
はじめに
こんにちは、ACS 事業部の平井です。
2025 年 7 月 16 日、17 日に開催された KubeCon & CloudNativeCon Japan 2025 に参加してきました。 events.linuxfoundation.org
今回はKubeConで気になったセッションをいくつかピックアップして紹介していきます。
キーノートセッションのまとめブログも別途出しておりますので、よろしければそちらもご覧ください。
- 【KubeCon Japan 2025】キーノートセッションを振り返る_Day1 - APC 技術ブログ
- 【KubeCon Japan 2025】キーノートセッションを振り返る_Day2 - APC 技術ブログ
2-Node Kubernetes: A Reliable and Compatible Solution - Xin Zhang & Guang Hu, Microsoft
セッションでは、2ノードのコントロールプレーンでも高可用性を実現するアーキテクチャが紹介されました。
https://kccncjpn2025.sched.com/event/1x716kccncjpn2025.sched.com
Kubernetesで通常「コントロールプレーンは最低3台必要」とされるのは、etcdがRaftアルゴリズムで過半数(3台中2台=2/3)を維持することでデータ整合性を保つためでであり、2台構成だとどちらかが落ちた時点で1/2のクォーラム割れを起こし、クラスタ全体が停止してしまいます。
そのため多くの企業において、レガシーな2台構成(アクティブ/パッシブ)からのkubernete移行という物理的に2台しか用意できない環境では可用性を確保することができませんでした。
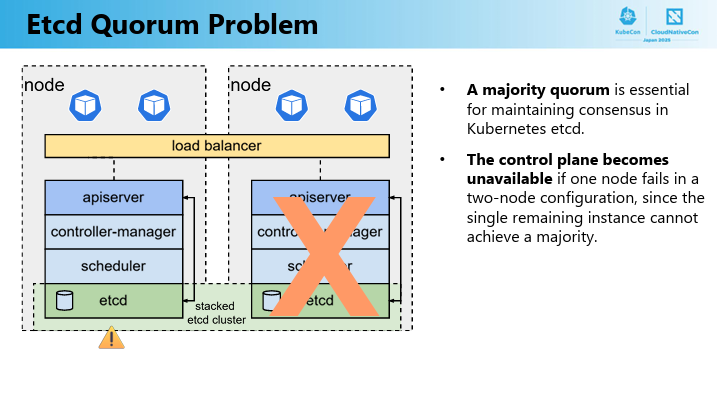
そこで物理的・コスト的制約で2台しか用意できないケースでもKubernetesの高可用性を実現する画期的なアプローチが「Witnessストレージ」と「拡張Raftアルゴリズム」を組み合わせた2ノードKubernetesだそうです。
Witnessストレージ
軽量な「第三の投票者」として機能し、片方のノードがダウンしても残りのノードとWitnessでクォーラムを維持します。デモではルーターに接続されたUSBドライブが使用されましたが、NFS/SMB共有やクラウドストレージも選択可能であり、必要な容量はわずか数キロバイトで、速度やサイズはほとんど影響しないようです。
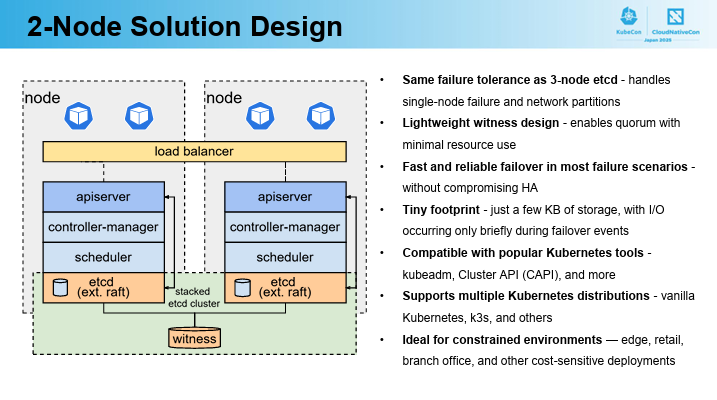
拡張Raftアルゴリズム
Kubernetesのデータストアであるetcdに、このアルゴリズムが組み込まれています。etcdのコアAPIは変更されておらず、KubernetesのAPIサーバーなどのコンポーネントは変更なしで動作し、クラスターはノード障害やネットワーク分断に耐え、データの一貫性を維持できるようです。
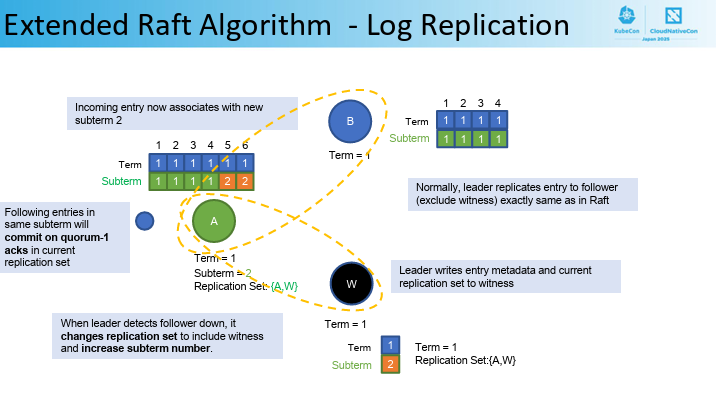
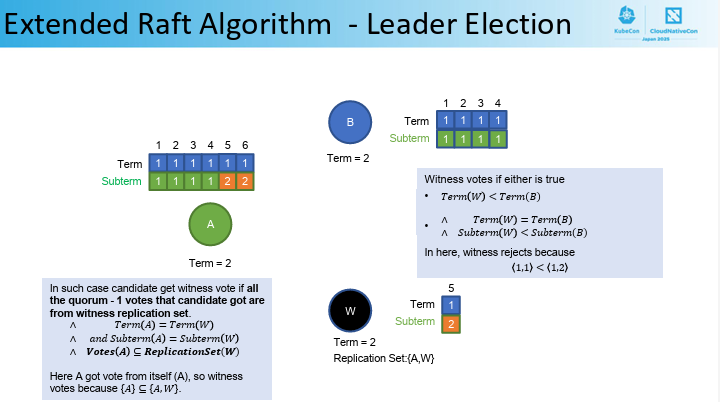
実機デモでは、2台構成のコントロールプレーンのうち一方の電源を抜いてもサービスに影響は一切なく、ダウンしたノード上のPodは瞬時に残るノードへ再配置され、ユーザー視点では従来の3ノード運用とまったく同じUXを体感できました。
公式機能として実装されれば、エッジ環境やコスト制約下の環境での Kubernetes 導入ニーズに応え、普及が一層加速しそうな、とても有意義なセッションでした。
Multi Cluster Magics With Argo CD and Cluster Inventory or Don't Get Lost in the Cl... Kaslin Fields
セッションでは、Kubernetesにおけるマルチクラスター管理の課題と、その解決策としてのMulticluster Orchestrator(MCO)の役割について紹介されました。
https://kccncjpn2025.sched.com/event/1x71Fkccncjpn2025.sched.com
はじめに複数のKubernetesクラスター間でのワークロード管理とリソース最適化を目的としてSIG Multiclusterが標準化を推進しているAPIについての説明がありました。
Multicluster Services (MCS) API
複数のクラスター間でのサービスアクセスを、単一クラスター内と同じくらい簡単にすることが目的。
ServiceExport、ServiceImport、ClusterSetといったオブジェクトを定義。

ClusterProfiles API
Cluster Inventoryの概念を導入し、ClusterProfileオブジェクト(CRDとして実装)によって、各クラスターのKubernetesバージョン、場所、GPUの有無などを記述可能。
MCS APIのClusterSetと組み合わせて、ワークロードをデプロイできるクラスターのグループを定義することが可能。

上記のAPIをサポートし、複数のKubernetesクラスター間でのワークロード管理とリソース最適化を簡素化する目的でGoogleが開発したものが、Multicluster Orchestrator(MCO)オープンソースプロジェクトだそうです。

MCOではHub Clusterという概念を導入し、MCS APIやClusterProfiles APIといったCRDが実行される管理の中核となり、 Argo CDなどのClusterProfileコンシューマーは、このHub Clusterを信頼できる情報源として利用し、ClusterSetにグループ化されたClusterProfileに基づいて複数クラスターにデプロイを行うそうです。
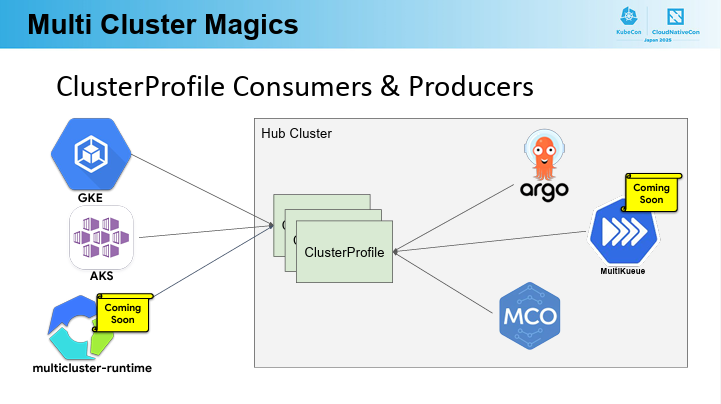
MCOのような具体的な実装を通じて、複雑なマルチクラスター環境の運用が「Kubernetes for Clusters」として統一的かつ魔法のように簡素化される未来への道筋が示されたセッションでした。
おわりに
初の日本開催となるKubeCon + CloudNativeCon Japan 2025、自分にとって日本初開催かつ初めての大規模技術イベントでしたが、各セッションのクオリティは圧巻で、最新のトレンドや実践的なノウハウを存分に吸収できました。
普段の業務では触れる機会のない大規模のクラスター運用事例や、軽量化・可観測性向上のための具体的なTipsを学べたことは大きな収穫でした。
また、技術を“使う側”にとどまらず、コミュニティへの貢献にも挑戦したいと思います。
来年も KubeCon + CloudNativeCon Japan 2026 が開催されるとのことなので、また参加できるよう英語力も鍛えていきたいと思います。
ACS事業部のご紹介
最後にご紹介です。
私の所属するACS事業部では、開発者ポータルBackstage、Azure AI Serviceなどを活用し、Platform Engineering+AIの推進・内製化のご支援をしております。
www.ap-com.co.jp www.ap-com.co.jp
また、一緒に働いていただける仲間も募集中です!
我々の事業部のCultureDeckはこちらです。
今年もまだまだ組織規模拡大中なので、ご興味持っていただけましたらぜひお声がけください。 www.ap-com.co.jp