はじめに
GLB事業部Lakehouse部の佐藤です。 この記事では、Databricks モデルサービングへのモデルのセットアップ方法についてご紹介します。
モデルサービング(Model Serving)は、機械学習モデルをプロダクション環境で使用できる形で提供するプロセスを指します。これは、トレーニング済みの機械学習モデルを実際のアプリケーションやシステムに統合し、予測や推論を行うためのインフラを構築することです。
Databricksのモデルサービングは、Databricksプラットフォーム内でシームレスに統合されたソリューションであり、一般的なモデルサービングよりも管理の手間を軽減できます。
このブログで使用したノートブック
この記事では、こちらのサンプルコードを実行しています。
前提条件
- AWSに構築されたDatabricksワークスペース
- リージョンはus-east1(tokyoリージョンでモデルサービングはまだリリースされていないため)
- 15.1 MLクラスターを使用
ノートブックの概要
このノートブックでは、モデルサービングエンドポイントにテキストエンベディングモデルをセットアップします。 大まかな流れは以下の通りです。
- 前半:Hugging Face Hubからモデルをダウンロードし、MLflowモデルレジストリに登録
- 後半:モデルサービングエンドポイントを作成し、作成したエンドポイントを起動してクエリを実行
検証結果(前半)
Hugging Face Hubからダウンロードしたモデルを、MLflowモデルレジストリに登録する:
コードは以下の通りです。
registered_model_name = 'mihsato-e5-small-v2'
import mlflow signature = mlflow.models.signature.infer_signature(sentences, embeddings) print(signature)
model_info = mlflow.sentence_transformers.log_model( model, artifact_path="model", signature=signature, input_example=sentences, registered_model_name=registered_model_name)
mlflow_client = mlflow.MlflowClient() models = mlflow_client.get_latest_versions(registered_model_name, stages=["None"]) model_version = models[0].version model_version
コードを実行した結果、モデルの登録が出来ました。
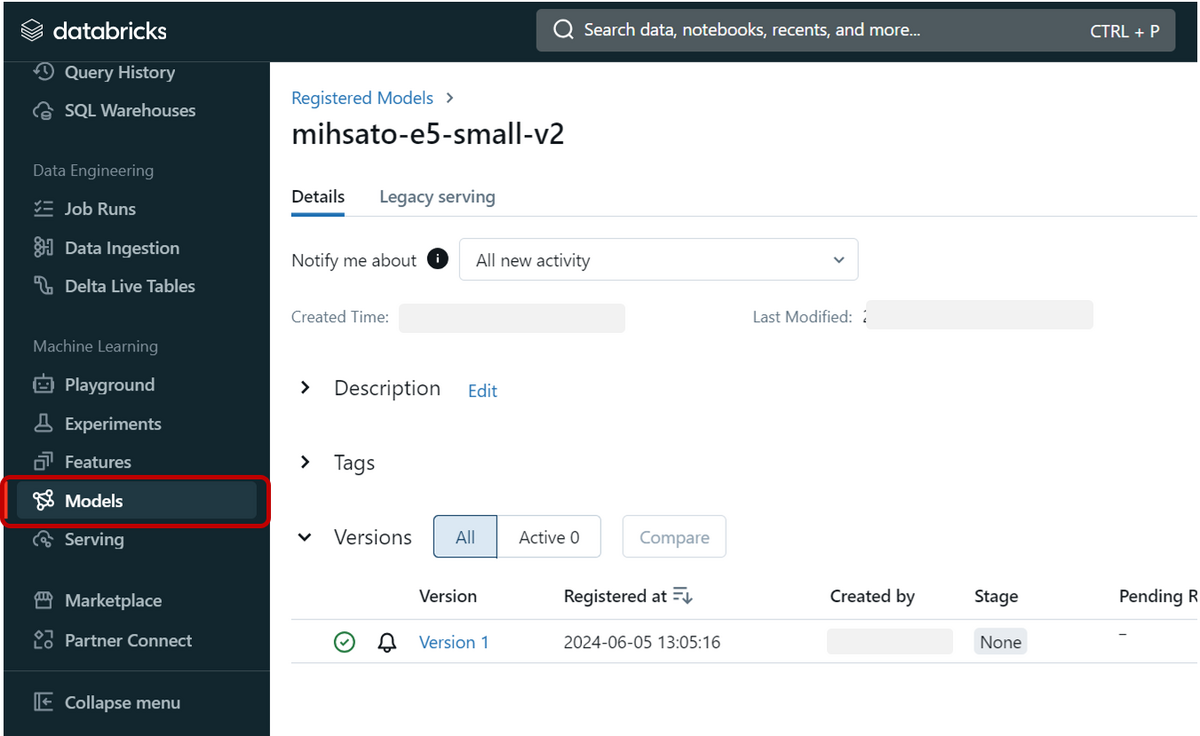
検証結果(後半)
モデルサービングエンドポイントを作成する:
コードは以下の通りです。
endpoint_name = "mihsato-e5-small-v2"
from databricks.sdk import WorkspaceClient from databricks.sdk.service.serving import EndpointCoreConfigInput w = WorkspaceClient()
endpoint_config_dict = {
"served_models": [
{
"name": f'{registered_model_name.replace(".", "_")}_{1}',
"model_name": registered_model_name,
"model_version": model_version,
"workload_type": "CPU",
"workload_size": "Small",
"scale_to_zero_enabled": True,
}
]
}
endpoint_config = EndpointCoreConfigInput.from_dict(endpoint_config_dict)
w.serving_endpoints.create_and_wait(name=endpoint_name, config=endpoint_config)
コードを実行した結果、モデルサービングエンドポイントが出来ました。
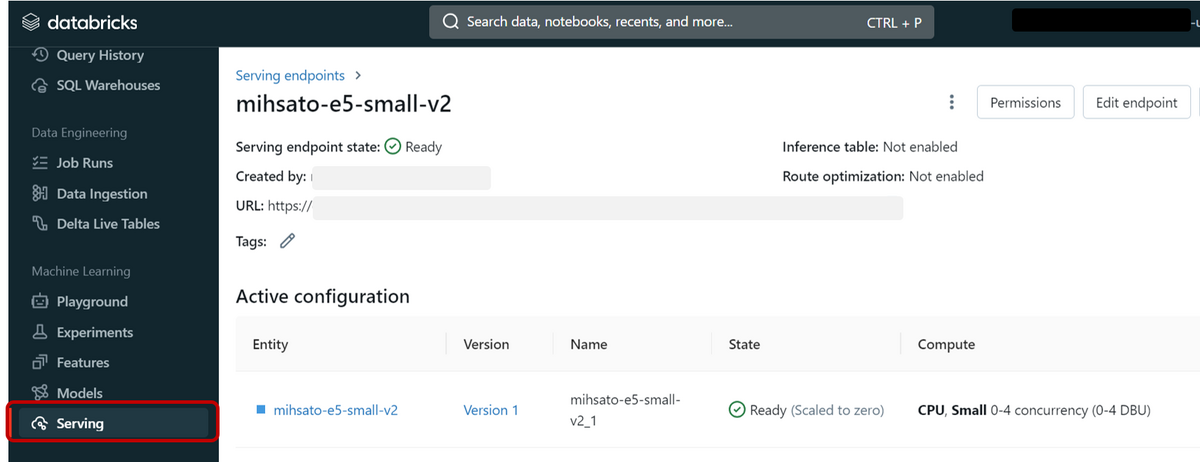
作成したエンドポイントを起動してクエリー:
コードは以下の通りです。
import time
start = time.time()
endpoint_response = w.serving_endpoints.query(name=endpoint_name, dataframe_records=['Hello world', 'Good morning'])
end = time.time()
print(endpoint_response)
print(f'Time taken for querying endpoint in seconds: {end-start}')
クエリーに対するベクトルと、計算にかかった時間が返ってきました。

おわりに
モデルサービングにLLMが複数セットアップされていたら、比較したり、アンサンブルしたいときにも便利そうだと感じました。
最後までご覧いただきありがとうございます。 私たちはDatabricksを用いたデータ分析基盤の導入から内製化支援まで幅広く支援をしております。 もしご興味がある方は、お問い合わせ頂ければ幸いです。