
はじめに
エーピーコミュニケーションズGDAI事業部Lakehouse部の鄭(ジョン)です。
この記事では、DatabricksのUnity Catalogを活用したMLOpsの実践方法をご紹介します。 シリーズ第2回となる今回は、Databricks の Unity Catalog(UC)を活用してシンプルな ALS (Alternating Least Squares)推薦モデルを構築し、そのプロセスを MLOps によって自動化したデモを紹介します。さらに、実際に MLOps ワークフローを設計・実行する手順を、コードとあわせて解説します。
- シリーズ第1回 : DatabricksのUnity Catalogを活用したMLOps(1編、概念・事例紹介) techblog.ap-com.co.jp
この記事の流れは以下のとおりです。
- デモ概要:デモのシナリオの説明
- 事前準備:データ、カタログ、ボリュームなどの準備
- ワークフロー全体の紹介:データエンジニアリング、モデル学習(ALS 推薦モデル)、モデル評価(RMSE の算出)、モデルレジストリの更新(Challenger と Champion の比較、UC エイリアスの更新)
目次
デモ概要
- シナリオ: 電子商取引サイトにおいて、顧客が商品を閲覧・クリック・購入するなどの行動ログをもとに、推薦モデルを構築します。
- 推薦モデル: ALS(Alternating Least Squares)に基づく協調フィルタリングモデルを採用し、顧客ごとに最適な商品推薦を提供します。
- ビジネス要件: 新しいモデルを作成した際、既存のサービスで稼働しているモデル(Champion)と性能を比較し、より優れている場合のみ自動的に本番環境へデプロイします。
事前準備
データ紹介
本デモでは Databricks MarketplaceのSimulated Retail Customer Dataという仮想の小売顧客および販売データを利用します。 このデータセットはcustomers、sales、sales_ordersの3つのテーブルで構成されていますが、本記事では customers と sales_orders の2つのテーブルを使用します。
環境準備
検証に使用するカタログ、スキーマ、およびボリュームを以下のように作成しました。
CREATE CATALOG IF NOT EXISTS MLOps; CREATE SCHEMA IF NOT EXISTS MLOps.raw; CREATE SCHEMA IF NOT EXISTS MLOps.data; CREATE SCHEMA IF NOT EXISTS MLOps.model; CREATE VOLUME IF NOT EXISTS MLOps.raw.source_files;
私の環境では、データが保存されているカタログとDLT(Delta Live Table)のターゲットデータのカタログ位置が一致しない場合、エラーが発生しました。 そのため、以下のようにソースデータを検証用カタログにコピーして対応しました。
src_volume = "/Volumes/databricks_simulated_retail_customer_data/v01/source_files/customers.csv" dst_volume = "/Volumes/MLOps/raw/source_files/customers/" # Ensure destination directory exists dbutils.fs.mkdirs(dst_volume) src_files = dbutils.fs.ls(src_volume) dst_files = dbutils.fs.ls(dst_volume) src_file_names = set(f.name for f in src_files) dst_file_names = set(f.name for f in dst_files) if src_file_names != dst_file_names: for f in src_files: src_path = f.path dst_path = src_path.replace(src_volume, dst_volume, 1) dbutils.fs.cp(src_path, dst_path, recurse=True) print("複製しました。") else: print("複製されたファイルが存在します。")
sales_orders テーブルについても同様の作業を行います。
ワークフロー全体の紹介
データエンジニアリング
このパートでは、メダリオンアーキテクチャの構築や DLT(Delta Live Tables)パイプラインの構築について紹介しています。
モデルにご関心のある方は、このパートは読み飛ばしてください。
メダリオンアーキテクチャを用いてデータエンジニアリングを実施しました。
Bronze Layer
Auto Loaderを利用することで、Volumes上に配置されたストリーミングIngestionのCSVファイルを自動的に検知し、Unity Catalogへ取り込みを行っています。
# customers bronzeテーブル @dlt.table() def customers_bronze(table_properties={"quality":"bronze"}): return ( spark.readStream.format("cloudFiles") .option("cloudFiles.format", "csv") .option("header", "true") .option("cloudFiles.inferColumnTypes", "true") .load("/Volumes/MLOps/raw/source_files/customers/") ) # sales_orders bronzeテーブル # sales_orders テーブルはマルチラインデータであるため、読み込み時にはさまざまなオプションを指定し、さらにスキーマを明示的に定義しています。 schema = spark.table("databricks_simulated_retail_customer_data.v01.sales_orders").schema @dlt.table(table_properties={"quality":"bronze"}) def sales_orders_bronze(): return ( spark.readStream.format("cloudFiles") .option("cloudFiles.format", "csv") .option("header", "true") .option("quote", '"') .option("escape", '"') .option("multiLine", "true") .option("mode", "PERMISSIVE") .schema(schema) .load("/Volumes/MLOps/raw/source_files/sales_orders/") )
Silver Layer
まず、Bronzeテーブルに対して簡単な前処理を行います。必要なカラムのみを選択し、Null値や空文字('')を取り除きます。
# 共通の前処理 def not_null_and_not_blank(col_name: str): return (F.col(col_name).isNotNull()) & (F.trim(F.col(col_name)) != "") # customers silverテーブル @dlt.table(table_properties={"quality":"silver"}) @dlt.expect_or_fail("pk_must_exist", "customer_id IS NOT NULL AND trim(customer_id) != ''") @dlt.expect_all_or_drop({ "state_present": "state IS NOT NULL AND trim(state) != ''", "city_present": "city IS NOT NULL AND trim(city) != ''", "units_present": "units_purchased IS NOT NULL AND trim(units_purchased) != ''", "loyalty_present": "loyalty_segment IS NOT NULL AND trim(loyalty_segment) != ''" }) def customers_silver(): base = spark.readStream.table("customers_bronze").alias("base") df = ( base.select("customer_id","state","city","units_purchased","loyalty_segment") .where( not_null_and_not_blank("customer_id") & not_null_and_not_blank("state") & not_null_and_not_blank("city") & not_null_and_not_blank("units_purchased") & not_null_and_not_blank("loyalty_segment") ) ) return df # sales_orders silverテーブル @dlt.table(table_properties={"quality":"silver"}) @dlt.expect_or_fail("pk_must_exist", "order_number IS NOT NULL AND trim(order_number) != ''") @dlt.expect_all_or_drop({ "clicked_items_present": "clicked_items IS NOT NULL AND trim(clicked_items) != ''", "customer_id_present": "customer_id IS NOT NULL AND trim(customer_id) != ''", "number_of_line_items_present": "number_of_line_items IS NOT NULL AND trim(number_of_line_items) != ''", "order_datetime_present": "order_datetime IS NOT NULL AND trim(order_datetime) != ''", "ordered_products_present": "ordered_products IS NOT NULL AND trim(ordered_products) != ''", "promo_info_present": "promo_info IS NOT NULL AND trim(promo_info) != ''" }) def sales_orders_silver(): base = spark.readStream.table("sales_orders_bronze").alias("base") df = ( base.select("clicked_items","customer_id","number_of_line_items","order_datetime","order_number","ordered_products","promo_info") .where( not_null_and_not_blank("clicked_items") & not_null_and_not_blank("customer_id") & not_null_and_not_blank("number_of_line_items") & not_null_and_not_blank("order_datetime") & not_null_and_not_blank("order_number") & not_null_and_not_blank("ordered_products") & not_null_and_not_blank("promo_info") ) ) return df
その後、整形した 2 つのテーブルを結合し、モデル学習用のフィーチャーテーブル(feature table)の基盤となるテーブルを作成します。
@dlt.table(table_properties={"quality":"silver"}) def sales_orders_customer_join_min(): base = dlt.read_stream("sales_orders_silver").alias("base") so = ( base.select("clicked_items","customer_id","number_of_line_items","order_datetime","order_number","ordered_products","promo_info") ) c = dlt.read("customers_silver").alias("c") df = ( so.join(c, "customer_id", "left") .select("clicked_items","customer_id","number_of_line_items","order_datetime","order_number","ordered_products","promo_info","state","city","units_purchased","loyalty_segment") ) return df
Gold Layer
上で結合したSilverテーブルを基に、ALSによる推薦モデル学習用のフィーチャーテーブルを作成します。
MLOps.data.als_interactions_30dはcustomer_id、product_id、interaction_weightの3つのカラムで構成されています。
- customer_id:ユーザー ID
- product_id:商品 ID
- total_qty:顧客が当該商品を購入した累計数量(または直近30日間の総購入数量)
- interaction_weight:直近30日間における顧客と商品の相互作用の強さ(購入回数、金額、直近性などを反映)
この interaction_weightが ALS モデルのインプリシットフィードバック信号として利用され、推薦モデルが顧客–商品マトリックスを学習できるようになります。
実際の運用では「現在時刻から過去30日以内のデータ」を対象としますが、本デモでは固定データを使用しているため、テーブル内の最新データを基準に30日以内のデータを抽出しています。
ITEMS_SCHEMA = T.ArrayType(T.StructType([
T.StructField("curr", T.StringType()),
T.StructField("id", T.StringType()),
T.StructField("name", T.StringType()),
T.StructField("price",T.StringType()),
T.StructField("promotion_info", T.StringType()),
T.StructField("qty", T.StringType()),
T.StructField("unit", T.StringType()),
]))
@dlt.table(table_properties={"quality":"gold"})
def als_interactions_30d():
base = dlt.read("sales_orders_customer_join_min").alias("base")
j = (
base
.withColumn(
"ts",
F.coalesce(
F.to_timestamp(F.from_unixtime(F.col("order_datetime").cast("long"))),
F.to_timestamp("order_datetime"),
F.col("order_datetime").cast("timestamp")
)
)
.withColumn("items", F.from_json("ordered_products", ITEMS_SCHEMA))
.withColumn("p", F.explode("items"))
)
mx = j.agg(F.max("ts").alias("max_ts"))
j = j.crossJoin(mx)
w30 = F.col("ts") >= F.date_sub(F.col("max_ts"), 30)
return (
j.where(w30)
.select(
"customer_id",
F.col("p.id").alias("product_id"),
F.col("p.qty").cast("int").alias("qty")
)
.where(F.col("qty").isNotNull() & (F.col("qty") > 0))
.groupBy("customer_id","product_id")
.agg(F.sum("qty").alias("total_qty"))
.withColumn("interaction_weight", F.log1p(F.col("total_qty")))
)
DLT(Delta Live Table)パイプラインの構築
上記のメダリオンアーキテクチャを用いて、DLT(Delta Live Table)パイプラインを構築します。
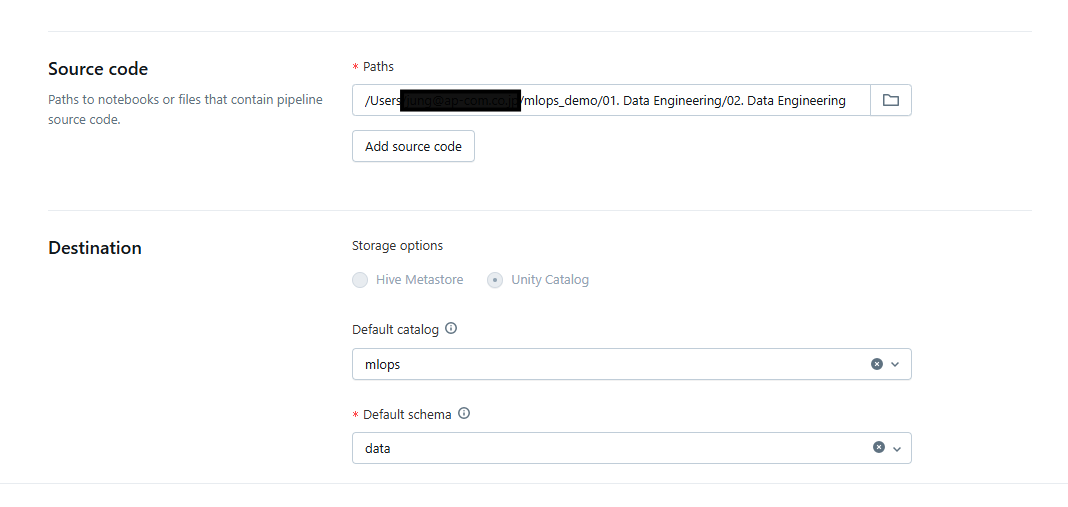
作成した 3 つのレイヤーを 1 つのノートブックにまとめ、ソースコードとして利用します。さらに、環境準備の際に作成したMLOps.dataスキーマを Destinationに指定します。
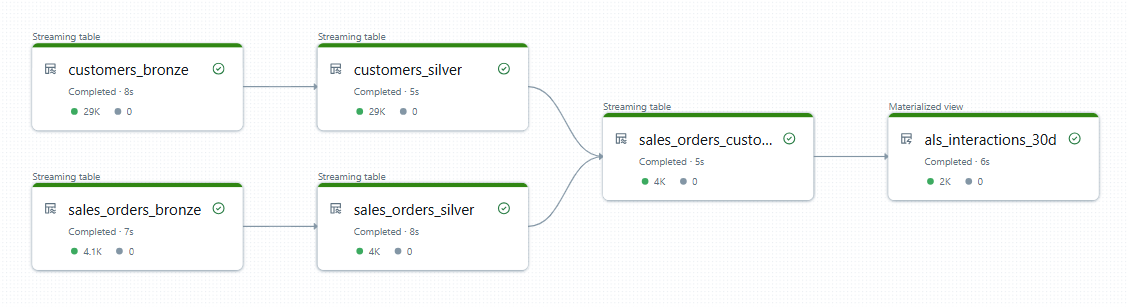
上記の設定をもとにパイプラインを実行すると、以下のような DLT パイプラインが作成されます。
モデル学習(ALS 推薦モデル)
このパートでは、モデル構築やMLflow Experiment、モデル学習やモデルのロギングについて紹介しています。
モデル評価やモデルレジストリの更新にご関心のある方は、このパートは読み飛ばしてください。
次に、Goldデータを利用して推薦モデルを学習します。 ここでは Spark の ALS(Alternating Least Squares)アルゴリズム を使用します。これは協調フィルタリングに基づく推薦システムでよく利用される手法です。
1)データのロードとインデックス化
まず、Unity Catalog に保存されている学習用テーブルを読み込み、文字列型の product_id を数値インデックスに変換します。
import mlflow import mlflow.spark from mlflow.exceptions import RestException from pyspark.ml.feature import StringIndexer from pyspark.ml.recommendation import ALS from mlflow.models import infer_signature interactions = spark.table("MLOps.data.als_interactions_30d") product_indexer = StringIndexer( inputCol="product_id", outputCol="product_id_idx", handleInvalid="skip" ) interactions_indexed = product_indexer.fit(interactions).transform(interactions)
2)ALS モデルの定義
ALS モデルを定義します。 ここでは customer_id をユーザー、product_id_idx をアイテム、interaction_weight をレーティングとして利用します。
ハイパーパラメータ(rank、maxIter、regParam)は、実験を通じて調整可能です。
als = ALS(
userCol="customer_id",
itemCol="product_id_idx",
ratingCol="interaction_weight",
implicitPrefs=True,
coldStartStrategy="drop",
rank=20,
maxIter=10,
regParam=0.1
)
3)MLflow Experiment の設定
モデルの学習および評価の記録を管理するために、MLflow Experiment を設定します。 Experiment が存在しない場合は、自動的に作成されるように例外処理を追加しています。
experiment_path = "/Workspace/Users/sample@adress.com/mlops_demo_model/als_recommendation" try: mlflow.set_experiment(experiment_path) print(f"Experiment found or created at: {experiment_path}") except RestException as e: if "RESOURCE_DOES_NOT_EXIST" in str(e): experiment_id = mlflow.create_experiment(experiment_path) mlflow.set_experiment(experiment_path) print(f"Experiment created at: {experiment_path}, ID: {experiment_id}") else: raise e
4)学習と検証
データを train / test に分割した後、モデルを学習し予測を行います。 現在のコードはデモを目的としているため、学習データの分割ルールを緩和し、interactions_indexed 全体を用いてモデルを学習しています。 評価段階では、別途分割した test データ のみを使用しています。
実際の運用環境では、一般的に train データで学習し、test データで評価する 方法が推奨されます。
train, test = interactions_indexed.randomSplit([0.8, 0.2], seed=42) with mlflow.start_run(run_name="training") as run: model = als.fit(interactions_indexed) predictions = model.transform(test)
5)Signature とモデルのロギング
MLflow にモデルを記録する際には、入力・出力のスキーマ(Signature)もあわせて保存します。 これによりモデルの再利用性が高まり、将来的なデプロイ時にスキーマ不一致によるエラーを防ぐことができます。
sample_input = test.limit(5).toPandas() sample_output = predictions.limit(5).toPandas() signature = infer_signature(sample_input, sample_output) mlflow.spark.log_model( spark_model=model, artifact_path="als_model", signature=signature ) mlflow.log_params({ "rank": 20, "maxIter": 10, "regParam": 0.1 }) run_id = run.info.run_id print(f"Training finished. Run ID: {run_id}")
モデル評価(RMSEの算出)
このパートでは、train/testデータの準備やモデル評価について紹介しています。
モデルレジストリの更新にご関心のある方は、このパートは読み飛ばしてください。
学習したALSモデルの精度を確認するために、RMSE(Root Mean Squared Error)を算出します。 RMSE は値が低いほど予測が実際の値に近いことを示します。
1)Train/Test データの準備
まず、前処理済みのデータを train/testに分割し、テーブルとして保存します。 このように保存しておくことで、他のノートブックやワークフローのステップでも同じデータを再利用することができます。
import mlflow import mlflow.spark from mlflow.exceptions import RestException from pyspark.ml.feature import StringIndexer from pyspark.ml.recommendation import ALS from pyspark.ml.evaluation import RegressionEvaluator interactions = spark.table("MLOps.data.als_interactions_30d") product_indexer = StringIndexer( inputCol="product_id", outputCol="product_id_idx", handleInvalid="skip" ) interactions_indexed = product_indexer.fit(interactions).transform(interactions) train, test = interactions_indexed.randomSplit([0.8, 0.2], seed=42) train.write.mode("overwrite").saveAsTable("MLOps.data.train_table") test.write.mode("overwrite").saveAsTable("MLOps.data.test_table")
2)最新の学習モデルの取得
MLflow Experimentから、直近に実行されたトレーニングRunを取得します。
experiment_path = "/Workspace/Users/jung@ap-com.co.jp/mlops_demo_model/als_recommendation" experiment = mlflow.get_experiment_by_name(experiment_path) runs_df = mlflow.search_runs( experiment_ids=[experiment.experiment_id] ) training_runs = runs_df[runs_df["tags.mlflow.runName"] == "training"] latest_training_run = training_runs.sort_values( by="start_time", ascending=False ).iloc[0] model_uri = f"runs:/{latest_training_run.run_id}/als_model" model = mlflow.spark.load_model(model_uri) print(model_uri)
3)RMSEの算出と保存
取得したモデルを用いて test データ に対する予測を行い、RMSEを算出します。 この値は MLflowにmetricとして記録され、後に他のモデルとの性能比較に活用されます。
predictions = model.transform(test)
evaluator = RegressionEvaluator(
metricName="rmse",
labelCol="interaction_weight",
predictionCol="prediction"
)
rmse = evaluator.evaluate(predictions)
with mlflow.start_run(run_name="evaluation") as run:
mlflow.log_metric("rmse", rmse)
mlflow.log_param("evaluated_model_uri", model_uri)
print(f"Evaluation finished. RMSE: {rmse}")
モデルレジストリの更新(ChallengerとChampionの比較、UCエイリアスの更新)
このパートでは、既存ChampionモデルのロードやChampionモデルとChallengerモデルの性能比較やモデルレジストリの更新について紹介しています。
全体のワークフローにご関心のある方は、このパートは読み飛ばしてください。
モデルの学習と評価が完了したら、新しく学習したChallengerモデルと既存の Championモデルを比較し、性能が優れているモデルをProductionに反映させます。
ここでいうChampionモデル とは、現在本番環境で利用されているモデルを指します。 Challengerモデルは、新たに学習した候補モデルであり、Championモデルと比較してより良い性能であれば、本番環境に採用されます。
Databricks Unity Catalog(UC)では、エイリアス(alias)機能を利用してChampion/Challengerモデルを管理します。
1)レジストリ URI の設定とデータ読み込み
Unity Catalogのモデルレジストリを利用するため、registry URIをUCモードに設定します。 前のステップで保存しておいたtestテーブルを使用して評価します。
mlflow.set_registry_uri("databricks-uc") test = spark.table("MLOps.data.test_table") uc_model_name = "MLOps.model.als_recommendation_model"
2)最新学習モデル(Challenger)の取得
MLflow Experimentから直近で実行された学習トレーニングRunを取得し、Challengerモデルとして登録します。
experiment_path = "/Workspace/Users/jung@ap-com.co.jp/mlops_demo_model/als_recommendation" experiment = mlflow.get_experiment_by_name(experiment_path) runs_df = mlflow.search_runs( experiment_ids=[experiment.experiment_id] ) training_runs = runs_df[runs_df["tags.mlflow.runName"] == "training"] latest_training_run = training_runs.sort_values( by="start_time", ascending=False ).iloc[0] model_uri = f"runs:/{latest_training_run.run_id}/als_model" challenger = mlflow.spark.load_model(model_uri)
3)既存Championモデルのロード
UCのエイリアス(alias)機能 を利用し、championというエイリアスで指定されたモデルをロードします。 もし既存のChampionモデルが存在しない場合は、Challengerモデルが自動的にChampionに昇格します。
try: champion = mlflow.spark.load_model(f"models:/{uc_model_name}@champion") print("Champion model exists in alias: champion") except Exception as e: champion = None print("No Champion model found. Challenger will be promoted directly.", e)
4)モデル評価の比較(RMSE)
それぞれのモデルでtestデータに対する予測を行い、RMSEを比較します。
- Challenger RMSE < Champion RMSE → Challengerを昇格
- それ以外の場合 → Championを維持
evaluator = RegressionEvaluator(
metricName="rmse",
labelCol="interaction_weight",
predictionCol="prediction"
)
predictions_challenger = challenger.transform(test)
challenger_rmse = evaluator.evaluate(predictions_challenger)
print("Challenger RMSE:", challenger_rmse)
if champion is not None:
predictions_champion = champion.transform(test)
champion_rmse = evaluator.evaluate(predictions_champion)
print("Champion RMSE:", champion_rmse)
else:
champion_rmse = None
5)UC エイリアスの更新
Challengerモデルがより優れている場合、MLflow Clientを利用してモデルをUCに登録し、そのバージョンにchampionエイリアスを付与します。このプロセスにより、常に最も性能の高いモデルだけが本番環境に残るように自動的に管理されます。
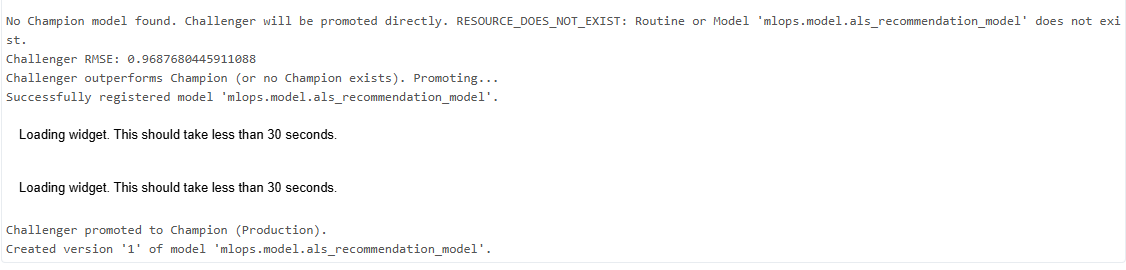
if champion is None or challenger_rmse < champion_rmse: print("Challenger outperforms Champion (or no Champion exists). Promoting...") client = mlflow.tracking.MlflowClient() result = mlflow.register_model(model_uri, uc_model_name) client.set_registered_model_alias( name=uc_model_name, alias="champion", version=result.version ) print("Challenger promoted to Champion (Production).") else: print("Challenger did not outperform Champion. No promotion.")
実行したら以下のようなメッセージが出力されます。
全体のワークフロー
このパートでは、これまでのプロセスを一つのワークフローとして構築する方法を紹介しています。
以下のイメージのように、データエンジニアリングからモデルの学習・評価、そしてレジストリの更新までを、1 つのワークフローとして構築します。
このワークフローの中には4つのタスクがあります。 最初のタスクには、データエンジニアリングパートで作成したDLTパイプラインを接続します。 その後、モデル学習、評価、そしてレジストリ更新の各ノートブックを順に接続します。
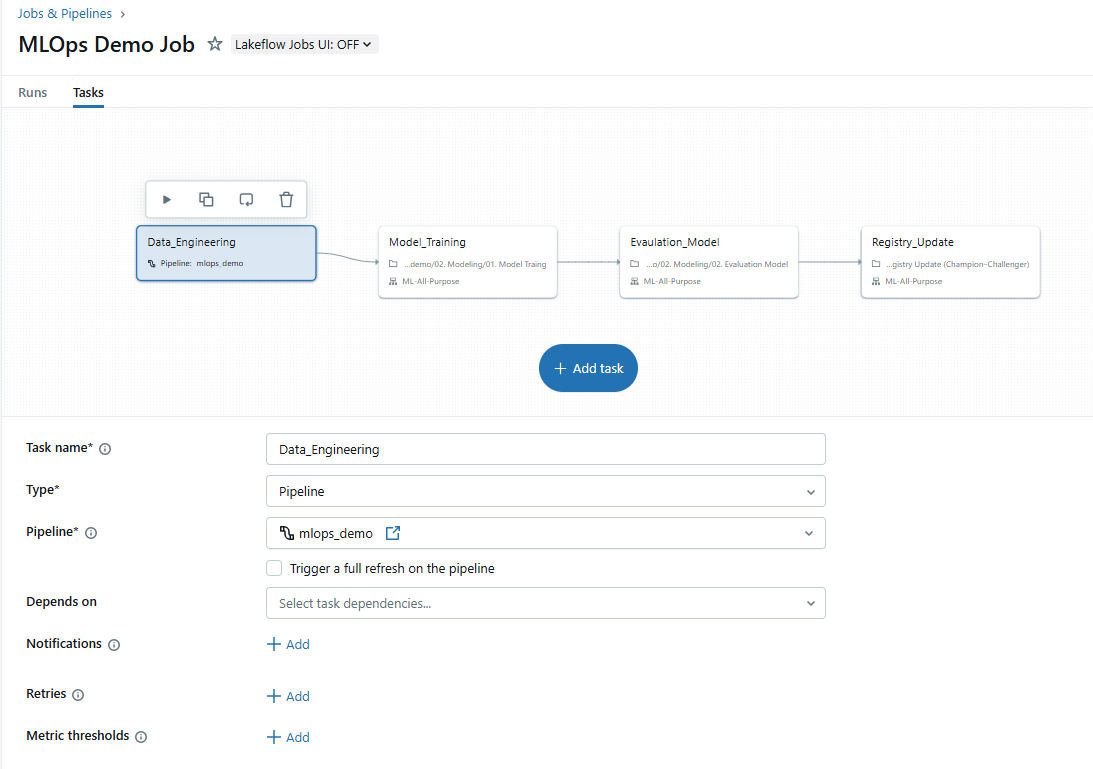
このワークフローを実行すると、DLTパイプラインが自動的に起動し、直近30日分のデータに基づいたGoldテーブルが更新されます。 その後、このデータを用いて新しいChallengerモデルを学習し、既存の本番環境にデプロイされているChampionモデル と性能を比較します。
更新されたGoldテーブルを利用して作った同じtestデータで RMSEを算出し、Challengerがより高い性能を示した場合は Championモデルを置き換え、そうでない場合は既存の Champion モデルをそのまま維持します。
さらに、一定期間Championモデルが更新されない状況が続く場合は、RMSEの推移を確認し、学習モデルのハイパーパラメータ調整など追加の改善施策を検討することができます。
まとめ
ここまで、Unity Catalogを活用したMLOpsデモ について解説してきました。 データエンジニアリングからモデルの学習・評価、そしてレジストリの更新までを、一連のワークフローとして自動化する流れを確認しました。
本記事の内容はあくまでデモ構成ではありますが、考え方や手順の一部は実務でも適用可能だと思います。特にChampion/Challengerモデル管理やUC エイリアス機能を活用することで、目指すMLOpsの基盤づくりに役立つのではないかと思います。
記事をお読みいただき、ありがとうございました。今後ともどうぞよろしくお願いいたします。

私たちはDatabricksを用いたデータ分析基盤の導入から内製化支援まで幅広く支援をしております。
もしご興味がある方は、お問い合わせ頂ければ幸いです。
また、一緒に働いていただける仲間も募集中です!
APCにご興味がある方の連絡をお待ちしております。