
企業のデータ資産の大部分が、実は活用しきれていない「非構造化データ」に眠っていると言われています。PDF、画像、スキャンされた文書といったフォーマットに閉じ込められたこれらのデータは、従来のBIやアナリティクス、AIのワークフローに組み込むことが困難でした。
本記事では、Databricksが開催したセッション「Intelligent Document Processing: Building AI, BI, and Analytics Systems on Unstructured Data」の内容を基に、この課題を解決する最新のアプローチを解説します。講演を担当したのは、DatabricksのAdam氏とJason氏。彼らが示したのは、データエンジニアリングからAIアプリケーションの構築までを単一のプラットフォームで完結させる、強力かつシンプルなソリューションです。
エンジニア「Alex」の苦悩:非構造化データ処理の現実
講演は、架空の航空会社「BrickAir」で働くエンジニア「Alex」のストーリーから始まりました。彼女の課題は、多くのデータ専門家にとって他人事ではないでしょう。
Alexは、航空機のメンテナンス記録が大量に保存されたPDFを分析するプロジェクトを担当していました。当初は順調に見えましたが、プロジェクトが進行するにつれて次々と壁にぶつかります。
- データソースの分散: データはSharePointだけでなく、Amazon S3やGoogle Driveにも散在。新しいドキュメントは毎日追加されます。
- 脆弱なパイプライン: ソースごとにカスタムのデータ取り込みパイプラインを構築する必要があり、そのコードは複雑で壊れやすく、メンテナンスに膨大な時間を要します。
- 運用負荷の増大: サードパーティAPIの仕様変更や予期せぬファイルの破損など、パイプラインは頻繁に停止。Alexは常に障害対応に追われます。
- ビジネス要求の加速: 経営層からは、社内チャットボットやAI検索、AIを活用したダッシュボードなど、多様なアウトプットを求められますが、既存のプロセスでは追いつけません。
このAlexの物語は、従来の非構造化データ処理が抱える「高い運用オーバーヘッド」「複雑な文書解析の困難さ」「本番環境への展開の遅さ」という3つの根深い問題を象徴しています。
IDPの進化とDatabricks Lakehouseが示す道
セッションでは、非構造化文書から情報を抽出し、分析に適した形に変換するIDP(Intelligent Document Processing)のアプローチが紹介されました。近年、生成AIや大規模言語モデル(LLM)の進化により、手書き文字や複雑な表を含む文書への対応精度が飛躍的に向上しています。
Databricksは、このIDPアプローチをLakehouseアーキテクチャ上でシームレスに実現するための統合データインテリジェンスプラットフォームとして「Lakeflow」を提唱しています。Lakeflowは、これまで分断されがちだったデータ取り込み、変換、オーケストレーションを一つの流れに統合し、AIの力を組み合わせることで、Alexが直面したような課題を根本から解決しようとしています。
Databricks Lakeflowによるソリューションの全体像
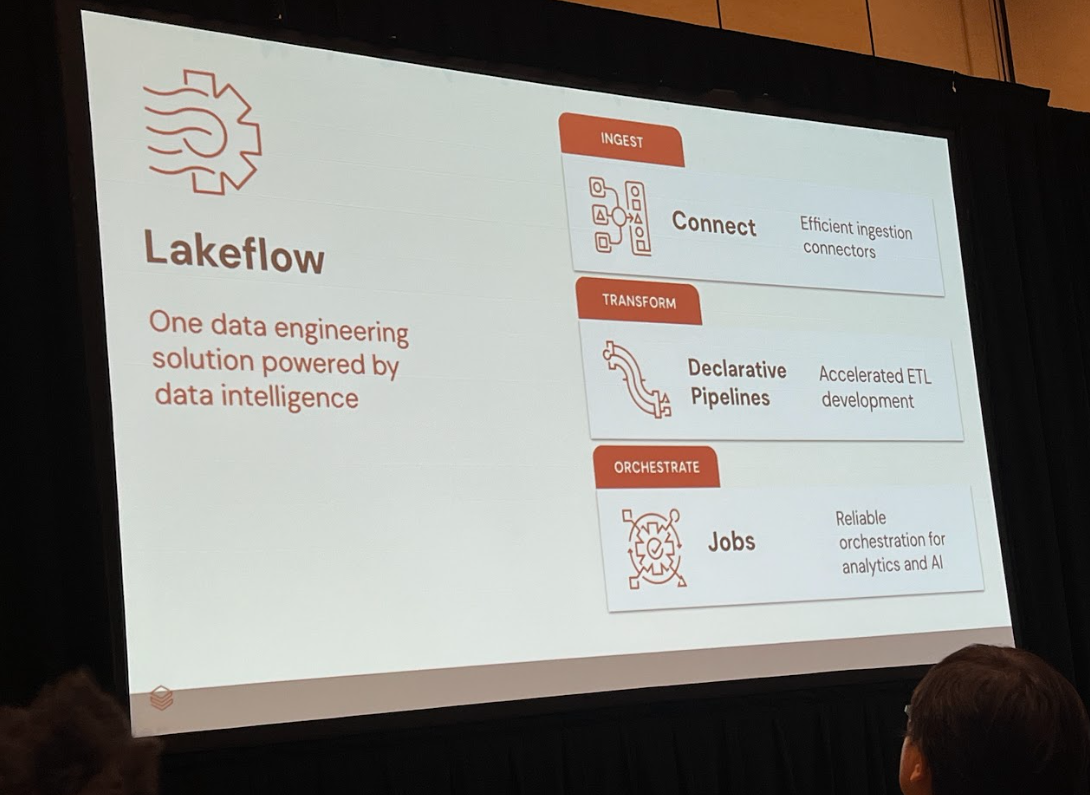
Lakeflowは、データエンジニアリングのワークフローをシンプルかつ強力に支援する複数のコンポーネントで構成されています。講演で紹介された主要な機能を順に見ていきましょう。
Lakeflow Connect:マルチソースからの自動データ取り込み

最初のステップは、散在するデータを取り込むことです。Lakeflow Connectは、SharePoint、Amazon S3、Google Driveといった多様なソースへのネイティブコネクタを提供します。これにより、エンジニアは数クリックの簡単な設定だけで、データ取り込みパイプラインを構築できます。
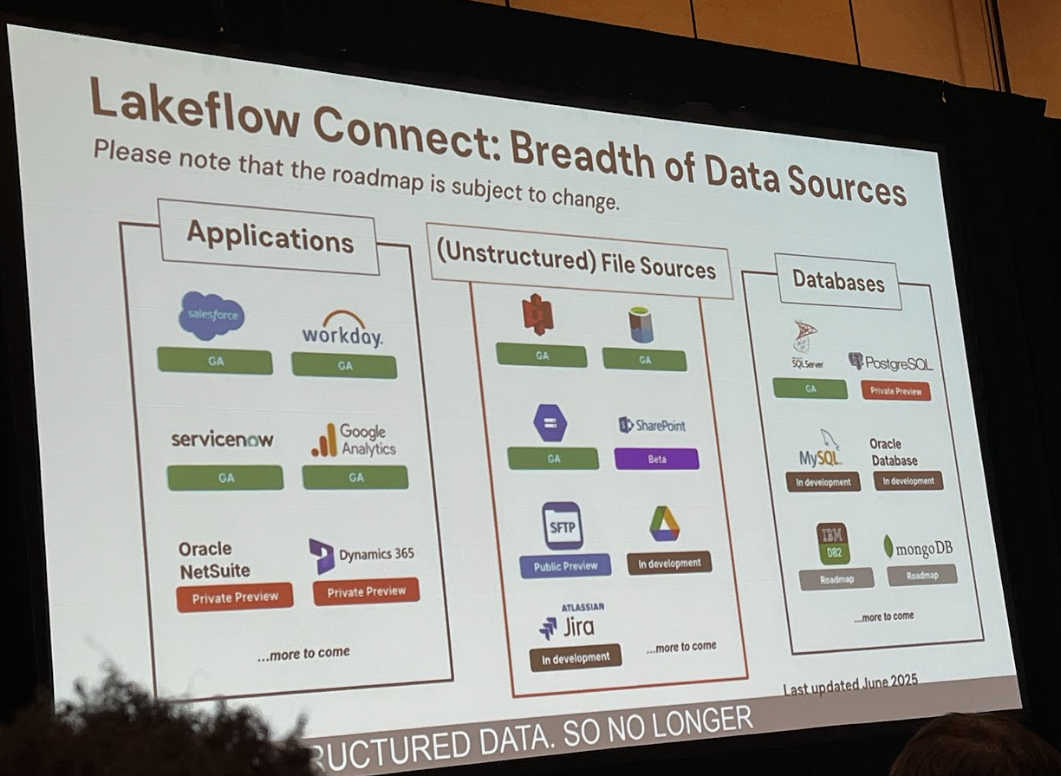
この機能の強力な点は、単にデータをコピーするだけではないことです。スキーマの変更自動検知、データリネージの追跡、エラー発生時の自動リトライといった運用に関わる面倒な作業をDatabricksプラットフォームが肩代わりしてくれます。Alexが苦労したカスタムパイプラインの構築とメンテナンス作業は、もはや不要になるのです。
AI Parse Document:文書構造の解析と変換
データがLakehouseに取り込まれたら、次はその中身を理解する番です。ここで登場するのが、新しいAI関数AI_PARSE_DOCUMENTです。この関数は、Deltaテーブルにバイナリ形式で保存されたPDFファイルを直接解析し、構造化された情報に変換します。
SQLライクなシンプルな呼び出しで、PDF内のテキストはもちろん、複雑なテーブル構造や手書き文字まで認識し、Markdown形式のテキストや推論されたスキーマ情報として出力します。複数のツールを組み合わせる必要なく、単一の関数で高度な文書解析が完結します。
AI Extract & カスタムAIエージェント:重要情報の自動抽出
文書の構造が理解できたら、次はビジネス上重要な情報をピンポイントで抽出します。AI_EXTRACT関数は、抽出したい情報のキー(例:「メンテナンス日」「技術者名」)を定義するだけで、AIが自動的に該当する値をテキストから抜き出してくれます。
しかし、汎用的なモデルでは精度が不十分な場合もあります。そこでDatabricksは、抽出精度をさらに高めるための「カスタムAIエージェント」機能を用意しました。これは、プロンプトや期待する出力スキーマを微調整し、特定のドキュメント形式や業務要件に合わせたエージェントをローコードで開発できる機能です。このフィードバックループにより、実用的なレベルまで精度を継続的に改善できます。
Lakeflow Declarative Pipelines & Jobs:ワークフロー自動化
ここまでの処理を、信頼性の高い自動化されたワークフローとしてまとめるのがLakeflow Declarative PipelinesとLakeflow Jobsです。
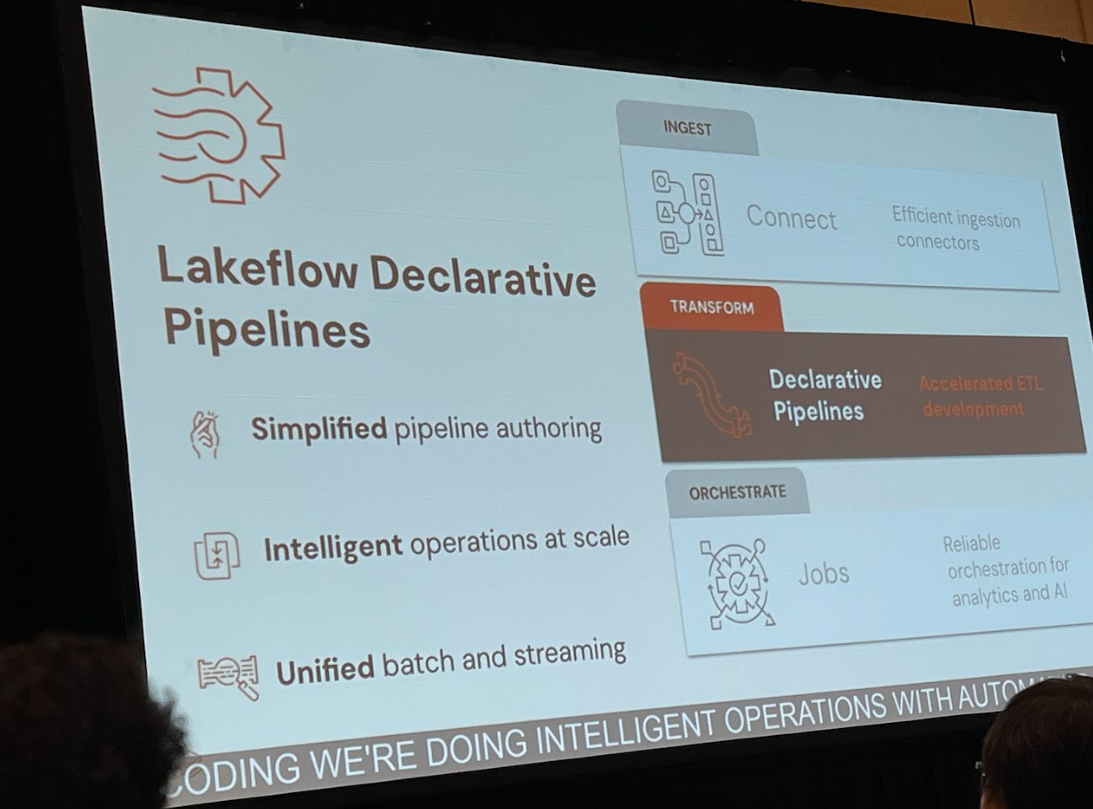
Declarative Pipelinesでは、一連のデータ変換処理(Parse、Extractなど)をSQLやPythonで宣言的に記述します。すると、Lakeflowが自動的に処理の依存関係を解析し、最適な実行計画を立ててくれます。特に重要なのが、インクリメンタル処理(差分処理)です。新しいファイルが追加された場合、パイプラインは全てのデータを再処理するのではなく、新規追加分のみを効率的に処理します。これにより、AIモデルの実行コストを大幅に削減できます。

最後にLakeflow Jobsを使い、データ取り込みからパイプラインの実行、そして最終的なBIダッシュボードの更新まで、エンドツーエンドのワークフロー全体をオーケストレーションします。日次での定期実行や、障害発生時の通知設定も簡単に行えます。
エンドツーエンドデモ:航空機メンテナンス記録の自動処理

講演のデモでは、これらの機能を組み合わせ、BrickAir社の航空機メンテナンス記録(手書きを含むPDF)を処理するプロセスが実演されました。
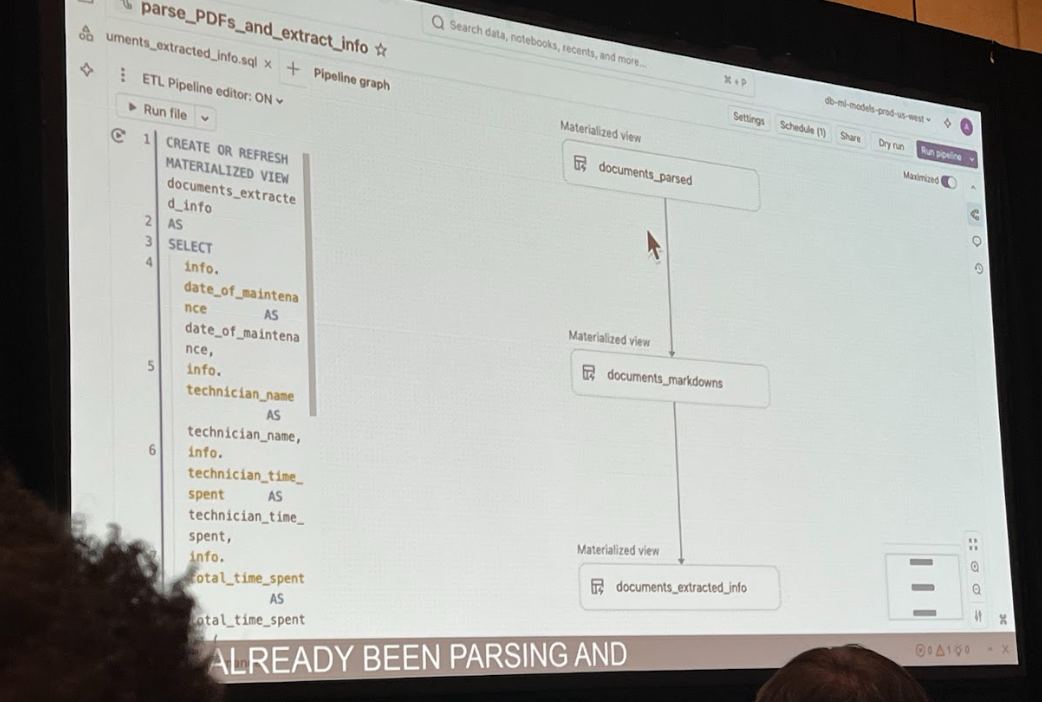
データ取り込みから構造化変換・抽出まで

まず、Lakeflow Connectを使ってSharePointサイトを指定し、メンテナンス記録のPDFファイルをDeltaテーブルにストリーミングで取り込みます。
次に、このテーブルに対して以下のようなSQLクエリを実行するパイプラインを定義しました。
- 文書解析 (
AI_PARSE_DOCUMENT):
PDFのバイナリデータからテキストやテーブル情報を抽出し、Markdown形式で新しいカラムに保存します。 - 情報抽出 (
AI_EXTRACT):
抽出したMarkdownテキストから、「date_of_maintenance」「technician_name」「technician_time_spent」といったキー情報を抽出します。
この2ステップだけで、PDFの山は構造化された貴重なデータテーブルへと姿を変えました。
パイプライン設定とダッシュボード更新
この一連の処理はDeclarative Pipelineとして保存され、グラフとして可視化されます。これにより、データの流れと依存関係が一目瞭然になります。
しかし、デモではAI_EXTRACTの結果に一部nullが含まれていました。これは、モデルが情報を確信を持って抽出できなかったことを示します。ここで「カスタムAIエージェント」の出番です。
開発者はエージェントのUI上で、抽出したい情報のデータ型(例:整数ではなく数値)を修正したり、「この値は日付の後に来る2番目の数字だ」といったヒントをプロンプトに追加したりしました。この簡単な調整だけでエージェントの精度は向上し、nullだった値も正しく抽出できるようになりました。
最後に、パイプラインのAI_EXTRACT関数を、この新しく作成したカスタムエージェントを呼び出すAI_QUERY関数に置き換えます。このパイプラインをJobsで定期実行するように設定すれば、SharePointに新しいメンテナンス記録が追加されるたびに、自動でデータが処理され、技術者の作業時間を分析するBIダッシュボードが常に最新の状態に保たれる、という仕組みが完成しました。
導入メリットとROIの考察
Databricksが示したこのアプローチは、企業に大きな価値をもたらします。
- 運用工数・開発期間の削減: Alexが数週間を費やしたパイプライン構築とメンテナンス作業は、数時間で完了しました。手作業のコーディングが大幅に削減され、運用はプラットフォームに任せられます。
- パイプラインの信頼性向上: 宣言的なパイプラインとインクリメンタル処理により、ワークフローは効率的かつ安定的に稼働します。
- ビジネス価値の最大化: これまで活用が難しかった非構造化データを迅速にインサイトに変え、RAG(Retrieval-Augmented Generation)を用いたチャットボットや高度なBIダッシュボードなど、具体的なビジネス成果へと直結させることが可能になります。
今後の展望:さらなる進化へ
Databricksの挑戦はまだ続きます。講演では、今後のロードマップとして以下の機能強化が挙げられました。
- 対応フォーマットの拡充: PDFに加え、Microsoft Word(.docx)やExcel(.xlsx)といった一般的なビジネス文書への対応。
- マルチモーダル機能の強化: 文書内の画像や図、チャートをより高度に解析・活用する機能。
- 信頼度スコア: AIによる解析結果に信頼度スコアを付与し、スコアが低いものだけを人間がレビューするワークフローの構築支援。
- コネクタの拡充: JiraやConfluenceなど、さらに多くのデータソースへの接続。
まとめと次のアクション
今回のセッションは、Databricks LakeflowとAI機能が、非構造化データ処理の常識をいかに変えようとしているかを明確に示しました。データ取り込みからAIによる解析、ワークフローの自動化まで、すべてがLakehouseという単一のプラットフォーム上でシンプルかつスケーラブルに実現できる世界は、もう目前です。
皆さんの組織にも、Alexが直面したようなPDFの山に埋もれたビジネス価値が眠っているかもしれません。この新しいアプローチは、その宝を掘り出すための強力なドリルとなるでしょう。興味を持たれた方は、Databricksプラットフォームの試用や、関連機能のプライベートプレビューへのサインアップを検討してみてはいかがでしょうか。