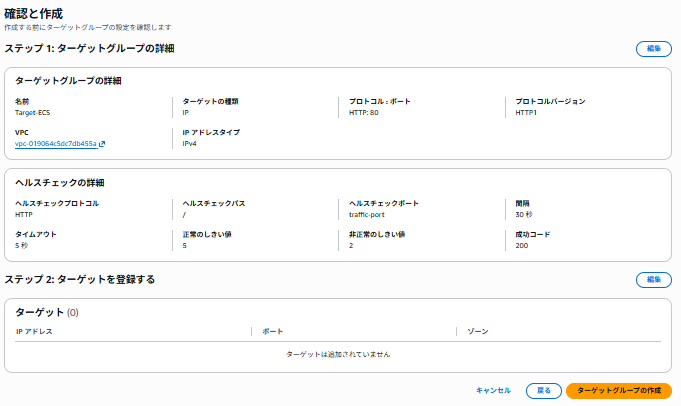
(画像はイベントサイトtopより)
目次
はじめに
こんにちは、クラウド事業部の坂口です。
去る2025年10月11日(土)に JAWS FESTA 2025 in 金沢 が開催され、幸いにも参加することができました!
今回はボランティアスタッフとして参加させていただけたので、スタッフとしての感想を中心につらつらとレポートを書いていこうと思います。
関連記事
弊社で、同じくボランティアスタッフとして参加された方のレポート記事はコチラ↓
techblog.ap-com.co.jp
イベントについて
JAWS FESTA とは
こちら のページより抜粋
JAWS-UGの活動は各支部が独立して運営しています。この各支部の勉強会とは別に年に2回、全国規模のイベントが開催されます。春のJAWS DAYS、秋のJAWS FESTAです。
JAWS DAYSは毎年東京で行われ、秋のJAWS FESTAは東京以外の地方で行われます。JAWS FESTAは、広島(2024)、福岡(2023、2015)、北海道(2019)、大阪(2018,2013)、愛媛(2017)、愛知(2016)、宮城(2014) で開催されました。今年のJAWS FESTAの会場は金沢となり、北陸地方では初の開催となります。
全国各地で活動している各支部のリーダーが集まり、オフラインによるネットワーキングを「再構築」し、お互いに刺激を受けあい、また地元に帰って活動する、というリズムを作り出しています。
JAWS FESTA 2025 in 金沢
そんな JAWS FESTA ですが、今年 (2025) は金沢(石川県金沢市)で開催されました!
JAWS FESTA 2025 in 金沢 のイベントサイトはこちらになります。
jawsfesta2024.jaws-ug.jp
本題には全く関係ない小話
何を隠そう、筆者は金沢市にそこそこ縁があります。
なので、今回のJAWS FESTA画像にある文言について完全自己満足で説明しようと思います。
※なお、あえて何も調べず書いているため、事実と異なる部分がある場合はすみません
『やっとるげん』
取り上げるのはコチラ 『秋の金沢 AWS やっとるげん 』
『やっとるげん』という箇所がいわゆる金沢弁で、『秋の金沢 AWS やっています 』というような意味になります。
単純にそれだけの意味ではあるのですが、会話の中だとあまりうまく認識してもらえず聞き返されることがあります。少なくとも筆者はありました。
『せんがん』
またその他の金沢弁として『勉強せんがん』→『勉強しないのか』というものもあります。
動詞を変えて『JAWS FESTA 行かんがん』→『JAWS FESTA 行かないのか』というように使います。
ちなみに、この金沢弁についても北海道札幌の地で聞き返されたことがあります。
筆者が不注意で使ってしまったので仕方ない部分はありますが、
『潤かす』や『押ささる』を筆頭に、なまらなまら言って突撃してくる札幌の方に不思議な顔をされたので記憶に残っています。
『ねーじ』
加えて、『〇〇 ねーじ』という金沢弁もあります。
こちらは『PC ねーじ』→『PC が無いじゃないか』という使われ方をし、金沢弁の例文として『ネジ ねーじ』という人類みな全てが笑う文が頻出します(世界平和)。
※ネジは、そのままプラスとかマイナスとかのネジです
金沢の民へ
という訳で、簡単な金沢弁の説明でした。
これで読者の方は金沢の民なので、引き続きよろしくお願いします。
本題
会場に関して
今回、会場は2か所。
会場が2か所になった理由としては、主要な駅(金沢駅)から近い場所での開催であるため、1つの会場では300人近い参加者をまかなえなかったのかと推察します。
実際に 2023(九州)JAWS FESTA 2023 KYUSHU , 2024(広島)JAWS FESTA 2024 in 広島 での開催時は、若干郊外にある大学講堂等を借りていました。
とはいえ、金沢駅から近場だったことと、各会場間が遠かったということも無く、個人的には移動が気分転換も兼ねた形になったので悪くなかったです。
ボランティアスタッフの流れ (~前日)
さて、冒頭でも記載した通り、今回はボランティアスタッフとして参加しました。
過去のJAWS FESTAでもボランティアスタッフとして参加したことはあったのですが、今後、同様にボランティアスタッフとして参加されるかもしれない方に向けて今回経験した流れだけ簡単に記載しておきます。
※念のためで、一部は画像を使わずテキストのみでの説明となります
①ボランティアスタッフへの申し込み ボランティアスタッフには、基本的にJAWS FESTAのイベント本ページに申し込みの案内が出されます。
今回は以下のようなページでした。
ページ下部の「応募フォーム」から必要事項を入力して申し込みができます。
募集の案内自体は X(旧Twitter) でもされていました!
なお、JAWS FESTA本編への参加申し込みとは別 になります。
JAWS FESTA本編の参加申し込みは例年 Doorkeeper (2025のページ: JAWS FESTA 2025 in Kanazawa - JAWS-UG | Doorkeeper ) でされており、ボランティアスタッフ募集よりも早いタイミングで公開されます。
事前に本編への申し込みをしておきましょう。ただし一般の参加枠含め埋まるのがかなり早いため、その点は注意です。
②ボランティアスタッフの受け付け ボランティアスタッフとして申し込みを行うと、JAWS-UG の Slackワークスペース (もしくはX(旧Twitter)) で 実行委員 の方から連絡がきます。
なおスタッフとしてのやり取りや共有なども Slack で行われるため、申し込みの段階でワークスペースに参加しておくのが良いと思います。
実行委員の方から連絡を受け、問題なくボランティアスタッフとして参加できるようであればSlackのスタッフ用チャンネルに追加いただけるので、以降はこのチャンネルでやり取りを行います。
またJAWS-UGのSlackワークスペースでは一般のJAWS-UGイベントの告知などもされるため、ボランティアスタッフ参加に関わらずワークスペースに参加しておいてあまり損はないかなと思います。
③ボランティアスタッフとしての役割確認 Slackのスタッフ用チャンネルに参加後、開催が近くなるとボランティアスタッフとしての役割・シフト表やスタッフのガイドを共有いただけます。
このタイミングで、当日ボランティアスタッフとして何をするかの役割分担が分かります。
また、ボランティアスタッフに向けての説明&質問会も別途実施をいただけます。会の実施はいくつか候補日があるので、都合の良いタイミングで参加しましょう。
役割・シフト表やガイドは適宜アップデートが入ることもあり、当日手元で見られるようにしておくと便利でした。
基本的にはこの説明&質問会を経て、当日を迎えることになります。
(個人としての)④開催前日 ※前日までのボランティアスタッフの流れとしては ③ボランティアスタッフとしての役割確認 で完了していますが、ここからは少しだけ補足として書いていきます。
今回はスタッフの会場集合時間が8時台だったこともあり、私は前日入りをしました。
ただ、お仕事の都合で当日朝に金沢に現地入りされる方も当然いらっしゃいましたが、実行委員の方に到着時間等は配慮いただけているようでした。なので (しんどくなければ) どちらでも良さそうかな、という感想です。
また、自身は用事があったため参加できませんでしたが、前日入りして時間がある方に向けて前日準備の依頼なんかもありました。
交流の時間が持てるので、似た機会があれば参加してみて良いかもしれません。
ボランティアスタッフの流れ (当日)
いよいよ当日です。
以降はボランティアスタッフとして私が担当した役割の動きをざっくりと書いていきます。
ちなみに、役割としては「受付(懇親会) 」でした。
①会場への集合、参加のチェックイン 前述の通り、当日朝8時台に会場の1つである ITビジネスプラザ武蔵 に集合。
見知った顔の方と挨拶をしたりして時間をつぶします。
時間になったら受付の設営フロアへ。
配布用Tシャツやトートバック、トランシーバーなんかが並べられています。
Tシャツは紫色がボランティアスタッフ用、黒色が実行委員用とのこと。
まずは受付担当が割り振られている方からDoorkeeperでのチェックインを済ませます。
チェックイン後は、自分用のトートバッグとスタッフTシャツを受け取りました。モノはこんな感じ。
②受付対応の説明、受付開始 ストラップへの名前記入やスタッフTシャツに着替えた後は、荷物を置いて受付対応の説明を受けることに。
なお会場にはスタッフ用の荷物置き場もあり、大変助かりました!
先述の通り、今回の役割としては懇親会受付で、こんな感じのテーブルで受付を行います。
懇親会受付の対応内容としてはこんな感じでした。
懇親会参加を申し込んだ方に、Doorkeeperのチェックインを実施
貸与のスマートフォンで、DoorkeeperチェックインアプリでQRコードを読み込む感じでした
QRコードでのチェックインを完了した方の、プラスチックホルダーやネームプレートにチェックイン完了のシールを貼る
チェックイン完了のシールを貼った方に、同様に "お酒飲めます" シールを貼る
写真撮影がNGの方へのネックストラップ配布
SNS等で写真がアップされることもあり、そういった写り込みを避けたい方向け
(右上から順に、チェックイン用スマートフォン・シール2種・ネックストラップ)
配置についた後はスタッフの方のチェックイン対応をしつつ、スタッフの朝礼に参加。
その後、イベント開場時間になると参加者の方が見え始めました。
懇親会参加しない方には基本的に対応不要であったものの、大まかに4つの対応があるため(写真を撮る暇があまり無いぐらいには)そこそこ忙しかったです。
③受付会場の移動、引き続き受付 最初に受付していた会場は午前中までで、午後からは受付場所を移動して更に受付対応を継続。
移動後の受け付け会場はサポーター企業ブースがあるフロアのエレベーター前で、午前中に比べるとかなりコンパクトになりこんな感じ。
なお余談ですが、幕の移動はエレベーターを使っていたものの高さがギリギリで大変そうでした。
また午後からの受付は特にシフト等はなく有志が実施する感じでした。
私はとりあえずで残って対応していた時間が多かったですが、主に以下の理由で忙しいタイミングもそれなりにあった印象です。
午後から来場する方がそこそこいらっしゃった
分からないことがあると受付でとりあえず聞いてみる方が多かった
懇親会に限らず受付全般の対応となった
イベント本編のDoorkeeperチェックイン、Tシャツ・トートバックの配布など
とはいえ、同じスタッフが常に受付にいたわけではなく、聴きたいセッションのタイミングやお昼休憩で適宜交代して対応をしていました。
※私自身も、セッションを聴きに行ったり、休憩を取ったりできました
④イベントの終盤、片付けなど 午後からの受付対応は実施しつつ、イベントの終盤では徐々に撤収の対応もお手伝いしていました。
こちらも私含めて手が空いている方が有志でお手伝いしていた感じです。
途中、余ったお菓子の配布なんかもしていました。
とりあえずで閉幕挨拶中も片付けをしていましたが、人が少なかったこともあり寂しげな雰囲気で楽しかったです。
(閉幕中のサポーター企業ブースの様子: 顔が写ってしまっていたので一部黒塗りしています)
閉幕後は、会場を後にする方をエレベーター前で見送ってボランティアスタッフも適宜撤収となりました。
感想
今回は縁のある石川県金沢市での開催ということで、個人的には若干テンションが上がっていました。
イベントでの受付スタッフは初めてだったものの、交流が多く持てて楽しかったです。
JAWS FESTAは年々内容がアップデートされていることもあり、毎年違った発見や楽しさに驚かされます。
来年以降も、何かしらの形で関われれば良いなと思いました。
なんだかんだ終了後には参加して良かったと思えるのは凄い。ありがとうございました!
お知らせ
私達クラウド事業部はクラウド技術を活用したSI/SESのご支援をしております。
www.ap-com.co.jp
https://www.ap-com.co.jp/service/utilize-aws/
また、一緒に働いていただける仲間も募集中です!
www.ap-com.co.jp
本記事の投稿者: さかぐち