
生成AIエージェントは自ら賢くなるのか?
生成AI、特に自律的にタスクをこなす「AIエージェント」の進化は目覚ましいものがあります。しかし、その複雑さが増すにつれて、開発段階でのテストだけでは品質を担保しきれないという課題も浮き彫りになってきました。本番環境で予期せぬ振る舞いをしたり、ユーザーの意図を汲み取れなかったりするケースは後を絶ちません。
この記事では、講演「Self-Improving Agents and Agent Evaluation With Arize & Databricks MLflow」を題材に、AIエージェントが本番環境での経験を通じて継続的に品質を向上させる「自己改善」の仕組みについて掘り下げていきます。両社のツールを組み合わせた評価手法とワークフローを解き明かし、皆さんのAIエージェント開発に役立つ知見を提供することを目指します。
Arize & Databricks MLflowによる自己改善ループの全貌
なぜ「継続的な」エージェント評価が必要なのか 従来のソフトウェア開発では、リリース前のテストが品質保証の要でした。しかし、AIエージェント、特に大規模言語モデル(LLM)を搭載したエージェントの振る舞いは非決定的であり、無数の入力パターンに対して完璧に動作することを事前に保証するのは困難です。
講演で示された考え方は、エージェントの品質向上は一度きりのイベントではなく、継続的なプロセスであるべきだというものです。本番環境で発生した「失敗」こそが、エージェントをより賢くするための最も価値あるデータとなります。こうした失敗例を体系的に収集し、分析し、改善サイクルに繋げる「自己改善ワークフロー」を構築することが、エージェントの価値を最大化する鍵となるのです。
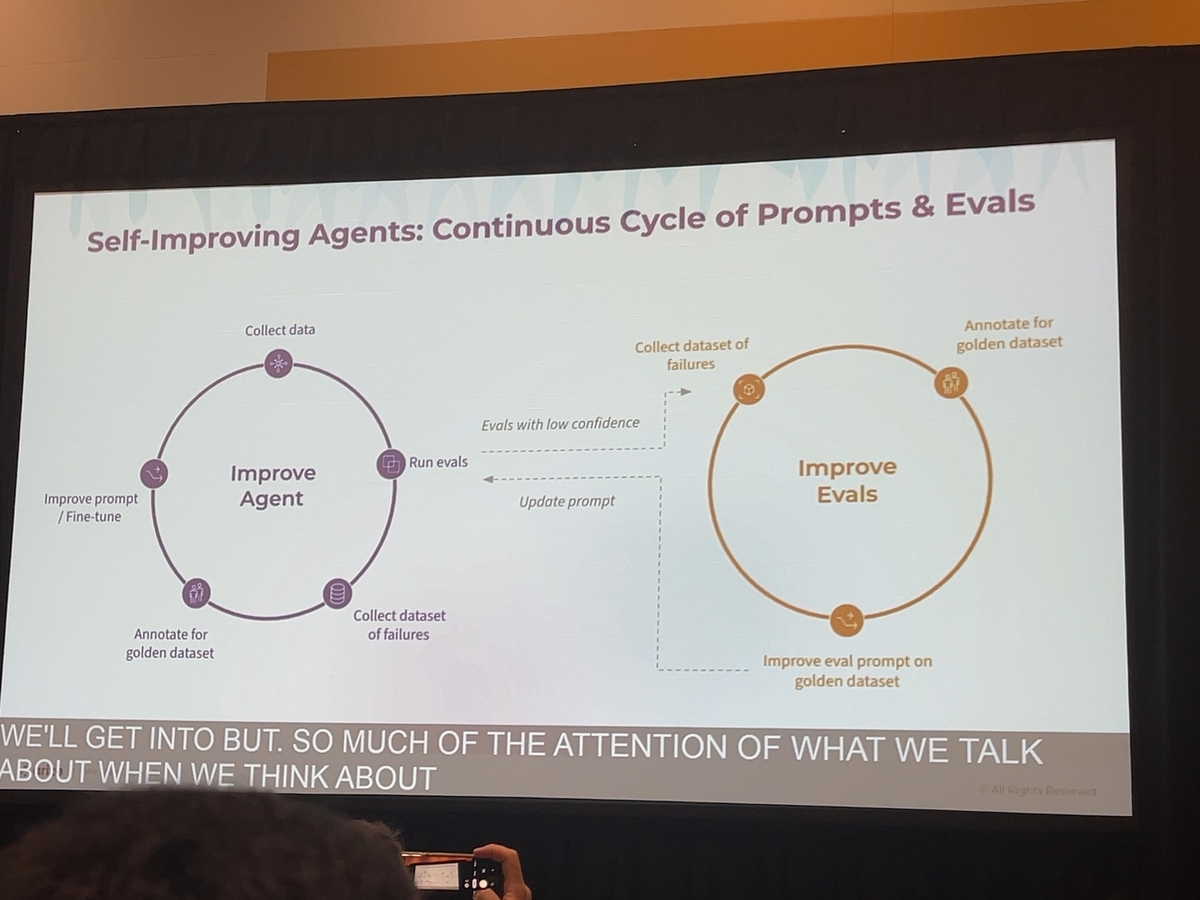
評価と改善を支えるプラットフォーム: Arize & Databricks MLflow
この自己改善ワークフローを実現するために用いられるのが、Databricks MLflowとArizeという2つのプラットフォームです。
Databricks MLflow: オープンソースのMLライフサイクル管理ツールで、実験の追跡やモデル登録などをサポートします。本稿では特に、エージェントの動作ログ(トレース)を収集し、実験のバージョン管理に利用する役割として紹介します。
Arize: モデルの挙動を可視化・モニタリングするプラットフォームです。収集されたトレースデータを用いてパフォーマンスの変動や異常を検知し、根本原因の分析や評価レポートの作成に活用できます。
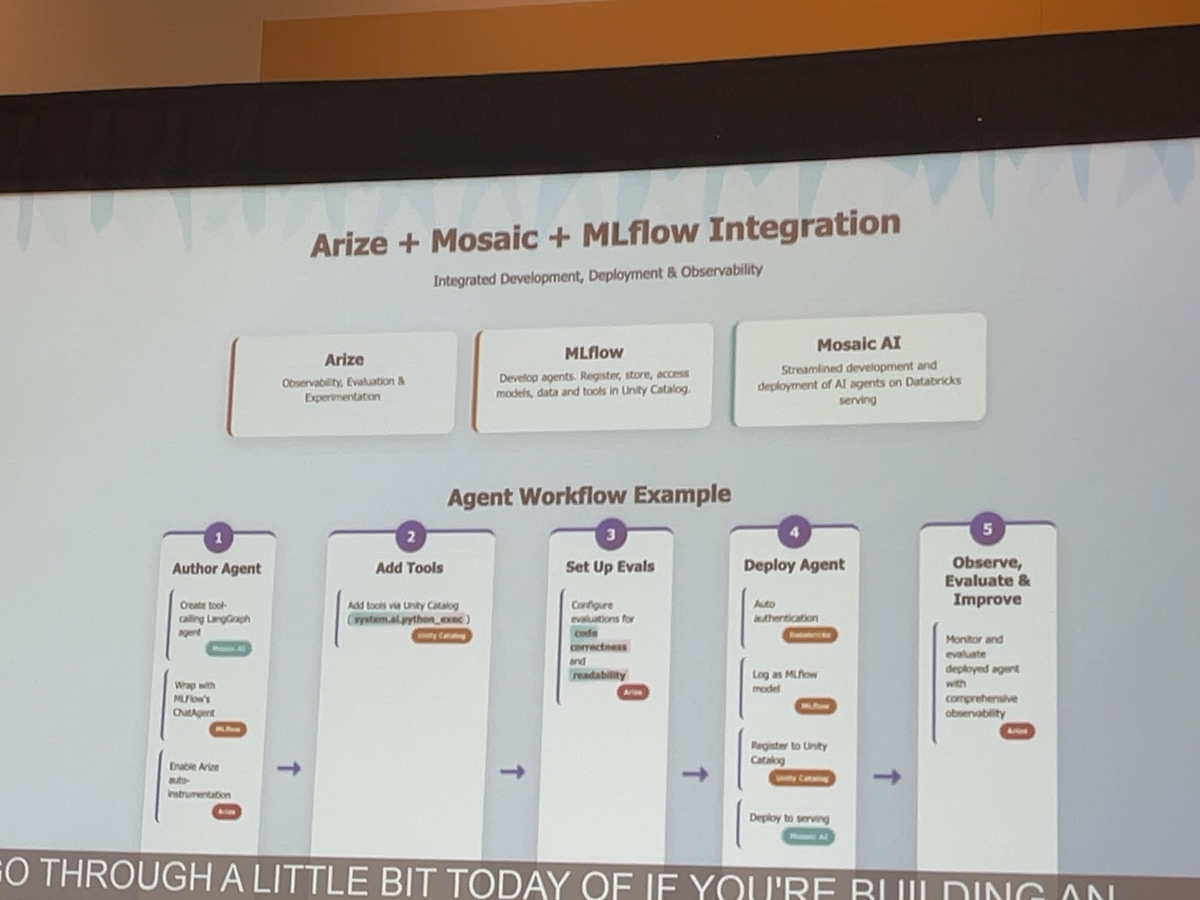
これらを組み合わせることで、トレースの収集から評価、失敗ケースの分析、改善実験までの流れをシームレスに実現します。
エージェントを多角的に評価する「3つのレベル」
講演では、AIエージェントの振る舞いを多角的に把握するための3段階評価フレームワークが提唱されました。
レベル1: ツール呼び出し評価 (Tool Calling Evaluation)
エージェントは外部APIやデータベースを「ツール」として呼び出し、タスクを遂行します。この評価では、エージェントが「適切なツール呼び出し」を、正しい引数で呼び出しているか」を検証します。 たとえば、API呼び出し時のパラメータ誤りによって期待した結果が得られないケースを捉え、個々の呼び出し成功率をモニタリングします。

レベル2: 軌跡評価 (Trajectory Evaluation)
単なる呼び出しだけでなく、タスクを完了するまでの一連のステップ(思考の軌跡)が論理的かつ効率的であるかを評価します。 講演では、Q&Aタスクと検索タスクでパフォーマンスに差異が見られる事例が紹介されました。検索タスクでは一部のステップで約半数が期待通りに動作しない例があり、弱点の特定に役立つことが示されています。

レベル3: セッション評価 (Session Evaluation)
ユーザーとの複数ターンにわたる対話全体を評価します。文脈の一貫性、過去の発言の保持、トーンやスタイルの維持など、対話経験全体からユーザー満足度を測る観点です。一つ一つの応答だけでなく、長期的に「会話パートナー」として機能しているかを検証できます。

自己改善を実現するワークフロー
3つの評価レベルを組み合わせ、以下のサイクルで自己改善を実行します。
トレースの収集と評価: 本番環境のエージェント動作をMLflowで収集し、各評価レベルに応じた自動チェックを実行します。
失敗ケースの検出: ツール呼び出しミスや軌跡上の不整合、対話全体の不備など、低パフォーマンスのトレースを抽出します。
ゴールデンデータセットの作成: 検出された失敗例をまとめ、正解となるツール呼び出しや理想的な応答をアノテーションします。
プロンプトの反復実験: ゴールデンデータセットを用いて新旧プロンプトを比較し、出力品質を定量的に評価。最適化されたプロンプトを選定します。

- 改善版の本番展開: 効果が確認されたプロンプトや設定を本番環境にデプロイし、サイクルを継続します。
このループを高速に回すことで、エージェントは運用中のリアルワールド経験を糧に自律的にパフォーマンスを向上させていきます。
実装における3つの重要な考慮事項
コスト管理のためのサンプリング: 評価処理をすべてのトレースに対して実施するとコストが増大します。10%程度のサンプリングでも傾向把握には十分であり、適切なサンプリング戦略が重要です。
プライバシー保護 (PIIマスキング): 本番データを扱う以上、個人情報の漏洩リスクを抑えるために名前やメールアドレスなどを自動でマスキングする仕組みを導入します。
評価テンプレートの継続的な進化: 一度設計した評価テンプレート(プロンプトや判定ルール)は、アプリケーションの変化に合わせて更新が必要です。評価基盤自体も自己改善の対象となります。
まとめ: エージェントは「育てる」時代へ
講演「Self-Improving Agents and Agent Evaluation With Arize & Databricks MLflow」が示したのは、もはやAIエージェント開発は一度作って終わりではなく、本番環境で「育てる」プロセスが不可欠だという事実です。
ツール呼び出し・軌跡・セッションの3レベルで多角的に評価し、失敗例から学ぶ自己改善ループを設計する。そして、その全体フローをMLflowやArizeといった専用ツールで効率化する。これが、これからのAIエージェント開発におけるベストプラクティスの一つと言えるでしょう。
まずは小規模な失敗ケースからサイクルを回し始め、自動評価の高速化とともに自己改善ワークフローを成熟させていくことが、次世代エージェントを生み出す鍵となります。