
はじめに
こんにちは、Global Data + AI事業部Lakehouse部の陳(チェン)です。
「Databricks Asset Bundlesを活用して、CI/CDをやってみよう」シリーズの第二弾です。第一編にて話をした「カタログ間のアーティファクトの移動」の実演に「変数参照」を交えながら、Databricks Asset Bundlesの活用方法を紹介いたします。
シリーズになっているため、アーティファクトの準備やDatabricks Asset Bundlesの準備について、第一編を参照してください。
まえおき
Databricks上で、CI/CDプロセスを円滑に行うためのDatabricks Asset Bundlesの紹介のため、想定読者はDatabricksの基本的な使い方に概念を持っている方です。そのため、本文の中に出てくる、ワークスペース・カタログの他、ローカルマシンにてDatabricksCLIの使用に関わる話題については説明をいたしません。必要に応じて、読者の各自でDatabricksの公式ドキュメントを参照していただければと思います。
また、本ブログシリーズに示されている作業の行う場所はDatabricks Free Editionを利用して構成されたため、様々な箇所において、設定に関わるものはシンプルになっていることにご注意ください。
もくじ
カタログ間のマイグレーションのおさらい
カタログ設計とデータ配置
Databricks Asset Bundlesを活用して、CI/CDをやってみよう:前準備編では、環境間のマイグレーションについて二種類を紹介しました。本篇の中身はFig1に沿って、カタログ間のマイグレーションをします。
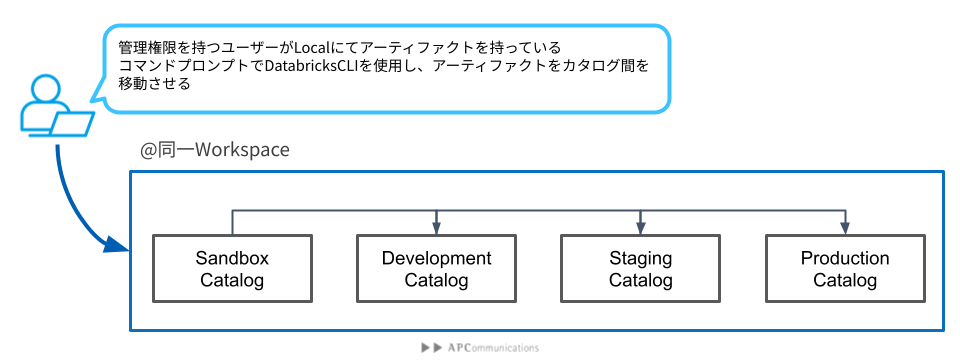
移動(マイグレーション)されたアーティファクトのコードは実際に使われているWorkspaceの/Workspace/<user_account>の配下に置きます。最終的に、アーティファクトのソース一式は下記のイメージで配置することになります。
workspace/users/<your_account>/
└── boundles/
├── 000_DEV_2025TEST
├── 100_STG_2025TEST
└── 200_PROD_2025TEST
アーティファクト(テーブル)を抜き、それぞれのカタログ配下のデータ配置は下記の通りです。それぞれのカタログの配下に、データソースのためのスキーマ(100_ingestion_data)を用意します。さらにその配下にVolumesを作成して、000_trip_dataというフォルダーに実際に取り込むべきのparquetファイルを置いておきます。また、それぞれのカタログ用途によって、データ量は違うことにご留意ください。
000_sandbox/ #開発者がテスト用のカタログのため、データ量は極少
└── 000_ingestion_data/
└── volumes/
└── 000_trip_data/
└── trip_file_1.parquet
100_dev/ #開発用のカタログのため、データ量は少
└── 000_ingestion_data/
└── volumes/
└── 000_trip_data/
├── trip_file_1.parquet
└── trip_file_2.parquet
200_stg/ #開発用のカタログのため、データ量は中
└── 000_ingestion_data/
└── volumes/
└── 000_trip_data/
├── trip_file_1.parquet
├── trip_file_2.parquet
└── trip_file_3.parquet
300_prod/ #開発用のカタログのため、データ量は本番用データ(ここでは一番多いデータ量を用意)
└── 000_ingestion_data/
└── volumes/
└── 000_trip_data/
├── trip_file_1.parquet
├── trip_file_2.parquet
├── trip_file_3.parquet
└── trip_file_4.parquet
YAMLファイルを作成
ベースとなるアーティファクトのYAMLファイルを用意します。前準備編のpipelineを原型としてこれから改変していくため、前回に使われていたdatabricks.ymlの中身をこちらに再掲載します。
bundle: name: 2025_APC_techblog #本アセットバンドルの名前 resources: #アーティファクトの情報を設定 pipelines: APC_techblog_bundle_202508: #Piplelineのプロジェクト名、リモート起動する際に必要 name: 20250806_TEST configuration: INGEST_PATH: /Volumes/000_sandbox/000_ingestion_data/000_trip_data/ #Databricks上でのデータソースのパス libraries: #Notebookのパスは、「databricks.ymlファイルから見る相対パス」を記述 - notebook: path: ./src/100_stream_bronze_ingestion.sql - notebook: path: ./src/200_stream_silver_filtering.sql - notebook: path: ./src/300_materialized_gold_aggregation.sql schema: ${var.dev_schema} continuous: false development: true photon: true channel: PREVIEW catalog: 000_sandbox serverless: true targets: #移行先の設定、必要に応じて、幾つかの環境を設定が可能。本篇では、devのみの設定になる。 dev: mode: development default: true workspace: host: https://dbc-xxxxxxxx-xxxx.cloud.databricks.com #ターゲットワークスペースのURL(一部マスキング済み)を記入 root_path: /Workspace/Users/yyyy@zzzz.co.jp/20250815_test #アセットバンドルの保存先@DatabricksPlatform(一部マスキング済み)、必要に応じて設定する variables: #ユーザー設定の変数、必要に応じて設定する def_schema: description: target schema for pipeline default: ingest_data dev_schema: description: target schema for dev default: 900_${var.def_schema}
こちらのYAMLファイルですが、ローカルマシンで保持されているDatabricks Asset Bundlesを一つのターゲットへマイグレーションするためのものになります。 これからはこのYAMLファイルを調整し、幾つかの環境へのマイグレーションを可能にします。
多環境間へデプロイのためのYAMLファイルの作成
仕上げたYAMLファイルの中身
変数代入を含め、最終的に作成される多環境間へのマイグレーションのためのYAMLファイルは下記の通りになります。また、こちらで掲載された例のデプロイ先はdevelopment環境とstaging環境になります。さらにproduction環境へのデプロイをしたい方はご自身で試してみてください。
bundle: name: 202508_APC_techblog resources: pipelines: APC_techblog_bundle_202508: name: 20250806_TEST configuration: INGEST_PATH: /Volumes/${var.ingest_catalog}/000_ingestion_data/000_trip_data/ libraries: - notebook: path: ./src/100_stream_bronze_ingestion.sql - notebook: path: ./src/200_stream_silver_filtering.sql - notebook: path: ./src/300_materialized_gold_aggregation.sql schema: ${var.base_schema} continuous: false development: true photon: true channel: PREVIEW catalog: ${var.target_catalog} serverless: true targets: development: mode: development presets: name_prefix: 'dev_chen_' default: true workspace: host: https://dbc-xxxxxxx-xxxx.cloud.databricks.com #ターゲットワークスペースのURL(一部マスキング済み)を記入 root_path: /Workspace/Users/xxx@yyyyyyy.aa.bbb/bundles/000_DEV_20250815_test #アセットバンドルの保存先@DatabricksPlatform(一部マスキング済み)、必要に応じて設定する variables: ingest_catalog: ${var.dev_catalog} target_catalog: ${var.dev_catalog} stage: mode: development presets: name_prefix: 'stg_chen_' workspace: host: https://dbc-xxxxxxx-xxxx.cloud.databricks.com #ターゲットワークスペースのURL(一部マスキング済み)を記入 root_path: /Workspace/Users/xxx@yyyyyyy.aa.bbb/bundles/100_STG_20250815_test #アセットバンドルの保存先@DatabricksPlatform(一部マスキング済み)、必要に応じて設定する variables: ingest_catalog: ${var.stg_catalog} target_catalog: ${var.stg_catalog} variables: target_catalog: description: target catalog setting default: 000_dev ingest_catalog: description: valoume catalog for ingesting data default: 000_dev base_schema: description: target schema for pipeline default: 100_pipeline_tables dev_catalog: description: target catalog for development env. default: 100_dev stg_catalog: description: target catalog for staging env. default: 200_stg
こちらのdatabricks.ymlファイルの中セクションごとを詳しく見ていきます。
bundle
本バンドルの基本設定になります。Nameはこのバンドルの名前を設定する項目で、必須になります。
resources
移行(マイグレーション)対象の中身になります。本ブログでは、Pipelineのみの移行になります。 Pipelineに関わる設定はパイプラインの元になるSQLスクリプト、パイプラインにより作成されたテーブルの登録先(カタログ、スキーマ)の設定を記述する箇所になります。 異なる環境へのマイグレーションがスムーズに行える、環境に対応するIngestionPathやカタログなどの設定は変数として設定してあります。設定の詳細はVariableというセクションを参照してください。
また、現在はPipelineが移行対象になりますが、Workflowなどの設定もできます。そして、移行対象のアーティファクトが多すぎる場合、スクリプトの書き方を変えて、アーティファクトに関する情報を他の場所(例えば/resources/)へ移動、変数などのマッピングによって構成することもできます。こちらに関しては、また後日とのことにいたしましょう。
targets
移行先の設定を記述するセクションになります。本ブログの場合、Development、Stagingの二つの環境を設定しております。それぞれの環境のWorkspaceURL、Mode(DevelopmentあるいはProduction)などを記述するところです。また、それぞれの環境における、パイプラインの運用における、データ取り込みの場所(Ingest_Schema)、作成されたテーブルの格納(登録)先(Target_schema)を事前に変数化をしておきました。移行先の環境に応じて、成果物(テーブル)の格納先が変更可能になっています。 Root_pathはアセットバンドルプロジェクトの移行先での格納場所を指定する場所になります。 また、オプション的な設定になりますが、移行されたアーティファクトの名前にプリフィックスを付けることもできます。こちらは「presets」の中の「name_prefixs」によって設定できます。
variables
変数の設定はこちらでまとめてあります。移行環境によって、例えば、取り込み先のパス、作成されたテーブルの格納先(カタログやスキーマ)は変更されます。これらの箇所、ハードコーディングすることもできますが、何かの理由で調整が必要になる場合、またはDatabricks.yml及びプロジェクトが大きくなり、同時に参照する必要なYAMLファイルが存在する場合になると、それぞれ対応する箇所を探しに行き、手動で変更することが必要になり、人為的なミスによりバグが生じるリスクも増えてきます。そのため、変数化可能な箇所を変数化の作業を行っておきましょう。
Databricks Asset Bundlesの変数の代入は階層的に代入することになっています。考え方によって階層の辿り方は違います。私は一番外側(アーティファクトの設定)から辿る形をとります。さて、見ていきましょう。
第一階層(アーティファクトの設定、resource項目)
アーティファクトに関わる設定で、必要なところを変数設定をしておきます。今の例ですと、データの取り込み先の一部(${var.ingest_catalog})、作成されたテーブル格納先のカタログ(${var.target_catalog})、スキーマ(${var.base_schema})を変数化しておきます。これらの変数は移行先(targets)よって変わることになります。どのように変わるかは第二階層に追跡していきます。
書き方はこちらになります。
resources: pipelines: APC_techblog_bundle_202508: name: 20250806_TEST configuration: INGEST_PATH: /Volumes/${var.ingest_catalog}/000_ingestion_data/000_trip_data/ libraries: (...中略...) schema: ${var.base_schema} continuous: false development: true photon: true channel: PREVIEW catalog: ${var.target_catalog} serverless: true
第二階層(ターゲットの設定、targets項目)
それぞれのターゲットに対応して、第一階層で設定された変数の受け渡しの設定を行います。 まず、ターゲットのdevとstgの設定項目の配下に、ingest_catalogとtarget_catalogの項目を用意します。そして、ターゲットがdevの場合、ingest_catalogとtarget_catalogは${var.dev_catalog}という変数を代入することに設定しておきます。同様に、ターゲットがstgの場合、ingest_catalogとtarget_catalogは${var.stg_catalog}という変数を代入することに設定しておきます。この記述で、ingest_catalogとtarget_catalogの中身はtargetによって変わります。
おさらいになりますが、書き方は下記の通りです。
targets: development: (...中略...) variables: ingest_catalog: ${var.dev_catalog} target_catalog: ${var.dev_catalog} stage: (...中略...) variables: ingest_catalog: ${var.stg_catalog} target_catalog: ${var.stg_catalog}
第三階層(変数設定本体、variables項目)
この項目で、それぞれの変数の「本体」を設定します。それぞれの変数に関するKeyとValueのペアーはここで明らかになります。 一部抜粋との形になりますが、下記の書き方になりますと、target_catalogというkeyに対し、000_devというvalueを実際に代入されることを設定してあります。
variables: target_catalog: description: target catalog setting default: 000_dev (..以下略...)
変数設定に関わる注意事項
Databricks Asset Bundlesを使用する際、変数設定の仕方にはいくつかの選択肢があります。本ブログで紹介したのはカスタム変数という設定方法でした。他はDatabricks Asset Bundles側から自動取得可能な変数を使用したり、Databricks CLIによるDatabricks Asset Bundlesを起動時に設定したり、別の設定ファイルを用意したりする、とのやり方があります。
特筆すべきなのは、自動取得可能な変数についてです。本家のドキュメントによりますと、ワークスペースのURLやユーザ名などの変数を自動取得することが可能になります。必要に応じて活用していただければと思います。
また、様々な変数設定の仕方があり、併用する際に優先順位を確認しながら変数設定を活用しましょう。
Databricks Asset Bundlesを実行
YAMLファイルの調整が終わりましたら、順番にローカルでバンドルされたアーティファクトをそれぞれの環境へのデプロイを行います。本ブログでは、developmentとstagingへのデプロイを行います。同じ手順を繰り返して、他の環境へのデプロイもできます。
各環境へのデプロイ
ローカルのコマンドプロンプトで「databricks bundle deploy -t <target_name> <bundle_name> -p <profile_name>」を入力すれば、対応の環境へBundleをアップロードします。
Development環境へのデプロイする場合、「databricks bundle deploy -t development 20250806_TEST -p 202508_DABtest」 になります。同様に、Staging環境へのデプロイする場合、「databricks bundle deploy -t stage 20250806_TEST -p 202508_DABtest」になります。実行する際に、フロントプロンプトの振る舞いはFig2の通りです。 デプロイする際に、フロントプロンプト上にメッセージが表示されます。最後に「Deployment completed!」が表示されたらデプロイが完了しました。

デプロイ結果を確認
無事にデプロイのコマンドの実行が終わりましたら、ワークスペースに移動し、デプロイされたアーティファクトを確認しましょう。 Fig3で示された通り、Workspaceの配下にDevelopment環境とStaging環境のためのフォルダーが作成されます。それぞれのフォルダーにはそれぞれの環境に必要なアーティファクト(コードやYAMLファイルなど)が格納されています。また、Pipelineの表示画面からも、それぞれの環境に対応する二つのパイプライン(dev_chen_20250806_TESTとstg_chen_20250806_TEST)が作成されていることを確認できます。
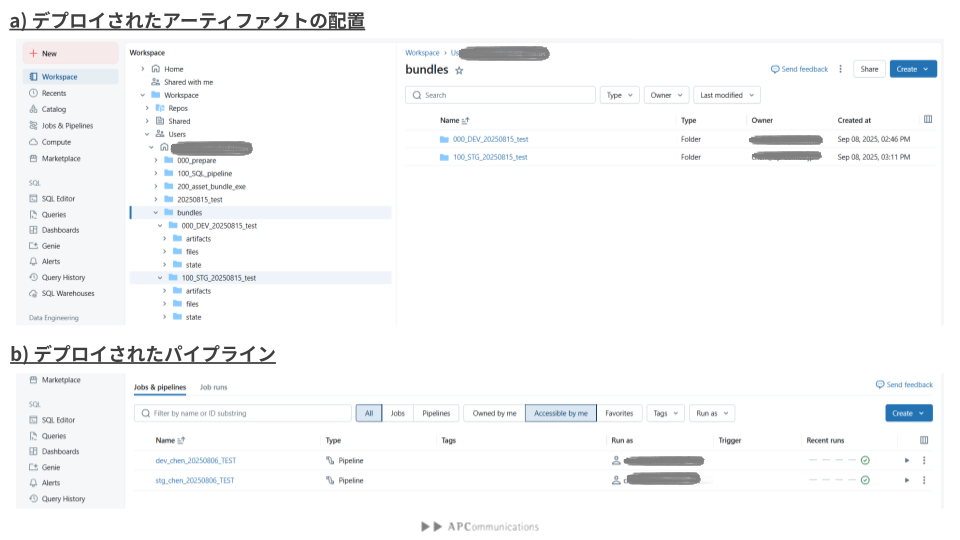
パイプラインの実行
それぞれのパイプライン、起動・実行してみましょう。起動する際に、ワークスペース上のUIによるパイプラインの実行、またはローカルのコマンドによるパイプラインの実行が可能です。使い慣れている方を選んでいただけます。実行結果はFig4に示しています。
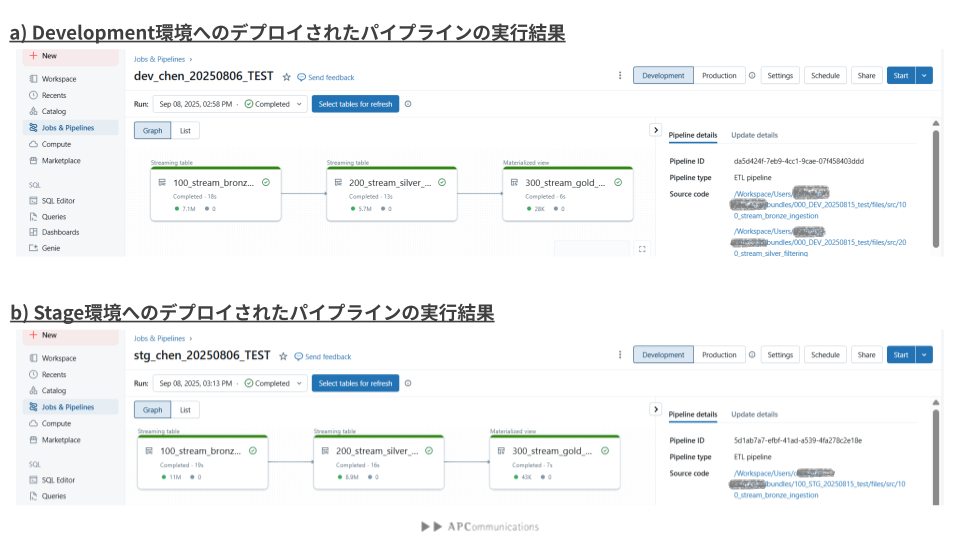
それぞれのパイプラインは実行可能になっています。処理された行数に違いはあり、取り込み先に置かれているデータ量の違いによるものになります。(取り込み先の変更などの詳細はdatabricks.ymlに記載してあります。)
おわりに
また長いブログになりました。最後まで読んでいただきありがとうございました。 本篇を通し、Databricks Asset Bundlesを利用して、変数設定を活用した多環境間へのアーティファクトへのデプロイについて、少しご紹介できればと思います。
最後に

私たちはDatabricksを用いたデータ分析基盤の導入から内製化支援まで幅広く支援をしております。もしご興味がある方は、お問い合わせ頂ければ幸いです。
また、一緒に働いていただける仲間も募集中です! APCommunicationsにご興味がある方の連絡をお待ちしております。