
はじめに
こんにちは、クラウドエンジニアリング部の本橋です。
現場の異動やAWSの試験がありバタバタしている間に前回から結構空いてしまいました。
前回はclient -> CloudFront -> S3へのアクセスをTLS通信化するところまでやりました。
前回記事はこちら
汎用的に使えそうなAWS構成 - 第2回 Route53/ACM 設定 - APC 技術ブログ
今回やること
前回までに作成した環境に①アクセスがあったときにログを出すように設定し、②Athenaでクエリを実行することを目標にします。
今回の範囲を図で示すと以下になります。
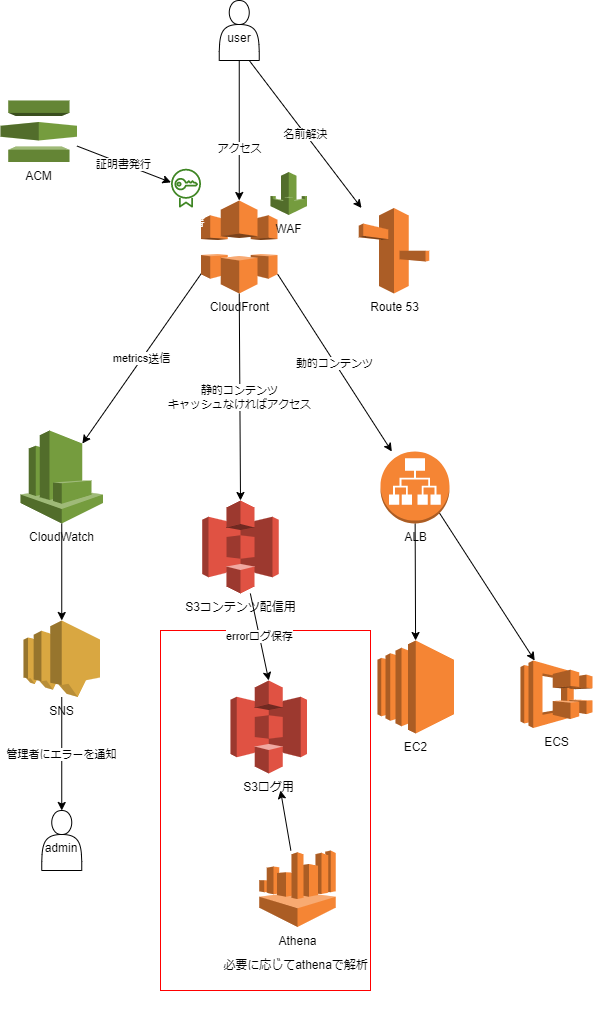
前回までの図の中ではCloudFrontからアクセスログを出力するようになっていましたが、
アクセスログの中身を確認した結果S3の方が面白そうだったのでアクセスログの出力元を変えてます。
①アクセスがあったときにログを出すように設定
まずはログを格納するS3を新たに作ります。すべてデフォルトで作成しました。
次に作成したS3側でログの格納を許可する設定をします。
以下のページを参考にしました。
Amazon S3 サーバーアクセスログを有効にします。 - Amazon Simple Storage Service
今回作成したS3に設定したバケットポリシー
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "S3ServerAccessLogsPolicy",
"Effect": "Allow",
"Principal": {
"Service": "logging.s3.amazonaws.com"
},
"Action": "s3:PutObject",
"Resource": "arn:aws:s3:::mmys30011224/logs/*",
"Condition": {
"StringEquals": {
"aws:SourceArn": "arn:aws:s3:::s3-sample5-images1"
}
}
}
]
}
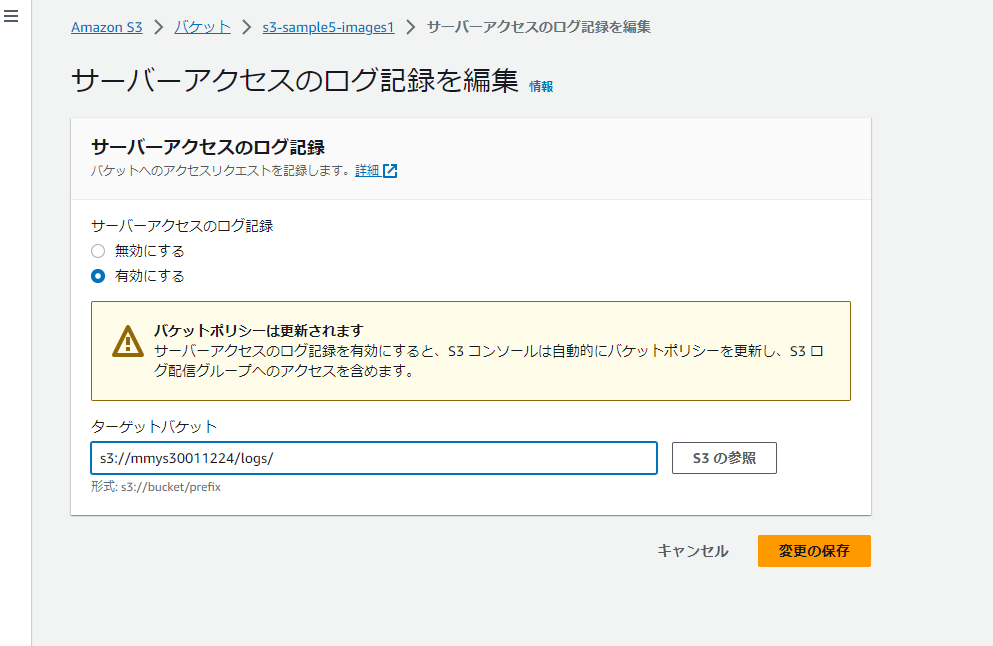
最後にアクセスログを発行する側のS3を設定します。
対象S3 -> 「プロパティ」 -> 「サーバーアクセスのログ記録」-> 「編集」 からアクセスログを有効にします。
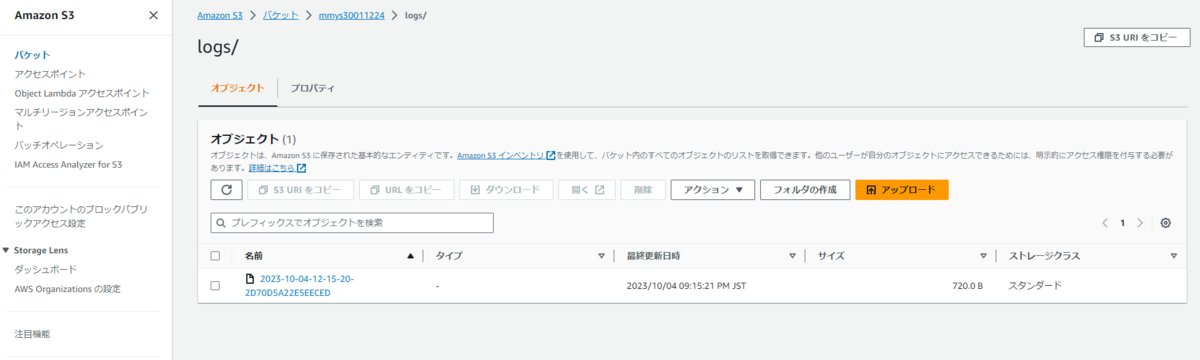
アクセスログはログ用バケットの/logsの下に設定しました。
サイトにアクセスしてしばらくするとアクセスログが出力されます。
想定通り/logsの下にアクセスログが出力されましたね。
②Athenaでクエリを実行
Athenaでクエリを実行するためにはデータカタログの作成が必要です。
調査した結果、一番シンプルな方法は手動でのdatabaseとtableの作成みたいなので今回はこちらでやります。
Athena を使用して Amazon S3 サーバーアクセスログを分析する方法を教えてください。
また、databaseとtableを作成するためのAthenaエディタを利用するにはワークグループの設定が必要でした。 Athena で Amazon S3 サーバーのアクセスログを分析する | AWS re:Post
以上をまとめると以下のようになります。
1.ワークグループを設定する
2.databaseを作成する
3.tableを作成する
1.ワークグループを設定する
Athenaページ -> 「ワークグループ 」-> 「ワークグループを作成」を選択
基本的にデフォルトで作成しました。
* 変更点
* ワークグループ名: test_work_group
* クエリ結果の設定 -> クエリ結果の場所: s3://mmys30011224/athena-output
2.databaseを作成する
クエリエディタに移動し、ワークグループに先ほど作成した「test_work_group」を設定。
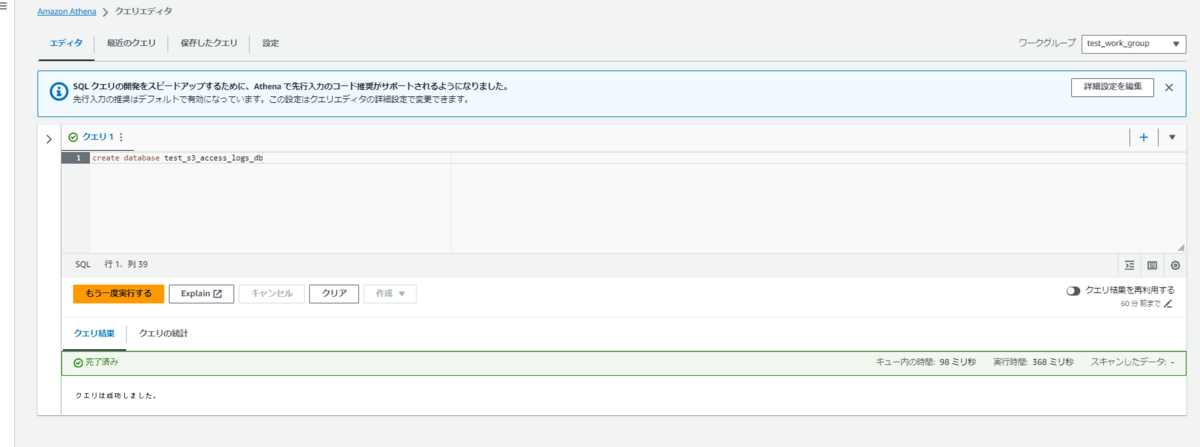
その後、database作成クエリを実行します。
コマンド
create database test_s3_access_logs_db
作成されたdatabaseはGlueページから確認可能です。

3.tableを作成する
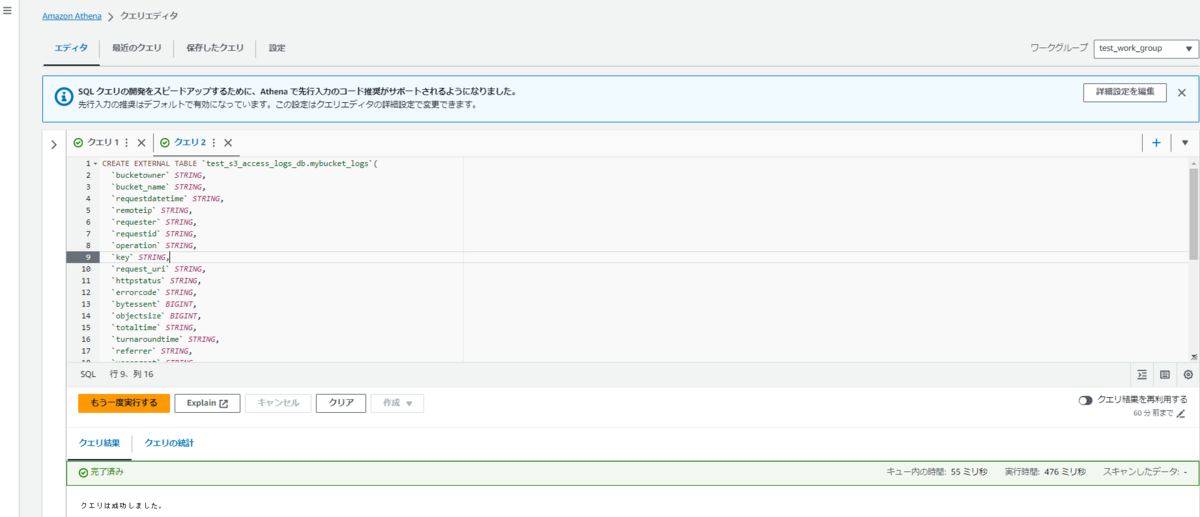
同じくクエリエディタで作成します。
基本的には上述のページに記載されているコマンドそのままですが、一行目のdatabase名とスキャン対象のLOCATIONの設定が必要です。
今回確認してませんが、tableもdatabase同様にGlueの画面から確認可能です。
コマンド
CREATE EXTERNAL TABLE `test_s3_access_logs_db.mybucket_logs`( `bucketowner` STRING, `bucket_name` STRING, `requestdatetime` STRING, `remoteip` STRING, `requester` STRING, `requestid` STRING, `operation` STRING, `key` STRING, `request_uri` STRING, `httpstatus` STRING, `errorcode` STRING, `bytessent` BIGINT, `objectsize` BIGINT, `totaltime` STRING, `turnaroundtime` STRING, `referrer` STRING, `useragent` STRING, `versionid` STRING, `hostid` STRING, `sigv` STRING, `ciphersuite` STRING, `authtype` STRING, `endpoint` STRING, `tlsversion` STRING) ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.RegexSerDe' WITH SERDEPROPERTIES ( 'input.regex'='([^ ]*) ([^ ]*) \\[(.*?)\\] ([^ ]*) ([^ ]*) ([^ ]*) ([^ ]*) ([^ ]*) (\"[^\"]*\"|-) (-|[0-9]*) ([^ ]*) ([^ ]*) ([^ ]*) ([^ ]*) ([^ ]*) ([^ ]*) (\"[^\"]*\"|-) ([^ ]*)(?: ([^ ]*) ([^ ]*) ([^ ]*) ([^ ]*) ([^ ]*) ([^ ]*))?.*$') STORED AS INPUTFORMAT 'org.apache.hadoop.mapred.TextInputFormat' OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat' LOCATION 's3://mmys30011224/logs/'
動作確認
出力したときに一番面白そうなerrorcodeを使って結果を出力してみます。
コマンド
SELECT errorcode, count(errorcode) as countOfErrorcode FROM test_s3_access_logs_db.mybucket_logs group by errorcode
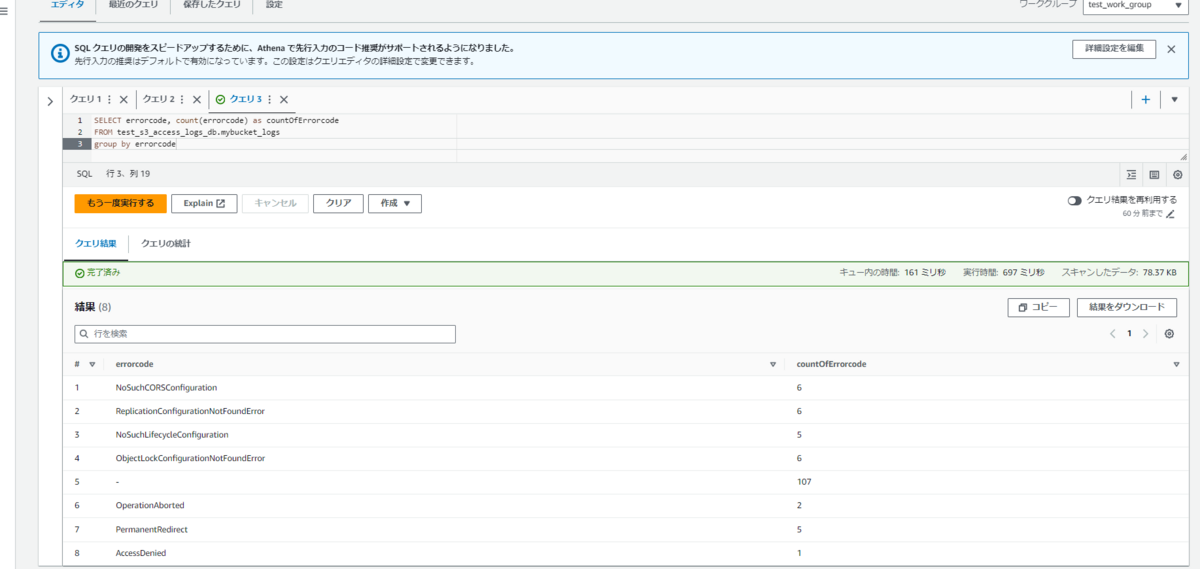
問題なくできました。
Terraform化
最後にterraform化して完了です(Athenaワークグループはできてないです。。)。
https://github.com/hsmto25519/aws_terraform
感想
今回すごく簡単なものですが、Athenaを使ってアクセスログを分析までやりました。
Athenaを利用するときの情報(database, tableなど)を手動で設定してますが、検証の前はGlue Crawlerを利用してデータカタログを作成する必要があると思っていました。
このような細かいところはAWS試験受験の際は気にすることはないので、改めて実際に手を動かして検証してみるのは大切だと思いました。
また、アクセスログには送信元IPアドレスも出力されていたので、IPアドレスをアクセス元地域(例えば日本、アメリカなど)に変換してからQuickSightで出力したらすごく面白そうでした。
ただ処理そのものが割と大変だったのとQuickSightを使うまでに社内でいろいろ手続きが必要そうだったので今回はやめました。
このあたりはAWSのマネージドサービスがうまいこと勝手にやってくれると思ってたのですが、そんなに甘くないんですね。勉強になりました。
今回検証が結構ハードだったこともありいろいろ感想があるのですが、長くなりそうなのでこの辺りで終わりにします。
最後までお読みいただきありがとうございます!
おわりに
APCはAWSセレクトティアサービスパートナー認定を受けております。

その中で私達クラウド事業部はAWSなどのクラウド技術を活用したSI/SESのご支援をしております。
https://www.ap-com.co.jp/service/utilize-aws/
また、一緒に働いていただける仲間も募集中です!
今年もまだまだ組織規模拡大中なので、ご興味持っていただけましたらぜひお声がけください。