Databricks Data + AI Summit 2025 Keynote 2日目

Databricks Data + AI Summit 2025のKeynote 2日目では、データとAIの活用をさらに加速させる、エンジニアにとってもビジネスユーザーにとっても非常に興味深い発表が目白押しでしたね。今回は、「Data Intelligence for All(すべての人のためのデータインテリジェンス)」というテーマのもと、データエンジニアリングからAI/BIまで、プラットフォーム全体を包括的に強化する数々の新機能がお披露目されました。
Databricksは、従来の分析プラットフォームの枠を超え、データとAIのライフサイクル全体を網羅する「オペレーティングシステム」のような存在へと進化しようとしているのが、今回の発表からも強く感じられました。オープンソース技術(Apache Spark、Delta Lake、MLflowなど)を基盤に成長してきたDatabricksは、エンタープライズでのAI活用が本格化する中で生じるデータのサイロ化やガバナンスの複雑さ、専門知識の属人化といった課題に対し、Unity Catalogによる統一ガバナンスやLakehouseアーキテクチャで応えてきましたよね。
今回のSummitでは、データの取り込み(Lakeflow Connect)から変換・オーケストレーション(Lakeflow Declarative Pipelines, Jobs)、ノーコード開発(Lakeflow Designer)、さらにはBI(AI/BI, Databricks One)、AIエージェント開発(Agent Bricks)といった、データとAIの活用プロセス全体をカバーする統合プラットフォーム戦略をさらに加速させる動きが見られました。これは、技術者だけでなく、ビジネスユーザーにもデータとAIの恩恵を広げ、企業全体のイノベーションを促進するというDatabricksの大きなビジョンに基づいていると言えるでしょう。このビジョンの実現には、オープン性とGoogle Geminiのようなパートナーシップが不可欠だということも、強調されていましたね。
それでは、今回のKeynoteで発表された主要なサービスを、まずは一覧で確認してみましょう。
今回発表された主要サービスの一覧
| カテゴリ | サービス名 | サービス概要 | 現時点(2025/06)のステータス |
|---|---|---|---|
| Spark | Spark 4.0 | SQL言語機能の拡張(SQLスクリプティング、PIPE構文、UDFなど)やPython APIの強化、VARIANTデータ型対応など、開発者体験とパフォーマンスが向上しました。 | 一般提供開始(GA) |
| Spark | Real-time mode | Spark Structured Streamingに導入された超低レイテンシ(p99で300ミリ秒未満)の実行モードで、運用系ユースケースに対応します。 | Public Preview(Apache Sparkへのコントリビューション進行中、次期リリース見込み) |
| Spark | Spark Declarative Pipelines | DatabricksのDelta Live Tables (DLT) で培われた宣言的ETLフレームワークをApache Sparkに寄贈し、バッチ/ストリーミング処理を単一APIで定義できるようになりました。 | Apache Sparkプロジェクトへコードマージ済み |
| Unity Catalog | Iceberg Managed Table | Unity CatalogがApache Iceberg形式のテーブルをフルサポートし、外部エンジンからのガバナンスされた読み書き、パフォーマンス最適化、Delta Sharing連携を実現します。 | Public Preview |
| Unity Catalog | Unity Catalog Metrics | ビジネス上の重要な指標(メトリクス)をUnity Catalog内で一元的に定義・管理できるセマンティックレイヤー機能です。BIツールなどから一貫した定義でアクセスできます。 | 2025年夏に一般提供開始(GA) |
| Unity Catalog | Unity Catalog Discover | 組織内のデータ資産(テーブル、ダッシュボード、AIモデルなど)をキュレーションし、ビジネスドメイン別に整理して容易に発見・アクセスできるようにする内部データマーケットプレイスです。 | Public Preview |
| Lakeflow | Lakeflow Connect | さまざまなエンタープライズアプリケーションやデータベースからデータをDatabricksプラットフォームへ効率的に取り込むための、ノーコード/APIベースのコネクタ群です。 | 一般提供開始(GA) |
| Lakeflow | Lakeflow Declarative Pipelines | DatabricksのDelta Live Tables (DLT) の進化版であり、オープンソースのSpark Declarative Pipelinesを基盤とする宣言的パイプライン構築機能です。AutoCDCや新しいIDE機能が提供されます。 | 一般提供開始(GA) |
| Lakeflow | Lakeflow Jobs | Databricksのワークフローオーケストレーション機能で、Power BI、dbt Labs、Snowflakeといった外部ツールのタスク実行も統合管理できるようになりました。 | 一般提供開始(GA) |
| Lakeflow | Lakeflow Designer | プログラミング知識がほとんどないユーザーでも、ドラッグ&ドロップや自然言語指示で本番環境グレードのETLパイプラインを構築できるAI搭載ノーコードパイプラインビルダーです。 | Public Preview(Summit後まもなく開始予定) |
| DB SQL | LakeBridge | レガシーデータウェアハウスからDatabricks SQLへの移行を支援する、無料・オープン・AI対応の移行ツールです。 | コア機能は一般提供開始(GA)、AIコード変換は段階的に導入中 |
| AI/BI | Genie Deep Research | DatabricksのAIアシスタント「Genie」の拡張機能で、オープンエンドなビジネス課題に対しAIが自律的に調査計画を立案・実行し、根拠付きの洞察を提示します。 | 将来リリース予定(2025年夏にPublic Preview開始予定) |
| AI/BI | Genie Knowledge Extraction | Genieがユーザーの利用状況や対話から組織固有の知識を抽出し学習する機能で、より正確で文脈に即した回答生成に役立ちます。 | Public Preview(Unity Catalogへのナレッジ公開は今後リリース予定) |
| AI/BI | Databricks One | 営業、マーケティング、財務などのビジネスユーザー向けに特別に設計された、Databricksプラットフォームの新しいエントリーポイントUIです。コードフリーでAI/BIダッシュボードやGenie、カスタムアプリにアクセスできます。 | Public Preview(2025年夏後半にパブリックベータ予定) |
| Gemini on Databricks | Googleの最先端大規模言語モデル(LLM)であるGeminiモデル群を、Databricks Data Intelligence Platformにネイティブに統合します。 | Keynoteで発表(近く導入予定) |
各サービス別解説
Spark関連発表
Spark 4.0 Apache Sparkは、データ処理の根幹を担うオープンソースプロジェクトであり、その最新メジャーバージョンであるSpark 4.0が2025年5月28日に一般提供開始(GA)されました。これはSparkとして初の4.x系メジャーバージョンとなる、大きな節目と言えるでしょう。

Spark 4.0の主な強化点としては、まずSQL言語の拡張が挙げられます。セッション変数やコントロールフローを含むSQLスクリプティング、再利用可能なSQL UDF(ユーザー定義関数)、分析ワークフロー向けのPIPE構文が導入されたことで、より複雑なロジックをSQL内でシンプルに記述できるようになりました。これによって、データエンジニアやアナリストは、これまでコードで実現していた複雑な処理をSQLでより効率的に表現できるようになる、というわけですね。
また、データ整合性の向上と相互運用性の改善のため、ANSIモードがデフォルトで有効化されました。半構造化JSONデータの効率的な処理を可能にする新しいデータタイプとしてVARIANTデータタイプも追加されており、JSONのような多様な形式のデータをLakehouseで扱う際に非常に役立つでしょう。
さらに、Pythonのデータサイエンティストにとって嬉しい機能もたくさんあります。カスタムのPythonバッチ・ストリーミングコネクタを実装できるPython Data Source APIや、動的スキーマをサポートするPolymorphic Python UDTF、そしてPySpark DataFrameで直接プロットを作成できるPlotly統合機能は、探索的データ分析(EDA)の効率を大きく向上させてくれそうですね。
Spark Connectの機能も改善され、Swift、Rust、Go言語クライアントのサポートが追加されました。これにより、多言語環境でのSpark利用がさらに容易になっています。構造化ログによるエラー分析とデバッグ機能の向上も、開発者の生産性向上に貢献します。
Spark 4.0は、AWS、Azure、GCPといった主要なクラウドプラットフォームのDatabricks Runtimeで利用可能であり、オンプレミス環境などでも利用できるオープンソースの特性を持っています。
公式ブログ: Introducing Apache Spark 4.0
Real-time mode Databricksは、Spark Structured Streamingにおいて、サブ秒からミリ秒レベルの超低レイテンシを実現する新しい実行モード「Real-time mode」を発表しました。これは、従来のマイクロバッチ処理(通常、数秒から数分のレイテンシ)では難しかった、より即時性が求められる運用系のユースケースに対応することを目的としています。
Real-time modeの技術的な成果としては、p99レイテンシを300ミリ秒未満で一貫して実現し、従来の10倍以上の低レイテンシを達成したと報告されています。このモードでは、マイクロバッチ方式のように事前に処理するデータを決定するのではなく、長時間稼働するタスクが常に新しいデータをポーリングし続け、データ到着後すぐに処理・更新を行うアーキテクチャを採用しています。これにより、リアルタイム推奨システムやリアルタイム不正検知、IoT制御といった、これまでSparkでは難しかった超低遅延の用途にも対応可能になる、というわけです。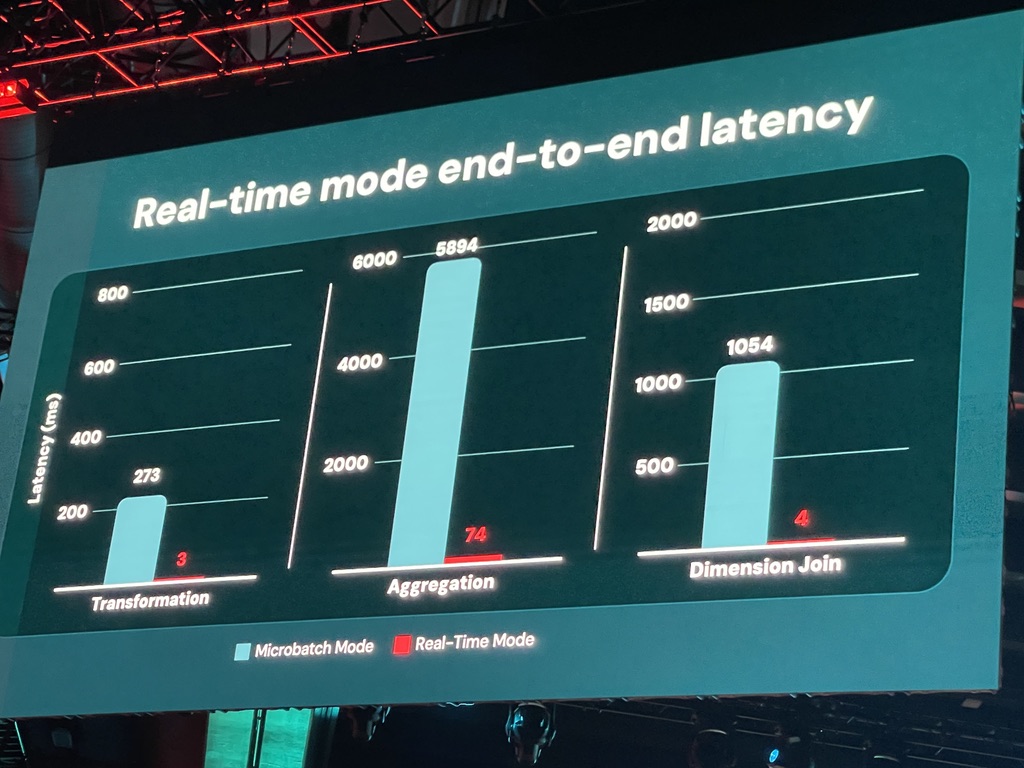
このReal-time modeはApache Sparkのオープンソースプロジェクトに寄贈される予定で、Spark Improvement Proposal (SIP) も承認済みとのこと。おそらくSpark 4.xの次のリリースで利用可能になる見込みだそうですね。これにより、Sparkエコシステム全体がこの超低レイテンシ処理の恩恵を受けられるようになり、Sparkの適用範囲が大幅に拡大することが期待されます。対応クラウドはAWS、Azure、GCP上のDatabricks Runtimeで利用可能になる見込みです。
Spark Declarative Pipelines Databricksは、Apache Sparkオープンソースプロジェクトに「Spark Declarative Pipelines」を寄贈することを発表しました。これは、DatabricksのDelta Live Tables (DLT) の開発で培われた、データパイプライン構築の複雑さを解消する宣言的なアプローチをベースにしています。
このフレームワークにより、開発者はわずか数行のSQLまたはPythonコードで、エンドツーエンドの本番環境グレードのデータパイプラインを構築できるようになります。主要な技術特徴としては、バッチ処理とストリーミング処理の両方を単一のAPIで定義・管理できる統一性があります。、パイプラインの目的を定義すれば、実行方法はSparkが自動で決定する宣言的アプローチ、堅牢なパイプライン作成に必要なコーディングの最小化、実行前の完全なパイプライン定義検証、そして複雑なデータ依存関係の自動処理が挙げられます。
従来のSparkパイプライン構築では、手動でのチェックポイント管理、障害復旧、依存関係の解決といった運用管理タスクに多くの工数が必要でしたが、宣言的なアプローチを採用することで、これらの課題が解消され、データエンジニアはビジネスロジックの実装といった本質的な作業に集中できるようになります。
Spark Declarative Pipelinesのコードは既にApache Sparkにマージされており、近い将来Sparkの公式リリース内で利用可能になる見込みです。これにより、Databricksプラットフォーム(AWS、Azure、GCP)を含む、Sparkが動作するあらゆる環境で利用可能になるでしょう。
公式プレスリリース: Databricks Donates Declarative Pipelines to Apache Spark™ Open Source Project
Unity Catalog関連発表
Iceberg Managed Table Unity Catalogは、データとAI資産全体にわたる統一されたガバナンスを実現するためのオープンなカタログソリューションとして、その進化を続けています。今回のKeynoteでは、共同創業者であるMatei Zaharia氏が、Unity CatalogにおけるApache Icebergのフルサポート、すなわち「Iceberg Managed Table」のパブリックプレビュー開始を発表しました。これは、Databricksが2024年に買収したTabular社の技術を統合した成果だそうですね。
Iceberg Managed Tableの主な技術的機能は以下の通りです。
- 完全なApache Icebergサポート: Unity CatalogがApache Iceberg REST Catalog APIを完全にサポートすることで、Icebergテーブルを“Managed Table”として作成・管理できます。
- 任意のエンジンからの読み書きアクセス: Snowflake、Trino、Amazon EMR、DuckDB、Apache Spark、Daft、Dremioといった外部エンジンからも、Unity Catalog経由でIceberg Managed Tableへの読み取りおよび書き込みが可能になります。特にSnowflakeからの書き込み機能は現在Public Preview段階です。

- 統一ガバナンス: Delta LakeとApache Iceberg形式の間でシームレスなガバナンスを実現し、外部エンジンからのアクセス時にもUnity Catalogで設定されたきめ細やかなアクセスコントロールポリシー(属性ベースアクセス制御など)が厳密に適用されます。
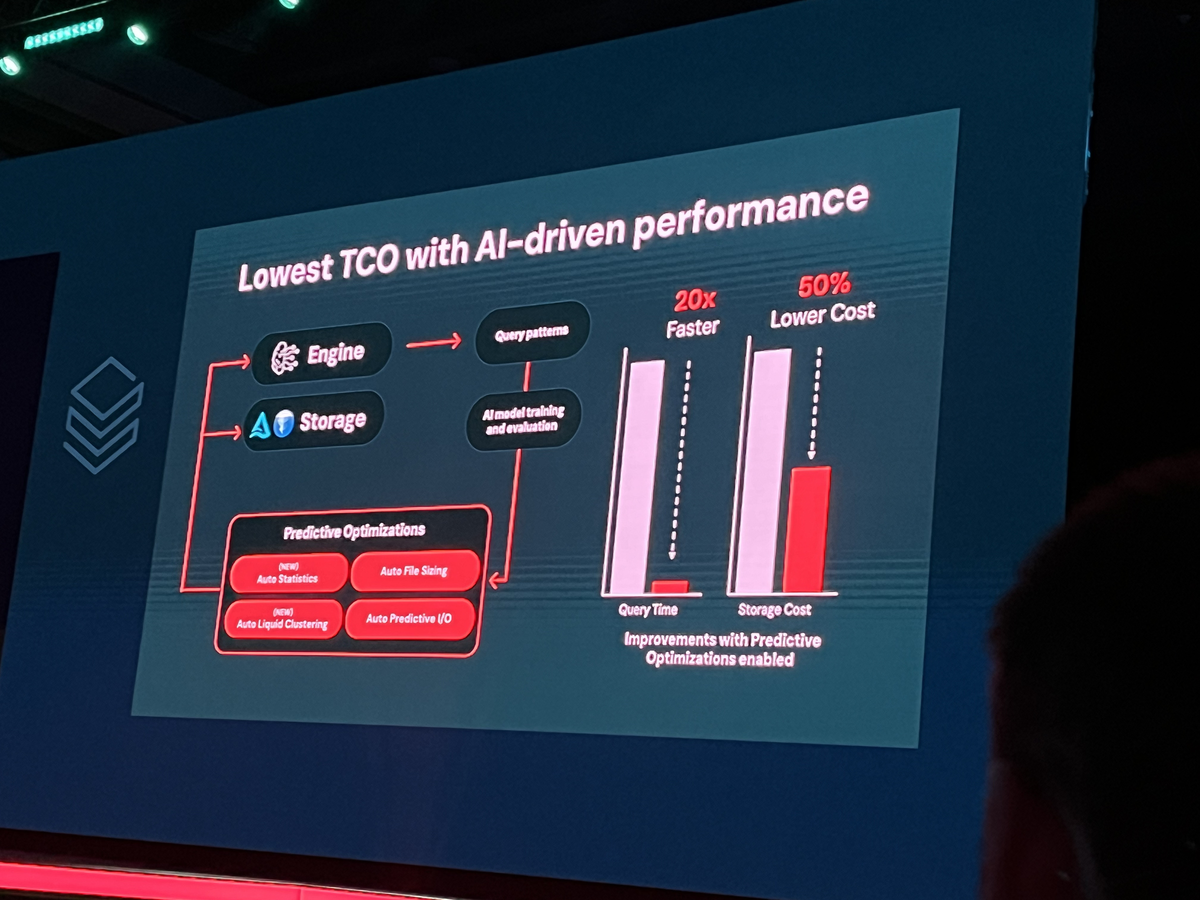
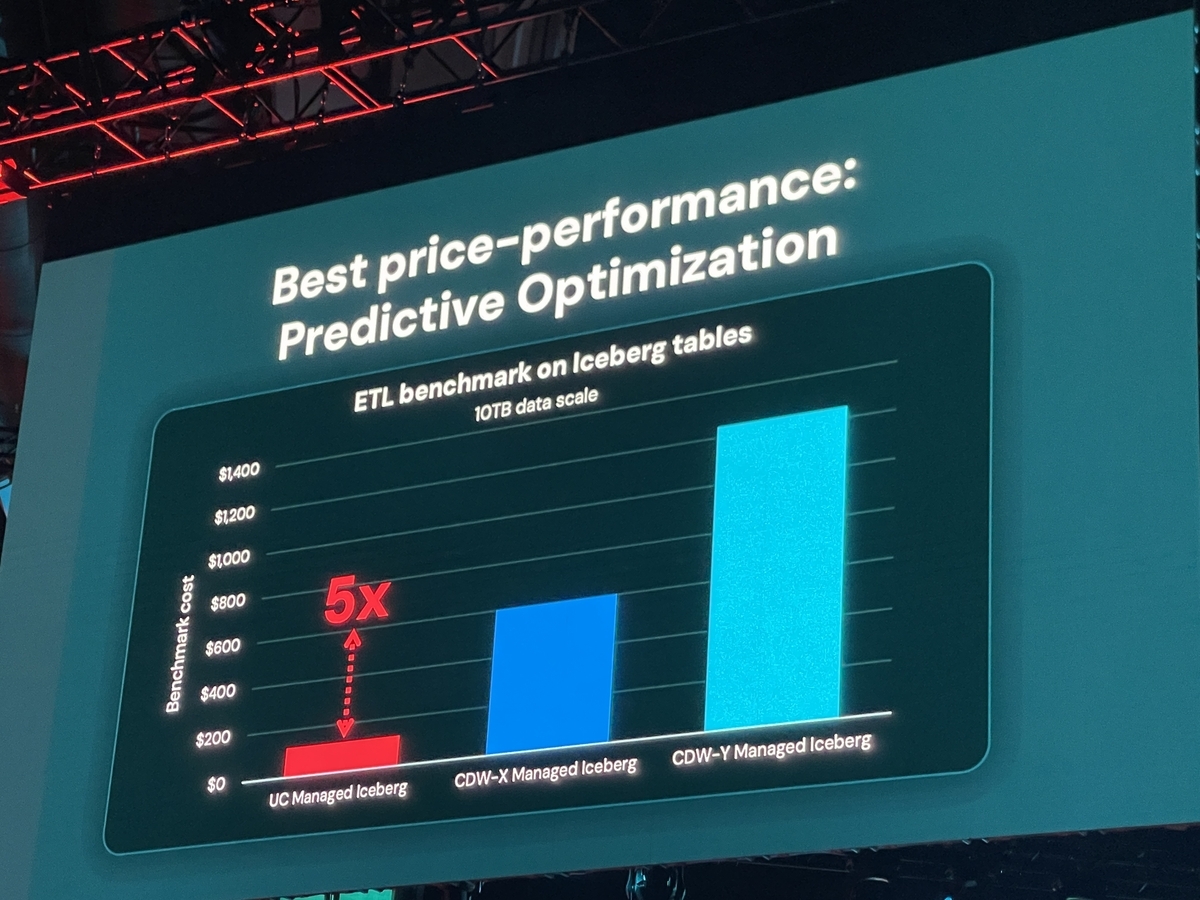
- パフォーマンス最適化: DatabricksがDelta Lake向けに開発してきた予測最適化技術(Predictive Optimization)をIcebergテーブルにも応用し、クエリ性能を最大5倍向上させるとのことです。
- Delta Sharingエコシステムとの連携: IcebergテーブルをDelta Sharingプロトコルを通じて、組織内外の他のユーザーやシステムと安全かつ容易に共有できるようになりました。
 この機能は、データレイクハウスの世界におけるDelta LakeとApache Icebergという主要なオープンテーブルフォーマットの共存を促進し、ユーザーが特定のフォーマットにロックインされることなく、既存のデータ資産をUnity Catalogによる一元的なガバナンスの下で活用できるようになるという点で、非常に戦略的な動きだと言えるでしょう。
この機能は、データレイクハウスの世界におけるDelta LakeとApache Icebergという主要なオープンテーブルフォーマットの共存を促進し、ユーザーが特定のフォーマットにロックインされることなく、既存のデータ資産をUnity Catalogによる一元的なガバナンスの下で活用できるようになるという点で、非常に戦略的な動きだと言えるでしょう。

対応クラウドはAWS、Azure、GCP全てで利用可能ですが、現在のところApache Parquetファイル形式のみをサポートし、行レベル削除には非対応という技術的制限がある点も理解しておきたいですね。GAは2025年後半を予定しているそうです。
Unity Catalog Metrics 企業にとって重要なビジネス指標(メトリクス)の定義が、部門や利用するツールによって異なり、混乱を招くケースは少なくありません。この課題を解決するため、Unity Catalog Metricsが2025年6月にパブリックプレビューとして発表され、2025年夏に一般提供開始(GA)の予定です。
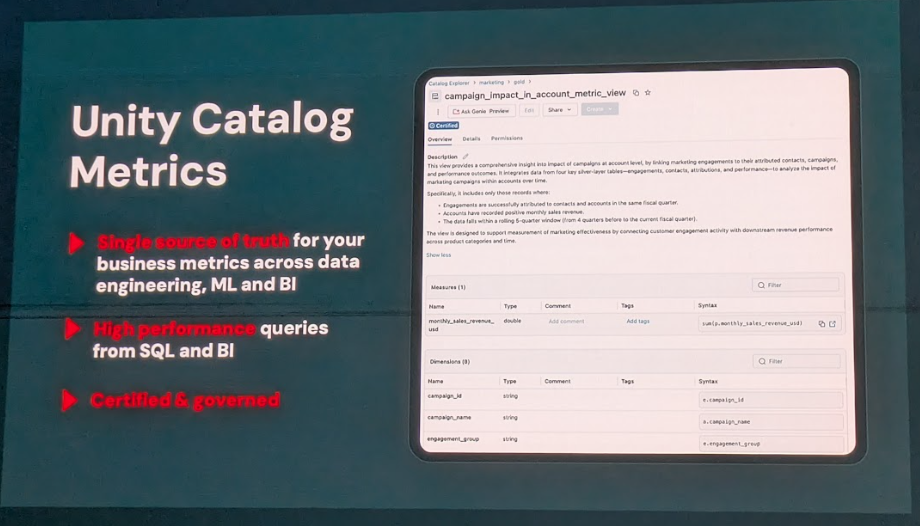
Unity Catalog Metricsは、ビジネスKPIやその他のメトリクスの計算方法(メジャー)や分析の切り口(ディメンション)を、YAMLベースでUnity Catalog内に一元的に定義できるセマンティックレイヤー機能です。これにより、データエンジニアリング、データサイエンス、ビジネスインテリジェンス(BI)といった異なる分野のユーザーが、組織全体で一貫したメトリクス定義を利用できるようになります。
主な特徴は以下の通りです。
- SQLアドレス可能性: 定義されたメトリクスは、MEASURE集約関数を使って完全にSQLでアドレス可能であり、Databricksプラットフォーム上のあらゆるコンピューティング環境や、外部のBIツールから、同一の定義に基づいて参照・理解できます。
- 集約化されたビジネスロジック: 複雑なビジネスロジックを集約化された定義に抽象化することで、利用者は計算の詳細を意識することなく、ビジネス上の意味でメトリクスを利用できます。
- ガバナンス機能: 組み込みの監査、系譜追跡、アクセス制御といったUnity Catalogの堅牢なガバナンス機能の対象となり、メトリクス定義の信頼性が確保されます。
- パフォーマンス最適化: Databricksのクエリエンジンおよび外部BIツール双方において、メトリクス計算のパフォーマンスが最適化され、高速な分析を実現します。
特に注目すべきは、主要なBIツールとのパートナー統合が進んでいる点です。TableauやSigma Computingは、Unity Catalog Metricsと連携するパートナーとして発表されており、Sigma ComputingはDatabricksの「2025 Business Intelligence Partner of the Year」を受賞しています。これにより、ユーザーは使い慣れたBIツールを継続利用しながら、Databricks上で定義された信頼性の高いメトリクスに基づいて分析を行えるようになる、というわけですね。その他にもHex、ThoughtSpot、Omni、Power BI、Lookerといったツールとの連携が示唆されています。
対応クラウドはAWS、Azure、GCP全てでパブリックプレビューが利用可能です。
公式ブログ: What's new in Databricks Unity Catalog - Data + AI Summit 2025 Databricks Eliminates Table Format Lock-in and Adds Capabilities for Business Users with Unity Catalog Advancements
Unity Catalog Discover 組織内にデータ資産が増え続ける中で、目的のデータを見つけ出し、その信頼性を判断することはますます困難になっていますよね。Unity Catalog Discoverは、この課題を解決するため、組織内のデータを整理し、ユーザーが必要なデータ資産に容易にアクセスできるようにする全く新しい方法として、Public Preview版が発表されました。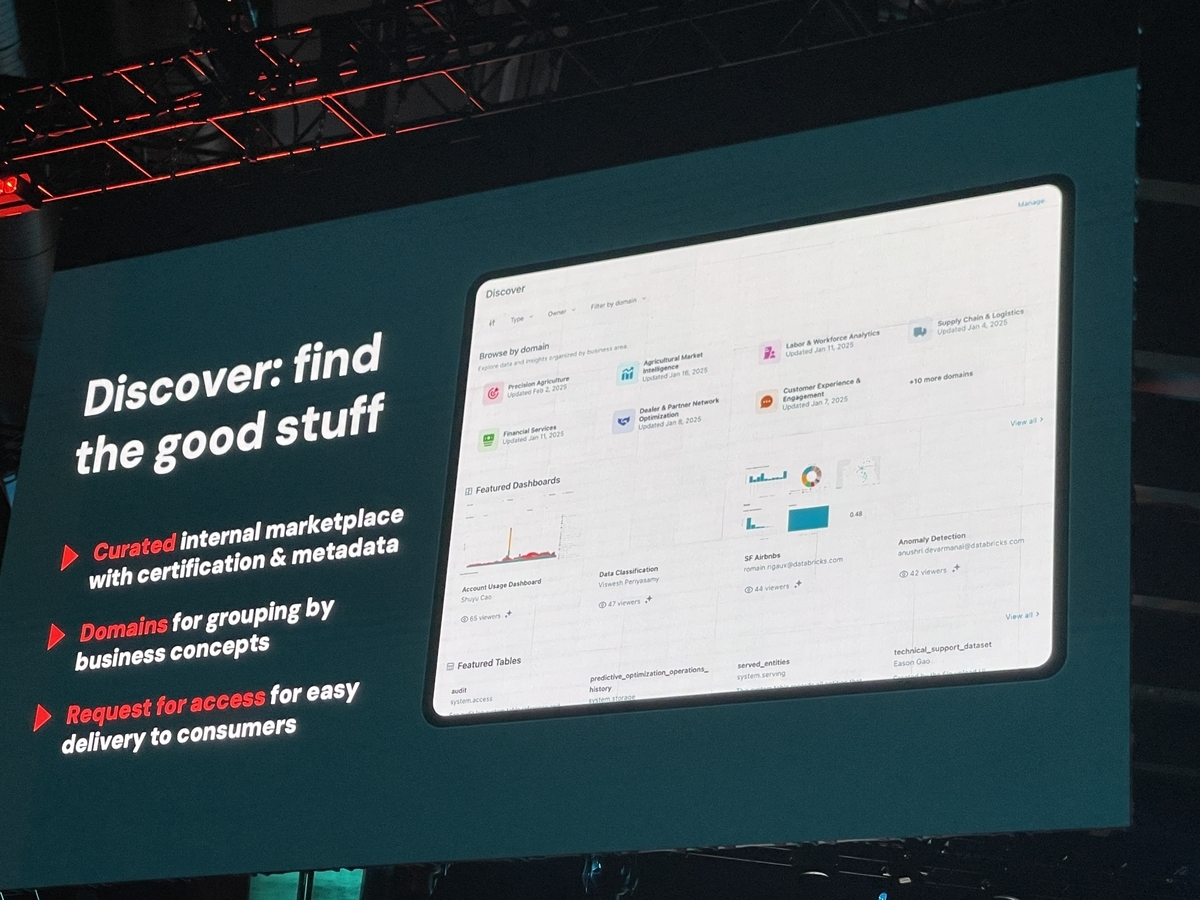
Unity Catalog Discoverは、キュレーションされた「内部データマーケットプレイス」のように機能し、信頼性の高いデータ資産の発見を支援します。主な機能は以下の通りです。
- AI搭載発見機能: 使用パターンに基づいたインテリジェントなレコメンデーション機能を提供します。
- ビジネスドメイン組織: 営業、マーケティング、財務といったビジネスドメイン別にデータ製品を整理できるため、ユーザーは膨大なテーブル一覧から探すのではなく、自身の業務に関連する精選された資産を効率的に閲覧できます。
- 自然言語インターフェース: Databricks Assistantが組み込まれており、自然言語での質問を通じて、コンテキストに応じた回答や関連資産の推奨が可能です。
- キュレーションと認証: データスチュワードが認定した高品質な資産や、組織内で広く利用されている信頼性の高い資産を明確に表示できます。タグ付けや、廃止予定資産への警告表示なども可能です。
- アクセス権リクエスト: 必要なデータ資産を発見した際に、その場でシームレスにアクセス権限をリクエストできる仕組みを提供します。
Unity Catalog Discoverは、単に技術的なメタデータをリストするだけでなく、認証マークの付与、利用頻度や関連性の高いユーザーといったソーシャルな情報、さらにはデータ品質に関するインサイトなどを前面に出すことで、ユーザーが安心してデータを選択し、活用できるように支援する、という点がポイントですね。これにより、データ探索にかかる時間を短縮し、データ活用のハードルを大きく下げることが期待されます。
対応クラウドはAWS、Azure、GCP全てで利用可能になる見込みです。
公式ブログ: What's new in Databricks Unity Catalog - Data + AI Summit 2025
Lakeflow関連発表
Lakeflow Connect データエンジニアリングにおいて、様々なデータソースからの効率的なデータ取り込みは、常に重要な課題ですよね。Lakeflow Connectは、エンタープライズアプリケーションやデータベースからのノーコードデータ取り込みを実現する機能群として、2025年6月時点で一般提供開始(GA)されました。
このサービスの主要機能は以下の通りです。
- 豊富なコネクタ群: Salesforce Platform、Workday Reportsは既にGA済みで、Google Analytics、ServiceNow、SQL Server、SharePoint、PostgreSQL、SFTPといったコネクタもプレビュー/ベータとして提供されています。これにより、多種多様なSaaSアプリケーション、データベース、ファイルソースからデータを効率的に取り込めるようになりました。

- ノーコードでのデータ取り込み: 直感的なポイント・アンド・クリックのユーザーインターフェースを提供しており、技術者でなくても数クリックで接続先を選択し、データ取り込みを設定できます。同時に、自動化のための強力なAPIも提供されているので、エンジニアは高度な設定も可能ですよ。
- 自動インクリメンタル処理(CDC): 初回ロード後は、ソースシステムで変更があったデータやテーブルの更新箇所のみを効率的に取り込む変更データキャプチャ(CDC)機能を備えています。これにより、高速かつスケーラブルなデータ取り込みが実現し、運用効率が高まるでしょう。このCDC技術には、Arcion買収によって得られた技術が活かされているそうですね。
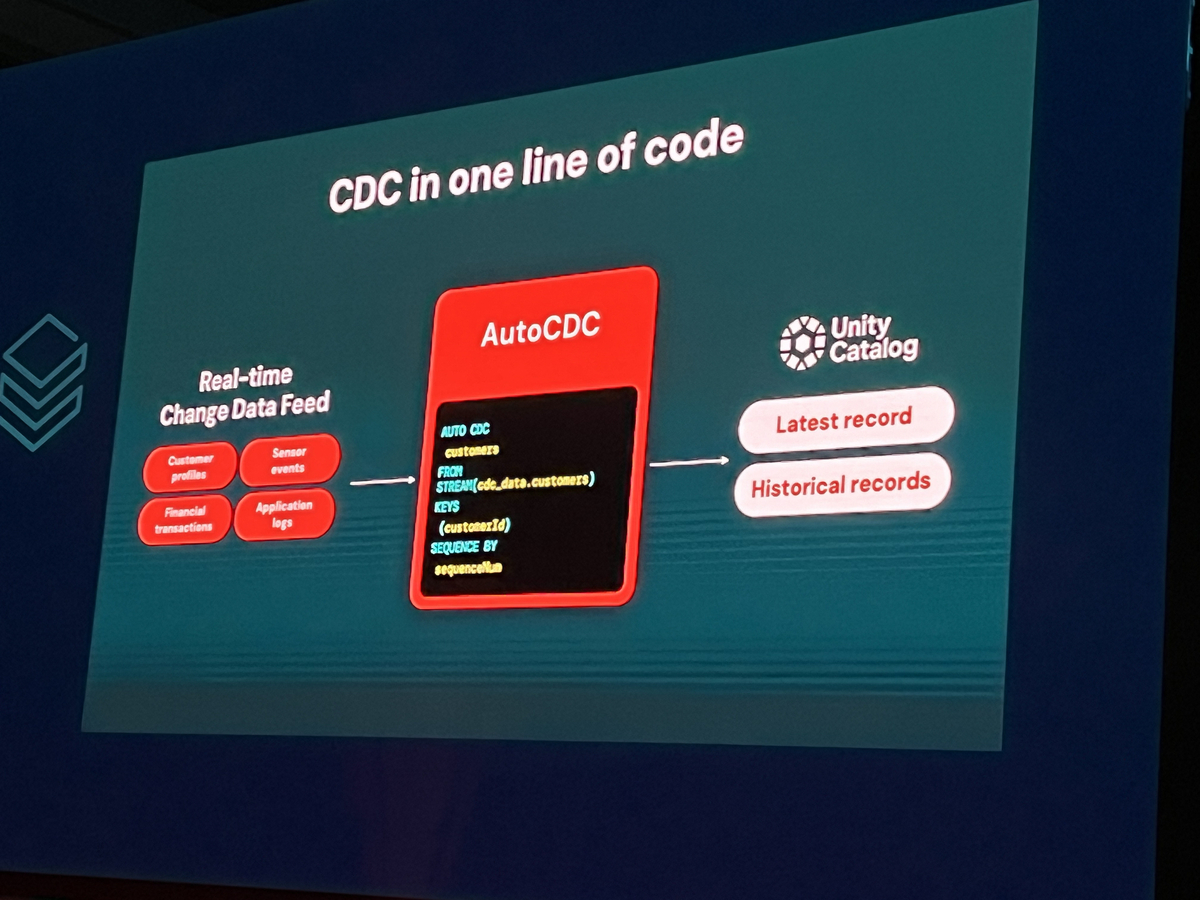
- Unity Catalog連携: 取り込まれたデータは自動的にUnity Catalogに登録され、リネージ(データの系譜)追跡やデータ品質管理といった堅牢なガバナンス機能の対象となります。
- Zerobus: 特に注目したいのが、高スループットの直接書き込み機能「Zerobus」です。これは、KafkaやAmazon Kinesisといった従来のメッセージバスシステムを介さずに、アプリケーションやデバイスから直接Unity Catalog内のテーブルにデータをプッシュできる新しいAPIなんです。最大100MB/sのスループットと5秒未満のレイテンシで、IoTイベント、クリックストリームデータ、テレメトリ、製造データといった大量のイベントデータをほぼリアルタイムで取り込むことが可能になりました。Joby Aviation社が電動航空機の工場現場からのデータ収集にZerobusを活用している事例も紹介されましたね。これにより、インフラの複雑性を低減し、データ取り込みパイプラインのセットアップが格段に容易になります。
 Lakeflow Connectは、Databricksプラットフォームのデータ取り込みの「入口」として、重要なコンポーネントであり、AWS、Azure、GCPの全ての主要クラウドプラットフォームで完全にサポートされています。
Lakeflow Connectは、Databricksプラットフォームのデータ取り込みの「入口」として、重要なコンポーネントであり、AWS、Azure、GCPの全ての主要クラウドプラットフォームで完全にサポートされています。
公式製品ページ: Efficient data ingestion into your lakehouse - Lakeflow Connect Managed connectors in Lakeflow Connect - Databricks Documentation
Lakeflow Declarative Pipelines Lakeflow Declarative Pipelinesは、データエンジニア向けの宣言的パイプライン構築機能であり、Databricksの主力機能であるDelta Live Tables (DLT) を進化させたものとして、一般提供開始(GA)となりました。この機能の基盤は、前述のApache Sparkオープンソースプロジェクトとして提供される「Spark Declarative Pipelines」にあり、100%のソース互換性を持つ点が特筆されます。これにより、既存のDLTパイプラインは変更なしにそのまま動作し、オープンな標準技術に基づいたパイプライン開発が可能になりました。
主な技術特徴は以下の通りです。
- Spark Declarative Pipelinesベース: オープンソース標準上で動作するため、特定のベンダー技術へのロックインを回避し、広範なSparkエコシステムの力を活用できます。
- 自動インクリメンタルETL(AutoCDC): 「Enzymeエンジン」と呼ばれる内部メカニズムにより、ソースデータの変更箇所を自動的に検出し、関心のある変更データのみを効率的に処理します。これにより、パイプラインの処理時間とコンピューティングコストを大幅に削減できます。SCD (Slowly Changing Dimension) Type 1およびType 2のシナリオにも対応し、順序が前後して到着するイベント(out-of-order events)も自動的に処理してくれるため、手動での複雑なコーディングが不要になります。

- 実績に裏打ちされた信頼性: ベースとなるDLTの技術は、Databricksによって4年以上にわたり本番環境で運用されてきた実績があり、高い信頼性と安定性を備えています。
- 新しいIDE機能: データエンジニアの開発生産性向上のために設計された、新しい統合開発環境(IDE)も発表されました。このIDEは、コードエディタとデータフローグラフの視覚的な表示、サンプルデータ、デバッグコンソールなどを単一ワークスペース内で実現し、AIによるコーディング支援やリアルタイムフィードバック機能を備えています。IDEは「まもなく提供予定」とされています。
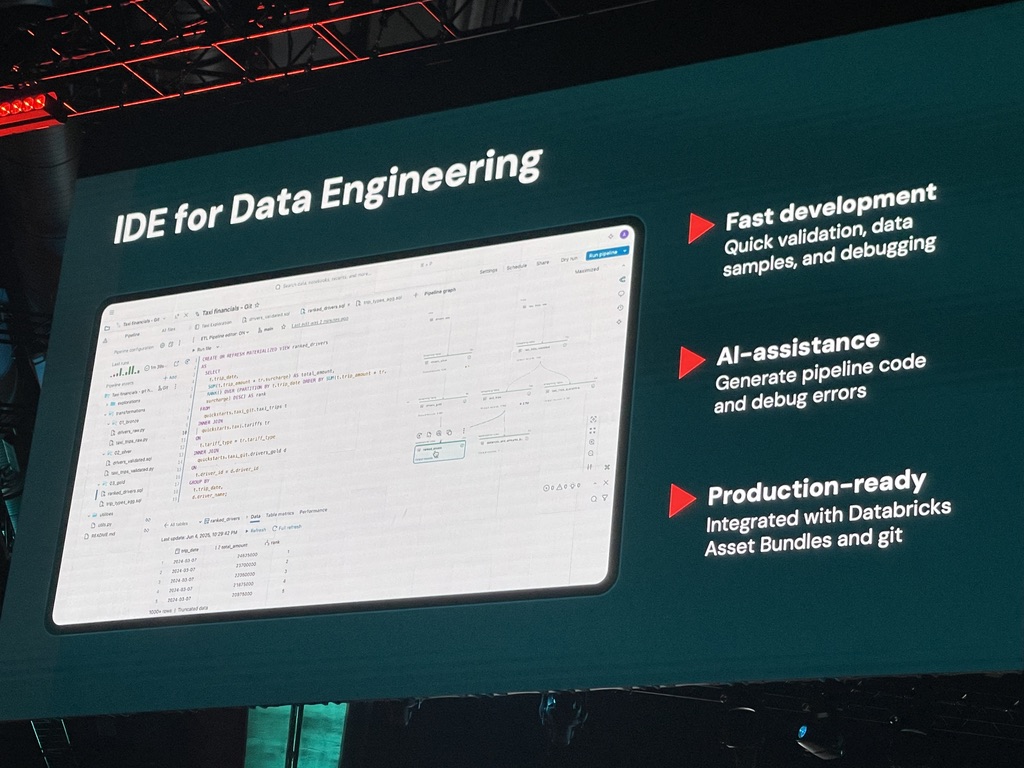 Lakeflow Declarative Pipelinesは、宣言的なパイプライン構築の容易さと運用信頼性を維持しつつ、その基盤をオープンソース標準と連携させることで、より広範なエコシステムとの親和性を高めている、という点がポイントですよね。これにより、ユーザーはオープンな技術基盤の上で開発できる安心感と、Databricksならではの高度な機能性や使いやすさの両方を享受できるようになります。AWS、Azure、GCPの各クラウドプラットフォームで利用可能です。
Lakeflow Declarative Pipelinesは、宣言的なパイプライン構築の容易さと運用信頼性を維持しつつ、その基盤をオープンソース標準と連携させることで、より広範なエコシステムとの親和性を高めている、という点がポイントですよね。これにより、ユーザーはオープンな技術基盤の上で開発できる安心感と、Databricksならではの高度な機能性や使いやすさの両方を享受できるようになります。AWS、Azure、GCPの各クラウドプラットフォームで利用可能です。
参考情報: Lakeflow Declarative Pipelines concepts - Azure Databricks
Lakeflow Jobs Lakeflow Jobsは、Databricksのワークフローオーケストレーション機能であり、既存のDatabricks Workflowsからリブランドされ、一般提供開始(GA)となりました。これは、Lakehouse環境において最も信頼されるオーケストレーターとしての地位を確立しており、発表時点で約15,000社の顧客、約20万人の週間アクティブユーザー、そして週間1億件以上のジョブ実行数を誇るとのことです。
Lakeflow Jobsの主な特徴は、その高度なワークフローオーケストレーション能力と、外部ツールとの連携強化にあります。

* 高度な制御フロー: ジョブあたり最大1,000タスク、ワークスペースあたり12,000保存ジョブをサポートし、ネイティブなfor-eachループ、条件ロジック、分岐といった高度な制御フロー構造をワークフロー内に組み込むことができます。これにより、複雑なジョブシーケンスをDatabricks上で効率的に管理できるようになりました。
* 外部ツール連携の強化:
* Power BI統合: Power BIへのデータセットやレポートの発行を自動化する専用タスクタイプをサポートしています。Unity Catalogで管理されるPower BIコネクションが利用されるため、データの一貫性も保たれます。
* dbt統合: dbt Coreプロジェクトの実行やdbtモデルの変換処理をLakeflow Jobsのワークフローに組み込んでオーケストレーションすることが可能です。
* Snowflake対応: Snowflake環境で実行されるジョブ(ストアドプロシージャやタスクなど)のオーケストレーションにも対応しており、Keynoteでは既に700社以上の顧客がLakeflow Jobsを利用してSnowflakeのジョブをオーケストレーションしていると述べられました。
* サーバーレス実行のサポート: ジョブの実行にサーバーレスコンピューティングを活用することで、インフラ管理のオーバーヘッドを削減し、迅速な起動と効率的なリソース利用を実現します。
* 任意のAPI呼び出し: サーバーレスノートブックとサーバーレスコンピューティングの能力を活用することで、Lakeflow Jobsを使ってあらゆるAPIエンドポイントを呼び出すタスクのオーケストレーションも可能になったそうです。
Lakeflow Jobsは、Databricksプラットフォーム内部のタスクだけでなく、外部のシステムやツールを含むワークフロー全体を統合的に管理・実行するハブとしての役割を強化している、という点がポイントですね。これにより、企業はエンドツーエンドの複雑なデータワークフロー全体をDatabricksから一元的に管理・監視できるようになり、運用管理のサイロ化を防ぎ、ワークフロー全体の可視性と信頼性を大幅に向上させることが可能になるでしょう。AWS、Azure、GCPの各クラウドプラットフォームで利用可能です。
公式ドキュメント: Lakeflow Jobs - Databricks Documentation Power BI task for jobs - Databricks Documentation
Lakeflow Designer データ活用のニーズがビジネス部門にも広がる中で、データパイプラインの構築には依然として高度な専門知識が必要とされ、データエンジニアのリソースがボトルネックとなるケースが多く見られますよね。Lakeflow Designerは、この課題を解決するため、プログラミングの知識がほとんどないユーザーでも直感的なビジュアルインターフェースを通じて本番環境グレードのETLパイプラインを構築できる、AI搭載のノーコード/ローコードパイプラインビルダーとして発表されました。これはData + AI Summit後まもなくPublic Previewが開始される予定です。
Lakeflow Designerの革新的な機能と特徴を重点的に見ていきましょう。
- ノーコード/ローコードETL開発: ドラッグ&ドロップ操作が可能なビジュアルユーザーインターフェース(UI)と、自然言語による指示を解釈するAIアシスタント機能を組み合わせることで、ユーザーはコードを書くことなくETLパイプラインを設計・構築できます。Excelや他のETLツールに親しんだビジネスユーザーにとっても直感的に操作できる設計になっている、という点が大きな魅力ですよね。
- ターゲットユーザー層の拡大: 主にデータアナリストやビジネスユーザーといった、必ずしも高度なプログラミングスキルを持たない非技術者や、コーディング経験の浅いユーザーを対象としています。これにより、データ準備やパイプライン構築の「民主化」を大きく前進させることを目指しています。
- Lakeflowプラットフォームとの完全統合: Lakeflow Designerで視覚的に作成されたパイプラインは、バックエンドでは通常のLakeflow Declarative Pipeline(Spark Declarative PipelineベースのSpark SQLコード)として実行されます。これにより、データエンジニアは生成されたSQLコードを確認・レビューしたり、必要に応じてカスタマイズしたりすることが可能です。アナリストが作成したパイプラインを手作業で書き直す必要がなくなるのは、非常に効率的ですよね。
- AIによる強力な支援機能:
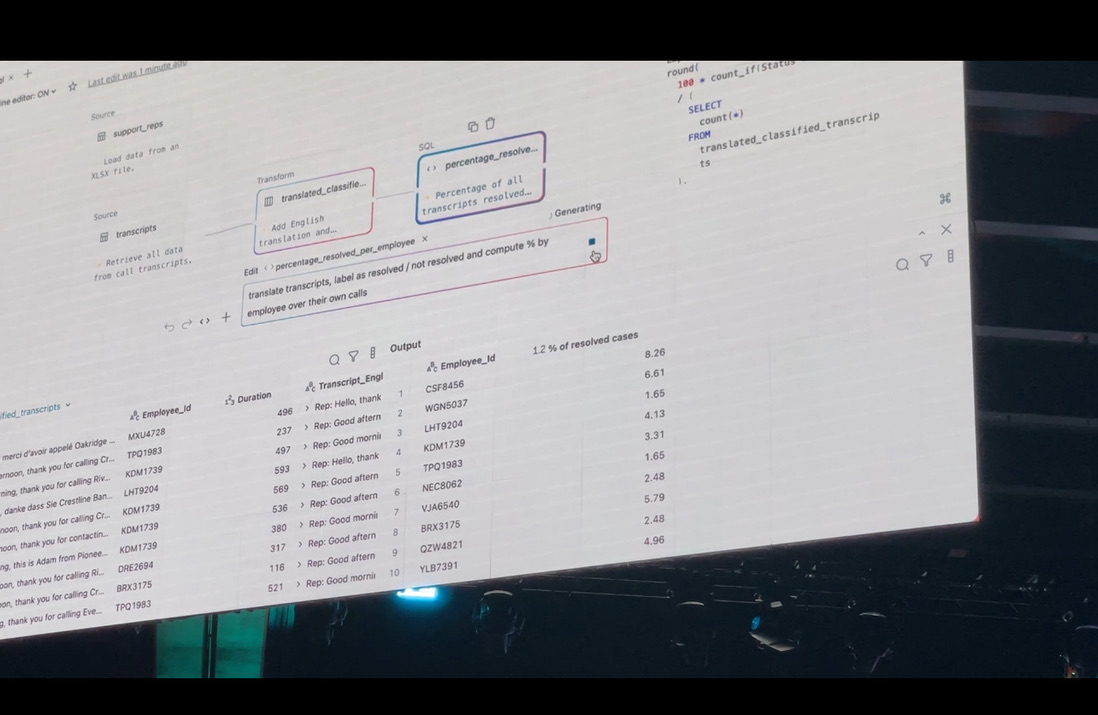
- 自然言語による変換指示: 「このカラムとあのカラムを結合して、結果をこうしてほしい」といった平易な英語の自然言語での指示に基づいて、AIが適切な変換処理を提案・生成します。
- Transform by Example: ユーザーが変換後のデータの期待される形式を、スプレッドシートのスクリーンショットのような具体的な「例」としてAIに示すことで、AIがその例から変換ロジックを推測し、データ変換処理を自動生成する画期的な機能です。
- AIによるデータ分類・翻訳: Keynoteのデモでは、コールセンターのトランスクリプトデータをAIが自動的に翻訳し、通話内容を「解決済み」「未解決」などに分類する様子が示されました。
- エラー防止とコンテキスト対応提案: Databricks Assistantとの統合により、自動エラー検出と修正、メタデータ、系譜、使用パターンを活用したコンテキスト対応の提案が可能です。
- コラボレーションの促進: データアナリストとデータエンジニアが、共有されたETLパイプラインの定義(ビジュアル表現とSQLコードの両方)を見ながら共同で作業を進めることが可能になります。
- エンタープライズグレードのガバナンスとスケーラビリティ: Lakeflow Designerは、基盤となるLakeflowエンジンの持つスケーラビリティ、信頼性、そしてUnity Catalogと連携した高度なガバナンス(アクセス制御、データリネージなど)といった利点をそのまま継承します。
Lakeflow Designerは、単なる簡易的なUIツールではなく、そのバックエンドでは堅牢かつスケーラブルなLakeflowエンジンが動作しているという点が非常に重要です。これにより、ビジネス部門の要求に対するアジリティ(俊敏性)を大幅に向上させるとともに、データエンジニアリングリソースのより効率的な活用を実現することが期待できます。
対応クラウドはAWS、Azure、GCP全てで利用可能となる予定です。
公式プレスリリース: Databricks Unveils Lakeflow Designer for Data Analysts to Build Reliable Pipelines Without Coding
DB SQL関連発表
LakeBridge 既存のレガシーデータウェアハウスからの移行は、多くの企業にとって時間とコストのかかる大きな課題ですよね。LakeBridgeは、企業が保有するレガシーデータウェアハウスシステムからDatabricks SQLおよびDatabricks Lakehouseプラットフォームへの移行を支援するために設計された、無料でオープンなAI対応マイグレーションツールとして発表されました。このツールには、Databricksが2025年2月に買収したBladeBridge社の高度な移行技術が統合されています。
LakeBridgeは、移行プロセス全体をカバーする包括的なエンドツーエンドのツールキットです。
 * 移行ライフサイクルのサポート: 既存環境の分析(Profiler、Analyzer)、SQLおよびETLコードの変換(Converter)、データの移行、そして移行後の検証(Validator)といった各フェーズを網羅的にサポートします。
* 移行ライフサイクルのサポート: 既存環境の分析(Profiler、Analyzer)、SQLおよびETLコードの変換(Converter)、データの移行、そして移行後の検証(Validator)といった各フェーズを網羅的にサポートします。
* 広範なソースシステムへの対応: Teradata、Snowflake、Oracle、SQL Server、Informatica、Amazon Redshift、Azure Synapse、Hiveなど、10種類以上の主要なレガシーデータウェアハウスやETLツールからの移行をサポートしています。
* 独自構文の変換: 各ベンダー独自のSQL方言(BTEQ、T-SQL、PL/SQLなど)やプロプライエタリなETLロジックを、Databricks SQL向けのANSI準拠SQLやApache Spark SQLに変換することで、特定のベンダーへのロックインを回避し、オープンなプラットフォームへのスムーズな移行を支援します。
特に注目すべきは、AIを活用した「Code Converter」です。
 * LLMベースの変換: 様々なレガシーソースの特性を学習し、特定の環境に応じたガイダンスも考慮して微調整された大規模言語モデル(LLM)を活用して、高度なコード変換を行います。
* LLMベースの変換: 様々なレガシーソースの特性を学習し、特定の環境に応じたガイダンスも考慮して微調整された大規模言語モデル(LLM)を活用して、高度なコード変換を行います。
* ビジネスロジック検証: 単なる構文変換に留まらず、変換前のレガシーコードからビジネスロジックを理解・抽出し、Databricks SQL用に生成された新しいコードのビジネスロジックと比較検証することで、意味的な一貫性を担保しようとします。不一致が検出された場合は、そのフィードバックをLLMのさらなる微調整に活用し、ループ処理によって精度を高めます。
* A/Bテストによる出力比較: レガシーシステムと新システムで同じ(または合成)データに対してクエリを実行した際の結果を比較検証し、出力に差異があればフィードバックして、両者の出力が一致するまでプロセスを繰り返します。
* 強化学習の導入計画: 将来的には、強化学習の技術をコードコンバーターに導入し、変換エンジン自体が過去の変換経験から学習し、時間とともに変換精度を自己進化させていく仕組みを目指しています。
LakeBridgeはDatabricksの顧客とパートナーに無料で提供されており、コア機能は既に一般提供開始(GA)されています。AIを活用した高度な変換機能は、現在「coming soon」または段階的に導入が進められている状況です。
公式ブログ: Introducing Lakebridge: Free, Open Data Migration to Databricks SQL Databricks Lakebridge | Fast, Predictable Migrations to Databricks
AI/BI関連発表
Databricksは、データとビジネスインテリジェンス(BI)の融合を「AI/BI」と称し、その領域に注力しています。Databricks上でのAI/BI機能の利用は急速に拡大しており、過去1年間でアクティブユーザー数が500%(すなわち6倍)に増加したと報告されました。DatabricksのAI/BI戦略は、「AIファースト」のアプローチによって差別化を図り、自然言語による対話型分析を実現するAIアシスタント「Genie」を中核に据えています。
Genie Deep Research Genie Deep Researchは、DatabricksのAIアシスタント「Genie」の機能を大幅に拡張する、非常に野心的な新機能です。従来のBIツールでは直接的な回答が難しかった「なぜ先月の売上が急増したのか?」「次の四半期のマーケティング戦略として、どの施策に注力すべきか?」といった、オープンエンドで複雑なリサーチクエスチョンに対応することを目指しています。
この機能の大きな特徴は、AIが自律的に調査計画を立案し、関連するデータを分析し、複数の仮説を検証し、最終的にその結論と根拠を要約して提示する点にあります。例えば、トレンド分析、売上構成要素の分析、顧客セグメント別の行動分析、ファネル効率の評価など、問いに答えるために必要となる複数の分析ステップをAIが計画し、並行して実行します。分析結果として得られた結論や提案だけでなく、その判断に至った根拠となるデータや分析ステップを引用情報として明確に提示することで、透明性と信頼性を確保してくれるのも安心ですよね。
Genie Deep Researchは、2025年夏にPublic Previewが開始される予定の、将来リリースされる機能とされています。これが実現すれば、従来はデータアナリストやビジネスコンサルタントといった専門家が多くの時間と労力を費やしてきた高度な分析業務の一部をAIが担うことになり、分析のスピードとスケーラビリティが飛躍的に向上する可能性を秘めていると言えるでしょう。
Unity Catalog Metrics (Unity Catalog Metricsの主な機能は前述の「Unity Catalog関連発表」セクションで詳しく解説しましたが、ここでは特にBIツールとの連携に焦点を当てて補足します。
Unity Catalog Metricsは、ビジネス上の重要な指標(メトリクス)をDatabricks Unity Catalog内で一元的に定義・管理できるセマンティックレイヤー機能として、2025年夏に6月に一般提供開始(GA)の予定ですとなりました。この機能の成功には、主要なBIツールとのシームレスな連携が不可欠ですよね。
Databricksは、Tableau、Sigma Computing、Hex、ThoughtSpot、Omni、Power BI、Lookerといった主要なBIツールや、Anomalo、Monte Carloといったデータオブザーバビリティツールとの連携を積極的に進めています。
特に注目すべきパートナーは以下の通りです。
- Sigma Computing: Databricksの「2025 Business Intelligence Partner of the Year」を受賞しており、Unity Catalog Metricsのサポートを公式に発表しています。これにより、SigmaユーザーはDatabricks上で一元管理された信頼性の高いメトリクス定義に基づいて、使い慣れたSigmaのインターフェースで分析を行うことが可能になりました。
- Tableau: Keynoteにおいて、Unity Catalog Metricsの連携パートナーとしてTableauの名前が挙げられました。Tableauのような広く普及しているBIツールからUnity Catalog Metricsを利用できるようになることで、多くの企業がDatabricks上で定義・管理された一貫性のあるメトリクスに基づいて、信頼性の高い分析やダッシュボード作成を行えるようになると期待されています。
- Monte Carlo: データオブザーバビリティプラットフォームであるMonte Carloも、Unity Catalog Metricsをサポートすることを発表しており、メトリクスの信頼性監視といった観点からの連携が期待されます。
Unity Catalog Metricsは、これまで各BIツール内や個別の分析スクリプト内にサイロ化しがちだったメトリクスの定義を、データプラットフォームレベルに引き上げることで、「信頼できる唯一の情報源(Single Source of Truth)」を実現しようとしています。これにより、組織全体でのデータ解釈の一貫性が向上し、部門間の認識の齟齬が減少し、より迅速で質の高いデータドリブンな意思決定が促進されることが期待されます。
公式ブログ: What's new in Databricks Unity Catalog - Data + AI Summit 2025 Monte Carlo Expands Databricks Partnership With Support For AI/BI And Unity Catalog
Genie Knowledge Extraction Genie Knowledge Extractionは、AIアシスタントGenieが、Databricksプラットフォーム内でのユーザーの利用状況や過去の対話、フィードバックを分析し、組織固有の知識や文脈(ナレッジ)を自動的に抽出・学習する機能です。この機能は現在AI/BI Genieのパブリックプレビューの一部として利用可能であり、継続的に改善が進められています。
主な技術的特徴は以下の通りです。
- 利用状況からの暗黙知抽出: プラットフォーム内でのデータの利用パターン、頻繁に実行されるクエリ、テーブル間の結合関係などから、スキーマ定義だけでは捉えきれない暗黙的な知識(例:特定のカラムがビジネス上どのような意味を持つか、特定のフィルター条件が慣習的に使われる理由など)を抽出します。
- ユーザーフィードバックによる学習ループ: Genieとの対話の中で、ユーザーがGenieの回答を「正しい」と確認したり、修正を加えたりすると、Genieはそのフィードバックを学習データとして取り込み、自身の知識を更新・洗練させます。
- 内部ナレッジストアへの蓄積: 学習によって獲得された知識は、Genieの内部ナレッジストアに構造化された形で蓄積され、将来の質問応答時に再利用されます。
- Unity Catalogへのナレッジ公開 (予定): Genieが学習・抽出したこれらのナレッジスニペットを、将来的にはUnity Catalog内のテーブルやビューに対する追加のメタデータとして公開する機能が追加される予定です。
企業のデータ活用においては、データベースのスキーマ定義だけでは表現しきれない、ビジネス特有の文脈、慣習、経験知といった「暗黙知」が、データの真の価値を引き出す上で決定的な役割を果たすことが少なくありません。Genie Knowledge Extractionは、AIがこれらの暗黙知を学習し、それを再利用可能な「形式知」へと転換することを可能にする、非常に重要な機能だと言えるでしょう。これにより、Genieは単なる自然言語インターフェースから、組織のデータとビジネスの機微を深く理解した真にインテリジェントなアシスタントへと進化します。さらに、学習した知識をUnity Catalogを通じて他のAIツールやユーザーと共有するという構想は、Databricksプラットフォーム全体のAI活用レベルを底上げし、組織全体のデータ理解度とAIの精度を向上させる大きな可能性を秘めています。
対応クラウドはAWS、Azure、GCP全てで利用可能です。
Databricks One 従来のDatabricksのインターフェースは、主にデータサイエンティストやデータエンジニアといった技術者向けに設計されていましたよね。しかし、データとAIの真の価値を組織全体で最大限に引き出すためには、ビジネスの最前線にいるユーザー自身が、専門家の手を介さずに、容易にデータにアクセスし、AIの力を活用できる環境が不可欠です。Databricks Oneは、この課題に応えるために、営業、マーケティング、財務、経営層といったビジネスユーザー向けに特別に設計された、Databricksプラットフォームの全く新しいエントリーポイントとなる体験として発表されました。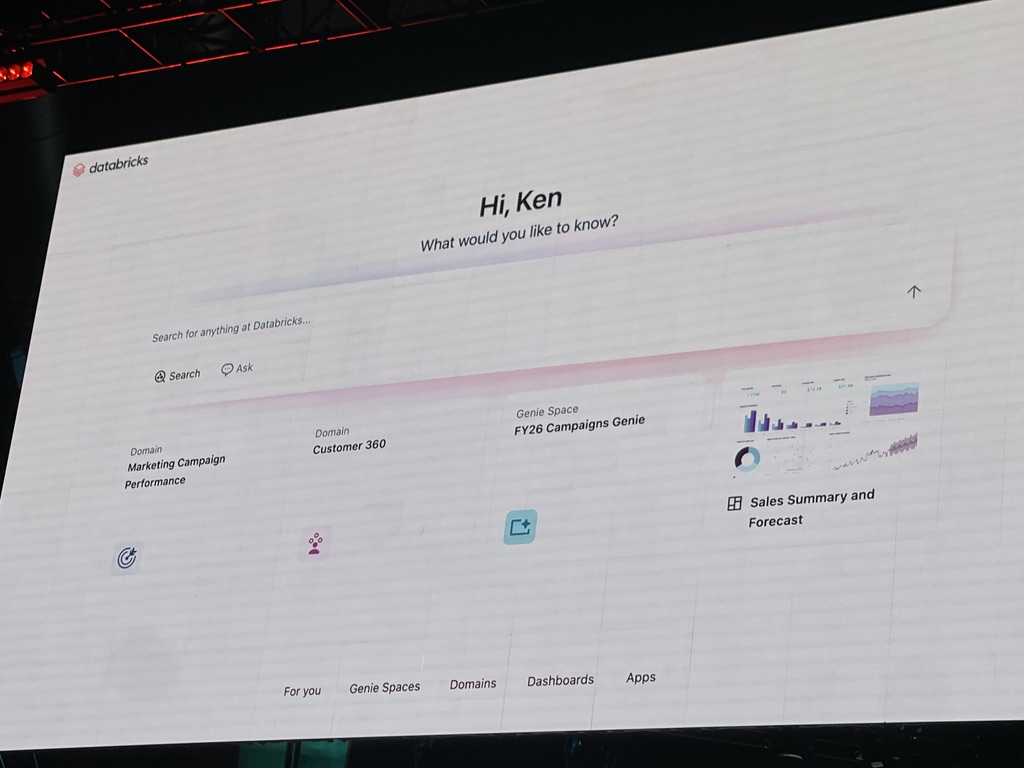
Databricks Oneの主な特徴は以下の通りです。
- ビジネスユーザー中心のUI/UX: データサイエンティストやエンジニアが慣れ親しんだ従来のDatabricksワークスペースとは明確に区別された、シンプルで直感的なユーザーインターフェースを提供します。検索ボックスから直接「Ask Genie」機能に切り替えて分析したい内容を質問できるなど、コードを書く必要のない環境が提供されます。
- 統合されたアクセスポイント: AI/BIダッシュボードの閲覧やインタラクション、AI/BI Genie(Deep Research機能を含む)への自然言語での質問、そして業務特化型のカスタムDatabricks Appsの利用といった、ビジネスユーザーが必要とする主要なデータ・AI機能へのシングルエントリーポイントとして機能します。
- 完全なコードフリー環境: ビジネスユーザーがプログラミングの知識なしに、データ探索、インサイト獲得、AI機能の利用を行えるように設計されています。
- Unity Catalogによる統一ガバナンス: Databricks Oneは、Databricks Data Intelligence Platformの基盤の上に構築されており、そのガバナンスモデルはUnity Catalogに基づいています。これにより、データのセキュリティ、アクセス制御、コンプライアンスが一元的に管理され、ビジネスユーザーでも安心してデータを利用できます。
- 容易なID管理とライセンス: Microsoft Entra ADやOktaといった既存のIDプロバイダーと直接統合され、管理者にとってユーザー追加が容易になります。また、シートベースのライセンス制限がなく、追加ライセンス料金も不要なため、組織内の誰でも新しいライセンス調達を気にすることなく利用できる、というのも大きな利点ですよね。
Databricks Oneは、2025年6月11日にPublic Previewが開始され、2025年夏後半にはパブリックベータ版として全ての顧客に提供開始される予定です。この取り組みが成功すれば、Databricksのユーザーベースを飛躍的に拡大させ、「Data Intelligence for All」というDatabricksのビジョンを具現化し、企業内におけるデータ活用文化の浸透とデジタルトランスフォーメーションを劇的に加速させる原動力となるでしょう。
Google関連発表
Databricksはマルチクラウド戦略を推進しており、主要なクラウドプロバイダーとの連携を強化しています。今回のサミットでは、特にGoogle Cloudとのパートナーシップの深化が注目されました。

Gemini(DatabricksにおけるGemini対応状況) 企業は、自社の貴重なデータを活用して、より高度なAIアプリケーション、特に生成AIを駆使したエージェントシステムなどを構築したいという強いニーズを持っていますよね。Googleの最先端大規模言語モデル(LLM)である「Gemini」モデル群を、Databricks Data Intelligence Platformにネイティブに統合するための戦略的製品パートナーシップが2025年6月12日に発表されました。
このパートナーシップのポイントを重点的に見ていきましょう。
- ネイティブ統合: Googleの最新Geminiモデル(高性能なGemini 2.5 Pro、軽量版のGemini 2.5 Flash、そして高度な推論を可能にする「Deep Think」モードを含む)が、Databricksプラットフォーム内でネイティブ製品として利用可能になります。これは、外部サービスとして呼び出すのではなく、Databricksのワークフローにシームレスに組み込める、という点が重要です。
- データ移動の不要性: 最大の利点の一つは、Databricks上に存在する企業の機密性の高いエンタープライズデータを、Geminiモデルを利用するために外部のGoogle Cloud環境に移動させる必要がないという点です。データはDatabricks環境内に留め置かれたまま、Geminiモデルによる処理を直接適用できるため、セキュリティ、コンプライアンス、データガバナンスの観点から非常にメリットが大きいと言えるでしょう。Unity Catalogによるエンドツーエンドのデータガバナンスも適用されるため、責任あるAIの利用とコンプライアンス遵守を支援します。
- 容易なアクセス方法: Databricksユーザーは、使い慣れたSQLクエリ(例えば
ai_query関数の拡張など)や、Databricksのモデルサービングエンドポイントを通じて、これらのGeminiモデルに容易にアクセスし、推論を実行できるようになります。 - インフラストラクチャ強化(GCP特化): Google Axion C4A VM(最大65%優れた価格パフォーマンス)やTitanium SSD(最大35%低いレイテンシの高性能ローカルストレージ)といった、Google Cloud Platform上のDatabricks環境に特化したインフラ強化も発表されました。
- マルチクラウド戦略の一環: Databricksは全てのクラウドで全てのモデルを自由に利用可能にすることを目指していますが、今回のGemini統合は特にGCP向けに設計されている、とのことです。
Databricksユーザーは、データ準備からモデル開発、AIエージェントの構築、そして本番環境での運用に至るまで、AIライフサイクルのほぼ全てのステージを単一のプラットフォーム上でシームレスに完結できるようになり、イノベーションのサイクルが大幅に加速することが期待されます。具体的な利用開始時期は「近く導入予定」とされています。
その他Keynote中のトピック
今回のKeynoteでは、上記主要サービス以外にも、Databricksの戦略と方向性を示すいくつかの重要なトピックが語られました。
- サンフランシスコへのコミットメント: サンフランシスコ市長のダニエル・ルリエ氏が登壇し、Databricksがサンフランシスコに本社を構え、数十億ドルの投資を行い、今後5年間にわたりAIサミットをサンフランシスコで開催し続けることを発表しました。これは、サンフランシスコがAI分野のイノベーションハブとして今後も重要であるというDatabricksの強い意思表明と言えるでしょう。
これらの発表からも、DatabricksがデータとAIのライフサイクル全体を網羅し、あらゆるスキルレベルのユーザーにその恩恵を届けようとしていることがよく分かりますね。
まとめ
Databricks Data + AI Summit 2025の2日目Keynoteでの発表は、DatabricksがデータとAIの分野において、オープン性、AIの民主化、そしてプラットフォームの統合という主要なテーマを力強く推進していることを明確に示していました。

* Spark 4.0やReal-time mode、Spark Declarative Pipelinesといったオープンソースへの貢献は、コミュニティ全体の技術力向上とエコシステムの拡大に寄与するものです。特にReal-time modeによる超低レイテンシ処理は、これまでのSparkの適用範囲を大きく広げる可能性を秘めていると感じました。
* Unity Catalogは、Iceberg Managed TableによるIcebergフォーマットのフルサポートや、Unity Catalog Metrics、Unity Catalog Discoverといった新機能により、単なるメタデータ管理ツールから、真のデータインテリジェンス基盤へと進化を遂げようとしています。データの一貫性と信頼性を確保しつつ、発見性を高めることで、ビジネスユーザーのデータ活用を促進する狙いが見えます。
* Lakeflow製品群(Connect、Declarative Pipelines、Jobs、そして特に注目すべきDesigner)は、データエンジニアリングのライフサイクル全体をカバーし、専門家からビジネスユーザーまで、あらゆるスキルレベルのユーザーが効率的にデータパイプラインを構築・運用できる環境を提供することを目指しています。Lakeflow Designerのノーコード/AI支援機能は、データパイプライン構築の「民主化」を大きく前進させる可能性を秘めているでしょう。
* DB SQLとLakeBridgeは、Lakehouseアーキテクチャの優位性をデータウェアハウジング市場に広げ、レガシーシステムからの移行をAIの力で加速させる、という非常に強力なメッセージを打ち出していましたね。
* そして、AI/BI、特にGenie Deep ResearchやDatabricks One、さらにはGoogle Geminiとのネイティブ統合は、AIの力を組織の隅々まで届け、真のデータドリブンな意思決定とイノベーションを促進するための強力な布石と言えるでしょう。ビジネスユーザーがコードを書かずにAI/BIを利用できるDatabricks Oneは、まさに「Data Intelligence for All」を具現化する存在と言えそうですね。
これらの新機能や戦略は、今後のデータとAIのトレンドに大きな影響を与える可能性があります。企業は、これらの新しいツールや機能を活用することで、データ活用のサイロ化を解消し、より迅速かつ柔軟にビジネス価値を創出できるようになることが期待されます。しかしながら、その一方で、これらの多岐にわたる新機能を効果的に導入・運用していくためには、それぞれの技術特性を深く理解し、自社の課題や目的に応じた適切なアーキテクチャ設計と人材育成が不可欠となるでしょう。今回の記事が、皆さんのデータとAIの旅の一助となれば幸いです。