はじめに
GLB事業部Lakehouse部の阿部です。
Chat GPTが登場して日本国内の企業でもオープンソースのLLMをリリースしたこともあり、LLM(大規模言語モデル)という言葉は聞く機会が増えました。
最近はLLMOpsという言葉もちらほら聞くようになりましたが、MLOpsとの違いやOpsとあるように運用はどのように行うのか、勉強中の整理として本記事を書きたいと思います。
LLMOpsとは
LLM(Large Language Model)+ Ops(Operations)の造語です。
LLMOpsの明確な定義はされておりませんが、DevOpsやMLOpsのようにLLMの開発と運用をパイプライン化することで開発と運用のサイクルを円滑に回すことではないかと思います。
LLMOpsの定義が曖昧であること、運用方法が定まっていないためLLMOpsという言葉はさほど使われておりません。
日本を対象としてGoogle TrendsでLLMとLLMOpsをキーワードに指定してトレンドを見たところ、「LLM」の検索数増加に対して「LLMOps」は検索数がかなり少ないことがわかります。
(対象の期間は2022年の11月にChat GPTがリリースされたことを踏まえて、その直前と記事執筆時点での日時を指定しました。)
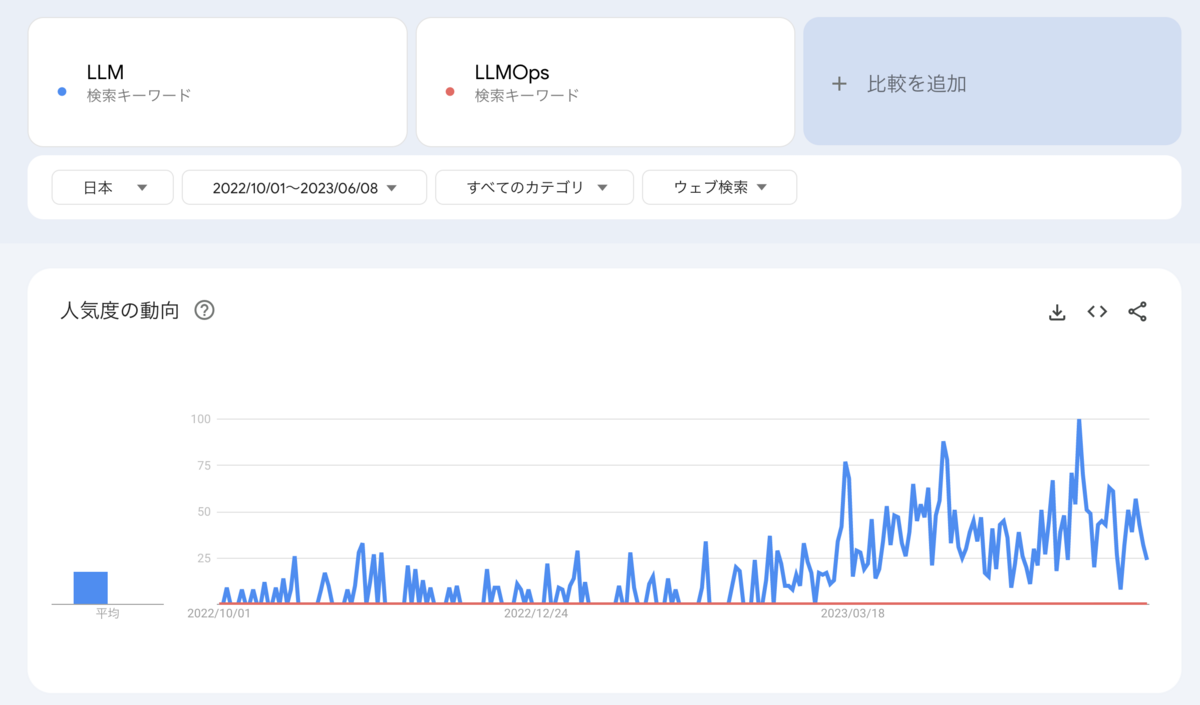
LLMの検索数のピークが見られる要因はわかりませんが、Chat GPTが使われ始めたことや、国内企業がオープンソースのLLMをリリースしたことなどが考えられます。
反対にLLMOpsについては国内においてLLMと比較して検索数が非常に少なく、その理由はMLOpsのように運用のベストプラクティスが定まっておらず、LLMOpsという言葉自体があまり使われていないからだと考えます。
ちなみに、アメリカではLLMの検索数が増加しておりLLMOpsについてもぼちぼち検索されていますが、それでも検索数は比較的少ないです。
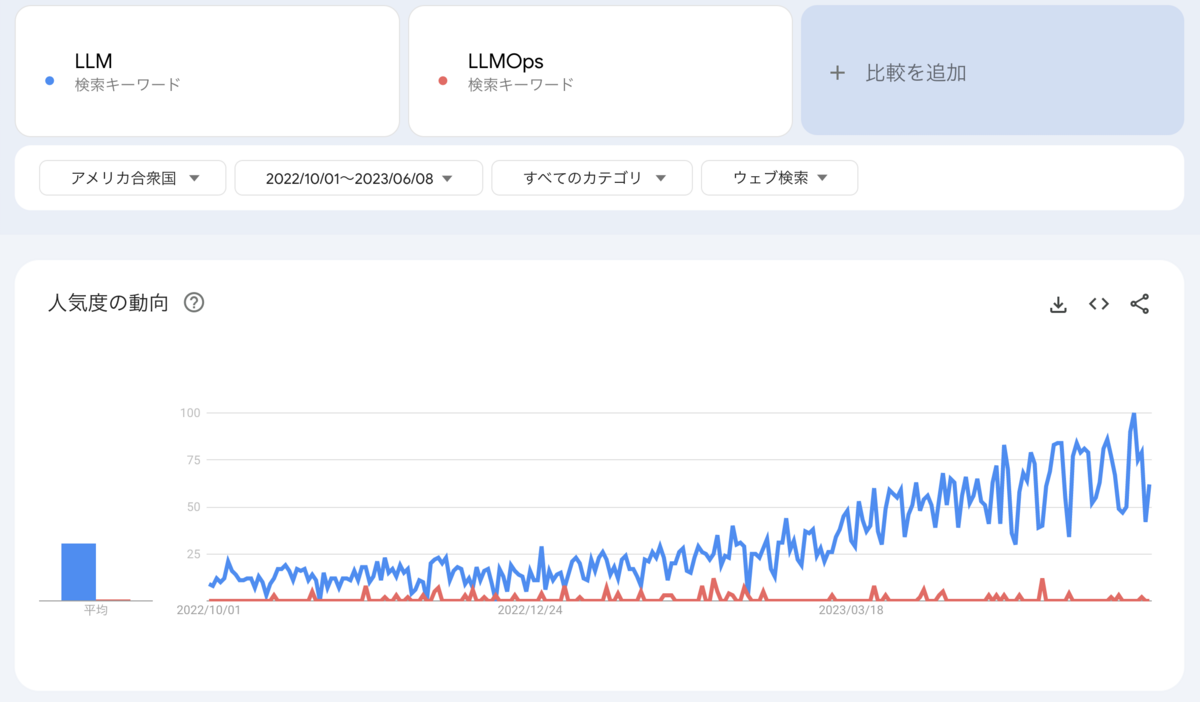
OpsとあるようにLLMの運用であると想像できますが、現時点で運用方法にベストプラクティスがなく事例もほぼないことから「LLMOpsとは〜である!」とは断言できません。
そのことから、本記事で話すLLMOpsの内容はあくまで参考の1つにしていただければと思います。
MLOpsと異なる精度向上の方法
LLMの精度向上の方法は、以下3つだと私は考えています。
MLOpsと大きく違うことは、精度向上にはファインチューニング以外の方法が用意されており、その方が適している可能性があります。
ちなみに、一度に1つだけ行うのではなく同時の実施も考えられます。
1. プロンプトの調整
まずはプロンプトエンジニアリングによるプロンプトの調整が考えられます。
改めてデータを選んで学習するファインチューニングより時間も手間もかからないため、モデルの精度向上の施策としてファーストチョイスであると思います。
さらに、プロンプトの調整のみで対応できるケースも一定数あると考えられるため、MLOpsのファインチューニングと比べてすぐに実行できます。
2. ベクトルデータベース(ベクトルストア)内のデータ更新
プロンプトのcontextに類似文書を挿入する際にベクトル検索を使用している場合、ベクトルデータベースの更新も候補の1つです。(結果、プロンプトの調整にはなると思います。)
プロンプトの調整と比べたら少々手間がかかりますが、後述するファインチューニングと比べたら手軽に行えます。
データを入れ替えたりデータ形式を変更するなどが考えられますが、もし新たにQAのデータセットにする場合はデータの準備が大変です。
3. ファインチューニング(再学習)
時間と手間の観点から個人的には最終手段と考えています。
MLOpsでは時間の経過とともに学習データの分布が変わることや、外部環境の変化により期待通りの出力が得られない場合に行います。
LLMでも手段の1つですがOpenなLLMであることが条件であり、上記2つの方法と比べて費用対効果が低い気がしますし、実際にLLMの開発をしている人のファーストチョイスではないと思います。
このように、MLOpsと比べて精度向上の選択肢が多くなったと言えます。
プロンプトの管理はどうするか
MLOpsのようなデータとモデル管理に加えて、プロンプトごとのモデルの精度を管理する必要があると思います。
理由としては、先ほど述べたようにプロンプト調整後に出力を評価することが考えられるからです。
プロンプトの管理方法として考えられるのは、プロンプトとモデルの出力結果または評価指標が紐づけであり、プロンプトの違いによる出力結果を考察する必要があります。
評価方法の課題
評価方法、評価指標をどうするか、期待した出力であるかどうかの評価基準はどうするかという課題があります。
期待通りの出力が得られているか評価する方法は整備されておらず、現在のところ人間が評価する他ありません。
LLMOpsの最初の段階では人間が介在することになりそうです。
運用・モニタリングにおける課題
運用・モニタリングにおける課題は2つだと考えます。
1つ目は、入力データの分布が変わっても自然言語だと分布の計算方法が決まっていないことです。
入力データの分布(ベクトルデータベースに入れるデータやファインチューニング用のデータ)が変わっても自然言語のためデータ分布を計算する方法に問題があります。
分布の計算方法として特定の語彙やn-gramの出現頻度、文長などから考える可能性もありますが、精度にどれほど起因しているかは判断が難しいと思います。
2つ目は、LLMからの出力結果を評価する方法です。
評価指標の所でも述べましたが、期待通りの答えが出たかどうかは現在のところ人間が評価するしかなく、そもそも答えが明確ではなく期待と近い答えをしてくれたら合格とするイメージです。
さらに、顧客ニーズやその他環境変化によって、LLMから期待する出力が得られなくなる可能性があります。
そのような環境変化に対応するにはファインチューニングに使用する学習データや、ベクトル検索使用時にはベクトルデータベースに格納するデータを定期的に見直す必要があるかもしれません。
DatabricksでLLMOpsを実現するには
LLMOpsをエンドツーエンドで実現する機能はまだありませんが、MLOpsと同様にML Flowを使うことでプロンプトとモデルの紐づけができそうです。
UI、UXの課題はありそうですが、今後の進化に期待です。
MLflow 2.3の紹介:LLMのネイティブサポートと新機能による強化
APC Data + AI Summit 2023 特設サイト
2023年6月26-29日の日程でData + AI Summit 2023が開催されます。
「Data + AI Summit 2023」ではDatabricks社とパートナー契約を締結しているエーピーコミュニケーションズが、現地より基調講演や最新アップデート情報などを弊社特設サイトから順次配信する予定です!
開催までの期間ではDatabricksの魅力や見どころをなどを掲載する予定となります。 Databricks社の方々にもご協力していただきますので、少しでもご興味のある方は1か月ほどの期間となりますがお付き合いいただければ幸いです。
Data AI Summitの見どころ
Data AI Summitの見どころの1つはやはりLLMです。
LLMに関するセッションは多く用意されており私が個人的に気になるLLMに関するセッションをピックアップしました。
DatabricksからLLMに関する衝撃的なニュースがあるかもしれません。
私も期間中はLLMに関する話題を注視したいと思います。
おわりに
本記事では、LLMOpsについて個人的な見解を踏まえて解説しました。
現時点でLLMの開発や運用においてベストプラクティスが定まっておらずLLMOpsの定義が明確ではないため、国内ではよく聞くワードではないかもしれません。
しかし、Google Trendsの結果からもアメリカを中心に盛り上がり、日本でも近いうちにLLMOpsの考え方が広まっていくのではないかと考えています。
今後もLLMOpsの動向を注視していきたいと思います。
最後までご覧いただきありがとうございます。
私たちはDatabricksを用いたデータ分析基盤の導入から内製化支援まで幅広く支援をしております。
もしご興味がある方は、お問い合わせ頂ければ幸いです。
そして、一緒に働いていただける仲間も募集中です!
APCにご興味がある方の連絡をお待ちしております。