はじめに
このセッションでは「意味検索と文脈ウェブ検索の紹介」に焦点を当てました。講演者は、コンピュータサイエンスのバックグラウンドに基づいた包括的な知識を共有しました。
目次
- はじめに
- 目次
- 意味検索とは何か?
- 文脈ウェブ検索の重要性
- データの管理とスケーリングのベストプラクティス
- データ取得と埋め込みの最適化
- Databricks Vector Search: ハイブリッド検索システムを最大限に活用し、パフォーマンスを最大化
意味検索とは何か?
意味検索は、ユーザーの意図とそのクエリの周囲の文脈を理解することで、従来のキーワード検索を超え、非常に関連性が高くパーソナライズされた情報を提供します。これは、文脈内での使用を考慮して単語の意味、つまりセマンティクスに焦点を当て、検索結果の精度と関連性を向上させます。
文脈ウェブ検索の重要性
文脈ウェブ検索は、ユーザーの特定の状況、意図、またはニーズを考慮し、これらの側面にカスタマイズされた情報を提供します。例えば、ユーザーが特定のプログラミング言語でのコーディング実践を検索する場合、そのユーザーの現在のスキルレベルと学習の文脈を理解し、最も関連性が高く有益な結果を提供します。
従来の検索エンジンは、単純なキーワードマッチングに依存しているため、このようなターゲット情報を提供するのにしばしば不十分です。しかし、意味検索技術の進歩を活用することで、これらの問題を大幅に軽減できます。ユーザーの意図とそのクエリの文脈の両方を完全に理解することで、より適切で豊かな情報が提供され、ユーザー体験が大幅に向上します。
このプレゼンテーションでは、現代の検索技術における意味検索と文脈ウェブ検索の重要な役割を詳述しました。これらの機能は、情報検索の精度を向上させ、直感的で意味のある満足のいく検索体験を提供するために不可欠です。ユーザーのニーズと文脈をより深く理解することで、検索技術はより反応が良くなり、ユーザーセントリックに進化しています。
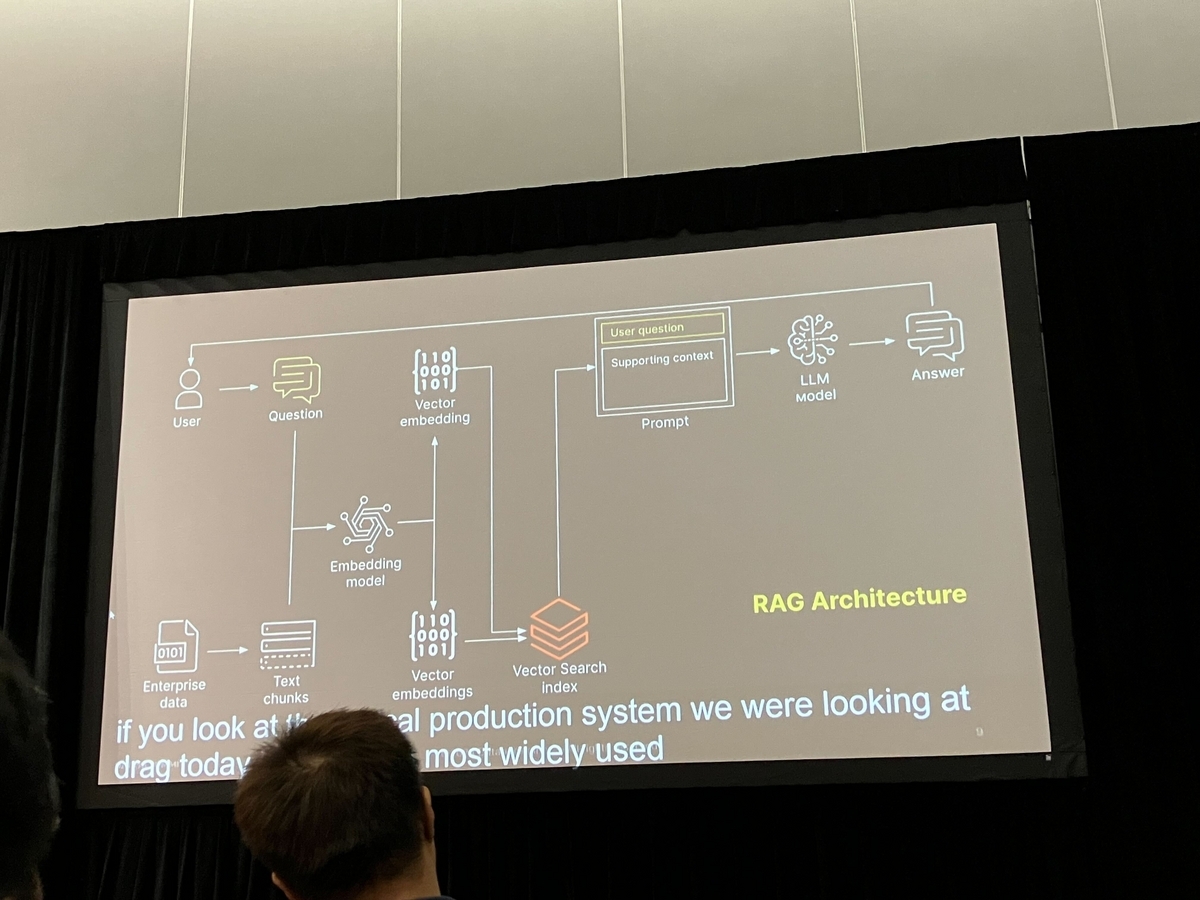
ベクター検索システムを理解するには、主に2つの主要なコンポーネントを知る必要があります。それは「インジェクション」と「ディテクション」です。
インジェクション
このフェーズでは、データ入力の速度が最も重要です。データはできるだけ迅速にシステムに統合される必要があり、それによって迅速な検索が可能となります。そして、エラー発生時のシステム障害を防ぐため、堅牢性を保つことも重要です。自動アップデートと変更検出を実装することで、手動介入の必要性を最小限に抑え、システムを効率的かつ強固なものにすることができます。
ディテクション
検出フェーズでは、ベクター検索のユニークな属性に焦点を当てることが重要です。この段階では、取り込まれたデータに効果的に対応し、処理することが求められます。データの精度と処理速度は、ユーザーの検索体験に大きく影響し、正確で迅速な検出メカニズムの必要性を強調します。
ベクター検索の基本から重要なコンポーネントに至るまで、詳細に掘り下げて調査しました。この包括的な理解は、将来指向の検索システムを開発するための貴重な基盤となります。
データの管理とスケーリングのベストプラクティス
今回のセクションで専門家たちはデータを効果的に管理しスケーリングする方法について詳述し、セキュリティやガバナンスのような重要な考慮事項を強調しました。ここでは議論されたコンセプトは以下の通りです。
柔軟性の道を開く
「柔軟性の道を開く」という概念は、事前に定義されたデザインや手順に厳密に従うことなく、データリソースの使用で適応性を維持することの重要性を強調しています。このアプローチにより、組織はよりスケーラブルで効率的なデータ管理プロセスを実現できます。柔軟性を許すことで、企業は変化に迅速に適応し、リソースの無駄を最小限に抑えながら効率的に運用をスケールアップできます。
スケールの課題
組織が拡大するにつれて、セキュリティとガバナンスの管理の複雑さも増します。セッションは、スケーリングが単にサイズを増やすことではなく、セキュリティプロトコルやガバナンスポリシーなど多くの動的な側面を統合することを含むと強調しました。これらの課題を成功裏に乗り越えるためには、適切な戦略と技術が不可欠です。これにより、堅牢でスケーラブルなデータ管理システムを促進することができます。
セキュリティとガバナンス
セッションでは、スケーラブルなデータ管理の文脈でいかにセキュリティとガバナンスが重要であるかについて深掘りしました。スケールアップシステムにおける主要な課題の一つはデータアクセスとセキュリティの管理であるため、これらの側面は重要です。強固なガバナンスとセキュリティの枠組みを設定することで、システムがスケールしてもデータが安全に保たれ、承認された人員のみがアクセスできるようになります。
データ取得と埋め込みの最適化
効率的なデータ取得のために適切なデータ形式を理解し選択することが重要であると強調されています。データは「短い形式」と「長い形式」に分類され、それぞれに合わせた取り扱い方法が求められます。「短い形式」は通常、短いテキストや小さな記事を含み、「長い形式」は長いレポートや詳細なドキュメントを含みます。適切な形式を正確に識別し、最適な処理方法を選択することは、効果的なデータ取得タスクの基礎となります。
埋め込みプロセスは、テキストデータを数値形式に変換することです。これによりAIモデルによる計算処理が大幅に容易になります。このステップを最適化することは、ベクトル検索の精度と関連するAIモデルの全体的なパフォーマンスを直接向上させることができます。
このセクションの注目点は、効果的にデータを取得し埋め込むための実用的な戦略に焦点を当てたことでした。これらの実践は、より高速に反応し、精度を高めるGenAIアプリケーションを構築する上で重要です。
効果的なデータ管理と埋め込みプロセスの入念な最適化は、AI技術を利用した堅牢なアプリケーションの開発に不可欠です。議論された方法論は、今後のAIプロジェクトを強化するために活用できる重要な洞察を提供します。
これらの洗練されたアプローチをプロジェクトに実装することで、AI駆動アプリケーションのパフォーマンスと精度を最適化することを推奨します。
Databricks Vector Search: ハイブリッド検索システムを最大限に活用し、パフォーマンスを最大化
Databricks Vector Searchでは、セマンティック検索を通じて効率的で正確な応答を保証することが重要です。特定の領域で最大のパフォーマンスを目指す場合、異なる戦略が必要です。
1. モデルサイズ
初期には、小さなモデルを使用した際にいくつかの情報損失が観察されましたが、より大きなモデル(バージョン1.5、約8000トークン)に切り替えた後、顕著な改善が見られました。大きなモデルへのこのシフトは、パフォーマンスの向上に寄与しました。
2. 次元の重要性
機械学習に精通している人々は、次元の重要性がいかに重要かを理解しています。より高い次元を選択することで、より特定でターゲットを絞ったクエリのランキングアプリケーションの機能を向上させることができます。より具体的な目的のためには、高い次元を使用することが勧められます。
3. スタイル特有の作業
特定のデータセットやスタイルを扱うためには、高度にカスタマイズされたモデルの使用が必要な場合があります。このカスタマイズにより、それぞれの使用事例に応じて微調整が可能となり、より効果的な結果を提供できます。
4. 正規化の重要性
データを標準化し、アルゴリズムが情報をより効率的に処理できるようにするためには、正規化が不可欠です。これにより、モデルは異なるデータソースからの情報をより正確に分析し、有用な洞察を抽出するのに役立ちます。
結論
Databricks Vector Searchのパフォーマンスを最大化するには、適切なモデルサイズ、高い次元性、スタイル特有のカスタマイズ、効果的な正規化など、さまざまな戦略的要素を統合することが関与しています。これらのアプローチは、高速で正確な応答を提供し、最終的にはユーザーエクスペリエンスを向上させる堅牢なハイブリッド検索システムを構築します。セマンティック検索能力の卓越性を維持するためには、継続的な洗練と新たなニーズや課題への適応が不可欠です。
これらの要素を組み合わせることで、Databricks Vector Searchのパフォーマンスを最大化し、より洗練されたハイブリッド検索システムを構築することが可能です。継続的な改善と調整は、高品質な情報を求めるユーザーに対して、より速く、より正確な応答を提供することを目指して行うべきです。

Databricks Data + AI Summit(DAIS)2024の会場からセッション内容や様子をお伝えする特設サイトをご用意しました!DAIS2024期間中は毎日更新予定ですので、ぜひご覧ください。
私たちはDatabricksを用いたデータ分析基盤の導入から内製化支援まで幅広く支援をしております。
もしご興味がある方は、お問い合わせ頂ければ幸いです。
また、一緒に働いていただける仲間も募集中です!
APCにご興味がある方の連絡をお待ちしております。