
ドメイン特化型AIエージェントの品質をどう測るか? MLflow 3とLLMジャッジによる実践的アプローチ 生成AI、特に特定の業務領域に特化したドメイン特化型AIエージェントの開発が急速に進んでいます。しかし、その自由で創造的な性質ゆえに、「品質」をどう定義し、どう測定するかは多くの開発者が直面する大きな課題です。
本記事では、DatabricksのソフトウェアエンジニアであるNikhil Thorat氏とSamraj Moorjani氏による講演「Creating LLM judges to Measure Domain-Specific Agent Quality」の内容を基に、ドメイン特化型AIエージェントの品質を体系的に評価し、改善していくための実践的なワークフローを解説します。講演では、MLflowの次期メジャーバージョンである「MLflow 3」の新機能が多数紹介されており、生成AI時代のMLOpsがどのように進化していくのか、その最前線を知ることができます。
生成AI時代の品質問題と、その解決策
講演の冒頭で、両氏は「テストされていないソフトウェアを本番に投入しても平気な人」や「エージェントのミスによる金銭的・評判的なリスクを気にしない人」にはこの話は向いていない、とユーモアを交えながら警鐘を鳴らしました。生成AIの出力は非決定的であり、その品質評価は従来のソフトウェア開発とは異なる難しさがあります。
この課題を具体的に理解するため、講演では通信会社(テルコ)のカスタマーサポートを自動化するAIエージェントが例として挙げられました。このエージェントは、ユーザーからの問い合わせ内容に応じて、請求担当、技術サポート担当、アカウント担当といった複数の専門エージェントに処理を振り分ける「マルチエージェントアーキテクチャ」を採用しています。
例えば、「国際ローミングを有効にしたい」という問い合わせがあったとします。この場合、請求やプランに関連する「請求エージェント」が対応するのが適切です。しかし、もしシステムがこれを誤って「アカウントエージェント」にルーティングしてしまったら、ユーザーは適切な回答を得られず、不満を抱くことになります。
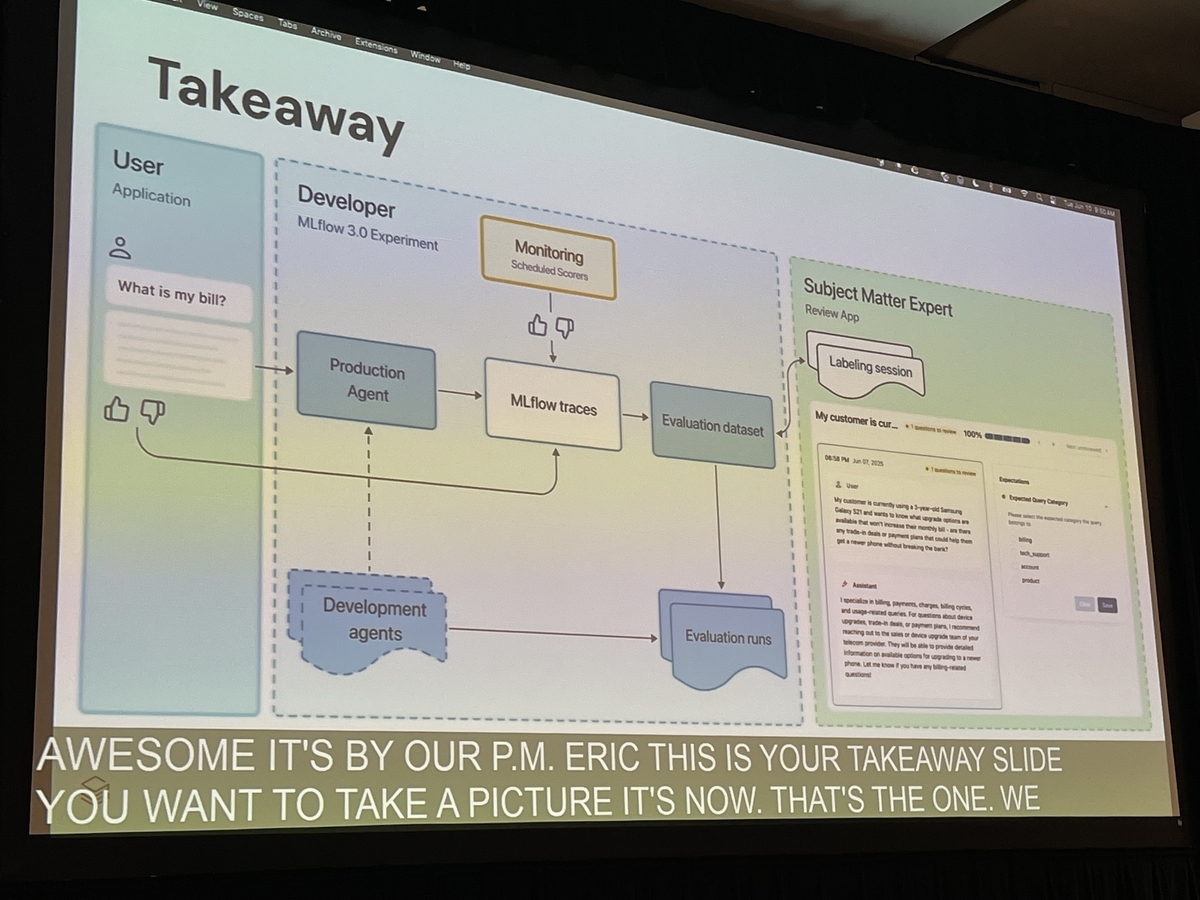
このような品質上のリスクに対し、講演者たちは「雰囲気で確認する(vibe check)」や、いわば「ぶっつけ本番(YOLOing into production)」のような場当たり的な対応では不十分だと指摘します。そこで登場するのが、Databricksが開発を主導するオープンソースのMLOpsプラットフォーム「MLflow」の最新版、MLflow 3です。MLflow 3は、エージェントの挙動を追跡・可視化し、評価データセットを構築、そしてLLMジャッジ自身を評価者(ジャッジ)として活用することで、生成AIアプリケーションの品質評価を体系的に行うための統合的な環境を提供します。
MLflow 3がもたらす統合的MLOps
MLflow 3は、従来の機械学習(クラシカルML)と生成AI(GenAI)のワークフローを、一つのプラットフォーム上でシームレスに管理することを目指して設計されています。講演で特に強調されたのは、以下の3つの強化ポイントです。
- トレーシング (Tracing): エージェント内部の複雑な意思決定プロセスを可視化し、デバッグを容易にします。
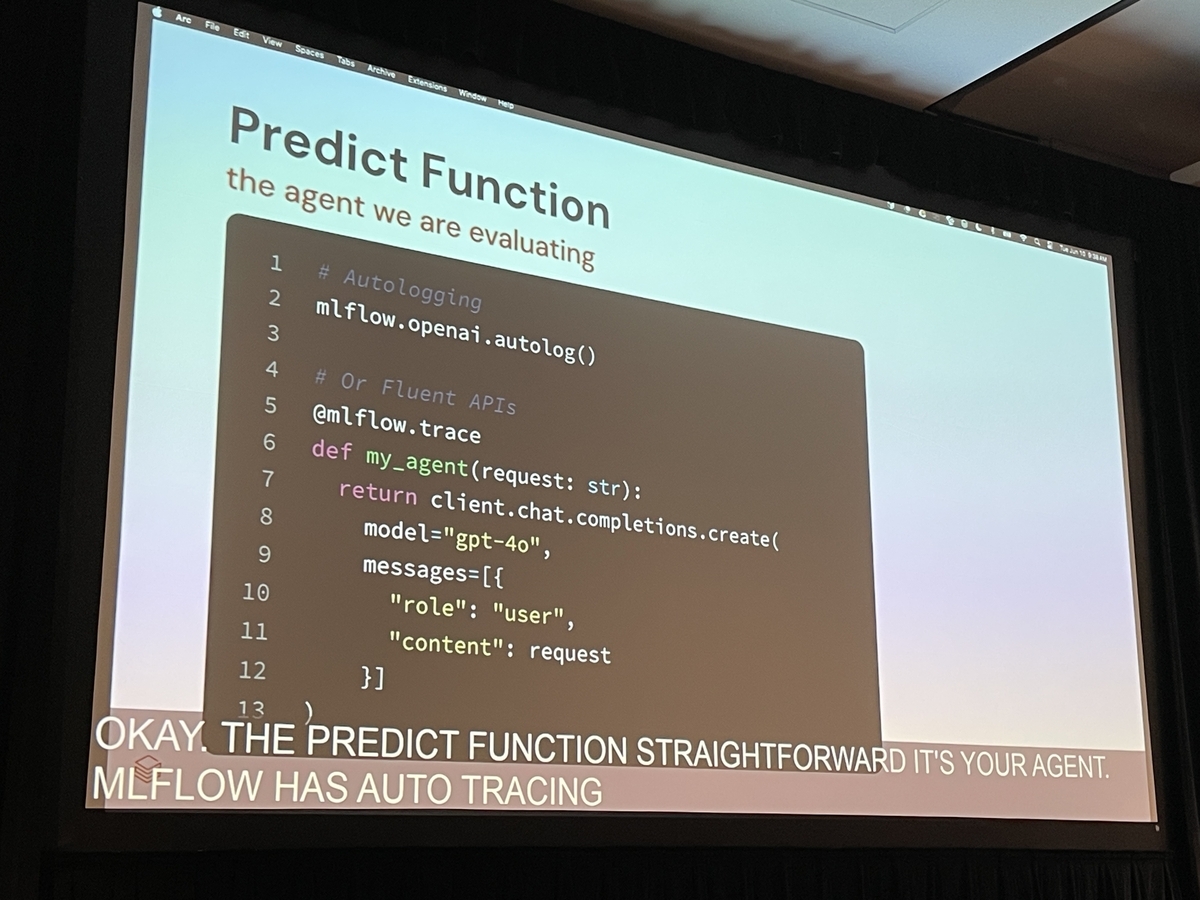
自動評価 (Automated Evaluation): LLMジャッジなどを活用し、品質評価を自動化・スケールさせます。

スケーラビリティ (Scalability): 本番環境での大規模な運用に耐えうる設計になっています。
これらの新機能により、開発者は生成AIエージェントの品質を、従来のソフトウェア開発における単体テストのように、体系的かつ継続的に管理できるようになります。
エージェントの挙動を解き明かす「MLflow Tracing」
問題解決の第一歩は、何が起きているかを正確に把握することです。MLflow Tracingは、マルチエージェントシステムのような複雑なアプリケーションの内部動作をステップごとに記録し、可視化する機能です。
講演のデモでは、ユーザーからの質問がスーパーバイザーエージェントに渡り、そこからどのサブエージェントにルーティングされたか、という一連の流れが時系列で表示されていました。これにより、前述の「国際ローミングの質問が誤ってアカウント担当にルーティングされた」問題が発生した際、開発者はトレース情報を確認することで、根本原因を突き止めることができます。
このケースでは、スーパーバイザーエージェントに与えるプロンプトに、各サブエージェント(請求、技術サポートなど)がどのような役割を担うのかが明確に記述されていなかったことが原因でした。トレース情報がなければ、この種の問題の特定には多くの時間と労力を要したでしょう。
さらに、ユーザーからのフィードバック(UI上のサムズアップ/ダウンなど)を各トレースに紐づけることで、「どのパターンの対話でユーザー満足度が低いか」を効率的に特定し、改善の優先順位付けに役立てることができます。
「単体テスト」の基盤となる評価データセットの構築
デバッグによって特定の問題を修正できたとしても、その修正が他の部分で新たな問題(リグレッション)を引き起こさないかを確認する必要があります。ここで重要になるのが、講演者が「GenAIアプリの単体テスト」と位置づけた評価の仕組みです。その基盤となるのが、評価データセットです。
MLflow 3では、トレーシングのUIから問題のあったトレースや、品質を維持したい重要なトレースを選択し、評価データセットとして簡単に保存できます。このデータセットはDeltaテーブルとして保存され、Unity Catalogを通じて一元的に管理されます。これにより、以下のようなメリットが生まれます。
- ガバナンス: 誰がデータセットにアクセスできるかを細かく制御できます。
- 再利用性: チーム内で評価基準となるデータセットを共有し、一貫した評価を行えます。
- リネージ: どの本番トレースから評価データが作成されたかを追跡できます。
この評価データセットには、入力データ(ユーザーの質問など)と共に、「期待値(Expectations)」、つまり正解ラベルを格納します。例えば、「国際ローミングの質問」という入力に対して、期待値は「請求エージェント」となります。
専門家との協業を加速させるラベリング
期待値を設定するラベリング作業は、開発者だけでは困難な場合があります。特にドメイン特化型エージェントでは、その分野の専門知識を持つ担当者(Subject Matter Expert, SME)の協力が不可欠です。
Databricksは、非技術者である専門家でも直感的にラベリング作業を行える「レビューアプリ」を提供しています。開発者は、評価データセットとラベリングのスキーマ(評価項目)を定義し、レビューセッションを作成します。専門家は、そのセッションにアクセスし、個々の事例に対して「このルーティングは正しいか?」といった問いに答えるだけで、高品質な正解データ(期待値)を効率的に作成できます。
この仕組みにより、開発者とドメイン専門家のコラボレーションが円滑に進み、評価の信頼性が大きく向上します。
LLMを評価者にする「スコアラー」と「LLMジャッジ」
評価データセットと期待値が揃えば、エージェントの出力を定量的に評価できます。mlflow.evaluate() APIを使用すると、評価データセットで定義した期待値との一致率やカスタムメトリクスを計算し、結果を可視化できます。
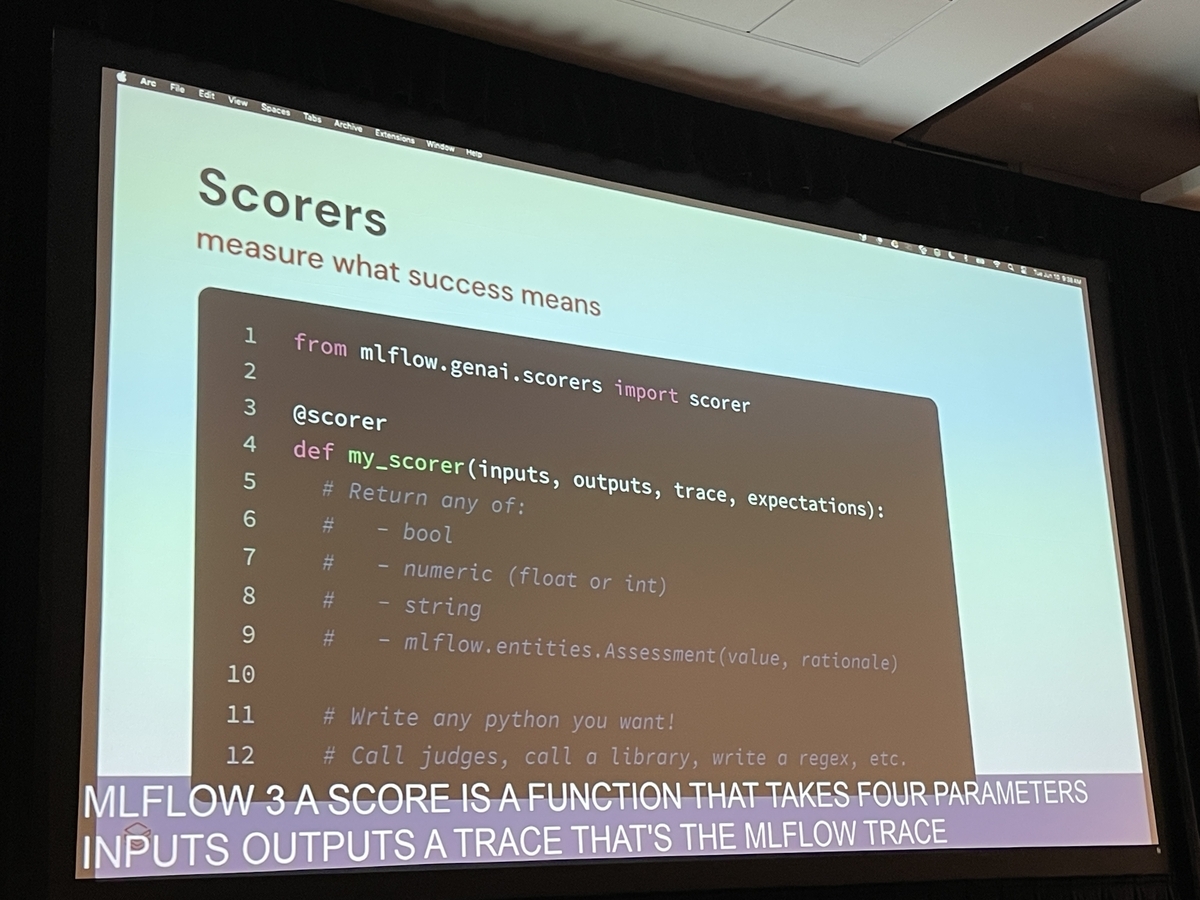
しかし、すべての評価に手作業でラベルを付けるのは現実的ではありません。そこで、MLflow 3では「スコアラー(Scorers)」という仕組みを用いて評価を自動化します。スコアラーには大きく分けて2つのタイプがあります。
期待値ありのスコアラー: 事前に定義された期待値と、エージェントの実際の出力を比較します。例えば、「実際のルーティング先が期待値と一致するか」を評価します。
期待値なしのスコアラー: 期待値(正解ラベル)がなくても、出力の品質を評価します。これを実現するのがLLMジャッジです。

LLMジャッジは、別のLLMを評価者として利用する強力な手法です。MLflow 3には、すぐに使える組み込みのジャッジが用意されています。特に強力なのが「Guidelines Judge」で、評価基準を自然言語で記述するだけで機能します。
例えば、「応答はプロフェッショナルなトーンでなければならない」「顧客IDをすでに知っている場合、再度尋ねてはならない」といったドメイン固有の複雑なルールをガイドラインとして与えることで、LLMジャッジがその基準に沿ってエージェントの出力を自動で評価してくれます。これにより、手動ラベリングのコストを大幅に削減しつつ、ビジネス要件に即したきめ細やかな品質評価を実現できます。 開発から本番運用まで一貫した品質管理 品質管理は一度きりの活動ではありません。本番運用が始まってからも、エージェントのパフォーマンスを継続的に監視し、劣化を検知して改善サイクルを回し続けることが重要です。
MLflow 3のモニタリング機能は、本番環境に流れるライブのトレースデータに対して、定義したスコアラー(LLMジャッジなど)をバックグラウンドで自動実行します。その結果はダッシュボードで可視化され、「特定のトピック(例:請求に関する不満)で品質が低下している」といったトレンドを早期に発見できます。問題が検知されたトレースは、新たな評価データセットとして追加され、次の改善サイクルへと繋がっていきます。
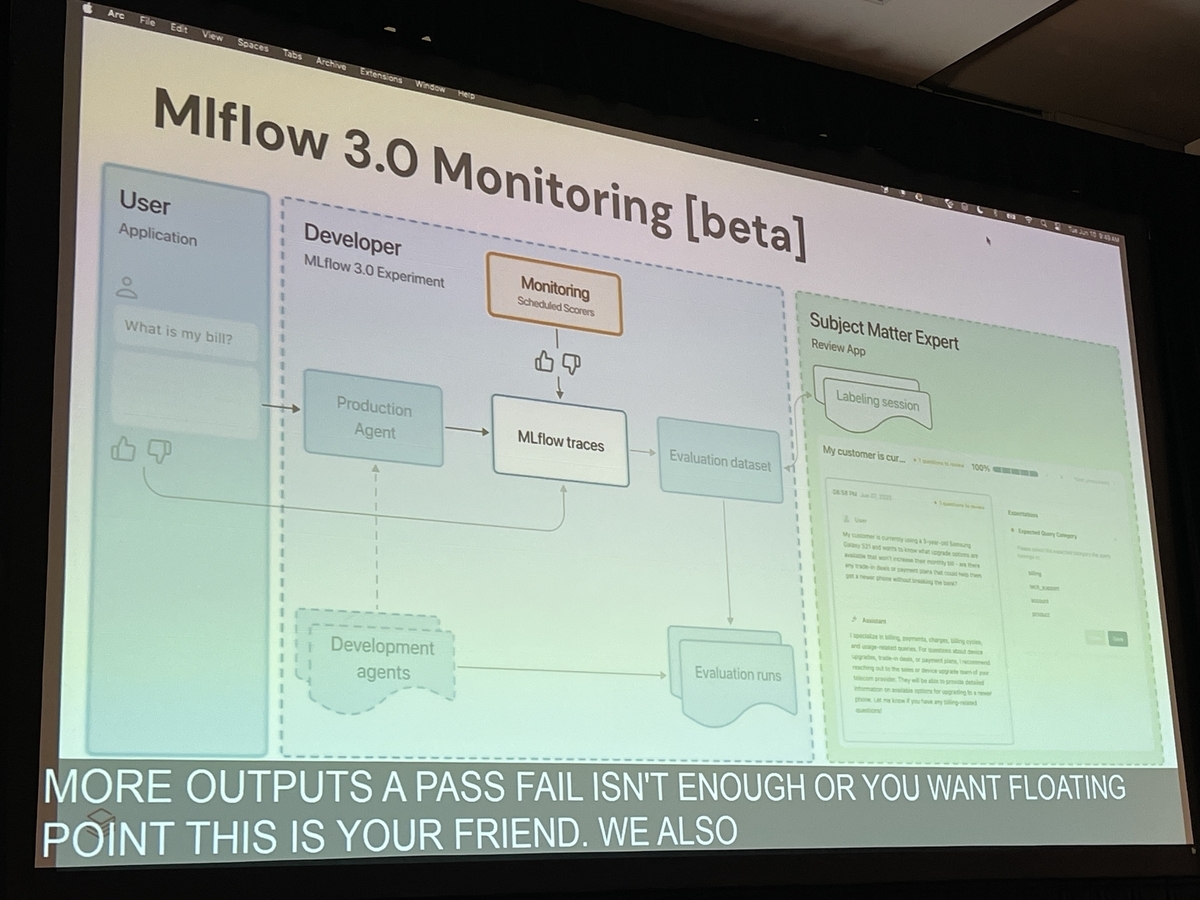
講演で示されたベストプラクティスは、以下のサイクルを回すことでした。
- Trace: 本番環境のエージェントの挙動をMLflow Tracingで捕捉する。
- Dataset構築: 問題のあるトレースや重要なトレースから評価データセットを作成する。
- Labeling: 専門家と協力して期待値をラベリングする。
- Evaluate: 評価データセットとLLMジャッジを用いて、開発中のエージェントを評価する。
- Improve: 評価結果を基にエージェントを改善する。
- Monitor: 改善されたエージェントを本番にデプロイし、継続的に品質を監視する。
まとめと今後の展望
本講演は、生成AI、特にドメイン特化型エージェントの品質保証が、もはや「雰囲気」や「勘」に頼る段階ではなく、体系的かつデータ駆動のアプローチが不可欠であることを明確に示しました。MLflow 3は、トレーシングによる可視化、評価データセットによる再現性の確保、そしてLLMジャッジによる評価の自動化とスケーリングを組み合わせることで、そのための強力な基盤を提供します。
講演の最後には、将来的には「エージェントがエージェントをデバッグする」ような、自動でインサイトを提示する機能も構想されていることが語られました。
生成AIアプリケーションを実験的なツールから、ビジネス価値を生み出す信頼性の高いソリューションへと昇華させるために、本記事で紹介したような評価手法の導入は、今後ますます重要になるでしょう。まずは、あなたのプロジェクトで発生している問題を一つ選び、その挙動をトレースすることから始めてみてはいかがでしょうか。