索します。
- 最も類似した 3 つを返します。
search_term = "number of interstellar objects in the milky way" search_term_vector = model.encode(search_term) search_term_list = [search_term_vector.tolist()] results = table.search(search_term_list, n=3) results

- 最も類似した 3 つの文章を確認します。
- pd.set_option()で表示する文章の幅を設定して文章全体を確認します。
# カラム値を...に減らすのではなく、全体を見るように設定 pd.set_option("display.max_colwidth", None) # 文章の確認 results[0]["sentences"]

- 他の検索もやってみます。
search_term = "how does planet formation occur" search_term_vector = model.encode(search_term) search_term_list = [search_term_vector.tolist()] results = table.search(search_term_list, n=3) results[0]["sentences"]

5. テーブルの削除
テーブルを削除します。
table.drop()
![]()
まとめ
今回の投稿ではDatabricks上で行ったKDB.AIのサンプルコードであるDocument Searchを紹介し、実習としてDatabricks上でサンプルコードを動かしました。
そして実習を通じて次のようなものを学びました。
- PyPDF2ライブラリとspacyライブラリでPDFを読み、各テキストを文章に分割する方法
- Sentence Transformersモデルを通じてVector Embeddingの作成方法
- KDB.AIを利用してQueryでセマンティック検索する方法
次回の投稿では、今回の投稿のようにKDB.AIの他のサンプルコードをDatabricks上で検証してみて、これについてご紹介したいと思います。
最後までご覧いただきありがとうございます。
引き続きどうぞよろしくお願い致します!

私たちはDatabricksを用いたデータ分析基盤の導入から内製化支援まで幅広く支援をしております。
もしご興味がある方は、お問い合わせ頂ければ幸いです。
また、一緒に働いていただける仲間も募集中です!
APCにご興味がある方の連絡をお待ちしております。