
はじめに
GLB事業部Lakehouse部の阿部です。
本記事は、前回のdbdemosを使ったDollyによるチャットbot構築の続きです。
Dollyを動かすことを通じて、プロンプトエンジニアリングやLLM学習の参考になれば幸いです。
本記事は、dmdemosにある以下のノートブックを参考にしています。
03-Q&A-promt-engineering-for-dolly
目次
- はじめに
- 目次
- 本デモの概要
- 前準備
- langchainを使ったプロンプトエンジニアリング
- 簡単な質問に答えるためにチェーンを使う
- 質問に対するプロンプトと回答の挙動を確認する
- Sparkを使ったQuestion Answeringに対する分散処理について
- 参考記事
- おわりに
本デモの概要
本デモでは、チャットbotでよくある入力された質問に対して回答するために、langchainを用いてプロンプトエンジニアリングを行い、Hugging Faceから読み込んだDolly 2.0を用います。
デモの最後にはApache Sparkを適用して1つの質問だけではなく、多くの質問に回答する方法について紹介します。
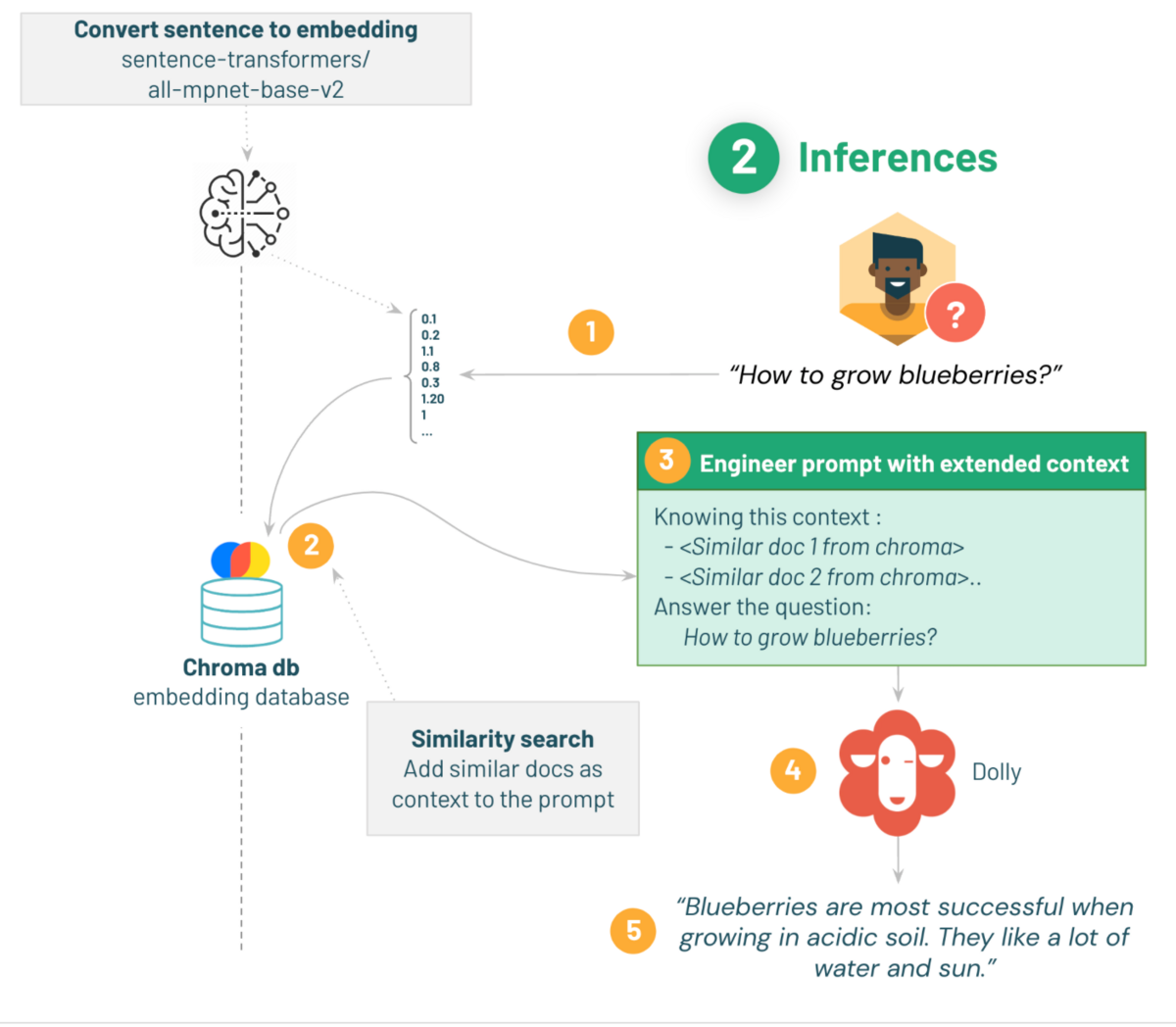
以下の流れでデモを進めます:
1. 取得した質問に対して、Q&Aデータセット準備時と同じembeddingモデルを使って埋め込みする。
2. chromaの文書に対して、取得した質問との類似性検索を行い類似する。
3. 質問と類似の文書をコンテキストとして含むPrompt Templateを行う。
4. テンプレート化したプロンプトをdollyに渡す。
5. 質問に対するガーデニングのアドバイスを受ける。
使用したクラスターは、dbdemosのセットアップ時に作成されたクラスターを使用します。
- Databricks Runtime Version: 13.0 ML
- Node type: StandardStandard_NC8as_T4_v3(56 GB Memory, 1 GPU)
後述しますが、もし途中でメモリーエラーが起きた場合は、よりメモリが大きいGPUクラスターに変更する必要があります。
前準備
まずは必要なライブラリをインストールします。
%pip install -U transformers langchain chromadb accelerate bitsandbytes
前回の記事のようにcatalogとdbに変数を入れ、カタログとDBを定義します。
%run ./_resources/00-init $catalog=hive_metastore $db=dbdemos_llm

Hugging Faceからembeddingモデルを読み込んだ後、前回の記事で作成したベクトルデータベースであるChoromadbを読み込みます。
# Start here to load a previously-saved DB from langchain.embeddings import HuggingFaceEmbeddings from langchain.vectorstores import Chroma if len(get_available_gpus()) == 0: Exception("Running dolly without GPU will be slow. We recommend you switch to a Single Node cluster with at least 1 GPU to properly run this demo.") gardening_vector_db_path = "/dbfs"+demo_path+"/vector_db" hf_embed = HuggingFaceEmbeddings(model_name="sentence-transformers/all-mpnet-base-v2") db = Chroma(collection_name="gardening_docs", embedding_function=hf_embed, persist_directory=gardening_vector_db_path)
本デモではGPUが搭載されたシングルノードのクラスターが推奨されているため、GPUを使用していない場合はエラーメッセージが出るようにしています。
試しに、簡単な質問を出してベクトルデータベース内の類似文書を抽出してみます。
類似性検索はdb.similarity_search()メソッドで行い、questionには検索するテキストを指定し、k (similar_doc_count)には返す類似文書の数を指定します。
def get_similar_docs(question, similar_doc_count): return db.similarity_search(question, k=similar_doc_count) # Let's test it with blackberries: for doc in get_similar_docs("how to grow blackberry?", 2): print(doc.page_content)
以下に、"how to grow blackberry?"と類似した文書を表示します。
I have a breed of blackberry bush in my backyard that is unlike any other blackberries I've had in the past and I'd very much like to plant more just like it. What part of the plant do I need to plant to make a new bush and what's the best way to do this? Added photo as requested: If we're talking about commonly referred to Rubus, most plants in the genus can be propagated 3 ways, by cuttings, by sectioning off suckers - the easiest if there are suckers present already, or by tip layering - burying the tip of a stem a few inches below ground to encourage the plant to produce a sucker. On a whim, I bought a pair of plants for my container garden. They were labelled raspberry and blackberry; however, I'm not certain about the blackberry plant. The blackberry that used to grow by my old house looked a lot more like the raspberry than the blackberry I just bought: (Now that I look at it again that's a terrible photo. I can take a better one if you want.) Obviously that raspberry plant is going to want a trellis, and they'll both need bigger pots. But will the blackberry also want a trellis? Or will it grow into more of a bush shape? When you plant them, be sure that they are no deeper than they were before. Use a porous, well drained potting mix, and water deeply. The blackberry is going to need a trellis, as well as the raspberry. You should use no less than 25 gallons of soil for each plant in the permanent container, but you can gradually get there if you want, by repotting into a pot one size larger every couple months during the growing season until you reach full size. You should also fertilize every other week with a balanced fruit and flower fertilizer (like 12-14-10).
今回は類似性検索をして返す文章を2つとしており、3段落目のOn a whim〜から2つ目の類似文書となります。
langchainを使ったプロンプトエンジニアリング
それでは、LLMとPromt Templateを組み合わせてlangchainのchainを作成します。
chainとは、モデルやプロンプト、chainを連結して1つのまとまりとして扱うためのものです。
Prompt Templateとは、必要に応じてプロンプトの一部を変数にしてプロンプトをテンプレート化する機能です。
Prompt Templateには他にも、質問と回答例などのいくつかのデモンストレーション(Few-shot)の例をプロンプトに含めるFewShotPromptTemplateや、チャットモデル用のテンプレートであるChatPromptTemplateなどがあります。
ちなみに、LangChain公式のGitHubからプロンプトのテンプレートの読み込みも可能です。
以下のコードは、Prompt Templateを行った後に作成したchainを返す関数になります。
from transformers import AutoTokenizer, AutoModelForCausalLM, pipeline import torch from langchain import PromptTemplate from langchain.llms import HuggingFacePipeline from langchain.chains.question_answering import load_qa_chain def build_qa_chain(): torch.cuda.empty_cache() model_name = "databricks/dolly-v2-3b" # can use dolly-v2-3b or dolly-v2-7b for smaller model and faster inferences. instruct_pipeline = pipeline(model=model_name, torch_dtype=torch.bfloat16, trust_remote_code=True, device_map="auto", return_full_text=True, max_new_tokens=256, top_p=0.95, top_k=50) # 注意: ドリー12B以下のモデルを使用しているが、24GB以下のRAMを持つGPUを使用している場合、8bitを使用してください。これには %pip install bitsandbytes が必要です。 # instruct_pipeline = pipeline(model=model_name, load_in_8bit=True, trust_remote_code=True, device_map="auto") # T4やV100のようにbfloat16をサポートしていないGPUでは、以下のようにtorch_dtype=torch.float16を使用してください。 # model = AutoModelForCausalLM.from_pretrained(model_name, device_map="auto", torch_dtype=torch.float16, trust_remote_code=True) # プロンプトのテンプレートを定義する。 template = """Below is an instruction that describes a task. Write a response that appropriately completes the request. Instruction: You are a gardener and your job is to help providing the best gardening answer. Use only information in the following paragraphs to answer the question at the end. Explain the answer with reference to these paragraphs. If you don't know, say that you do not know. {context} Question: {question} Response: """ prompt = PromptTemplate(input_variables=['context', 'question'], template=template) hf_pipe = HuggingFacePipeline(pipeline=instruct_pipeline) # Set verbose=True to see the full prompt: return load_qa_chain(llm=hf_pipe, chain_type="stuff", prompt=prompt, verbose=True)
PromptTemplate()メソッドを使用することで、contextとquestionを変数としてプロンプトをテンプレート化しています。
コードの最後にload_qa_chain()メソッドを使用し、LLMとプロンプトをまとめてchainとしています。
読み込むDollyのモデルについて:
pipelineクラスを用いてDollyをダウンロードしていますが、推論の速度とメモリーを考慮して
一番パラメーター数が少ないdolly-v2-3bを呼んでいます。
経緯としては、デモ用に用意されたクラスターのメモリーは56 GBですが、7bのメモリを読み込んだ際にメモリーエラーが起きてしまったため、3bのモデルを呼ぶことにしました。
pipelineクラスの引数もこちらに載せておきます。
- return_full_text: 出力結果に生成したテキストだけではなくプロンプトを含めるかどうかを指定します。
- max_new_tokens: 生成したテキストの最大のトークン数を指定します。
- top_p: トークンの生成時に使用される確率のしきい値を指定します。
- top_k: トークン生成時の確率上位k個のトークンのみを選択します。
load_qa_chain()メソッドの引数です。
- llm: 回答に使用するllm
- chain_type: LLMに対してどのようにchunkを処理させるか指定できます。
ここではchunk分割をしないstuffを指定し、すべてのコンテキストとしてプロンプトに渡してLLMに入力しています。
- verbose: Trueにすることで前処理やプロンプト全体が見えるようになります。
build_qa_chain()をインスタンス化し、Dollyの読み込みとchainの構築を実行します。
qa_chain = build_qa_chain()
この処理には時間がかかり、私の環境で10分近くかかりました。
簡単な質問に答えるためにチェーンを使う
ここまでの処理を関数として定義し、HTML形式で出力するようにします。
質問と関連する類似文書をベクトルデータベースから取得してHTML形式で返す関数を定義しており、質問に対して回答のソース付きで回答します。
def answer_question(question): similar_docs = get_similar_docs(question, similar_doc_count=2) result = qa_chain({"input_documents": similar_docs, "question": question}) result_html = f"<p><blockquote style=\"font-size:24\">{question}</blockquote></p>" result_html += f"<p><blockquote style=\"font-size:18px\">{result['output_text']}</blockquote></p>" result_html += "<p><hr/></p>" # 水平線を表示 for d in result["input_documents"]: # 類似文書の内容を取り出す source_id = d.metadata["source"] # 類似文書のメタデータであるsourceを取り出す result_html += f"<p><blockquote>{d.page_content}<br/>(Source: <a href=\"https://gardening.stackexchange.com/a/{source_id}\">{source_id}</a>)</blockquote></p>" displayHTML(result_html)
質問と回答、最後にcontextとして挿入する類似文書をHTML形式で表示するようにしています。
質問に対するプロンプトと回答の挙動を確認する
長らくお待たせしました。
質問を与えて回答結果を確認します。
answer_question("What is the best kind of soil to grow blueberries in?")
実行結果を表示します。
まずは、verbose = Trueによって表示されるプロンプトの内容を確認します。
> Entering new StuffDocumentsChain chain... > Entering new LLMChain chain... Prompt after formatting: Below is an instruction that describes a task. Write a response that appropriately completes the request. Instruction: You are a gardener and your job is to help providing the best gardening answer. Use only information in the following paragraphs to answer the question at the end. Explain the answer with reference to these paragraphs. If you don't know, say that you do not know. What are the best soil amendments for blueberries grown in containers? What's the best mulch? Last year I used chopped leaves from a friend's landscaping job that is no longer around. I also remember hearing about adding coffee grounds to the soil to help with acidity. I haven't tested the soil yet, but have a bunch of coffee grounds from a local coffee shop. Do they raise the ph so much that I shouldn't add them if I haven't tested the soil? A good soil mix for pot grown blueberries is a porous, acidic mix high in organic matter. A good mix could be made by mixing these materials by weight: 5/8 topsoil 2/8 peat moss 1/16 vermiculite 1/16 coarse sand Plus some slow release plant food. To help with the acidity, mix 1/4 pound of aluminum sulfate into the top 6" of soil. There are several mulches that fit the needs of the blueberry bushes. Bark mulch is acidic, long lasting and attractive. Also, shredded wood, aged sawdust, and pine straw are good mulches. Coffee grounds are only very slightly acidic, so they will not be useful in maintaining ph. But they do make good compost, and if composted with an acidic material high in carbon, such as the mulching materials mentioned above, they would make an excellent mulch that would feed the plants and help maintain soil ph. I've got a blueberry in a pot that was repotted without amending the soil. Now it seems to be growing okay but rather then repotting it again, I'm wondering if I can apply a coffee grounds mulch while it still has a few berries, and i mean only a very few berries compared with the numbers on it when i bought it just on a year ago. Or should I wait? I haven't tested the soil pH, and I don't use tap water for watering, but fish water from my gold fish. I did put some citrus fertiliser on it once late last year, and we're now in mid summer. Amendments for blueberries in the fall. Goldfish pond water is probably good because the organic material in the water lowers the ph some. However blueberries like acidic soil. They grow under the canopies of great trees in the wild which keeps the soil pretty acidic. Blueberries also like lots of water. You want a very loose humus that will dump all the water and not stay wet, but you need to water often. Question: What is the best kind of soil to grow blueberries in? Response: > Finished chain. > Finished chain.
contextにはdb.similarity_searchによってクエリーと類似した文書を2つ返されていることがわかります。
それでは、同時に出力されるHTML形式で指定した回答結果も確認します。

タイトルである質問の下に回答結果が表示されており、水平線の下に2つの類似文書とsourceが表示されています。
Sparkを使ったQuestion Answeringに対する分散処理について
ここまではチャットbotでよく使われる、1つの質問に対して回答を返すというLLMを実装しました。
ここではもうひとつ、Sparkを使って複数の質問に対して分散処理をして回答する方法も紹介します。
注意
質問のデータセットがそこまで多くないことから、シングルノードのGPUクラスターを使用して処理していますが、
質問の数が膨大になると処理時間が長くなるためマルチノードのGPUクラスターの使用が想定されます。
以下のコードは、Spark UDFを定義して複数の質問からなるデータフレームに対して回答しています。
from pyspark.sql.functions import pandas_udf import pandas as pd from typing import Iterator import os @pandas_udf('answer string, sources array<string>') def answer_question_udf(question_sets: Iterator[pd.Series]) -> Iterator[pd.DataFrame]: os.environ['TRANSFORMERS_CACHE'] = hugging_face_cache hf_embed_udf = HuggingFaceEmbeddings(model_name="sentence-transformers/all-mpnet-base-v2") db_udf = Chroma(collection_name="gardening_docs", embedding_function=hf_embed_udf, persist_directory=gardening_vector_db_path) qa_chain_udf = build_qa_chain() for questions in question_sets: responses = [] for question in questions: # k is the number of docs to retrieve to feed as context similar_docs = db_udf.similarity_search(question, k=2) result = qa_chain_udf({"input_documents": similar_docs, "question": question}) responses.append({"answer": result["output_text"], "sources": [str(d.metadata["source"]) for d in result["input_documents"]]}) yield pd.DataFrame(responses)
これまでの一連の処理をUDFとして定義し、複数の質問のデータフレームに回答するように定義しています。
保存済みの質問のデータフレーム"gardening_dataset"を読み込み、リパテーションします。
リパテーションの数は分散処理時のノードの数に合わせますが、今回はシングルノードで進めるため"1"にします。
分散処理をする場合は、マルチノードのクラスターを使用し、リパテーションの数をノードの数に合わせて指定してください。
new_questions_df = spark.table("gardening_dataset") \ .filter("parent_id IS NULL") \ .select("body") \ .toDF("question") \ .limit(10) #Saving a subset of question to answer for faster processing new_questions_df.repartition(1).write.mode("overwrite").saveAsTable("question_to_answer") new_questions_df = spark.table("question_to_answer").repartition(1) # Repartition to number of GPUs (multi node or single node with N gpu) display(new_questions_df)
読み込んだ質問のデータフレームを表示します。

次に、それぞれの質問に対して回答結果とそのソースを新しいカラムに作成します。
response_df = new_questions_df.select(col("question"), answer_question_udf("question").alias("response")).select("question", "response.*") display(response_df)

複数の質問に対しても、ベクトルデータベースから抽出した類似文書(Question)のソースと回答が返されていることがわかります。
以上でチャットbotの構築は終了です。
前回の記事から見て頂いた方、ありがとうございました。
しかし、チャットbotは会話の内容を踏まえて回答をしていくため、過去の会話を記憶する必要があります。
これを実現する機能の1つにLangChainのmemoryがあります。
次回の記事では、本デモで構築したチャットbotにLangChainのmemoryを導入し、チャットbotを構築したいと思います。
参考記事
おわりに
本記事では、ベクトルデータベースから検索した類似文書をプロンプトにcontextとして挿入し、回答するまでの流れを解説しました。
LLMのライブラリであるLangChainは定期的に大幅なアップデートもあるため、今回使用したコードが将来的に使えないことも考えられます。
その際は、LangChainの公式ドキュメントを参照いただければと思います。
最後までご覧いただきありがとうございます。
私たちはDatabricksを用いたデータ分析基盤の導入から内製化支援まで幅広く支援をしております。
もしご興味がある方は、お問い合わせ頂ければ幸いです。
そして、一緒に働いていただける仲間も募集中です!
APCにご興味がある方の連絡をお待ちしております。