
Databricks Data + AI Summit 2025 Keynote 1日目
Databricks Data + AI Summit 2025のKeynote 1日目では、データとAIの民主化をさらに推進し、企業におけるAI活用を加速させるための画期的な発表がいくつもありました。データとAIの複雑な環境をシンプルにし、より多くの人がAIを活用できるようにするというDatabricksのビジョンが色濃く反映されていたように感じられます。
Keynoteに登壇したDatabricksのAli Ghodsi CEOは、カンファレンスがこの10年で大きく成長し、データとAIの融合が深まっていることに触れていましたね。現在では、モスコーンセンターに2万2,000人以上が参加し、世界中で6万5,000人がオンラインで視聴しているとのことです。これはまさに、データとAIへの関心が世界中で高まっている証拠と言えるでしょう。
また、これまでのデータ・AI分野は、多くのシステムが独自データを持ち、高コストやベンダーロックインに悩まされてきたと指摘されていました。これに対し、DatabricksはUnity Catalogを通じた統一ガバナンスとオープンフォーマット(Delta LakeやApache Iceberg)を基盤とすることで、この複雑さを解消し、データとAIの民主化を進めるという明確な戦略を示していました。
今回のKeynoteで発表された主要なサービスは、まさにこの戦略を具現化するものばかりでした。
今回発表された主要サービスの一覧
Databricks Data + AI Summit 2025 初日Keynoteで発表された主要項目を、それぞれの概要と現時点でのステータスと共にまとめました。
| サービス名 | サービス概要 | 現時点(2025/06)のステータス |
|---|---|---|
| Lakebase | Databricksが「AI時代のための新しいデータベースカテゴリー」として発表した、レイクハウスに深く統合されたフルマネージドPostgreSQL互換OLTPデータベースです。トランザクション処理と分析・AIワークロードのシームレスな統合を目指しています。 | Public Preview |
| Databricks Apps | Databricksプラットフォーム上でインタラクティブなデータ&AIアプリケーションを安全に構築・デプロイ・スケールするためのフルマネージドサービスです。データサイエンティストや開発者が素早くアプリケーションを本番展開できることを狙っています。 | 一般提供 (GA) |
| Agent Bricks | 生成AIを用いた企業向けAIエージェントを迅速かつ高品質に構築・運用するための新サービスで、宣言的なアプローチによってユーザーがタスクを記述するだけで最適なエージェントを自動生成・チューニングできることを目指しています。 | Beta |
| MLflow 3.0 | 機械学習ライフサイクル管理プラットフォームMLflowのメジャーアップデート版で、従来の機械学習・ディープラーニングから生成AIまでを単一プラットフォームで統合的に管理することを目的としています。 | 一般提供 (GA) |
| GPUのサーバレス対応 | Databricksプラットフォームにおけるサーバレスコンピュート機能がGPUインスタンスに拡張対応したものです。ユーザーがインフラ構築せずにオンデマンドで高性能GPUリソースを利用可能となります。 | Beta (A10G) |
| MCP on Databricks | AIエージェントが外部のデータやツールにアクセスするためのオープン標準プロトコル(Model Context Protocol)のDatabricksプラットフォームへの正式対応です。カスタムコネクタ実装の手間を減らすことを目指します。 | Beta |
| Databricks Free Edition | Databricks社が発表した無償利用枠のプラットフォーム環境で、従来有償版でしか使えなかった多くの機能を開放し、幅広い層がクレジットカード不要でDatabricksを体験・習得できるようにしています。 | 提供開始 |
各サービスの詳細
それでは、それぞれのサービスについてもう少し詳しく見ていきましょう。
Databricks Free Edition
今回のDatabricks Free Editionの発表は、特にデータとAIを学び始めたい方々にとって、非常に大きなニュースだったのではないでしょうか。Databricks社は、このサービスを「オープンソースと教育への原点回帰」と位置づけており、データとAIのスキル不足という課題を解決するために、今後3年間で1億ドルを教育投資に投じる計画があるそうです。
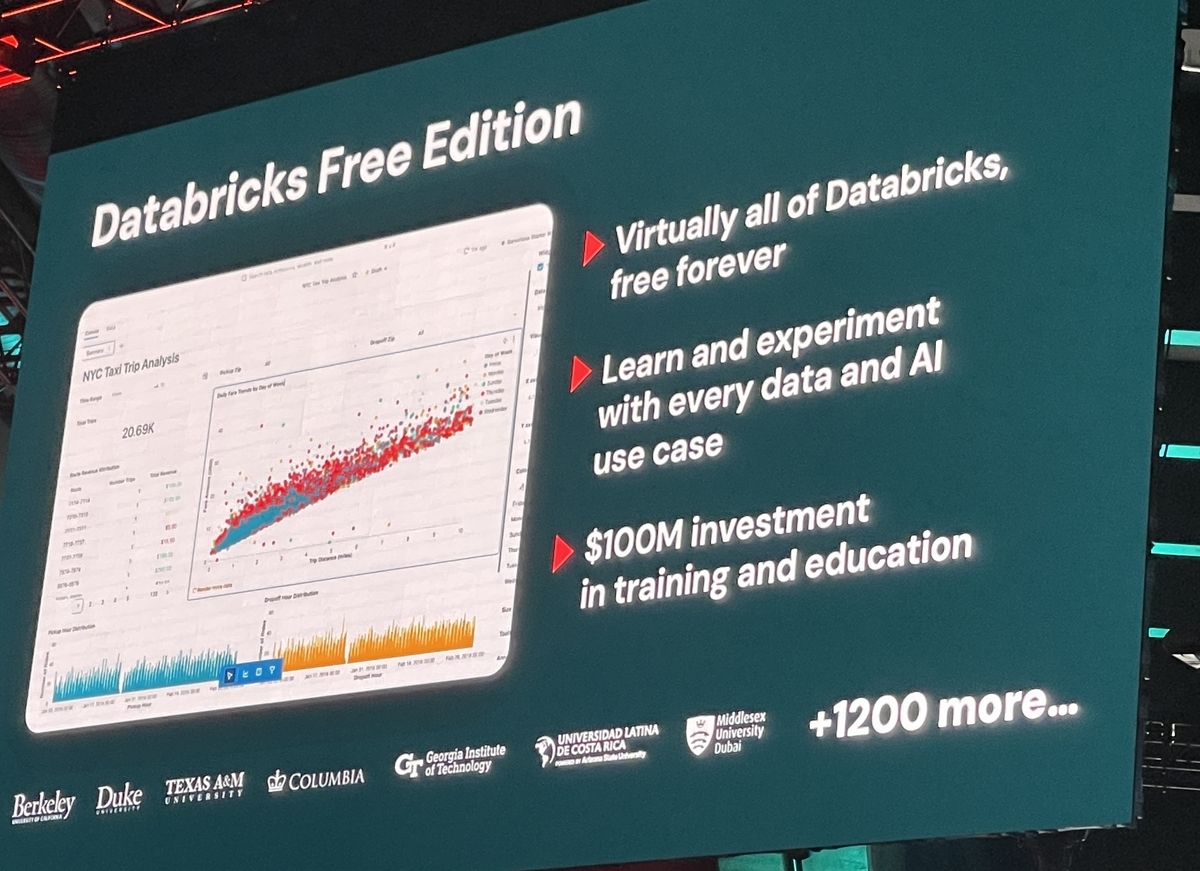 このFree Editionは、学習や実験目的でDatabricksプラットフォームを利用できる無償枠の環境を提供しています。これまで有償版でしか使えなかった多くの機能が開放され、なんとクレジットカードの登録もビジネス用メールアドレスも不要で、個人のメールアドレス(GmailやHotmailなど)があれば永続的に無料でアクセスできるようになりました。これは、学生や研究者、意欲的な開発者など、幅広い層がDatabricksのデータ&AIプラットフォームを気軽に体験・習得できる素晴らしい機会です。
このFree Editionは、学習や実験目的でDatabricksプラットフォームを利用できる無償枠の環境を提供しています。これまで有償版でしか使えなかった多くの機能が開放され、なんとクレジットカードの登録もビジネス用メールアドレスも不要で、個人のメールアドレス(GmailやHotmailなど)があれば永続的に無料でアクセスできるようになりました。これは、学生や研究者、意欲的な開発者など、幅広い層がDatabricksのデータ&AIプラットフォームを気軽に体験・習得できる素晴らしい機会です。
具体的に何ができるかというと、ノートブックを使ったデータ処理、SQLエディタ、ダッシュボード作成、Lakehouse上の主要ツールなど、Databricksのコア機能が一通り利用可能です。Sparkによるデータ処理や機械学習ワークフロー、BIダッシュボード、データパイプラインを構築するLakeflow、さらにはAIアシスタント機能「Databricks Assistant」も使えるとされています。
さらに嬉しいことに、Databricks Academyで提供されている数百時間分の自己学習コースが全て無償化されました。これにより、ユーザーはFree Edition上で実践しながら、データエンジニアリング、データサイエンス、機械学習、そして生成AIといった各分野のコースを無料で受講できます。これはまさに、実践的なスキルを身につけるための理想的な環境と言えるでしょう。
もちろん、学習・試用目的のエディションなので、計算リソースや機能にはいくつか制約があります。たとえば、クラスターは小規模に限定され、長時間の大規模計算には向かないそうです。また、DBFS(分散ファイルシステム)への直接アップロードはできず、Unity Catalog経由のボリュームを使う必要があるといった制限も報告されています。あくまで個人利用や小規模なプロジェクト向けであり、本格的な商用目的の処理には有償版へのアップグレードが必要になる点は注意しておきたいですね。Free Editionから直接有償版へのアップグレードパスはないので、もし本格的に使いたくなったら、新たにトライアルを始める必要があるようです。
Databricks Free Editionは、学習とエコシステム拡大へのDatabricksの強いコミットメントを示すもので、データとAIに興味があるすべての人にとっての入り口になりそうですね。
- 公式情報リンク:
- Databricks公式ブログ記事: Introducing Databricks Free Edition
- Databricks公式ページ: Free Edition
Lakebase
Databricks Data + AI Summit 2025の初日Keynoteで特に注目を集めたのが、Lakebase(レイクベース) の発表でした。Databricksはこれを「AI時代のための新しいデータベースカテゴリー」として打ち出しており、従来のデータベースの常識を覆す可能性を秘めていると感じています。
なぜDatabricksが「新しいデータベースカテゴリー」を作る必要があったのか、その背景には、既存のデータベースがAI用途に十分対応できていないという強い問題意識があります。Ali Ghodsi CEOは、OracleやSQL Server、MySQLといった従来のトランザクションデータベース(OLTPデータベース)は過去40年間ほとんど変わっておらず、データが「スティッキー(固定化)」で、高コストなベンダーロックインに苦しんでいると強調していました。一度データが格納されると、他のシステムへの移行が非常に困難になり、ベンダー側も革新の必要性を感じにくい状況だったわけです。また、これまでのデータベースはクラウドやAIを念頭に設計されておらず、手動での介入や保守が複雑で、スケールアウトも難しいという課題がありました 。
これに対し、LakebaseはLakehouse(レイクハウス)に深く統合されたフルマネージドのPostgreSQL互換OLTPデータベースとして登場しました。その最大の目的は、トランザクション処理(OLTP)と分析・AIワークロードをシームレスに統合することにあります。これまでのシステムでは、リアルタイムデータをアプリケーションに投入し、それをAIに活用するためには、データのサイロ化や煩雑なETL(Extract, Transform, Load)プロセスが必要でした。しかし、Lakebaseを使うことで、そのような手間を省き、Lakehouse上で直接トランザクションDBを持てるようになります。これは、データがアプリケーションと分析・AIワークロードの間でスムーズに流れるようになることを意味し、企業がリアルタイムデータから迅速に価値を引き出す上で大きな意義がありますよね。
Lakebaseの主な特徴を見ていくと、その革新性がよくわかります。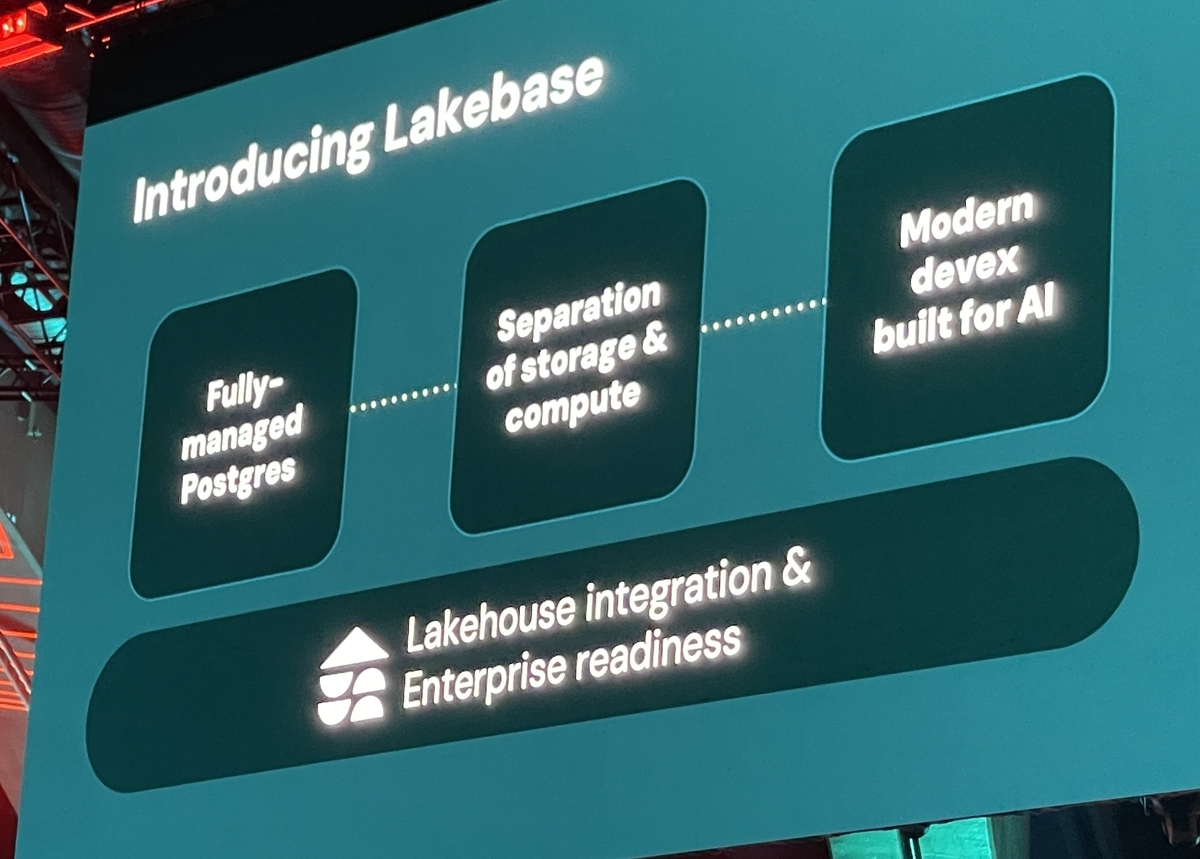 まず、オープンソースのPostgresエンジンを基盤としているため、PostgreSQLの広大なエコシステムや豊富な拡張機能(PostGISやpgvectorなど)を活用できる点が開発者にとって非常に魅力的です。
まず、オープンソースのPostgresエンジンを基盤としているため、PostgreSQLの広大なエコシステムや豊富な拡張機能(PostGISやpgvectorなど)を活用できる点が開発者にとって非常に魅力的です。
次に、最も重要なアーキテクチャの変更点として、コンピュート(計算処理)とストレージの分離 が挙げられます。Databricksは最近、この技術に強みを持つNeon社を約10億ドルで買収しており、その技術がLakebaseの基盤となっています。この分離アーキテクチャによって、Lakebaseは超低レイテンシー(10ms未満)、高いTPS(transactions per second、10,000QPS超)、そして99.999%の高可用性を実現しています。データは低コストなオブジェクトストレージ(S3, ADLS, GCSなど)にオープンフォーマットで保存され、トランザクション処理はベース層で行うというアプローチです。
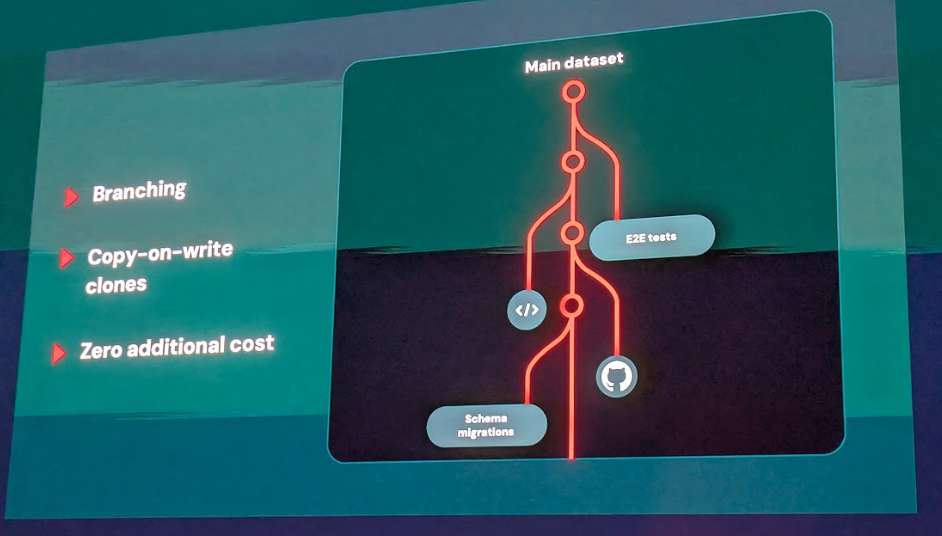
さらに、開発者体験を大きく向上させる機能として、コピーオンライトのブランチ機能 があります。これにより、データベース全体(データとトランザクションストリームを含む)のクローンを1秒未満で作成でき、変更を加えない限り追加のストレージコストは発生しません。これは、CI/CDのようなモダンな開発ワークフローやAIエージェントベースの開発において、コードのブランチを切るようにデータベースのブランチも瞬時に作成・破棄できることを意味し、非常にコスト効率が良いとされています。
また、自動スケーリングが可能な サーバレスコンピュート も特徴で、データベースは1秒未満で起動し、負荷に応じて迅速にスケールアップ/ダウンし、利用がない時にはゼロまでスケールダウンして、使った分だけ料金を支払うモデルになっています。これは、大量のAIエージェントが一時的にデータベースを必要とするようなユースケースに最適ですね。

Databricksの既存サービスとの統合も非常に深く、Unity Catalogによる統一ガバナンス、Delta LakeによるCDC(変更データキャプチャ)管理、Featureストア・モデルサービングとの連携、そしてRAG(検索強化型生成)をはじめとするAI・MLワークロードとのネイティブな統合も実現しています。実際に、Neon社の元CEOであるNikita氏によると、Neon.com上のデータベースの80%以上がAIエージェントによって作成されている実績があるそうで、AI時代に対応した設計であることがわかります。
現在のステータスとしては、Lakebaseは2025年6月時点でPublic Preview段階です。すでに数百社の顧客が多様なユースケースで利用を始めており、AWSおよびAzure上でプレビュー提供されています。Google Cloud Platform (GCP)への対応も今後予定されているとのことです。
今後の予定としては、公式なGA時期はまだ言及されていませんが、Lakehouseとの一体化をさらに深める機能拡充(例:レイクハウス内の自動同期やより多くの分散トランザクション最適化)がロードマップ上に予想されます。また、既存のデータベースからLakebaseへの移行を容易にするためのツール群「Lakebridge」の提供もアナウンスされており、移行パスも考慮されているようです。
現時点では、その内部実装の詳細や具体的な性能ベンチマーク、料金体系については十分な情報が公開されていない部分もあります。しかし、LakebaseはDatabricksが分析分野での強固な地位から、運用データベース市場へと積極的に進出し、AI時代のデータ管理を根本から変えようとする、非常に戦略的な取り組みと言えるでしょう。
- 公式情報リンク:
- Databricks公式ドキュメント: Lakebaseとは何ですか?
Databricks Apps
Databricks Appsは、Databricksプラットフォーム上でデータとAIを活用したインタラクティブなアプリケーションを、より簡単に構築・デプロイ・スケールできるようにするフルマネージドサービスです。このサービスは、データサイエンティストや開発者が、苦労せずに作ったアプリケーションを本番環境へ展開できるようにすることを目指しています。
このDatabricks Apps、実は2024年11月には既にPublic Previewとして公開されていたんですよ。そして、今回のDatabricks Data + AI Summit 2025で、ついに 一般提供(GA) が開始されました!プレビュー期間中には、2,500以上の顧客が20,000を超えるアプリを作成したそうで、Databricks史上最も急速に成長したプレビュー製品だったというから驚きですよね。これは、企業がデータとAIの成果をアプリケーションとして迅速に形にしたいというニーズが非常に高いことを示していると言えるでしょう。
特にGAで強化されたり、明確になったりした点はいくつかあります。
- サポートフレームワークの拡充: これまでStreamlit、Dash、GradioといったPythonの人気フレームワークをサポートしていましたが、GAでは新たにNode.jsやReactを含むJavaScriptフレームワークのサポートが発表されました。これにより、より多くの開発者が慣れ親しんだ言語やツールでアプリを構築できるようになりましたね。25種類のプリインストール済みオープンソースパッケージも提供されるので、すぐに開発を始めやすい環境が整っています。
- Lakebaseとの統合: 今回のKeynoteで発表された新しいOLTPデータベースサービス「Lakebase」との「ワンクリック統合」が発表されました。これにより、データインテリジェンスアプリを新しいデータベースプラットフォーム上で簡単に展開できるようになります。
- App Builderエコシステムの発表: Databricksは「App Builderエコシステム」というコンセプトを発表しました。これは、AIベースのコーディング、ビジュアル編集、直接コーディングなど、あらゆるインターフェースや構成をサポートし、Databricksのパートナーと連携することで、最新の開発環境を提供していくというものです。Superblocksのようなパートナーとの連携もデモで紹介されていましたね。

Databricks Appsは、開発者がアプリをローカルで開発し、Databricksワークスペースにデプロイして共有できる点が魅力です。Databricksの既存インフラ上にセキュアなマルチテナント環境として動作し、Unity Catalogによるデータガバナンス、Databricks SQLによるデータクエリ、モデルサービング、Lakeflow(ETLバッチ)、OAuth/サービスプリンシパルによる認証統合など、プラットフォームの主要サービスとシームレスに統合されます。これにより、データやAIワークロードに特化した社内向けアプリを容易に構築できます。
典型的なユースケースとしては、インタラクティブなデータ可視化ダッシュボード、RAG(検索強化型生成)チャットボットアプリ、社内運用ツールなどが挙げられます。ブリヂストンのLLM社内利用アプリや、武田薬品の調査報告書処理アプリの事例なども紹介されており、実際に多くの企業で活用されていることがわかります。
Databricks Appsは、Databricksプラットフォームが利用可能な主要クラウド(AWS、Azure、GCP)の全リージョンでGAとして順次提供されています。GAに達したことで基本機能は成熟したと言えますが、今後はサポートするフレームワークのさらなる拡充やリソース上限の拡大、デプロイやCI/CDのさらなる自動化などが期待されますね。
- 公式情報リンク:
- Databricks公式ドキュメント: Databricks Apps
- GA発表時の公式ブログ記事: Announcing General Availability of Databricks Apps
Agent Bricks
Databricks Data + AI Summit 2025の目玉の一つとして発表された Agent Bricks(エージェント・ブリックス) は、生成AIエージェントの開発と運用に特化した新しいサービスで、そのコンセプトが非常に画期的だと感じました。現在はベータ版として提供が始まっています。
従来の企業におけるAIエージェント(会話ボットや自動化AIなど)の構築には、品質確保やコスト最適化が大きな障壁となっていました。多くの企業が、エージェントのパフォーマンスを把握できなかったり、適切な最適化手法を選ぶのが難しかったり、品質とコストのバランス調整に苦労したりしているそうなんです。例えば、自動車メーカーの例では、自社製品に関する質問に競合他社の車を推薦してしまったり、存在しない製品を回答してしまったりと、実運用における「幻覚」の問題が顕著だったようです。
こうした課題を解決するためにAgent Bricksが目指すのは、宣言的なアプローチ によって、ユーザーがタスクを記述するだけで最適なエージェントを自動生成・チューニングすることです。これは、複雑なエージェント開発の試行錯誤を大幅に削減し、初期段階からプロダクションレベルのAIエージェントをスピーディーに構築することを可能にするものなんです。
 Agent Bricksの核となる特徴は、以下の3つのステップでエージェント開発を自動化する点にあります。
Agent Bricksの核となる特徴は、以下の3つのステップでエージェント開発を自動化する点にあります。
 1. 評価基盤の自動構築: ユーザーが「どんなタスクをエージェントにやらせたいか」を自然言語で指定すると、Agent Bricksはタスクに合わせた評価基準とLLMジャッジ(Large Language Modelを用いた回答評価モデル)を自動生成します。これにより、エージェントの出力品質を客観的に計測し、パフォーマンスを迅速に把握できるようになります。人間によるフィードバック(Human-in-the-Loop)もサポートされているため、評価の精度をさらに高められる仕組みですね。
1. 評価基盤の自動構築: ユーザーが「どんなタスクをエージェントにやらせたいか」を自然言語で指定すると、Agent Bricksはタスクに合わせた評価基準とLLMジャッジ(Large Language Modelを用いた回答評価モデル)を自動生成します。これにより、エージェントの出力品質を客観的に計測し、パフォーマンスを迅速に把握できるようになります。人間によるフィードバック(Human-in-the-Loop)もサポートされているため、評価の精度をさらに高められる仕組みですね。
2. 最適化の自動探索: 品質とコストのバランスを取るため、Agent BricksはTAO(Task-aware Optimization)やALHF(Agent Learning from Human Feedback、人間のフィードバックによる学習)、プロンプトエンジニアリング、モデルファインチューニング、報酬モデル、ベクトル検索など、最先端のチューニング手法を組み合わせてエージェントのパラメータやプロンプトを自動調整します。これにより、手作業では困難な高品質かつ低コストなエージェントを自動構築できます。特にALHFは、自然言語による指示(例:「1990年5月以前のデータはすべて無視する」)を受け取り、システムが自動的にコンポーネント(ベクトルインデックス、ジャッジ、ツール記述など)を変更してその指示を反映する、という革新的な技術が紹介されました。
3. 合成データの生成: ユーザー企業のデータに似たドメイン固有の合成データを大量に生成し、エージェントの訓練データを補強して堅牢性を向上させる機能も備わっています。
これらのプロセスを経て、ユーザーは最終的に提示された複数のエージェントバージョンの中から、希望の品質・コストバランスのものを選ぶだけで済むようになります。

Agent Bricksは、情報抽出エージェント(文書からのデータ抽出)、ナレッジQ&Aエージェント(社内知識に基づく回答)、マルチエージェントのオーケストレーション(複数エージェントを連携させ複合タスクを処理)、業界特化のカスタム対話エージェント(マーケティング文書生成など)といった多様なユースケースに対応しています。すでに製薬大手AstraZenecaでは40万件以上の治験文書からコード不要で構造化データ抽出を1時間以内に実現した事例や、Flo Health社が汎用LLMより2倍の医療精度を達成したカスタム健康相談エージェントを構築した事例などが紹介されていましたね。
現在のステータスはBeta版で、2025年6月の発表と同時に全てのDatabricksユーザー向けに利用可能になりました。Databricksプラットフォーム上のサービスなので、基本的にDatabricksが動作する全クラウド(AWS、Azure、GCP)のワークスペースで利用可能です。今後の予定としては、GAに向けてさらなる改良が進められる見込みで、タスク種類の拡大や、ユーザー独自評価指標の組み込み、UI上でのノーコードエージェント設計などが期待されます。
- 公式情報リンク:
MLflow 3.0
機械学習のライフサイクル管理といえばMLflow、という方も多いのではないでしょうか。Databricksが主導するオープンソースプロジェクトであるMLflowが、今回のSummitで MLflow 3.0 というメジャーアップデート版として一般提供(GA)がアナウンスされました。このアップデートは、従来の機械学習・ディープラーニングだけでなく、生成AI(GenAI) までを単一プラットフォームで統合的に管理することを目的に、全面的に刷新されたそうなんです。
MLflow 3.0の最大のポイントは、生成AIの実験から運用まで、そのライフサイクル全体をサポートするために強化された機能にあります。
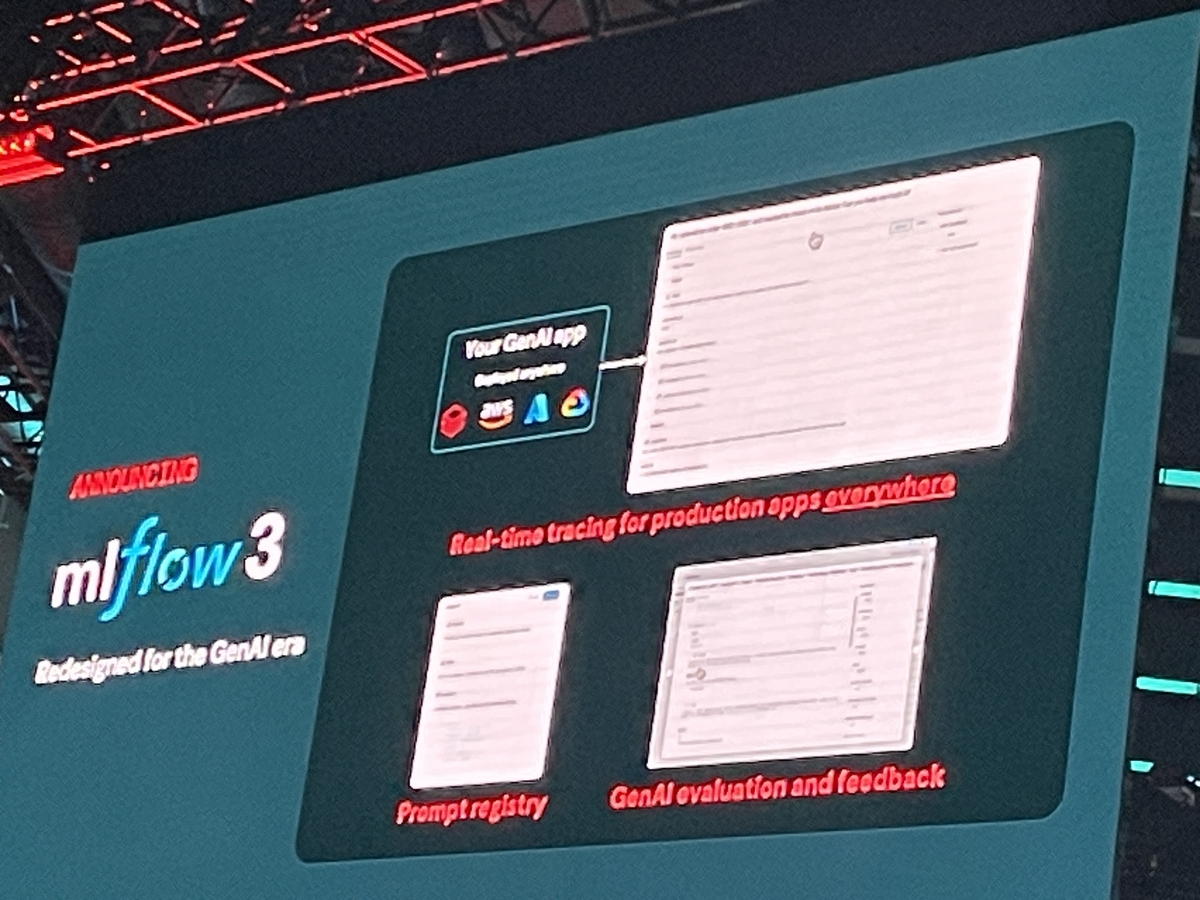 特に注目すべき新機能は以下の通りです。
特に注目すべき新機能は以下の通りです。
- プロンプトや出力のトレーシング(Trace)機能: 大規模言語モデル(LLM)に対する入力プロンプトや生成結果、中間生成物などを詳細に記録し、どのプロンプトがどんな結果を生んだかを追跡できるようになりました。これによって、LLMの挙動デバッグが格段に容易になります。複雑なGenAIアプリケーションのエンドツーエンドの可視性を提供し、入力、出力、レイテンシ、コストをキャプチャし、プロンプトやデータ、アプリのバージョンにリンクできます。
- LLM評価(ジャッジ)統合: LLMを用いた自動評価(LLM-as-judge)機能や、人間によるフィードバック収集のためのUI/APIが統合され、モデル出力の品質を評価・比較する仕組みが標準装備されました。例えば、生成テキストの事前定義評価基準に対するスコアリングや、複数モデルの回答を横断比較するツールが提供されます。
- プロンプトおよびアプリケーションのバージョン管理: 従来のMLflowはモデルやデータのバージョン管理が中心でしたが、3.0ではプロンプトやエージェントの構成も含めた包括的なバージョン管理をサポートするようになりました。これにより、プロンプトエンジニアリングの試行錯誤も履歴管理できるようになり、Gitライクなコミットベースバージョニングシステムで、組織全体でのプロンプトの保存や再利用、自動改善も可能になります。
- 新しいLoggedModelエンティティ: MLflow Trackingに新しいファーストクラスオブジェクトとして「LoggedModel」が追加されました。これは、従来のモデルだけでなく、GenAIエージェントの定義や評価、ディープラーニングのチェックポイント管理を合理化するためのもので、多様なAI成果物を一貫して追跡、バージョン管理、評価できるようになります。
- AI Gateway対応: Databricksが提供するAI Gateway(LLMエンドポイントの統合管理機能)とも連携し、推論サービスのモニタリング(トラフィックやコスト追跡など)もMLflowからできるようになりました。
要するに、MLflow 3.0は、実験追跡・モデル管理という従来の機能に加え、生成AI開発に不可欠な「プロンプトやエージェントの管理・評価・継続的改善」機能を統合したプラットフォームへと進化したと言えるでしょう。これにより、企業はLLMやエージェントを含むAIプロジェクト全体を一元的に管理し、迅速なデバッグや品質向上サイクルを回せるようになるはずです。
MLflow 3.0はすでに一般提供(GA)されており、オープンソース版もリリース済みです。Databricksプラットフォームにはすでに組み込まれており、もちろんAWS、Azure、GCP上のワークスペースでUnity Catalogやノートブックと組み合わせて利用できます。また、プラットフォーム非依存で動作するため、Databricksを使わない環境でもOSSとして組み込んで使用可能ですよ。
- 公式情報リンク:
- Databricks公式ブログ記事: MLflow 3.0: Unified AI Experimentation, Observability, and Governance
- MLflow公式ドキュメント: MLflow 3.0
GPUのサーバレス対応
Databricksプラットフォームのコンピューティング能力が、今回のKeynoteでさらに進化しました。2025年6月に、サーバレスコンピュート機能が GPUインスタンスに拡張対応(ベータ版) したんです。これは、機械学習トレーニングやディープラーニング、LLMのファインチューニングなど、GPUを使うワークロードを、ユーザーがインフラ構築の手間なくオンデマンドで高性能なGPUリソースとして利用できるようになることを意味しています。
これまでは、GPUクラスタを自分で起動・管理する必要があり、その運用はなかなか複雑でしたよね。インスタンスの選定からスケーリング、そして停止忘れによるコスト浪費など、面倒な作業が多かったはずです。しかし、サーバレスGPUでは、Databricks側でGPUノードのプロビジョニングとスケーリングを自動で管理してくれます。ユーザーはノートブックの環境設定でGPUを選択するだけで利用開始でき、アイドル時には自動でリソースが解放されるので、無駄なコストを抑えられます。
現在のところ、サーバレスGPUではNVIDIA A10 GPUが採用されており、モデル学習や推論に高い計算性能を提供します。起動も高速で、データサイエンティストが素早く実験を開始できるとされています。将来的にNVIDIA H100 GPUも提供される予定があるそうですよ。DatabricksノートブックやAutoMLツール、MLflowとも統合されているので、既存の開発フローを損なわずにGPUパワーを活用できるのは嬉しいポイントですよね。
推奨されるユースケースとしては、深層学習モデルのトレーニング(画像・音声認識、レコメンデーション)、大規模言語モデルの微調整(ファインチューニング)、ディープラーニングによる時系列予測など、カスタムモデルの訓練全般が挙げられています。特にLLMの実験では大量のGPU資源を断続的に使うことが多いので、サーバレスによる自動管理はコスト効率に大きく貢献しそうです。
現在のステータスはベータ版で、Databricksの管理者側でベータ機能を有効化する必要がある場合があります。対応クラウド・リージョンは、2025年6月時点ではAWSの一部リージョン(us-east-1およびus-west-2)で提供開始されています。AzureやGCPへの対応については、まだ公式な言及はありませんが、今後拡大していく可能性はありそうです。
なお、このサービスにはいくつかの制約もあります。例えば、対応するGPUはA10のみで、他のGPUインスタンスは選択できません。また、PrivateLinkのようなネットワーク制限環境やHIPAA準拠ワークスペースのような高度セキュリティ環境では利用不可、そしてジョブ(バッチ処理)での利用は現時点では非対応だそうです。これらの制約が今後どう改善されるかは未定ですが、利用を検討する際は公式ドキュメントで最新情報を確認することをおすすめします。
- 公式情報リンク:
- Databricks公式ドキュメント: Serverless GPU compute
MCP on Databricks
最近のAIエージェントのトレンドでよく耳にするのが、Model Context Protocol(MCP) というオープン標準プロトコルですよね。これは、AIエージェントが外部のデータやツールにアクセスするための共通のやり方を定義するもので、Anthropic社などが提唱しています。Databricksは、このMCPのサポートを2025年6月にプラットフォームへ正式対応(ベータ版)したと発表しました。
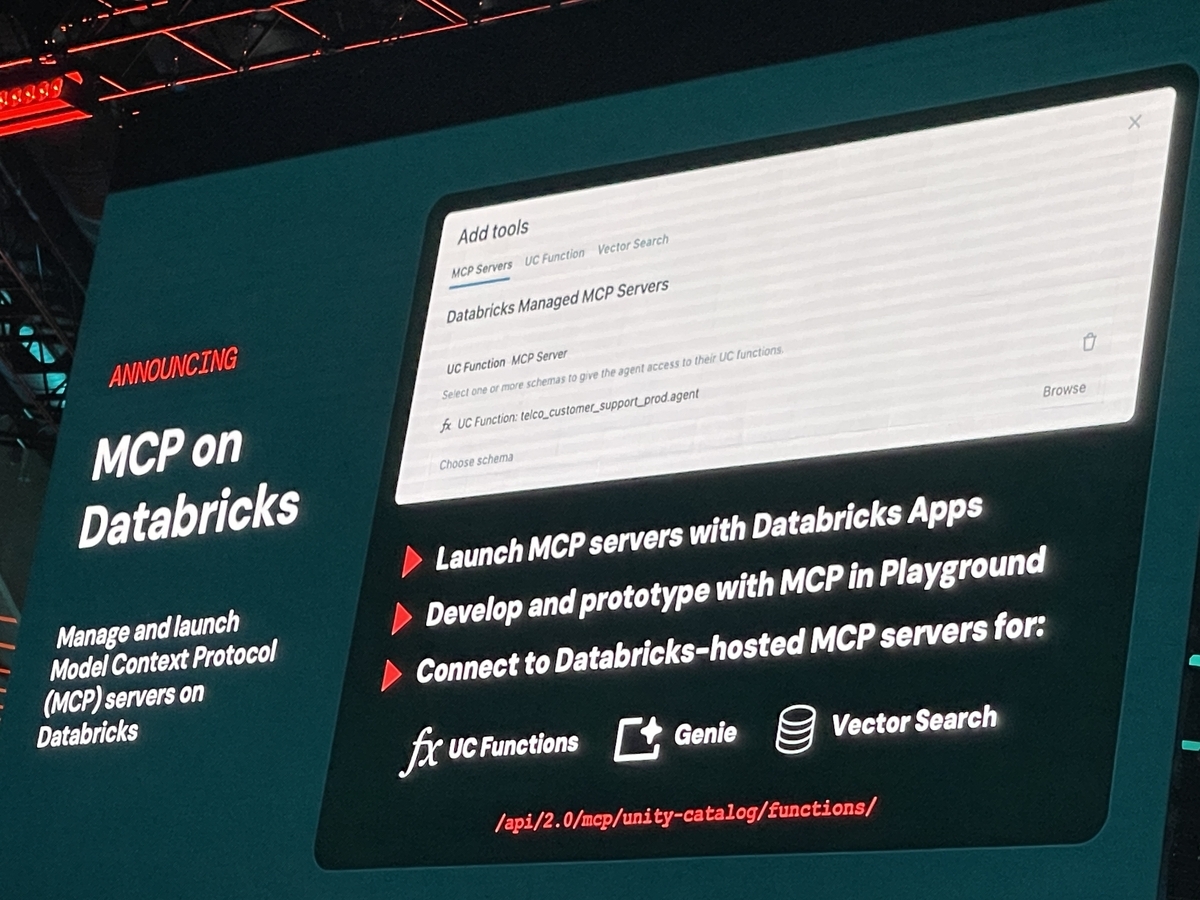 DatabricksがMCPに対応したことの意義はとても大きいと感じています。これまでは、AIエージェントが社内の様々なデータソースやツールにアクセスさせようとすると、個別にコネクタを開発したり、セキュリティ設定を調整したりと、非常に手間がかかることが多かったですよね。MCPを使うことで、どんなAIエージェントでも共通のやり方でデータソースやツールを呼び出せるようになるので、カスタムコネクタの実装にかかる労力を大幅に削減できます。
DatabricksがMCPに対応したことの意義はとても大きいと感じています。これまでは、AIエージェントが社内の様々なデータソースやツールにアクセスさせようとすると、個別にコネクタを開発したり、セキュリティ設定を調整したりと、非常に手間がかかることが多かったですよね。MCPを使うことで、どんなAIエージェントでも共通のやり方でデータソースやツールを呼び出せるようになるので、カスタムコネクタの実装にかかる労力を大幅に削減できます。
DatabricksがMCPをサポートすることで、自社のエージェントフレームワーク(Agent Bricksなど)はもちろん、他社のエージェントからも、Unity Catalog管理下のデータや機能に安全にアクセスできるようになります。これはつまり、DatabricksプラットフォームがAIエージェントのための土台として、外部の様々なシステムと連携するための「標準の橋渡し役」を担うようになった、ということなんです。たとえば、Databricksで構築したエージェントが、MCPを介してSlackやGitHub、他のデータベースなど、あらゆる外部ツールにアクセスできるようになれば、ユースケースの幅が飛躍的に広がります。逆に、AnthropicのClaudeのような外部のAIエージェントからDatabricks内のデータを扱う際も、MCP対応によって安全に実現できるようになります。
Databricksが提供するMCPの具体的な機能は以下の通りです。
- Managed MCP Servers(マネージドMCPサーバ): Databricksがすでに用意したMCP準拠のサーバエンドポイントを提供します。具体的には、Unity Catalog上のベクター検索インデックスに問い合わせるサーバ、Unity Catalog上の関数(関数ストアに登録したPython/SQL関数)を実行するサーバ、Databricksの構造化データ向けLLM分析機能「Genie」に問い合わせるサーバなどがあります。エージェント開発者はこれらのURLを指定するだけで、Databricks内のデータやツールにアクセスをエージェントに与えることができ、権限はUnity Catalogで管理されているので安全性も確保されています。
- Custom MCP Servers(カスタムMCPサーバ)のホスティング: Databricksプラットフォーム上で、ユーザーが独自に作成したMCPサーバやサードパーティ製のMCPサーバをホスティングすることも可能です。Databricks Apps機能を使ってデプロイできるので、他のユーザーと共有したり、常時稼働させたりできます。これにより、Databricksが用意していない外部ツール連携(例:社内のオンプレDBやサードパーティAPI)もMCP経由でエージェントに組み込めるようになります。
現在のステータスはベータ版で、Managed MCPサーバの利用にはBetaプログラムへの参加が必要だそうです。Databricksプラットフォームの共通機能として、AWS、Azure、GCPのどのクラウド上でも利用可能ですよ。
今後の予定としては、MCP自体がオープン標準として進化していく中で、Databricksもフィードバックを踏まえてGAを目指すとみられます。MCPサーバの種類追加(ファイルシステムアクセス用など)や、Agent BricksのようなUI上でのノーコード連携、さらにはパートナーエコシステムとして他社が提供するMCPサーバのマーケットプレイス的な展開も期待されますね。
- 公式情報リンク:
- Databricks公式ドキュメント: Model context protocol (MCP) on Databricks
- Anthropic社の公式ブログ記事: Introducing the Model Context Protocol
その他Keynote中のトピック
Keynoteでは、各サービスの詳細な発表だけでなく、Databricks全体の戦略や、データとAIの現状、そして未来についての興味深い話も多くありました。
- Databricksの成長とオープンソースへのコミットメント: Ali Ghodsi CEOは、DatabricksがApache Sparkをリリースしてから、いかにコミュニティとカンファレンスが成長したかを語っていましたね。Delta Lakeが10億ドル以上、Apache Icebergが3億6,000万ドル以上、MLflowが3億ドル以上の価値を持つと評価されており、オープンソースの価値とそれがDatabricksの基盤であることを強調していました。
- AIの民主化ツール: Databricksは、データから価値を引き出すためにプログラミング言語の知識が必要だった壁を取り払い、英語などの自然言語でデータに問いかけるだけで答えを得られるようにすることを目指しています。その具体例として、81%の顧客が利用する「Genie」と、98%の顧客が利用する「Assistant」が紹介されました。Genieは自然言語で質問すると、複数のエージェントを組み合わせてコードを生成・実行するそうですよ。AssistantはDatabricksプラットフォームのあらゆる側面を理解し、エラー診断やコード説明、データに合わせた支援を行ってくれるそうです。
- パートナーエコシステム: Databricksは5,800以上のパートナーと連携しているとのこと。AWS、Google Cloud、Microsoftといったハイパースケーラーのほか、AccentureやDeloitteのようなシステムインテグレーター、AnthropicやNVIDIAのような技術パートナー、そしてWalmartやS&P Globalといったデータプロバイダーなど、多岐にわたる企業との協力体制が紹介されていました。
- 統一ガバナンスの重要性: データとAIの基盤において、Unity Catalogによる統一ガバナンスの重要性が改めて強調されました。アクセス制御だけでなく、データ発見、系譜追跡、ビジネス意味論の理解、コスト管理、データ品質モニタリングといった多岐にわたる機能が、組織内のすべてのデータ資産(構造化データ、非構造化データ、AIモデル、ダッシュボードなど)に対して一元的に適用されるべきだという考え方です。
- 顧客事例: Joby(eVTOL開発でのデータ活用)、Virgin Atlantic(データインテリジェンスの活用)、MasterCard(AIエージェントプラットフォームと不正検知)、JPMorgan Chase(AIへの大規模投資とデータ管理)など、多様な業界の企業がDatabricksをどのように活用してビジネスを革新しているかの事例が紹介されました。特にJPMorgan Chaseは、AI分野に約20億ドルを投資し、約600件のユースケースを展開しているそうです。
まとめ
Databricks Data + AI Summit 2025の初日Keynoteでは、Lakebaseという新しい運用データベースカテゴリ、一般提供が開始されたDatabricks Apps、AIエージェント構築を自動化するAgent Bricks、生成AIに最適化されたMLflow 3.0、サーバレスGPUサポート、AIエージェントのためのModel Context Protocol (MCP) サポート、そして学習機会を広げるDatabricks Free Editionといった、データとAIのランドスケープを大きく変革しうる発表が多数行われました。
これらの発表は、Databricksが運用ワークロードと分析ワークロードの両方に対応し、生成AIを企業にとって実用的かつアクセスしやすいものにするために多大な投資を行うことで、データとAIのための包括的なプラットフォームとしての地位を確立しようとする明確な軌道を示していると言えるでしょう。データのサイロ化や複雑なインフラ管理といった課題を、オープンフォーマットと統一ガバナンス、そしてマネージドサービスによって解決し、誰もがデータとAIの力を活用できる「Data Intelligence for All」というビジョンを具現化しようとしています。
多くのサービスがまだプレビュー版やベータ版であることから、今後も顧客からのフィードバックを受けてさらなる改良が進められることが予想されます。特にLakebaseはデータベース市場に大きな変革をもたらす可能性を秘めていますし、Agent BricksやMLflow 3.0は生成AIのエンタープライズ導入を加速させるでしょう。Databricks Free Editionは、長期的なエコシステムの成長とAI人材の育成に大きく貢献すると期待されますね。
今回の発表は、Databricksが単なるデータプラットフォームから、AI時代の包括的なデジタル変革基盤へと進化を遂げたことを強く印象づけるものだったのではないでしょうか。