
はじめに
GLB事業部Lakehouse部の鄭(ジョン)です。
Databricks Lakehouse Platformが提供するデモであるdbdemosの中で、dbt jobsの調整と実行をするデモを紹介したいと思います。
www.dbdemos.ai
今回の投稿はdbdemosを初めて使う初心者に参考になるガイドを作成することを目標にしています。
以下の内容は前回の記事に続きます。
techblog.ap-com.co.jp
前回に作成されたフォルダとdbt_c360_gold_churn_featureの作業について学びましょう。
目次
dbt jobsの流れ
dbt jobsは3つのタスクで構成されています。
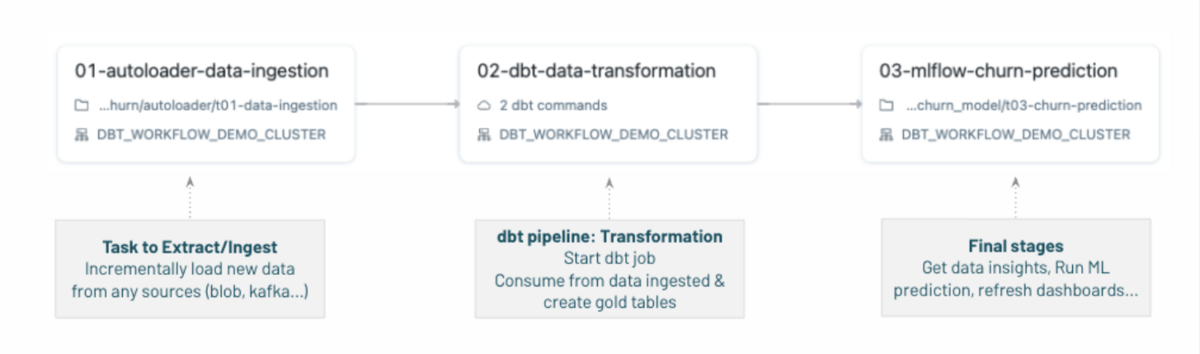
01-autoloader-data-ingestion: データブリックスのオートローダーを使用してブロックストレージからファイルを抽出した後、そのデータでブロンズテーブル(Rawテーブル)を作成します。
02-dbt-data-transformation: dbt パイプラインを実行して変換(transformations)を行い、このブロンズテーブルのデータを消費してシルバーテーブルとゴルドーテーブルを生成します。
03-ml-churn-prediction: 最終タスクのための最終作業でML予測モデルを活用してChurnを予測しました。Churnは解約を意味します。(契約、購読など顧客の離脱)
Reposに作成されたフォルダ
前回にdbdemosを読んでdbdemosの中にあるdbt-on-databricksを設置しました。
そうしたら自動的にReposにフォルダが作成されます。
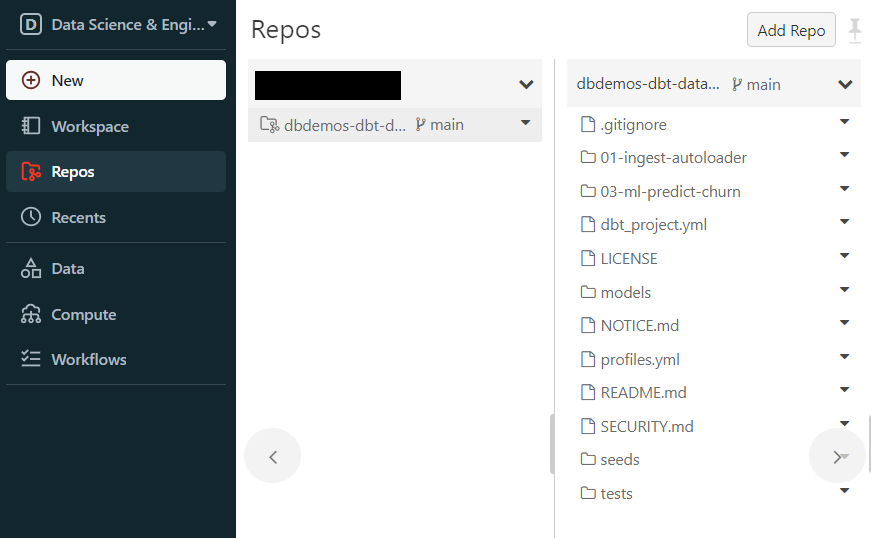
フォルダの構成
フォルダの構成を見たらプロジェクトの全体的な構成について知ることができます。
フォルダの説明は次のGitHubを引用しました。
github.com
各フォルダについて全体的な流れを理解しやすい順序で説明しました。
01-ingest-autoloader
ここにはRawデータをLakehouseに収集するためのノートブックがあります。
新しいデータがクラウドストレージにアップロードされたら、これを収集してdbtパイプラインを通じて変換することを目指します。
以下は、ファイルへのコードの一部抜粋です。
ストリームデータを読んでブロンズテーブルを作成する関数「incrementally_ingest_folder」を定義し、
引数はpath、format、tableをユーザーから入力し、
ブロンズ テーブルは、デルタテーブルに新しいデータが増分されます。
.trigger(availableNow=True) クエリは複数のマイクロバッチを実行し、すべてのデータを処理してから停止します。
def incrementally_ingest_folder(path, format, table): (spark.readStream # ストリームデータを読みます。 .format("cloudFiles") cloudFiles # ストリームデータのフォーマットはcloudFilesです。(オートローダー .option("cloudFiles.format", format) # cloudFilesのフォーマットを変数formatの形に変えます。) .option("cloudFiles.inferColumnTypes", "true") # スキーマの推論を利用するときに、Columnを使います。 .option("cloudFiles.schemaLocation", f"/dbdemos/dbt-retail/_schemas/{table}") # 推論されたスキーマとそれ以降の変更を保存する場所です。 .load(path) # pathを読みます。 .writeStream # ストリーム データを作成します。 .format("delta") #デルタテーブルで作成します。 .option("checkpointLocation", f"/dbdemos/dbt-retail/_checkpoints/{table}") # ストリーミングのメタデータを保存する場所を設定します。 .trigger(availableNow = True) # 複数のマイクロバッチを実行し、すべてのデータを処理してから停止します。 .outputMode("append") #ストリーミングされた新しいデータは、テーブルに追加される形式で更新します。 .toTable(table)) # テーブルの名前を読みます。
関数「incrementally_ingest_folder」を使って3つのブロンズテーブルを作ります。('dbdemos.dbt_c360_bronze_users', 'dbdemos.dbt_c360_bronze_orders', 'dbdemos.dbt_c360_bronze_events')
それぞれのテーブルのフォーマットはjson、json、csvです。
incrementally_ingest_folder('/dbdemos/dbt-retail/users', 'json', 'dbdemos.dbt_c360_bronze_users') incrementally_ingest_folder('/dbdemos/dbt-retail/orders', 'json', 'dbdemos.dbt_c360_bronze_orders') incrementally_ingest_folder('/dbdemos/dbt-retail/events', 'csv', 'dbdemos.dbt_c360_bronze_events')



dbt_project.yml
ここにはDatabricks SQL warehouseへの接続設定やSQL変換ファイルの保存場所などの情報が含まれています。
全てのdbtプロジェクトにはdbt_project.ymlが必要です。
これを通じてディレクトリが dbt プロジェクトであることを dbt が認識できるように手伝います。
以下は、dbt_project.ymlファイルのコードの一部抜粋です。
- 各タグの説明はコメントを作成しました。
name: 'dbdemos_dbt_c360' -- プロジェクト名で文字と数字とアンダースコアで書きます。 config-version: 2 -- バージョン名 version: '0.1' -- バージョン名 profile: 'dbdemos_dbt_c360' -- dbtでプロファイルはDWの接続設定名を指します。 model-paths: ["models"] -- モデルとソースを配備するパスを指定します。 seed-paths: ["seeds"] -- テスト用のデータであるシードファイルを配備するパスを指定します。 test-paths: ["tests"] -- テストコードを配備するバスを指定する。 dbt のテストで使います。 analysis-paths: ["analysis"] -- 分析用の SQL を配置するパスを指定します。 macro-paths: ["macros"] -- マクロを配備するパス。 target-path: "target" -- dbt コマンドの出力先パスを指定します。 clean-targets: -- 削除対象のディレクトリを指定します。 - "target" - "dbt_modules" - "logs" require-dbt-version: [">=1.0.0", "<2.0.0"] -- 特定のdbtバージョンでのみ動作するようにプロジェクトを制限します。 models: -- モデルの設定を記述します。 dbdemos_dbt_c360: materialized: table staging: materialized: view
タグの説明は次のブログとdbtサイトを引用しました。 zenn.dev docs.getdbt.com
models
dbt のモデルは、モジュール単位のデータ変換ブロックを含む単一の .sql ファイルを参照します。
ここではMedallion Architectureに従って変換(transformations)を 4 つのファイルにモジュール化しました。
('dbt_c360_silver_events.sql', 'dbt_c360_silver_orders.sql', 'dbt_c360_silver_users.sql', 'dbt_c360_gold_churn_features.sql')
各ファイル内では、変換の具体的な方法をテーブルやビューとして設定できます。
Medallion Architectureについての詳細は次のサイトをご確認ください。
メダリオンアーキテクチャ | Databricks
以下は、ファイルへのコードの一部抜粋です。(dbt_c360_silver_events.sql)
- 上で作成したブロンズテーブルから希望する情報を選んでデルタテーブルの形でシルバーテーブルを作成しました。
{{config(materialized = 'table', file_format = 'delta')}}
select
user_id,
session_id,
event_id,
`date`,
platform,
action,
url
from dbdemos.dbt_c360_bronze_events

以下は、ファイルへのコードの一部抜粋です。(dbt_c360_silver_orders.sql)
上で作成したブロンズテーブルから希望する情報を選んでデルタテーブルの形でシルバーテーブルを作成しました。
to_timestamp, castを使ってタイプを変更するなどデータの前処理をします。
{{
config(materialized = 'table', file_format = 'delta')
}}
select
cast(amount as int), -- intタイプに変換する関数
`id` as order_id,
user_id,
cast(item_count as int), -- intタイプに変換する関数
to_timestamp(transaction_date, "MM-dd-yyyy HH:mm:ss") as creation_date -- DatetimeIndexで変換する関数
from dbdemos.dbt_c360_bronze_orders

以下は、ファイルへのコードの一部抜粋です。(dbt_c360_silver_users.sql)
上で作成したブロンズテーブルから希望する情報を選んでデルタテーブルの形でシルバーテーブルを作成しました。
to_timestamp, initcap, castを使ってタイプを変更するなどデータの前処理をします。
{{
config(materialized = 'table', file_format = 'delta')
}}
select
id as user_id,
sha1(email) as email, -- 長さの異なる文字列を同じ長さに変換できるハッシュ関数
to_timestamp(creation_date, "MM-dd-yyyy HH:mm:ss") as creation_date, -- DatetimeIndexで変換する関数
to_timestamp(last_activity_date, "MM-dd-yyyy HH:mm:ss") as last_activity_date, -- DatetimeIndexで変換する関数
initcap(firstname) as firstname, -- 最初の文字だけを大文字の残りの小文字で出力する関数
initcap(lastname) as lastname, -- 最初の文字だけを大文字の残りの小文字で出力する関数
address,
canal,
country,
cast(gender as int), -- intタイプに変換する関数
cast(age_group as int), -- intタイプに変換する関数
cast(churn as int) as churn -- intタイプに変換する関数、ブロンズ テーブルではtrue、false
from dbdemos.dbt_c360_bronze_users

以下は、ファイルへのコードの一部抜粋です。(dbt_c360_gold_churn_features.sql)
上記のシルバーテーブルから予測モデルに使用する変数を選別してゴールドテーブルを作ㅁります。
3 つのシルバー テーブルのプライマリ キーであるユーザー ID でインナー ジョインして合わせます。
変数は予測モデルのfeatureとして使用できるようにユーザーIDでグループ化し、集計関数を通じて数値化します。
{{
config(materialized = 'table', file_format = 'delta')
}}
-- block 1 --
churn_orders_stats as
(select user_id,
count(*) as order_count, -- 注文件数
sum(amount) as total_amount, -- 総額
sum(item_count) as total_item, -- 製品購入数
max(creation_date) as last_transaction -- 最後の取引
from {{ref('dbt_c360_silver_orders')}}
group by user_id -- ユーザーID別
),
-- block 2 --
churn_app_events_stats as
(
select first(platform) as platform,
user_id,
count(*) as event_count, -- イベント数
count(distinct session_id) as session_count, -- セッション数
max(to_timestamp(date, "MM-dd-yyyy HH:mm:ss")) as last_event -- 最後のイベントの日付
from {{ref('dbt_c360_silver_events')}}
group by user_id
) -- ユーザーID別
select *,
datediff(now(), creation_date) as days_since_creation, -- 加入期間
datediff(now(), last_activity_date) as days_since_last_activity, -- 最後の活動がいつなのか
datediff(now(), last_event) as days_last_event -- 最後のイベントに参加してから過ぎた時間
from {{ref('dbt_c360_silver_users')}}
inner join churn_orders_stats using (user_id)
inner join churn_app_events_stats using (user_id)

tests
テストは、dbt モデルについて行うアサーションです。
普通はデータの品質と検証を目的に使います。
また特定のアサーションに失敗した記録を隔離および分離する機能もあります。
以下は、コードの一部抜粋です。
- 販売総額がマイナスの場合は、ユーザーidと販売総額の記録を別に作成して隔離しています。
{{ config(store_failures = true) }} -- 失敗したときに保存します。
select
user_id,
sum(amount) as total_amount
from {{ref('dbt_c360_silver_orders')}}
group by 1 -- 最初のコラムにグループ化します。
having not (total_amount >= 0)
03-ml-predict-churn
ここにはdbt 変換が完了した後、MLFlowから Churn 予測 MLモデルをロードするためのノートブックが含まれています。
モデル予測を含むゴールドテーブル「dbt_c360_gold_churn_predictions」はBI 分析を作って、Churnを減らすためのアクションを実行するために利用できます。
Churnモデルの作成はこのデモの中にないため。ここにダミーモデルを作成します。
以下は、コードの一部抜粋です。
- MLを実行できる実験スペースを作成します。
from mlflow.store.artifact.models_artifact_repo import ModelsArtifactRepository import os import mlflow.pyfunc import mlflow from mlflow import MlflowClient import random mlflow.autolog(disable=True) def init_experiment_for_batch(path, experiment_name): # MLを実行できる実験スペースを作成する関数です。 pat_token = dbutils.notebook.entry_point.getDbutils().notebook().getContext().apiToken().get() # ワークスペースのtokenを自動的に読み込みます。 url = dbutils.notebook.entry_point.getDbutils().notebook().getContext().apiUrl().get() # ワークスペースのurlを自動的に読み込みます。 import requests requests.post(f"{url}/api/2.0/workspace/mkdirs", headers = {"Accept": "application/json", "Authorization": f"Bearer {pat_token}"}, json={ "path": path}) # 接続するurlにpathにあるデータを送信します。 headersはheaderの情報です。 xp = f"{path}/{experiment_name}" print(f"Using common experiment under {xp}") mlflow.set_experiment(xp) # experimentを作ります。 init_experiment_for_batch("/Shared/dbdemos/dbt", "03-churn-prediction") # "/Shared/dbdemos/dbt"にexperiment"03-churn-prediction"を作ります。 # path: /Shared/dbdemos/dbt # experiment_name: 03-churn-prediction

- MLFlow からモデルをロードします。
リモートレジストリの情報は次のURLをご確認ください。
https://www.dbdemos.ai/minisite/lakehouse-retail-c360/04-Data-Science-ML/04.3-running-inference.html
- ダミーモデルを作ります。
try: model_name = "dbdemos_churn_dbt_model" model_uri = f"models:/{model_name}/Production" local_path = ModelsArtifactRepository(model_uri).download_artifacts("") # リモートレジストリからモデルをダウンロードします。(Lakehouse for C360 demoで作ったモデルです。 ) except Exception as e: print("Model doesn't exist "+str(e)+", will create a dummy one for the demo. Please install dbdemos.install('lakehouse-retail-c360') to get a real model") # モデルがない場合の対処方法 class dummyModel(mlflow.pyfunc.PythonModel): # class dummyModelを作ります。 def predict(self, model_input): # 関数predictを作ります。 return model_input['user_id'].map(lambda x: random.randint(0, 1)) # map()で反復的に関数を実行します。 user_id ごとに 0 と 1 の間の任意の整数を生成します。 model = dummyModel() # modelにclass dummyModelを入れてくれます。 with mlflow.start_run(run_name="dummy_model_for_dbt") as mlflow_run: m = mlflow.sklearn.log_model(model, "dummy_model") # モデルを保存します。 model_registered = mlflow.register_model(f"runs:/{ mlflow_run.info.run_id }/dummy_model", model_name) # レジスタモデルを作成します。 client = mlflow.tracking.MlflowClient() # 過去の履歴確認可能client.transition_model_version_stage(model_name, model_registered.version, stage = "Production", archive_existing_versions=True) #レジスタモデルのversionのstageを"Production"で変更します。

- ダミーモデルを通じてChurn を予測します。
import mlflow from pyspark.sql.functions import struct predict = mlflow.pyfunc.spark_udf(spark, f"models:/dbdemos_churn_dbt_model/Production", result_type="double") spark.udf.register("predict_churn", predict) #Python 関数をSQL 関数で変換します。
モデルについての詳細は次のイメージとサイトをご確認ください。("04-Data-Science-ML"パート)

- Churn を予測されるゴルドーテーブルを作ります。('dbdemos.dbt_c360_gold_churn_predictions')
CREATE OR REPLACE TABLE dbdemos.dbt_c360_gold_churn_predictions AS SELECT predict_churn(struct(user_id, age_group, canal, country, gender, order_count, total_amount, total_item, platform, event_count, session_count, days_since_creation, days_since_last_activity, days_last_event)) as churn_prediction, * FROM dbdemos.dbt_c360_gold_churn_features
- SELECT文を使ってChurnの予測を確認します。
SELECT user_id, platform, country, firstname, lastname, churn_prediction FROM dbdemos.dbt_c360_gold_churn_predictions LIMIT 10;

seeds
CSV ファイルを保存するために使用するオプションのフォルダです。

まとめ
今回はdbdemosを利用してインストールしたフォルダの構成を見ながら、プロジェクトの全般的な構成について学びました。
RawデータをLakehouseに収集するブロンズテーブル、ブロンズテーブルから希望する情報を選択するシルバーテーブル、Churnを予測するダミーモデルで作られたゴールドテーブルまで調べながら、Medallion Architectureの変換を見ました。
dbt_project.ymlのタグを通じてdbtの構成について学びました。
今回の投稿がdbdemosを初めて使用した初心者の方の参考になればと思います。
最後までご覧いただきありがとうございます。
引き続きどうぞよろしくお願い致します!

私たちはDatabricksを用いたデータ分析基盤の導入から内製化支援まで幅広く支援をしております。
もしご興味がある方は、お問い合わせ頂ければ幸いです。
また、一緒に働いていただける仲間も募集中です!
APCにご興味がある方の連絡をお待ちしております。